
基于 Ansible 的生产级 Java 应用部署系统设计与实践 —— 状态、版本、权限、回滚四个核心问题
很多团队的裸机部署还停留在「SCP 传 jar + SSH 重启」的阶段。能用,但不可复用、不可回滚、不可审计。本文拆解一个真实在产的 Ansible 部署项目——它用不到 200 行 YAML + 一个 Shell 脚本,实现了 Java 应用的幂等初始化、四目录版本管理、七命令生命周期、开机自启和服务注销闭环。面向正在用 Ansible 管理裸机/VM Java 部署的运维与 SRE 工程师,聚焦可复用的设计模式与踩坑点。
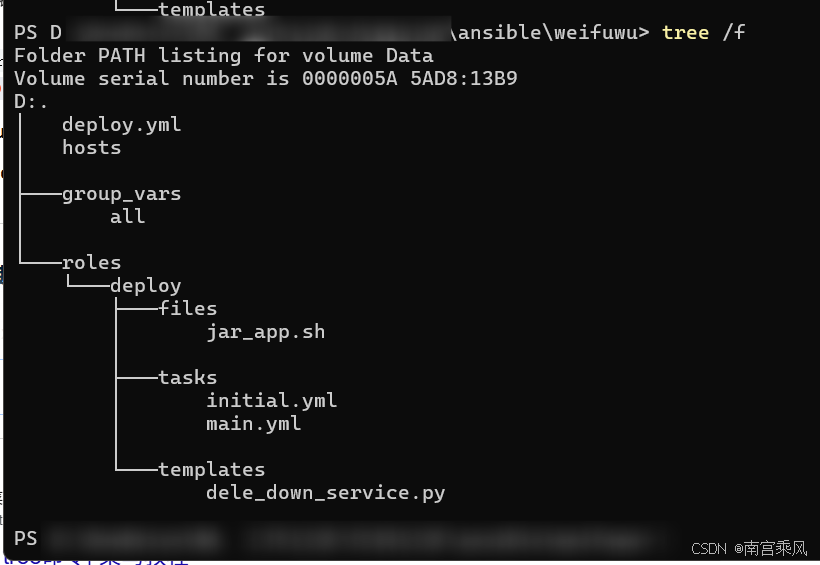
一、先看全貌:一个最小可用的 Ansible 部署项目
整个项目的文件结构:
核心只有 7 个文件,却覆盖了一个 Java 应用从「首次装机」到「日常更新回滚」的完整闭环。入口 deploy.yml 极简:
- name: Deploy Jar Package
hosts: all
remote_user: root
roles:
- deploy
这种「入口只做声明,逻辑全在 Role 里」的写法是 Ansible 的最佳实践。deploy.yml 可以被复用、被组合进更大的 Playbook,而 deploy Role 本身保持自包含。
二、幂等初始化:条件执行的艺术
部署脚本最常见的坑是「重复执行会出错」——比如重复创建用户、重复写开机启动项。这个项目用 stat 检测 + 条件 include 解决了幂等性。
2.1 主任务流程:检测 → 初始化 → 上传 → 更新
# roles/deploy/tasks/main.yml
- name: 检测应用目录
stat: path=/fjf_work/{{jobname}}
register: app_dir
- include_tasks: initial.yml
when: app_dir.stat.exists == false
- name: 获取jar包名称
shell: basename `ls roles/deploy/files/*.jar`
args:
warn: no
delegate_to: 127.0.0.1
register: package
- name: 上传jar包
copy: src={{package.stdout}} dest=/fjf_work/{{jobname}}/package/ owner=fjf group=fjf mode=0644
- name: 运行jar包
command: /fjf_work/{{jobname}}/bin/jar_app.sh update
args:
warn: no
这段流程的执行逻辑:
关键设计是 when: app_dir.stat.exists == false——只有首次部署才执行初始化。后续每次更新都跳过 initial.yml,直接走「上传 jar → update」的快路径。这保证了:
- 幂等:重复跑
ansible-playbook deploy.yml不会重复建用户、重复写 rc.local; - 快:日常更新只做必要的两步;
- 安全:不会因为重复初始化破坏已有配置。
最佳实践 #1:Ansible 的幂等性不能只靠模块自身的
state=present,跨多步骤的「首次/非首次」分支要用stat+register+when显式控制。把「初始化」和「更新」拆成不同 task 文件,用条件 include 串联,比把所有逻辑塞进一个main.yml用一堆when判断清晰得多。
2.2 初始化任务:建用户、建目录、装脚本、设自启
# roles/deploy/tasks/initial.yml
- name: 添加fjf账号
user: name=fjf state=present
- name: 创建目录结构
file: path={{item.path}} state=directory owner=fjf group=fjf mode={{item.mode}}
with_items:
- { path: "/fjf_work", mode: "0755" }
- { path: "/fjf_work/{{jobname}}", mode: "0755" }
- { path: "/fjf_work/{{jobname}}/bin", mode: "0755" }
- { path: "/fjf_work/{{jobname}}/logs", mode: "0755" }
- { path: "/fjf_work/{{jobname}}/backup", mode: "0750" }
