
02 | 基于现代C++完整实现一个低延迟交易系统
在本章中,我们将研究视频流、在线游戏、实时数据分析和电子交易等不同领域的一些应用。我们将了解它们的行为,以及在极低延迟的考量下哪些功能需要实时执行。我们还将介绍电子交易生态系统,因为在本书的其余部分,我们将以此为案例研究,用C++从头开始构建一个系统,重点是理解和运用低延迟理念。
在本章中,我们将涵盖以下主题:
- 理解直播视频流应用中的低延迟性能
- 了解在游戏应用中哪些低延迟约束很重要
- 讨论物联网(Internet-of-Things,IoT)和零售分析系统的设计
- 探索低延迟电子交易
本章的目标是深入探讨不同业务领域中低延迟应用的一些技术方面。在本章结束时,你应该能够理解和认识到实时视频流、离线和在线游戏应用、物联网设备和应用以及电子交易等应用所面临的技术挑战。你将能够了解技术进步所提供的不同解决方案,以解决这些问题,并使这些业务可行且有利可图。
理解直播视频流应用中的低延迟性能
在本节中,我们将首先讨论视频流应用中低延迟性能背后的细节。我们将定义与直播视频流相关的重要概念和术语,以建立对该领域和商业用例的理解。我们将了解这些应用中延迟产生的原因及其对业务的影响。最后,我们将讨论构建和支持低延迟视频流应用的技术、平台和解决方案。
定义低延迟流中的重要概念
在这里,我们将首先定义一些与低延迟流应用相关的重要概念和术语。让我们从一些基础知识开始,逐步深入到更复杂的概念。
视频流中的延迟
视频流被定义为实时或接近实时传输的音频视频内容。一般来说,延迟是指输入事件和输出事件之间的时间延迟。在直播视频流应用的背景下,延迟具体是指从直播视频流到达录制设备的摄像头,然后传输到目标观众的屏幕并在那里进行渲染和显示所花费的时间。不难直观理解,为什么在直播视频流应用中,这也被称为 “端到端延迟(glass-to-glass latency)”。无论实际应用是什么,无论是视频通话、其他应用的直播视频流还是在线视频游戏渲染,视频流应用中的端到端延迟都非常重要。在直播中,视频延迟基本上就是录制端捕获视频帧到观看端显示视频帧之间的延迟。另一个常见的术语是 “卡顿(lag)”,它通常指的是高于预期的端到端延迟,用户可能会感觉到性能下降或画面卡顿。
视频分发服务和内容交付网络
视频分发服务(Video Distribution Service,VDS)是一个听起来很专业,但实际上相对容易理解的概念。VDS基本上是指负责从源获取多个传入的视频和音频流,并将它们呈现给观众的系统。VDS最著名的例子之一就是内容交付网络(Content Delivery Network,CDN)。CDN是一种在全球范围内高效分发内容的方式。
转码、复用和码率转换
让我们讨论三个与音视频流编码相关的概念:
- 转码(Transcoding)是指将媒体流从一种格式(如编解码器、视频大小、采样率、编码器格式等较低级别的细节)解码,并可能以不同的格式或参数重新编码的过程。
- 复用(Transmuxing)与转码类似,但这里交付格式发生变化,而编码方式不变,不像转码那样改变编码。
- 码率转换(Transrating)也与转码类似,但我们改变视频的比特率;通常是将其压缩到较低的值。视频比特率是指每秒传输的比特数(或千比特数),它反映了视频流中的信息和质量。
在下一节中,我们将了解低延迟视频流应用中延迟的来源。
理解视频流应用中延迟的来源
让我们看看 “端到端旅程” 的详细情况。本节的主要目的是了解视频流应用中延迟的来源。下图大致描述了从摄像头到显示器的端到端旅程中发生的事情:
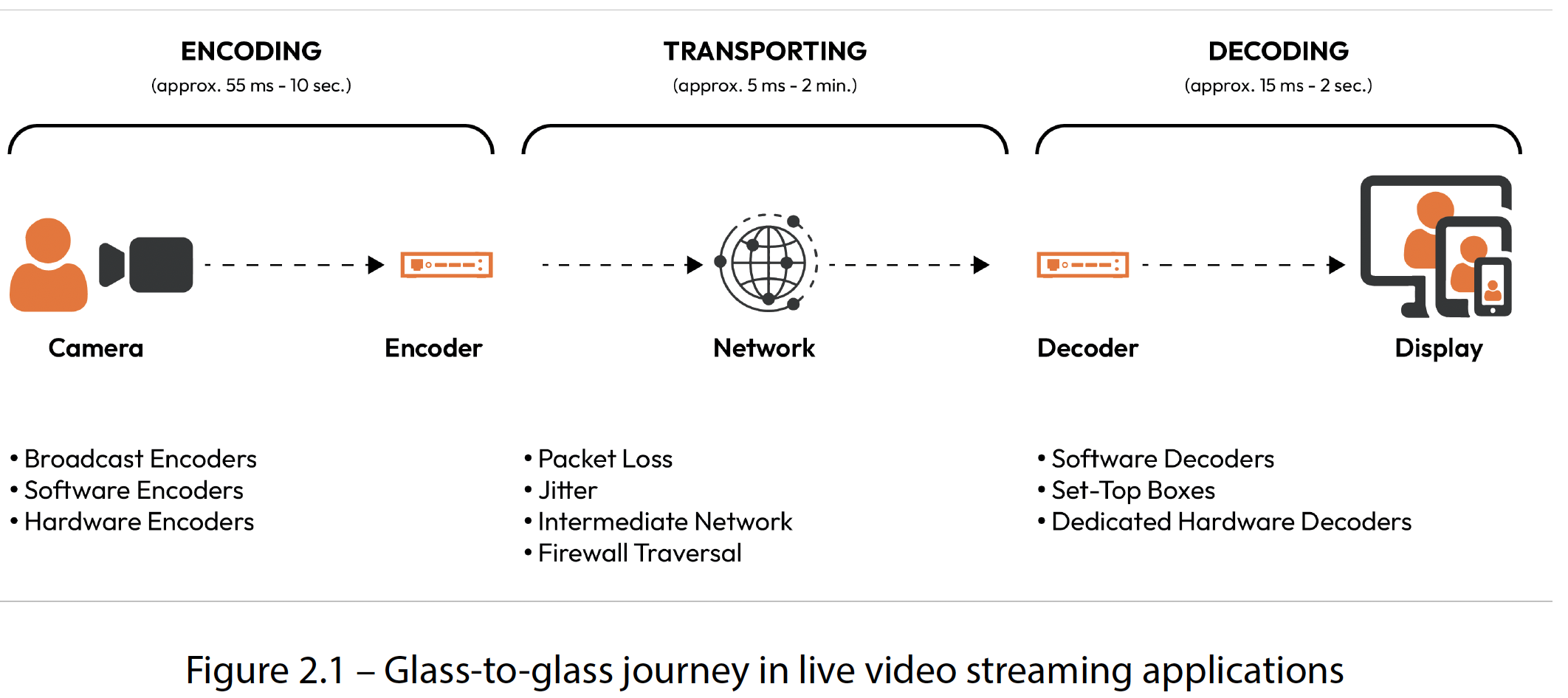
图2.1 直播视频流应用中的端到端旅程)
讨论端到端旅程中的步骤
我们将从了解低延迟视频流应用端到端旅程中涉及的所有步骤和组件开始。延迟有两种形式:初始启动延迟和直播开始后视频帧之间的延迟。通常对于用户体验来说,稍微长一点的启动延迟比视频帧之间的延迟更能被接受,但在尝试降低一种延迟时,通常需要在两者之间进行权衡。所以,我们需要了解对于特定用例哪个指标更重要,并相应地调整设计和技术细节。从广播端到接收端的端到端旅程的步骤如下:
- 广播端的摄像头捕获和处理音频和视频。
- 广播端对视频进行采集和打包。
- 编码器对内容进行转码、复用和码率转换。
- 通过适当的协议在网络上发送数据。
- 通过VDS(如CDN)进行分发。
- 接收端接收并缓冲数据。
- 在观众设备上解码内容。
- 在接收端处理数据包丢失、网络变化等问题。
- 在观众选择的设备上渲染音视频内容。
- 对于交互式应用,可能会从观众那里收集交互式输入(选择、音频、视频等),并在需要时将它们发送回广播端。
既然我们已经描述了从发送端到接收端,甚至可能再回到发送端的内容交付背后的细节,在下一节中,我们将描述在这条路径上可能出现延迟的地方。通常,每个步骤花费的时间并不长,但多个组件中的高延迟可能会累积起来,导致用户体验显著下降。
描述路径上出现高延迟的可能性
我们将研究低延迟视频流应用中出现高延迟的原因。在我们上一小节讨论的端到端路径的每个组件上,都有很多导致高延迟的原因。
物理距离、服务器负载和网络质量
- 这是一个显而易见的原因:源和目的地之间的物理距离会影响端到端延迟。当从不同国家流式传输视频时,这一点有时会非常明显。
- 除了距离之外,互联网连接本身的质量也会影响流媒体延迟。缓慢或带宽有限的连接会导致不稳定、缓冲和卡顿。
根据同时流式传输视频的用户数量以及这给流媒体路径中涉及的服务器带来的负载,延迟和用户体验会有所不同。服务器过载会导致响应时间变慢、延迟增加、缓冲和卡顿,甚至可能使流媒体完全停止。
捕获设备和硬件
视频和音频捕获设备对端到端延迟有很大影响。将音频和视频帧转换为数字信号需要时间。像录制设备、编码器、处理器、重新编码器、解码器和转发器等先进系统对最终用户体验有重大影响。捕获设备和硬件将决定延迟值。