- { path: "/fjf_work/{{jobname}}/package", mode: "0750" }
- { path: "/fjf_work/{{jobname}}/rollback", mode: "0750" }
- { path: "/fjf_work/{{jobname}}/runtime", mode: "0750" }
- name: 上传脚本文件
copy: src=jar_app.sh dest=/fjf_work/{{jobname}}/bin/ owner=fjf group=fjf mode=0755
- name: 设置文件权限
file: path=/etc/rc.d/rc.local state=file mode=0755
- name: 设置开机启动
lineinfile:
path: '/etc/rc.d/rc.local'
regexp: '^/fjf_work/{{jobname}}/bin/jar_app.sh'
line: '/fjf_work/{{jobname}}/bin/jar_app.sh start'
这里有四个值得拆解的细节。
第一,权限分层。 注意目录权限不是一刀切:
| 目录 | 权限 | 原因 |
|---|---|---|
bin/、logs/ |
0755 |
脚本要执行,日志可能被监控Agent读取 |
runtime/、package/、rollback/、backup/ |
0750 |
包含制品,只允许属主和属组访问 |
0750 比 0755 收紧了「其他用户」的读权限——jar 包里可能有配置密码,不应让同机其他应用读到。
第二,lineinfile 的幂等性。 设置开机启动用的是 lineinfile 而不是 echo >>:
lineinfile:
path: '/etc/rc.d/rc.local'
regexp: '^/fjf_work/{{jobname}}/bin/jar_app.sh'
line: '/fjf_work/{{jobname}}/bin/jar_app.sh start'
regexp 保证同一应用的启动项只写一行——重复执行会替换而不是追加。如果用 echo >> /etc/rc.d/rc.local,跑 10 次 playbook 就会有 10 行重复的启动命令,开机时启动 10 次应用。
最佳实践 #2:修改配置文件永远用
lineinfile/blockinfile/template,不要用shell: echo >>。前者幂等,后者每次追加。这是 Ansible 新手最容易犯的错。
第三,/etc/rc.d/rc.local 的执行权限。 CentOS 7+ 默认 rc.local 没有执行权限,开机不会执行它。所以初始化里有一行:
- name: 设置文件权限
file: path=/etc/rc.d/rc.local state=file mode=0755
没有这一步,写了启动项也白写——这是 CentOS 7 迁移到 systemd 后的经典坑。
第四,降权运行。 初始化建了 fjf 用户,但 playbook 是 remote_user: root 执行的。脚本以 root 跑,应用以 fjf 跑——执行权和运行权分离,这个设计在后面的 jar_app.sh 里体现。
三、四目录结构:用文件系统表达部署状态
初始化创建了 4 个核心目录,它们不是随意命名,而是一套用文件系统状态表达部署阶段的设计:
| 目录 | 作用 | 数量约束 | 权限 |
|---|---|---|---|
runtime/ |
当前正在运行的 jar | 恰好 1 个 | 0750 |
package/ |
待部署的新版本 jar | 恰好 1 个 | 0750 |
rollback/ |
上一版本(用于回滚) | 至多 1 个 | 0750 |
backup/ |
带时间戳的历史备份 | 任意 | 0750 |
这套设计的精妙之处:任何一个时刻,看四个目录里有什么 jar,就能推断出应用处于什么状态。而且 jar_app.sh 对异常状态有显式拦截:
function get_jar_name() {
i=0
for subdir in runtime package rollback
do
number=`ls ${subdir}/*.jar 2> /dev/null | wc -l`
if [ ${number} -eq 0 ]; then
jar_name[$i]='no_exist'
elif [ ${number} -eq 1 ]; then
jar_name[$i]=$(basename `ls ${subdir}/*.jar`)
else
jar_name[$i]='too_many'
fi
let "i=i+1"
done
}
每个目录的 jar 数量有三种状态:no_exist(没有)、正常(1 个)、too_many(多个)。too_many 是危险信号——说明之前某次部署中断了或有人手动塞了文件,此时脚本直接 exit 1 拒绝继续,避免在不确定状态下操作。
最佳实践 #3:部署脚本的所有操作前置都应该做「状态校验」。宁可拒绝执行,也不要在脏状态下继续。
check_runtime_jar()函数就是这道闸门——no_exist和too_many都会被拦截。
注意 rollback/ 目录只保留一个版本:每次 update 时先 rm -f rollback/*.jar 再把当前版本拷进去。这是有意为之——回滚只允许回到「上一次可用版本」,而不是任意历史版本。回滚到太旧的版本往往比故障本身更危险(数据库 schema 可能已经不兼容)。
四、jar_app.sh:七命令生命周期管理
jar_app.sh 提供 7 个子命令,覆盖应用全生命周期:
case "$1" in
'start') start_function ;;
'stop') stop_function ;;
'restart') restart_function ;;
'status') status_function ;;
'backup') backup_function ;;
'update') update_function ;;
'rollback') rollback_function ;;
*) echo "Usage: $0 {start|stop|restart|status|backup|update|rollback}" ;;
esac
这 7 个命令不是平铺的,它们有明确的职责分层:
update 和 rollback 是「编排命令」,它们内部组合调用 stop_jar + start_jar 等原子函数。start/stop/restart/status 是「原子命令」,可以单独执行。这种分层让脚本既能在 Ansible 里被编排,也能登录机器手动救火。
4.1 进程检测:用 jar 名匹配 java 进程
function status_jar() {
get_jar_name
pids=`ps -f -C java --no-headers | grep -E "(/|\s)+${runtime_jar_name}" | awk '{print $2}'`
if [ -n "${pids}" ]; then
return 0
else
return 1
fi
}
ps -C java 按命令名过滤 java 进程,再用 jar 包名做二次匹配,最后取 PID。这种「软匹配」的好处是零配置——不需要额外的 PID 文件,只要知道 jar 名就能查进程。
踩坑警示:用 jar 文件名匹配 java 进程的前提是「同机不同应用的 jar 名不相似」。如果一台机器上跑
app-1.0.jar和app-1.0.1.jar,正则app-1.0可能误伤两个进程。生产环境中,PID 文件或唯一端口绑定是更可靠的进程标识。这份脚本用 jar 名匹配是为了零配置,代价是牺牲了一部分严谨性——适合「一机一应用」的部署模型。
4.2 启动:daemon 降权 + 超时判定
function start_jar() {
status_jar
if [ $? -eq 0 ]; then
echo "[INFO] The program is running. No need to start it again."
return 0
fi
cd ${parent_path}
if [ $UID -eq 0 ]; then
daemon --user=${user} java -server -Xms1024m -Xmx2048m -jar ${parent_path}/runtime/${runtime_jar_name} >/dev/null 2>&1 &
else
daemon java -server -Xms1024m -Xmx2048m -jar ${parent_path}/runtime/${runtime_jar_name} >/dev/null 2>&1 &
fi
timeout=${start_timeout}
step=5
for (( count=0; count<timeout; count=count+step))
do
sleep $step
status_jar
if [ $? -eq 0 ]; then
echo "[INFO] Starting program successfully."