流媒体协议、传输和抖动缓冲
鉴于有不同的流媒体协议可供选择(我们很快会讨论),最终的选择会决定视频流应用的延迟。如果协议没有针对动态自适应流媒体进行优化,可能会增加延迟。总体而言,直播视频流协议有两类:基于HTTP的和非基于HTTP的,这两种广泛选择在延迟和可扩展性方面存在差异,这会改变最终系统的性能。
通过VDS选择的互联网路由会改变端到端延迟。这些路由也可能随时间变化,数据包可能在某些节点排队,甚至可能无序到达接收端。处理这些问题的软件称为抖动缓冲器(jitter buffer)。如果CDN出现问题,也会导致额外的延迟。此外,还有编码比特率等限制因素(较低的比特率意味着单位时间内传输的数据较少,会导致较低的延迟),这些都会改变所遇到的延迟。
编码 - 转码和码率转换
编码过程决定了最终视频输出的压缩方式、格式等,编码协议的选择和质量将对性能产生巨大影响。此外,观众设备(电视、手机、个人电脑、苹果电脑等)和网络(3G、4G、5G、局域网、Wi-Fi等)有很多种选择,流媒体提供商需要实施自适应比特率(Adaptive Bitrate,ABR)来有效地处理这些情况。运行编码器的计算机或服务器需要有足够的CPU和内存资源,以便编码过程能够跟上传入的音视频数据。无论我们是在计算机上使用编码软件,还是使用BoxCaster或Teradek等编码硬件,都会产生从几毫秒到几秒不等的处理延迟。编码器需要执行的任务是摄取原始视频数据、缓冲内容,然后在转发之前对其进行解码、处理和重新编码。
在观众设备上解码和播放
假设内容在没有明显延迟的情况下到达观众设备,客户端仍然需要解码、播放和渲染内容。视频播放器不会在接收到视频片段时就立即逐个渲染,而是会在内存中设置一个已接收片段的缓冲区。这意味着在视频开始播放之前,会缓冲几个片段,根据所选片段的实际大小,这可能会在用户端造成延迟。例如,如果我们选择一个包含10秒视频的片段长度,用户端的播放器必须至少接收一个完整的片段才能播放,这会在发送端和接收端之间引入额外的10秒延迟。通常,这些片段的长度在2到10秒之间,试图在优化网络效率和端到端延迟之间取得平衡。显然,观众设备、平台、硬件、CPU、内存和播放器效率等因素都会增加端到端延迟。
测量低延迟视频流中的延迟
测量低延迟视频流应用中的延迟并不是特别复杂,因为我们关心的延迟范围至少要达到几秒,用户才能明显感觉到延迟或卡顿。测量端到端视频延迟的最简单方法如下:
- 首先可以使用场记板应用程序。场记板是电影制作过程中用于同步视频和音频的工具,现在有应用程序可以检测由于延迟导致的两个流之间的同步问题。
- 另一种选择是将视频流发布回自己,通过排除网络因素来测量捕获、编码、解码和渲染步骤中是否存在任何延迟。
- 一个显而易见的解决方案是对运行相同直播流的两个屏幕进行截图,以发现差异。
- 测量直播视频流延迟的最佳解决方案是在源端给视频流添加时间戳,然后接收端可以使用它来确定端到端延迟。显然,发送端和接收端使用的时钟需要有较好的同步。
理解高延迟的影响
在了解高延迟对低延迟视频流应用的影响之前,我们首先需要明确不同应用可接受的延迟是多少。对于那些对实时交互要求不高的视频流应用,延迟在5秒以内都是可以接受的。对于需要支持直播和交互场景的视频流应用,延迟在1秒以内就足以满足用户需求。显然,对于视频点播而言,延迟不是问题,因为它是预先录制的,不存在直播组件。总体来说,实时直播应用中的高延迟会对终端用户的体验产生负面影响。实时性的关键在于让观众有身临其境的感觉,而接收和渲染内容时出现的较大延迟会破坏这种实时观看的体验。最让观众厌烦的体验之一,就是实时视频因延迟而频繁暂停和缓冲。
下面我们简要讨论一下延迟给实时视频流应用带来的主要负面影响。
音视频质量低下
如果视频流系统的组件无法实现实时延迟,通常会导致更高程度的压缩。由于对音视频数据进行了高度压缩,音频质量有时会听起来嘈杂刺耳,视频质量则可能模糊且出现像素化,整体用户体验较差。
缓冲暂停和延迟
缓冲是最影响用户体验的问题之一,因为观众会感受到画面卡顿,频繁暂停,无法获得流畅的观看体验。如果视频不断暂停缓冲,观众会感到非常沮丧,这很可能导致观众放弃观看该视频、离开该平台,甚至不再选择相关业务。
音视频同步问题
在许多实时音视频流应用的实现中,音频数据和视频数据是分开发送的,因此音频数据可能比视频数据更快到达接收端。这是因为音频数据本身比视频数据的大小要小,并且由于高延迟,视频数据在接收端可能会落后于音频数据。这就会导致同步问题,影响观众的实时视频流观看体验。
播放——倒带和快进
即使应用并非完全实时,高延迟也可能导致倒带和快进出现问题。这是因为音视频数据必须重新发送,以便终端用户的播放器能够与新选择的位置重新同步。
探索低延迟视频流技术
在本节中,我们将探讨适用于音视频数据编码、解码、流传输和分发的不同技术协议。这些协议是专门为低延迟视频流应用和平台设计的。这些协议大致可分为两类——基于HTTP的协议和非基于HTTP的协议。但对于低延迟视频流而言,通常基于HTTP的协议是更好的选择,这一点我们将在本节中详细讨论。
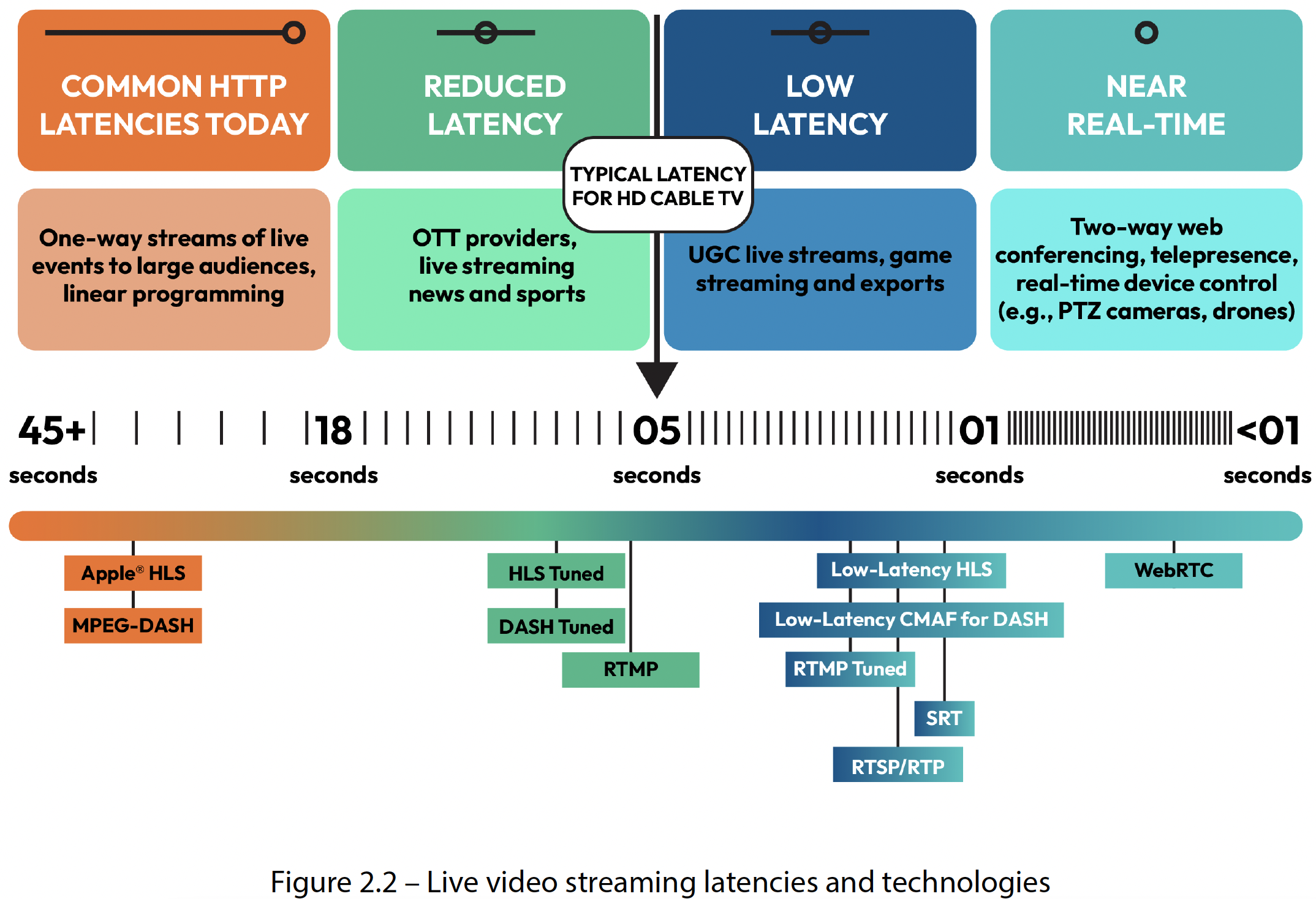
图2.2——实时视频流延迟和技术
非基于HTTP的协议
非基于HTTP的协议结合使用用户数据报协议(UDP,User Datagram Protocol )和传输控制协议(TCP,Transmission Control Protocol)将数据从发送方传输到接收方。这些协议可用于低延迟应用,但许多协议对自适应流技术的支持并不先进,且可扩展性有限。实时流协议(RTSP,Real-Time Streaming Protocol )和实时消息协议(RTMP,Real-Time Messaging Protocol )就是这类协议的两个例子,下面我们将对它们进行讨论。
RTSP