return 0
fi
done
# ...
}
两个关键点。
第一,root 降权启动。 当脚本以 root 执行时,通过 daemon --user=fjf 降权到普通用户启动 Java 进程。daemon 函数来自 /etc/rc.d/init.d/functions,它封装了 setsid、umask、工作目录切换等细节,比裸 nohup 更可靠。
这是安全基线——生产应用绝不应该以 root 身份运行。Ansible playbook 以 root 执行(为了建用户、改权限),但应用进程必须降权。这份脚本做到了执行权和运行权分离。
最佳实践 #4:部署脚本的执行用户和应用的运行用户应该分离。脚本可以 root,但应用进程必须降权。一个 root 跑的 Java 进程一旦被 RCE,攻击者直接拿到 root,整台机器沦陷。
第二,轮询判定启动成功。 这个版本的 start_timeout=10 秒,每 5 秒检查一次进程是否存活。这是「乐观判定」——进程还在就算成功,适合启动快、没有健康检查端点的应用。
进阶提示:这个版本没有 HTTP 健康检查。如果应用启动慢(Spring Boot 加载 2 分钟),10 秒判定窗口太短,可能误判失败。生产环境建议增加
health_uri配置,启动时轮询 HTTP 端点返回 200 才算成功。本项目的演进版本已经加入了这个能力。
4.3 停止:两段式优雅停止
function stop_jar() {
status_jar
if [ $? -eq 1 ]; then
echo "[INFO] The program is not running. No need to stop it."
return 0
fi
for pid in ${pids}; do
kill ${pid} # 第一段:SIGTERM
done
timeout=${shutdown_timeout} # 10 秒
step=2
for (( count=0; count<timeout; count=count+step))
do
sleep $step
status_jar
if [ $? -eq 1 ]; then
echo "[INFO] Shutting down program successfully."
return 0
fi
done
for pid in ${pids}; do
kill -9 ${pid} # 第二段:SIGKILL
done
echo "[WARNING] Program has been killed forcibly."
}
这是教科书式的两段式停止:先发 SIGTERM 给应用留优雅退出的窗口(10 秒),超时再 SIGKILL 强杀。
SIGTERM 给了应用执行 shutdown hook 的机会——关闭数据库连接池、刷新缓存、完成在途请求。SIGKILL 是兜底,但代价是 shutdown hook 不执行,可能导致数据不一致。
最佳实践 #5:停止用两段式:SIGTERM + 超时 + SIGKILL。
shutdown_timeout要大于应用最长优雅退出时间。这个版本设的 10 秒偏短——如果应用有大量在途请求或慢 SQL,10 秒可能来不及排空。生产环境建议 30-60 秒。
4.4 update:状态机式部署
function update_function() {
get_jar_name
# 前置校验:package 必须有且仅有 1 个 jar,runtime 不能有多个
if [ "${package_jar_name}" == "no_exist" ]; then exit 1; fi
if [ "${package_jar_name}" == "too_many" ]; then exit 1; fi
if [ "${runtime_jar_name}" == "too_many" ]; then exit 1; fi
if [ "${runtime_jar_name}" == "no_exist" ]; then
# 首次部署,无需停机备份
echo "[INFO] No need to stop it or backup."
else
# 非首次:备份 → 存 rollback → 停止 → 清 runtime
cp -a runtime/${runtime_jar_name} backup/${runtime_jar_name}.bak_`date +%Y%m%d_%H:%M:%S`
rm -f rollback/*.jar
cp -a runtime/${runtime_jar_name} rollback/${runtime_jar_name}
stop_jar
rm -f runtime/*.jar
fi
# 替换 + 启动
mv -f package/${package_jar_name} runtime/${package_jar_name}
get_jar_name
start_jar
}
把 update 流程画成状态机:
这套设计的核心假设是:目录操作是原子的(mv 在同一文件系统下是原子的)。这比「先删后拷」安全得多——如果拷贝中断,runtime 目录就空了,应用起不来。
部署顺序也讲究:先备份 → 再存 rollback → 才停止 → 最后替换。停止前把 rollback 准备好,这样即使替换后新版本启动失败,也能立即 rollback 恢复,不用等备份目录里翻时间戳。
最佳实践 #6:部署的中间状态要可恢复。这份脚本通过「先备份再替换 + rollback 目录」保证了任何一步失败都能退。比起直接
rm + cp,多一步备份换来的是部署的可逆性。回滚路径要在停止前就准备好,而不是失败后才临时找。
4.5 rollback:一键回到上一版本
function rollback_function() {
get_jar_name
# 前置校验
if [ "${rollback_jar_name}" == "no_exist" ]; then exit 1; fi
if [ "${rollback_jar_name}" == "too_many" ]; then exit 1; fi
if [ "${runtime_jar_name}" == "no_exist" ]; then
echo "[INFO] No need to stop it."
else
stop_jar
rm -f runtime/*.jar
fi
mv -f rollback/${rollback_jar_name} runtime/${rollback_jar_name}
get_jar_name
start_jar
}
rollback 比 update 简单:停止 → rollback 目录的 jar 移到 runtime → 启动。注意 rollback 执行后,rollback/ 目录就空了——不支持连续回滚两次。这是有意的安全设计,防止误操作回滚到太旧的版本。
运维提示:rollback 命令执行后,rollback 目录清空。如果需要再次回滚,要先从
backup/目录手动恢复一个版本到 rollback 目录。backup/目录保留所有带时间戳的历史版本,是最后的安全网。
五、服务注册与注销:Consul 集成
项目里有一个 dele_down_service.py,用于从 Consul 注销 critical 状态的服务:
# roles/deploy/templates/dele_down_service.py
service_url = 'http://{{consul_server}}:8500/v1/health/state/critical'
r = requests.get(service_url)
data = json.loads(r.content)
dele_url = []
for i in data:
serviceID = i['ServiceID']
ip = re.findall(r'\d+.\d+.\d+.\d+', i['Node'])
url = 'http://%s:8500/v1/agent/service/deregister/%s' % (ip[0], serviceID)
dele_url.append(url)
for s in dele_url:
r = requests.get(s)
逻辑是:查询 Consul 所有 critical 状态的服务 → 提取 ServiceID 和节点 IP → 调用各节点的 deregister API 注销。
但注意:这个脚本在两处都被注释掉了。
jar_app.sh 的 stop_jar 里:
#/usr/bin/python dele_down_service.py >/dev/null 2>&1
initial.yml 的上传步骤:
#- name: 上传python脚本
# template: src=dele_down_service.py dest=/fjf_work/{{jobname}}/bin/ owner=fjf group=fjf mode=0755
这说明这个能力设计过但未启用。为什么?
注释掉是有原因的。这个脚本的设计有个隐患:它注销的是所有 critical 服务,不分应用。如果同一 Consul 集群里有别的应用刚好处于 critical(比如正在重启),会被一起注销掉,造成误伤。
正确的做法应该是按 ServiceID 或 ServiceName 过滤,只注销当前应用的 critical 实例:
# 改进版思路(伪代码)
my_service_name = '{{jobname}}'
for i in data:
if i.get('ServiceName') == my_service_name: # 只处理自己的
# ... deregister
最佳实践 #7:服务注销要「精准定位」,不能「无差别清理」。这个脚本被注释掉,说明作者意识到了风险——宁可手动处理 critical 实例,也不要让脚本误删别人的服务注册。这种「有问题先下线,宁缺毋滥」的决策是成熟的运维判断。
完整的脚本
#!/bin/bash
export LANG=en_US.UTF-8
export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
user=fjf
start_timeout=10
shutdown_timeout=10
# Source function library.
. /etc/rc.d/init.d/functions
#export JAVA_HOME=/usr/local/jdk-11.0.1
#export PATH=${JAVA_HOME}/bin:${PATH}
# 获取本脚本所在目录
basepath=$(cd `dirname $0`; pwd)
# 获取父目录(应用安装目录)
parent_path=`dirname ${basepath}`
cd ${parent_path}
# 先尝试获取runtime目录下的jar包名称,如没有,再获取package目录下的jar包名称
function get_jar_name() {
i=0
for subdir in runtime package rollback
do
number=`ls ${subdir}/*.jar 2> /dev/null | wc -l`
if [ ${number} -eq 0 ]; then
jar_name[$i]='no_exist'
elif [ ${number} -eq 1 ]; then
jar_name[$i]=$(basename `ls ${subdir}/*.jar`)
else
jar_name[$i]='too_many'
fi
let "i=i+1"
done
runtime_jar_name=${jar_name[0]}
package_jar_name=${jar_name[1]}
rollback_jar_name=${jar_name[2]}
}
# 检查jar包运行状态:运行,返回值为0;未运行,返回值为1。
# 本函数需提供给其它函数调用。本函数中不对runtime目录下的jar包数量做校验,交给调用它的函数进行校验。
function status_jar() {
get_jar_name
pids=`ps -f -C java --no-headers | grep -E "(/|\s)+${runtime_jar_name}" | awk '{print $2}'`
if [ -n "${pids}" ]; then
return 0
else
return 1
fi
}
# 本函数检查runtime目录下面jar包的数量。
# 本函数需提供给其它函数调用。
function check_runtime_jar() {
get_jar_name
if [ "${runtime_jar_name}" == "no_exist" ]; then
echo "[INFO] No jar package is found under '${parent_path}/runtime' directory."