RTSP是一种应用层协议,曾用于低延迟视频流传输。它还具备播放功能,允许播放和暂停视频内容,并且可以处理多个数据流。然而,如今它已不再流行,被其他更现代的协议所取代,我们将在后面的章节中介绍这些协议。RTSP被HLS和DASH等现代协议所取代,是因为许多接收端不支持RTSP,它与HTTP不兼容,并且随着基于网络的流应用的出现而逐渐失宠。
Flash和RTMP
曾经,基于Flash的应用非常受欢迎。它们使用RTMP,在低延迟流场景中表现良好。然而,由于多种原因,主要是安全相关的问题,Flash技术的受欢迎程度大幅下降。网络浏览器和内容分发网络(CDN,Content Delivery Network)都不再支持RTMP,因为随着需求的增长,它的扩展性不太理想。RTMP是一种流协议,能够实现低延迟流传输,但正如前面提到的,它现在正被其他技术所取代。
基于HTTP的协议
基于HTTP的协议通常将连续的音视频数据流分解为长度在2到10秒之间的小片段。然后,这些片段通过内容分发网络(CDN)或网络服务进行传输。这些协议是低延迟直播应用的首选,因为它们不仅延迟可接受,而且功能丰富,扩展性更好。不过,这些协议也有我们之前提到的一个缺点:产生的延迟取决于片段的长度。最小延迟至少是片段的长度,因为接收端需要至少接收完整的一个片段后才能播放。在某些情况下,根据视频播放设备的实现方式,延迟可能是片段长度的数倍。例如,iOS系统在播放第一个片段之前,至少会缓存三到五个片段,以确保渲染流畅。
一些基于HTTP的协议示例如下:
- HTTP实时流(HTTP Live Streaming,HLS)
- HTTP动态流(HTTP Dynamic Streaming,HDS)
- 微软平滑流(Microsoft Smooth Streaming,MSS)
- HTTP动态自适应流(Dynamic Adaptive Streaming over HTTP,DASH)
- 通用媒体应用格式(Common Media Application Format,CMAF)
- 高效流协议(High-Efficiency Stream Protocol,HESP)
在本节中,我们将讨论其中一些协议,以了解它们的工作原理,以及它们如何在实时视频流应用中实现低延迟性能。总体而言,这些协议旨在扩展到支持数百万个同时接收者,并支持自适应流和播放功能。基于HTTP的流协议通过标准HTTP协议进行通信,并且需要服务器进行分发。相比之下,我们稍后将探讨的网络实时通信(WebRTC,Web Real-Time Communication )是一种对等(P2P,Peer-to-Peer )协议,从技术上讲,它可以在两台机器之间建立直接通信,无需中间机器或服务器。
HLS
HLS既用于实时音视频内容传输,也用于视频点播,并且具有很好的扩展性。视频传输平台通常会将RTMP转换为HLS。同时使用RTMP和HLS是实现低延迟并向所有设备进行流传输的最佳方式。低延迟HLS(LL-HLS,Low Latency HLS )的变体可以将延迟降低到2秒以内,但仍处于实验阶段。LL-HLS通过利用对流和渲染部分片段的能力,而非要求完整片段,实现了低延迟实时音视频流传输。HLS和LL-HLS作为应用最广泛的自适应比特率(ABR,Adaptive Bitrate )流协议,其成功源于对大量用户的可扩展性,以及与大多数类型的设备、浏览器和播放器的兼容性。
CMAF
CMAF相对较新;严格来说,它并不是一种全新的格式,而是对各种视频流协议进行打包和交付。它与HLS和DASH等基于HTTP的协议协同工作,对视频片段进行编码、打包和解码。这通常有助于企业降低存储成本和音视频流延迟。
DASH
DASH是由运动图像专家组(MPEG,Moving Picture Experts Group )的工作成果发展而来,是我们之前讨论的HLS协议的替代方案。它与HLS非常相似,因为它也准备了不同质量级别的音视频内容,并将其划分为小片段,以实现自适应比特率流传输。在底层,DASH仍然依赖CMAF,具体来说,它依赖的一个特性是分块编码,这有助于将一个片段分解为几毫秒的更小的子片段。它依赖的另一个特性是分块传输编码,该特性将发送到分发层的这些子片段进行实时分发。
HESP
HESP是另一种基于HTTP的自适应比特率流协议。该协议有着雄心勃勃的目标,即实现超低延迟、提高可扩展性、支持当前流行的内容分发网络(CDN)、降低带宽需求,以及减少流切换时间(即开始新的音视频流的延迟)。由于它的延迟极低(小于500毫秒),因此是WebRTC协议的竞争对手,但HESP的成本可能较高,因为它不是开源协议。
从根本上讲,HESP与其他协议的主要区别在于它依赖两个流而不是一个流。其中一个流(仅包含关键帧或快照帧)被称为初始化流。另一个流包含对初始化流中的帧进行增量更改的数据,这个流被称为延续流。因此,虽然初始化流中的关键帧包含快照数据,需要更高的带宽,但它们支持在播放过程中快速定位视频中的各个位置。而延续流的带宽较低,因为它只包含变化数据,一旦接收端的视频播放器与初始化流同步,就可以快速播放。
虽然从理论上讲,HESP听起来很完美,但它也有一些缺点,例如编码和存储两个流而不是一个流的成本更高,需要对两个流进行编码和分发,并且需要更新接收端平台上的播放器以解码和渲染这两个流。
WebRTC
WebRTC被视为实时视频流行业的新标准,它的延迟可以低至1秒以内,因此可以在大多数平台和几乎所有浏览器(如Safari、Chrome、Opera、Firefox等)上播放。它是一种对等(P2P)协议,即它在设备或流应用之间创建直接通信通道。WebRTC的一个很大优势是它不需要额外的插件来支持音视频流和播放。它还支持双向实时音视频流的自适应比特率和自适应视频质量更改。尽管WebRTC使用对等协议,可以为视频会议建立直接连接,但性能仍然取决于硬件和网络质量,因为无论是否是对等协议,这对所有协议来说都是需要考虑的因素。
WebRTC确实面临一些挑战,例如需要自己的多媒体服务器基础设施,需要对交换的数据进行加密,需要安全协议来处理UDP协议的漏洞,需要以经济高效的方式在全球范围内扩展,以及处理WebRTC所集成的多种协议带来的工程复杂性。
探索低延迟流的解决方案和平台
在本节中,我们将探索一些最受欢迎的低延迟视频流解决方案和商用平台。这些平台基于我们在上一节讨论的所有技术,来解决实时音视频流应用中与高延迟相关的许多业务问题。请注意,这些平台中的许多都支持并使用多种底层流协议,但我们将提及它们主要使用的协议。
Twitch
Twitch是一个非常受欢迎的在线平台,主要被想要实时直播游戏玩法并通过聊天、评论、捐赠等方式与目标受众互动的视频游戏玩家使用。不言而喻,这需要低延迟流以及扩展到大型社区的能力,而Twitch提供了这些功能。Twitch使用实时消息传输协议(RTMP,Real Time Messaging Protocol)满足其广播需求。
Zoom
Zoom是在新冠疫情和居家办公时代迅速走红的实时视频会议平台之一。Zoom提供几乎无延迟的实时低延迟音频和视频会议服务,并支持众多用户同时在线。它还提供诸如视频会议期间的屏幕共享和群聊等功能。Zoom主要使用Web实时通信(WebRTC,Web Real-Time Communication)流协议技术。
Dacast
Dacast是一个用于直播活动的平台,尽管它的延迟不像其他一些实时流应用那么低,但在广播方面仍具有可接受的性能。它价格实惠且运行良好,但不支持很多交互式工作流程。Dacast也使用RTMP流协议。
Ant Media Server
Ant Media Server使用WebRTC技术提供极低延迟的视频流平台,旨在企业内部部署或云端使用。它还用于实时视频监控和基于监视的应用程序,这些应用程序的核心需要实时视频流。
Vimeo
Vimeo是另一个非常受欢迎的视频流平台,虽然它不是业内速度最快的,但仍被广泛使用。它主要用于承载实时活动直播和点播视频分发应用。Vimeo默认使用RTMP流,但也支持包括HLS(HTTP Live Streaming)在内的其他协议。
Wowza
Wowza在在线实时视频流领域已经存在很长时间,非常可靠且应用广泛。索尼(Sony)、Vimeo和Facebook等许多大公司都在使用它,它专注于大规模地为商业和企业层面提供视频流服务。Wowza是另一个使用RTMP流协议技术的平台。
Evercast
Evercast是一个超低延迟的流平台,在协作内容创建和编辑应用以及直播应用中有着广泛的用途。由于它能够支持超低延迟性能,多个协作者能够实时共享他们的工作区,创造一个实时协作编辑的环境。近年来,由于新冠疫情、远程工作与协作以及在线协作教育系统的兴起,这类用例的需求激增。Evercast在其流服务器上主要使用WebRTC。
CacheFly
CacheFly是另一个为直播活动广播提供实时视频流的平台。它提供个位数秒的可接受低延迟,并且在实时音视频广播应用中扩展性很好。CacheFly使用基于自定义Websocket的端到端流解决方案。
Vonage Video API
Vonage Video API(以前称为TokBox)是另一个提供实时视频流功能的平台,面向大公司,以支持企业级应用。它支持数据加密,这使得它成为寻求在线音视频会议、会议和培训的企业、公司和医疗保健公司的首选。Vonage使用RTMP和HLS作为其广播技术。
开源广播软件(Open Broadcast Software,OBS)
OBS是另一个低延迟视频流平台,而且它是开源的,这使得它在许多可能因企业级解决方案成本过高而却步的圈子中很受欢迎。许多直播各种内容的主播都在使用OBS,甚至像Facebook Live和Twitch这样的平台也使用了OBS的一些部分。OBS支持多种协议,如RTMP和安全可靠传输(SRT,Secure Reliable Transport)。
到此,我们结束了对实时视频流应用低延迟考虑因素的讨论。接下来,我们将转向视频游戏应用,与实时视频流应用相比,它们有一些共同特征,尤其是在在线视频游戏方面。
理解游戏应用中低延迟的关键限制因素
自20世纪60年代诞生以来,视频游戏已经发生了巨大的变化。如今,视频游戏不再局限于独自游玩,甚至也不只是与身边的人一起玩或对战。如今,游戏涉及全球各地的众多玩家,而且这些游戏的质量和复杂性也大幅提升。毫不奇怪,对于现代游戏应用来说,超低延迟和高可扩展性是不可或缺的要求。随着增强现实(AR,Augmented Reality)和虚拟现实(VR,Virtual Reality)等新技术的出现,对超低延迟性能的需求进一步增加。此外,随着移动游戏与在线游戏的融合,复杂的游戏应用被移植到智能手机上,这就需要超低延迟的内容交付系统、多人游戏系统和超快的处理速度。
在上一节中,我们详细讨论了低延迟实时视频流应用,包括交互式的流应用。在本节中,我们将探讨视频游戏应用中的低延迟考虑因素、高延迟的影响以及实现低延迟性能的技术。由于许多现代视频游戏要么是在线的,要么是云游戏,或者由于多人游戏功能而具有很强的在线属性,所以我们在上一节学到的很多内容在这里仍然很重要。对于游戏应用来说,实时流式传输和渲染游戏、防止延迟以及快速有效地响应玩家互动是必要的。此外,还有一些额外的概念、注意事项和技术可以最大限度地提高低延迟游戏性能。
低延迟游戏应用中的概念
在了解高延迟对游戏应用的影响以及如何降低这些应用中的延迟之前,我们将定义并解释一些与游戏应用及其性能相关的概念。对于低延迟游戏应用来说,最重要的概念是刷新率、响应时间和输入延迟。这些应用的主要目标是最小化玩家与玩家在屏幕上控制的角色之间的延迟。实际上,这意味着任何用户输入都能立即在屏幕上反映出效果,并且由于游戏环境导致的角色任何变化都能立即在屏幕上呈现出来。当游戏过程感觉非常流畅,玩家感觉自己真的置身于屏幕上呈现的游戏世界中时,就实现了最佳的用户体验。现在,让我们来讨论一下低延迟游戏应用中的重要概念。