exit 1
fi
if [ "${runtime_jar_name}" == "too_many" ]; then
echo "[INFO] Two or more jar packages are found under '${parent_path}/runtime' directory."
exit 1
fi
}
# 本函数实现本脚本的status功能。
# 本函数不提供给其它函数调用。
function status_function() {
check_runtime_jar
status_jar
if [ $? -eq 0 ]; then
echo "[INFO] Jar package '${runtime_jar_name}' is running."
else
echo "[INFO] Jar package '${runtime_jar_name}' is not running."
fi
}
# 停止jar包。
# 本函数需提供给其它函数调用。本函数中不对runtime目录下的jar包数量做校验,交给调用它的函数进行校验。
function stop_jar() {
status_jar
if [ $? -eq 1 ]; then
echo "[INFO] The program is not running. No need to stop it."
return 0
fi
echo "[INFO] Shutting down program . . . . . . "
for pid in ${pids}; do
kill ${pid}
done
timeout=${shutdown_timeout}
step=2
for (( count=0; count<timeout; count=count+step))
do
sleep $step
status_jar
if [ $? -eq 1 ]; then
echo "[INFO] Shutting down program successfully."
return 0
fi
done
status_jar
for pid in ${pids}; do
kill -9 ${pid}
done
#/usr/bin/python dele_down_service.py >/dev/null 2>&1
echo "[WARNING] Program has been killed forcibly."
}
# 本函数实现本脚本的stop功能。
# 本函数不提供给其它函数调用。
function stop_function() {
check_runtime_jar
stop_jar
}
# 运行jar包。
# 本函数需提供给其它函数调用。本函数中不对runtime目录下的jar包数量做校验,交给调用它的函数进行校验。
function start_jar() {
status_jar
if [ $? -eq 0 ]; then
echo "[INFO] The program is running. No need to start it again."
return 0
fi
echo "[INFO] Starting program . . . . . . "
# 启动程序前确保先切换到应用根目录,因有些jar程序会将它的日志写到相对启动路径的logs/目录中。
cd ${parent_path}
if [ $UID -eq 0 ]; then
daemon --user=${user} java -server -Xms1024m -Xmx2048m -jar ${parent_path}/runtime/${runtime_jar_name} >/dev/null 2>&1 &
else
daemon java -server -Xms1024m -Xmx2048m -jar ${parent_path}/runtime/${runtime_jar_name} >/dev/null 2>&1 &
fi
timeout=${start_timeout}
step=5
for (( count=0; count<timeout; count=count+step))
do
sleep $step
status_jar
if [ $? -eq 0 ]; then
echo "[INFO] Starting program successfully."
return 0
fi
done
status_jar
if [ $? -eq 0 ]; then
echo "[INFO] Starting program successfully."
else
echo "[ERROR] Starting program times out."
exit 1
fi
}
# 本函数实现本脚本的start功能。
# 本函数不提供给其它函数调用。
function start_function() {
check_runtime_jar
start_jar
}
# 本函数实现本脚本的restart功能。
# 本函数不提供给其它函数调用。
function restart_function() {
check_runtime_jar
stop_jar
start_jar
}
# 本函数实现本脚本的backup功能。
# 本函数不提供给其它函数调用。
function backup_function() {
check_runtime_jar
cp -a runtime/${runtime_jar_name} backup/${runtime_jar_name}.bak_`date +%Y%m%d_%H:%M:%S`
echo "[INFO] Package '${parent_path}/runtime/${runtime_jar_name}' has been backed up successfully."