延迟(Ping)
在计算机科学和在线视频游戏应用中,延迟指的是数据从用户计算机发送到服务器(或者可能是另一个玩家的计算机),再到数据返回到原始用户计算机所花费的时间。通常,延迟的大小取决于应用程序;对于低延迟的电子交易,延迟通常在几百微秒,而对于游戏应用,通常是几十到几百毫秒。延迟基本上衡量的是在服务器或客户端机器没有任何处理延迟的情况下,服务器和客户端之间通信的速度。
游戏应用对实时性的要求越高,所需的延迟时间就越低。这在诸如第一人称射击游戏(FPS,First-Person Shooter)、体育和赛车游戏中通常是必需的,而其他游戏,如大型多人在线游戏(MMO,Massively Multiplayer Online)和一些即时战略游戏(RTS,Real-Time Strategy)则可以容忍较高的延迟。游戏界面本身通常具有显示延迟功能或实时显示延迟统计信息。一般来说,50到100毫秒是可接受的延迟时间,超过100毫秒可能会在游戏过程中导致明显的延迟,而更高的延迟会严重降低玩家的体验,使游戏难以进行。通常,小于25毫秒是实现良好响应、清晰视觉渲染和无游戏卡顿的理想延迟。
每秒帧数(Frames per second,FPS)
FPS(不要与第一人称射击游戏混淆)是在线游戏应用中的另一个重要概念。FPS衡量显卡每秒可以渲染多少帧或图像。FPS也可以用来衡量显示器硬件本身(即显示器硬件每秒可以显示或更新多少帧)。较高的FPS通常会使游戏世界的渲染更加流畅,用户对输入和游戏事件的体验也会感觉更灵敏。较低的FPS会使游戏和渲染感觉生硬、卡顿和闪烁,总体上会大大降低玩家的游戏体验和接受度。
对于一款游戏来说,要能正常运行甚至可玩,30 FPS是最低要求,这可以支持主机游戏和一些PC游戏。只要FPS保持在20 FPS以上,这些游戏就可以继续正常游玩,不会有明显的卡顿和性能下降。对于大多数游戏来说,60 FPS或更高是理想的性能范围,大多数显卡、PC、显示器和电视都能轻松支持。超过60 FPS之后,下一个目标是120 FPS,这只有在连接到支持至少144Hz刷新率的显示器的高端游戏硬件上才需要且能够实现。再往上,240 FPS是可达到的最高帧率,需要搭配240Hz刷新率的显示器。这种高端配置通常只有最狂热的游戏玩家才会需要。
刷新率
刷新率是一个与FPS密切相关的概念,尽管从技术上讲它们略有不同,但它们确实相互影响。刷新率衡量屏幕刷新的速度,并影响硬件可以支持的最大FPS。与FPS一样,刷新率越高,在游戏过程中屏幕上的动画运动渲染过渡就越平滑。最大刷新率限制了可实现的最大FPS,因为即使显卡的渲染速度比显示器屏幕的刷新速度快,此时的瓶颈就变成了显示器屏幕的刷新率。当FPS超过刷新率时,我们会遇到一种显示问题,称为画面撕裂(Screen tearing)。画面撕裂是指显卡(GPU)与显示器不同步,在某些情况下,显示器会在当前帧之上绘制一个不完整的帧,导致屏幕上出现部分帧和完整帧重叠的水平或垂直分割。这虽然不会完全破坏游戏体验,但如果偶尔出现,至少会分散玩家注意力;如果频繁出现,则会完全破坏游戏的视觉质量。有多种处理画面撕裂的技术,我们很快就会介绍,比如垂直同步(V-Sync)、自适应同步(Adaptive Sync)、FreeSync、Fast Sync、G-Sync和可变刷新率(VRR,Variable Refresh Rate)。
输入延迟
输入延迟衡量的是从用户产生输入(如按键、鼠标移动或鼠标点击)到该输入的响应在屏幕上呈现所花费的时间。这基本上是硬件和游戏对用户输入和交互的响应速度。显然,对于所有游戏来说,这个值都不为零,它是硬件本身(控制器、鼠标、键盘、网络连接、处理器、显示器等)或游戏软件本身(处理输入、更新游戏和角色状态、调度图形更新、通过显卡渲染并刷新显示器)延迟的总和。当输入延迟较高时,游戏会感觉反应迟钝和卡顿,这会影响玩家在多人游戏或在线游戏中的表现,甚至会让用户完全无法享受游戏。
响应时间
响应时间常被误认为是输入延迟,但它们是不同的概念。响应时间指的是像素响应时间,基本上是指像素改变颜色所需的时间。输入延迟会影响游戏的响应速度,而响应时间则会影响屏幕上渲染动画的模糊程度。直观地说,如果像素响应时间较长,在屏幕上渲染运动或动画时,像素改变颜色所需的时间就会更长,从而导致画面模糊。较低的像素响应时间(1毫秒或更低),即使对于有快速镜头移动的游戏,也能带来清晰锐利的图像和动画质量。像第一人称射击游戏和赛车游戏就是很好的例子。当响应时间较长时,我们会遇到一种称为 “拖影(ghosting)” 的现象,即当有运动发生时,痕迹和残影会在屏幕上慢慢消失。通常情况下,拖影和较高的像素响应时间不是问题,现代硬件很容易实现小于5毫秒的响应时间,渲染出清晰的动画。
网络带宽
网络带宽对在线游戏应用程序的影响与对实时视频流应用程序的影响相同。带宽衡量的是每秒可以从游戏应用服务器上传或下载多少兆比特的数据。带宽还会受到数据包丢失的影响,我们接下来会讲到,而且它会因玩家的位置以及他们连接的游戏服务器不同而有所变化。在考虑网络带宽时,还有一个概念是 “竞争(Contention)”。竞争衡量的是有多少个用户同时尝试访问同一服务器或共享资源,以及这是否会导致服务器过载。
网络数据包丢失和抖动
网络数据包丢失是网络传输中不可避免的问题。网络数据包丢失会降低有效带宽,并引发重传和恢复协议,这会带来额外的延迟。一定程度的数据包丢失是可以容忍的,但当网络数据包丢失率非常高时,会降低在线游戏应用程序的用户体验,甚至会使游戏无法进行。抖动与数据包丢失类似,只不过在这种情况下,数据包是无序到达的。这会在用户端的游戏软件中引入额外的延迟,因为接收方必须保存无序到达的数据包,等待尚未到达的数据包,然后再按顺序处理这些数据包。
网络协议
在网络协议方面,主要有两种用于在互联网上传输数据的协议:传输控制协议(TCP,Transmission Control Protocol )和用户数据报协议(UDP,User Datagram Protocol)。TCP通过跟踪成功交付给接收方的数据包,并具备重传丢失数据包的机制,提供了一种可靠的传输协议。在应用程序不能容忍数据包和信息丢失的情况下,其优势显而易见。缺点是,这些检测和处理数据包丢失的额外机制会导致额外的延迟(额外的毫秒数),并且会降低可用带宽的使用效率。必须依赖TCP的应用程序示例有在线购物和网上银行,在这些场景中,确保数据正确传输至关重要,即使传输有所延迟。UDP则侧重于确保数据尽快传输,并更有效地利用带宽。然而,它是以不保证数据包的交付甚至不保证数据包按顺序交付为代价的,因为它没有重传丢失数据包的机制。UDP适用于那些可以容忍一定数据包丢失而不会完全崩溃,并且相比延迟的信息更能接受丢失部分信息的应用程序。这类应用程序的一些例子有实时视频流和在线游戏应用程序的某些组件。例如,在线视频游戏中的一些视频组件或渲染组件可以通过UDP传输,但一些组件,如用户输入以及游戏和玩家状态更新,则需要通过TCP发送。
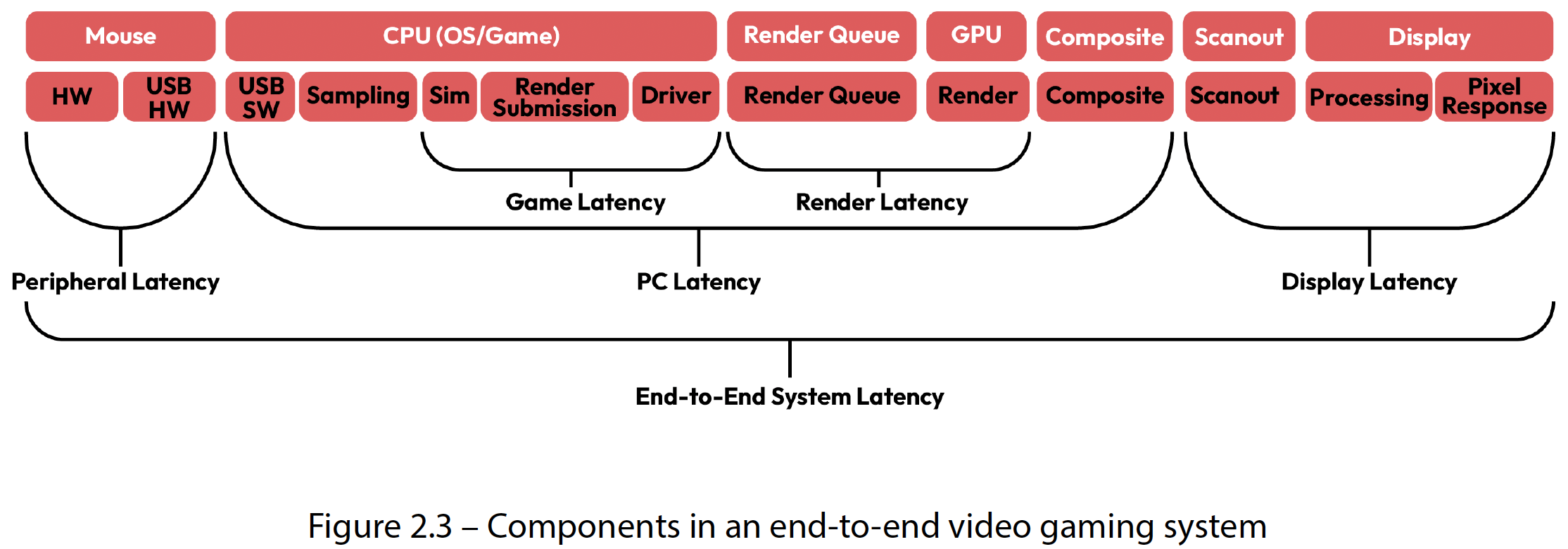
图2.3 端到端视频游戏系统中的组件
提高游戏应用程序性能
在上一节中,我们讨论了一些适用于低延迟游戏应用程序的概念,以及它们对应用程序和用户体验的影响。在本节中,我们将深入探讨游戏应用程序高延迟的来源,并讨论可以采取哪些措施来降低游戏应用程序的延迟,提高性能,从而提升用户体验。
从开发者角度优化游戏应用程序
首先,我们来看看游戏开发者优化游戏应用程序性能的方法和技术。让我们快速介绍一些开发者采用的优化技术,其中一些适用于所有应用程序,而一些仅适用于游戏应用程序。
管理内存、优化缓存访问和优化关键路径
与其他低延迟应用程序一样,游戏应用程序必须高效利用可用资源,最大化运行时性能。这包括正确管理内存以避免内存泄漏,尽可能多地进行预分配和预初始化。在关键路径上避免使用垃圾回收以及动态内存分配和释放等机制,对于达到特定的运行时性能预期也很重要。这对游戏应用程序尤为重要,因为视频游戏中有很多对象,特别是那些构建和处理大型游戏世界的对象。
大多数低延迟应用程序的另一个重要方面是尽可能高效地使用数据和指令缓存。游戏应用程序也不例外,尤其是考虑到它们必须处理大量数据。
包括游戏应用程序在内的许多应用程序,大部分时间都花在关键循环中。对于游戏应用程序来说,这个循环可能是检查输入、根据物理引擎更新游戏状态和角色状态,以及在屏幕上进行渲染和生成音频输出。游戏开发者通常会花大量时间关注在这个关键路径上执行的操作,就像我们处理任何在紧密循环中运行的低延迟应用程序一样。
视锥体裁剪(Frustum culling)
在计算机图形学中,视锥体(view frustum)是指当前在屏幕上可见的游戏世界部分。视锥体裁剪是指确定哪些对象在屏幕上可见,并仅在屏幕上渲染这些对象的技术。换一种方式理解,大多数游戏引擎都会尽量减少用于处理屏幕外对象的处理能力。这通常是通过将对象的显示或渲染功能与其数据和逻辑管理(如位置、状态、下一步动作等)分离来实现的。消除渲染当前不在屏幕上的对象的开销,可以将处理成本降低到原来的一小部分。另一种实现这种分离的方法是,为对象提供一个在屏幕上时使用的更新方法,以及一个在屏幕外时使用的更新方法。
缓存计算结果和使用数学近似法
这是一种易于理解的优化技术,适用于需要进行大量复杂数学计算的应用程序。游戏应用程序在其物理引擎中尤其需要进行大量数学计算,对于拥有大型游戏世界和众多对象的3D游戏来说更是如此。在这种情况下,会使用一些优化技术,如缓存计算值而不是每次都重新计算、使用查找表以内存使用换取CPU使用来查找值,以及使用数学近似法代替计算成本高昂但极为精确的表达式。这些优化技术在视频游戏领域已经使用了很长时间,因为长期以来硬件资源极其有限,开发这类系统需要依赖这些技术。
id Software的光线投射引擎(它开创并支持了《德军总部》《毁灭战士》《雷神之锤》等游戏)是早期低延迟软件开发的杰出杰作。另一个例子是在横版过关游戏或俯视视角射击游戏中,屏幕上有很多敌人,但很多敌人具有相似的移动模式,可以重复使用而无需重新计算。
优先处理关键任务并利用CPU空闲时间
在大型游戏世界中处理众多对象的游戏引擎,通常有很多对象需要频繁更新。游戏引擎不应在每一帧更新时都更新每个对象,而需要对关键部分中需要执行的任务进行优先级排序(例如,自上一帧以来视觉属性发生了变化的对象)。一种简单的实现方法是,为每个对象提供一个成员方法,游戏引擎可以使用该方法检查自上一帧以来对象是否发生了变化,并对这些对象的更新进行优先级排序。例如,一些游戏组件,如场景(静态环境对象、天气、光照等)和抬头显示器(HUD,heads-up display ),更新频率并不高,并且通常只有极其有限的动画序列。与更新这些组件相关的任务,优先级略低于其他一些游戏组件。
将任务分为高优先级和低优先级任务,还意味着游戏引擎可以通过确保在所有硬件和游戏设置下都执行高优先级任务,来保证良好的游戏体验。如果游戏引擎检测到CPU有大量空闲时间,它可以添加一些额外的低优先级功能(如粒子引擎、光照、阴影、大气效果等)。
根据图层、深度和纹理对绘制调用进行排序
游戏引擎需要确定向显卡发出哪些渲染或绘制调用。为了优化性能,目标不仅是尽量减少发出的绘制调用数量,还要对这些绘制调用进行排序和分组,以实现最佳执行效果。在向屏幕渲染对象时,我们必须考虑以下图层或因素:
- 全屏图层:包括抬头显示器、游戏图层、半透明效果图层等。
- 视口图层:如果有镜子、传送门、分屏等情况,就会存在视口图层。
- 深度因素:我们需要按从后到前或从最远到最近的顺序绘制对象。
- 纹理因素:包括纹理、阴影、光照等。
对于这些不同图层和组件的排序,以及绘制调用发送到显卡的顺序,有很多决策要做。例如,对于半透明对象,可能会按从后到前的顺序排序(即先按深度排序,再按纹理排序)。对于不透明对象,则可能先按纹理排序,并省略位于不透明对象后面的对象的绘制调用。