}
# 本函数实现本脚本的update功能。
# 本函数不提供给其它函数调用。
function update_function() {
get_jar_name
if [ "${package_jar_name}" == "no_exist" ]; then
echo "[INFO] No jar package is found under '${parent_path}/package' directory."
exit 1
fi
if [ "${package_jar_name}" == "too_many" ]; then
echo "[INFO] Two or more jar packages are found under '${parent_path}/package' directory."
exit 1
fi
if [ "${runtime_jar_name}" == "too_many" ]; then
echo "[INFO] Two or more jar packages are found under '${parent_path}/runtime' directory."
exit 1
fi
echo "[INFO] Starting to update . . . "
if [ "${runtime_jar_name}" == "no_exist" ]; then
echo "[INFO] No jar package is found under '${parent_path}/runtime' directory. No need to stop it or backup."
else
cp -a runtime/${runtime_jar_name} backup/${runtime_jar_name}.bak_`date +%Y%m%d_%H:%M:%S`
rm -f rollback/*.jar
cp -a runtime/${runtime_jar_name} rollback/${runtime_jar_name}
stop_jar
rm -f runtime/*.jar
fi
mv -f package/${package_jar_name} runtime/${package_jar_name}
get_jar_name
start_jar
echo "[INFO] Program has been updated successfully."
}
# 本函数实现本脚本的rollback功能。
# 本函数不提供给其它函数调用。
function rollback_function() {
get_jar_name
if [ "${rollback_jar_name}" == "no_exist" ]; then
echo "[INFO] No jar package is found under '${parent_path}/rollback' directory."
exit 1
fi
if [ "${rollback_jar_name}" == "too_many" ]; then
echo "[INFO] Two or more jar packages are found under '${parent_path}/rollback' directory."
exit 1
fi
if [ "${runtime_jar_name}" == "too_many" ]; then
echo "[INFO] Two or more jar packages are found under '${parent_path}/runtime' directory."
exit 1
fi
echo "[INFO] Starting to roll back . . . "
if [ "${runtime_jar_name}" == "no_exist" ]; then
echo "[INFO] No jar package is found under '${parent_path}/runtime' directory. No need to stop it."
else
stop_jar
rm -f runtime/*.jar
fi
mv -f rollback/${rollback_jar_name} runtime/${rollback_jar_name}
get_jar_name
start_jar
echo "[INFO] Program has been rolled back successfully."
}
case "$1" in
'start')
start_function
;;
'stop')
stop_function
;;
'restart')
restart_function
;;
'status')
status_function
;;
'backup')
backup_function
;;
'update')
update_function
;;
'rollback')
rollback_function
;;
*)
echo "Usage: $0 {start|stop|restart|status|backup|update|rollback}"
esac
六、开机自启:rc.local 的取舍
初始化任务里设置了开机启动:
- name: 设置文件权限
file: path=/etc/rc.d/rc.local state=file mode=0755
- name: 设置开机启动
lineinfile:
path: '/etc/rc.d/rc.local'
regexp: '^/fjf_work/{{jobname}}/bin/jar_app.sh'
line: '/fjf_work/{{jobname}}/bin/jar_app.sh start'
用 rc.local 做开机自启是传统方案,简单直接,但有局限:
| 方案 | 优点 | 缺点 |
|---|---|---|
rc.local(本项目) |
简单、无学习成本 | 不监控进程,挂了不重启;启动顺序难控制 |
| systemd service | 进程挂了自动重启、依赖管理、日志journal | 需要写 unit 文件 |
| supervisord | 跨语言统一管理、Web UI | 多一个依赖 |
rc.local 的本质是「开机时跑一次」,不提供进程守护。如果 Java 进程 OOM 挂了,rc.local 不会拉起来。
最佳实践 #8:
rc.local适合「开机启动」这个场景,但不适合「进程守护」。生产环境建议用 systemd 的Restart=on-failure或 supervisord 做进程守护。如果坚持用 rc.local,至少配合一个 cron 定时检查进程存活并拉起。
七、变量管理:group_vars 的作用
# group_vars/all
jobname: core-amc-job_allauto
# hosts
172.18.199.134
应用名 jobname 放在 group_vars/all,所有主机组共享。目标主机写在 hosts 清单里。
这个设计很轻量——只有一个变量、一台主机。但它的价值在于应用名与部署逻辑解耦。要部署别的应用,只需:
- 改
group_vars/all里的jobname; - 把新应用的 jar 放到
roles/deploy/files/; - 改
hosts里的目标 IP。
Role 本身一行不用改。这就是 Ansible Role 可复用的核心——把变化的抽成变量,不变的写成逻辑。
进阶提示:如果要部署多个应用,可以改用
group_vars按应用分组,或用 inventory 的 host_vars 区分。当前的单变量设计适合「一个 Role 管一类应用」的场景。
八、踩坑清单与最佳实践总结
把整个项目能提炼的经验,浓缩成一份可复用的清单:
Ansible 编排
- 入口 playbook 只做声明,逻辑全在 Role 里,保持可复用可组合
- 幂等性靠
stat+register+when显式控制「首次/非首次」分支 - 修改配置文件用
lineinfile/template,不要用shell: echo >>(会重复追加) - CentOS 7+ 的
rc.local默认无执行权限,设开机启动前必须chmod +x
目录与权限
- 用四目录结构(runtime/package/rollback/backup)表达部署状态
- 目录权限分层:
bin//logs/用0755,制品目录用0750 - 创建专用运行用户(如 fjf),执行权和运行权分离
进程与生命周期
- 进程检测用
ps -C java+ jar 名匹配,注意「一机一应用」前提 - 启动用
daemon --user降权,不要以 root 跑应用 - 停止用两段式:SIGTERM + 超时 + SIGKILL,
shutdown_timeout大于最长优雅退出时间 - update 流程:先备份 → 存 rollback → 停止 → 替换 → 启动,保证每步可回退
- rollback 只允许回到上一版本,不支持连续回滚(安全设计)
服务治理
- 服务注销要「精准定位」,不能「无差别清理」(本项目的 Consul 脚本因风险被注释)
- 有问题的能力宁可先下线,宁缺毋滥
版本管理
- 用
mv而非rm + cp做版本替换(mv在同文件系统下原子) - rollback 目录只保留一个版本;backup 目录保留带时间戳的全量历史
- 应用名抽成变量(
group_vars),Role 逻辑保持应用无关
九、局限与演进方向
公平地说,这套方案有其适用边界,也有明显的演进空间:
当前局限
- 无进程守护:
rc.local只管开机启动,进程挂了不重启; - 无健康检查:启动判定只看进程存活,不看 HTTP 就绪;
- JVM 参数硬编码:
-Xms1024m -Xmx2048m写死在脚本里,不同应用无法独立调优; - 单机脚本,无滚动更新:多机部署靠 Ansible 逐台执行,会有短暂不可用窗口;
- 日志直接丢弃:
>/dev/null 2>&1丢弃了标准输出,完全依赖应用自身的日志框架。
演进路径
每一步演进都在解决上一层的局限,但也引入新的复杂度。rc.local + jar_app.sh 适合「裸机、少量应用、运维人力充足」的场景——它的好处是简单透明、排障容易、没有额外依赖。当应用数量增长、可用性要求提高时,再逐步演进到 systemd、配置中心、容器化。
不是所有团队都需要一步到位上 K8s。先用简单方案把部署规范化、可回滚,比盲目上云更有价值。这份 Ansible 项目就是「规范化裸机部署」的典型样本——它把「SCP + SSH 重启」升级成了「幂等初始化 + 版本管理 + 一键回滚」,投入产出比极高。
结语
这个项目不到 200 行 YAML + 一个 Shell 脚本,却实现了生产级部署该有的全部要素:幂等、可回滚、可审计、权限分离、状态可观测。它不是最先进的方案,但它是最适合裸机场景的成熟方案。
本文基于一个真实在产的 Ansible 部署项目整理。涉及的主机 IP、应用名等已做脱敏处理。设计原则适用于任何基于 Ansible 的裸机/VM Java 部署场景。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)