从玩家角度优化游戏应用程序
对于游戏应用程序而言,很多性能表现取决于终端用户的硬件、操作系统以及游戏设置。本节将介绍终端用户在不同设置和不同资源条件下,为最大化游戏性能可以采取的一些措施。
升级硬件
提升游戏应用性能的第一个明显方法是升级终端用户运行游戏的硬件。其中比较重要的有游戏显示器、鼠标、键盘和控制器。高刷新率的游戏显示器(比如支持1920×1080像素分辨率的360Hz显示器,以及支持2560×1440像素分辨率的240Hz显示器)能够提供高质量的渲染效果和流畅的动画,增强游戏体验。我们还可以使用具有极高轮询率的鼠标,这样点击和移动操作的响应速度比以前更快,能够减少延迟和卡顿。同样,对于键盘来说,游戏键盘的轮询率要高得多,可以提高响应速度,这在需要频繁按键的游戏中(比如即时战略游戏)尤为明显。另外需要提到的是,使用特定主机和平台官方的、口碑好的控制器通常能获得最佳性能。
游戏显示器刷新率
我们之前已经多次讨论过这个方面。随着高质量图像和动画的兴起,游戏显示器自身的质量和性能变得相当重要。关键在于要选择刷新率高且像素响应时间短的显示器,这样动画能够快速且流畅地渲染和更新。显示器的配置还必须避免我们之前提到的画面撕裂、拖影和模糊等问题。
升级显卡
升级显卡是另一个能显著提升性能的选择,它可以提高帧率,进而改善游戏表现。英伟达(NVIDIA)发现,在某些情况下,升级显卡和GPU驱动程序可以帮助提升超过20%的游戏性能。英伟达的GeForce系列、ATI的Radeon系列、英特尔的HD Graphics等都是很受欢迎的显卡供应商,它们提供的更新优化驱动程序可以根据用户平台上安装的显卡来提升游戏性能。
对显卡进行超频
除了升级GPU或作为其替代方案,另一个可能的性能提升途径是尝试对GPU进行超频以增加每秒帧数(FPS)。对GPU进行超频是通过提高其频率来最终提高GPU的FPS输出。不过,对GPU超频的一个缺点是会使内部温度升高,在极端情况下可能导致过热。所以在超频时,应该监测温度变化,逐步提高超频幅度,并在过程中持续监测,同时要确保电脑、笔记本电脑或主机有足够的散热措施。对GPU进行超频大约能提升10%的性能。
升级内存
这是另一个显而易见的通用优化方法,同样适用于低延迟游戏应用。给电脑、智能手机、平板电脑或主机增加额外的内存,可以让游戏应用和图形渲染任务发挥出最佳性能。值得庆幸的是,在过去十年里,内存价格大幅下降,所以这是一种很容易提升游戏应用性能的方法,强烈推荐使用。
调整硬件、操作系统和游戏设置
在上一小节中,我们讨论了一些通过升级硬件资源来提升游戏应用性能的方法。在本小节中,我们将探讨针对硬件、平台、操作系统以及游戏本身的设置进行优化,从而进一步提升游戏应用的性能。
启用游戏模式
游戏模式是高端电视和类似的高端显示器所具备的一种设置。启用游戏模式会禁用显示器的一些额外功能,这些功能虽然能提升图像和动画质量,但会带来更高的延迟。启用游戏模式会使图像质量略有下降,但可以通过减少渲染延迟来提升低延迟游戏应用的终端用户体验。比如Windows 10系统中的Windows游戏模式,启用后就能优化游戏性能。
使用高性能模式
我们这里所说的高性能模式指的是电源设置。不同的电源设置会在电池使用和性能之间进行优化;高性能模式比低性能模式消耗电池电量更快,可能也会使内部温度升得更高,但它可以提升正在运行的应用程序的性能。
延迟自动更新
自动更新是Windows系统中一项广为人知的功能,它会自动下载并安装安全补丁。虽然这通常不是什么大问题,但如果在我们进行在线游戏时开始下载并安装一个较大的自动更新,就可能会影响游戏性能和体验。如果自动更新与高处理器使用率和高带宽占用的游戏时段重合,会导致处理器使用率和带宽消耗飙升,进而降低游戏性能。所以,在运行对延迟敏感且资源消耗大的游戏应用时,关闭或延迟Windows自动更新通常是个不错的主意。
关闭后台服务
这是与我们刚刚讨论的延迟自动更新类似的另一个优化选项。我们可以找到并关闭那些可能在后台运行,但对于低延迟游戏运行并非必需的应用和服务。实际上,关闭这些应用和服务可以避免它们在游戏过程中意外且不确定地占用硬件资源。这样就能将最多的资源提供给游戏应用,从而最大化低延迟游戏应用的性能。
使帧率达到或超过刷新率
我们之前讨论过画面撕裂的概念,所以为了避免这种情况,我们至少需要一个帧率达到或超过刷新率的系统。像FreeSync和G-Sync这样的技术可以在保持低延迟性能的同时实现流畅的渲染,避免画面撕裂。当帧率超过刷新率时,延迟会继续保持较低水平,但如果帧率大幅超过刷新率,画面撕裂可能会再次出现。可以通过使用垂直同步(V-Sync)技术或有意限制帧率来解决这个问题。FreeSync和G-Sync需要硬件支持,所以你需要一个兼容的GPU才能使用这些技术。不过,使用FreeSync和G-Sync的好处是你可以完全禁用会引入延迟的V-Sync,只要有相应的硬件支持,就能获得低延迟且无画面撕裂的渲染体验。
禁用三重缓冲和V-Sync并仅在全屏模式下运行
我们之前解释过,由于需要使GPU渲染的帧与显示设备同步,V-Sync会引入额外的延迟。三重缓冲是V-Sync的另一种形式,其目的同样是减少画面撕裂。当游戏在窗口模式下运行(即游戏在一个窗口内而不是全屏运行)时,三重缓冲的作用尤为明显。这里的关键是,为了通过禁用V-Sync和三重缓冲来降低延迟并提升性能,我们必须仅在全屏模式下运行游戏。
为实现低延迟和高帧率优化游戏设置
现代游戏提供了大量的选项和设置,旨在最大化性能(有时可能会以牺牲渲染质量为代价),终端用户可以根据目标硬件、平台、网络资源和性能需求来优化这些参数。降低抗锯齿等设置就是一个例子,降低分辨率是另一种选择。最后,调整与视距、纹理渲染、阴影和光照相关的设置也可以在牺牲一些渲染质量的前提下最大化性能。抗锯齿是为了在低分辨率环境中渲染高分辨率图像时使边缘更平滑,而不是出现锯齿状,所以降低抗锯齿设置会降低图像的平滑度,但可以加快低延迟性能。如果需要进一步提升性能,也可以降低诸如火焰、水、动态模糊和镜头光晕等高级渲染效果的设置。
进一步优化硬件
在前面两个小节中,我们讨论了通过升级硬件资源以及调整硬件、操作系统和游戏设置来优化低延迟游戏应用的方法。在本小节中,我们将讨论如何进一步挖掘性能潜力,以及还有哪些方法可以进一步优化在线低延迟游戏应用的性能。
安装DirectX 12 Ultimate
DirectX是微软开发的一款Windows图形和游戏应用程序编程接口(API)。将DirectX升级到最新版本意味着游戏平台可以获得最新的修复和改进,进而实现更好的性能。目前,DirectX 12 Ultimate是最新版本,预计DirectX 13将于2022年底或2023年初发布。
对磁盘进行碎片整理和优化
随着文件在硬盘上的创建和删除,磁盘会出现碎片,空闲和已使用的磁盘空间块会分散开来,导致驱动器性能下降。硬盘驱动器(HDD)和固态硬盘(SSD)是大多数游戏平台常用的两种存储设备。SSD比HDD快得多,通常不会出现很多与碎片相关的问题,但随着时间推移性能仍可能下降。例如,Windows系统有一个磁盘碎片整理和优化应用程序,可以优化驱动器性能,这也能提升游戏应用的性能。
确保笔记本电脑散热良好
当笔记本电脑或个人电脑因处理器、网络、内存和磁盘的高负载使用而处于高负荷状态时,其内部温度会升高。这不仅存在风险,还会迫使笔记本电脑通过限制资源消耗来降温,最终影响性能。我们特别提到笔记本电脑是因为通常情况下,个人电脑的散热能力比笔记本电脑更好。通过清理通风口和风扇、清除灰尘、将笔记本电脑放置在坚硬、光滑且平坦的表面上、使用外部电源以避免耗尽电池电量,甚至使用额外的散热支架等方式确保笔记本电脑有效散热,可以提升其游戏性能。
使用NVIDIA Reflex低延迟技术
NVIDIA Reflex低延迟技术旨在最小化从用户点击鼠标、敲击键盘或操作控制器,到相应操作的反馈在屏幕上呈现之间的输入延迟。我们之前已经讨论过延迟的来源,NVIDIA将从输入设备到处理器再到显示器的延迟分解为九个部分。NVIDIA Reflex软件通过改善CPU和GPU之间的通信路径、跳过不必要的任务和暂停以优化帧传输和渲染,以及加快GPU渲染时间,来提高这一关键路径的性能。NVIDIA还提供了NVIDIA Reflex延迟分析器,用于测量使用这些低延迟增强功能所带来的速度提升。
讨论物联网和零售分析系统的设计
在上一章中,我们讨论了物联网(IoT)和零售分析,以及它们所涉及的许多不同用例。本节的重点是简要探讨用于实现这些应用和用例低延迟性能的技术。请注意,物联网是一个仍在积极发展和演进的技术领域,所以在未来几年会有很多突破和进步。让我们快速回顾一下物联网和零售数据分析的一些重要用例。许多这些新应用和未来的可能性都得益于5G无线技术、边缘计算和人工智能(AI)的研究与发展。在下一节中,我们将与其他有助于实现低延迟物联网和零售数据分析应用的技术一起探讨这些方面。
许多应用属于远程检查/分析类别,在这个领域中,无人机可以取代人类,成为远程技术人员、监测桥梁、隧道、铁路、公路和水路等基础设施,甚至是变压器、电线、天然气管道以及电力和电话线等设施的第一道防线。将人工智能融入这些应用中,可以提高数据分析的复杂性,从而创造新的机会和用例。融入增强现实(AR)技术也增加了更多可能性。现代汽车会收集大量数据,并且随着自动驾驶汽车的发展,物联网的用例进一步扩展。农业、航运和物流、供应链管理、库存和仓库管理以及车队管理等领域的自动化,为物联网技术创造了众多其他用例,并对这些设备生成和收集的数据进行分析。
确保物联网设备的低延迟
在本节中,我们将探讨一些有助于实现物联网应用和零售分析低延迟性能的注意事项。请注意,我们之前讨论的许多关于实时视频流和在线视频游戏用例的注意事项,如硬件资源、数据流的编码和解码、内容交付机制以及硬件和系统级优化等,在这里同样适用。为了简洁起见,我们不会在此重复这些技术,而是介绍一些专门适用于物联网和零售数据分析的低延迟注意事项。
对等连接(P2P)
物联网设备的对等连接(Peer-to-Peer,P2P)是在不同物联网设备之间,或者物联网设备与终端用户应用程序之间建立直接连接。用户从其设备发出的输入会直接发送到目标物联网设备,中间不经过任何第三方服务或服务器,从而最大限度地减少延迟。同样,物联网设备的数据也会直接从设备传输回其他设备。P2P连接方式是替代通过云连接物联网设备的一种选择,因为通过云连接会由于额外的服务器数据库、云工作实例等因素产生额外的延迟。P2P也被称为物联网的去中心化应用支持平台(Application Enablement Platform,AEP),是基于云的AEP的替代方案。
使用第五代无线网络(5G)
5G无线技术提供更高的带宽、超低延迟、可靠性和可扩展性。不仅终端用户能从5G中受益,对于需要低延迟和实时数据流及处理的物联网设备和应用程序的各个环节来说,5G也很有帮助。5G的低延迟特性有助于实现更快、更可靠的库存跟踪、运输服务与监控、配送物流的实时可视化等功能。5G网络在设计时就考虑到了各种不同的物联网用例,所以它非常适合各类物联网应用。
理解边缘计算
边缘计算是一种分布式处理技术,其核心要点是将处理应用程序和数据存储组件尽可能靠近数据来源,在物联网场景中,数据来源就是捕获数据的物联网设备。边缘计算打破了旧有的模式,即数据由远程设备记录,然后传输到中央存储和处理位置,最后将结果再传输回设备和客户端应用程序。这项令人兴奋的新技术正在彻底改变大量物联网设备所产生数据的传输、存储和处理方式。边缘计算的主要目标是降低远距离传输大量数据的带宽成本,并支持超低延迟,以满足那些需要尽可能快速高效处理大量数据的实时应用的需求。此外,它还能为企业降低成本,因为企业不一定需要基于云的集中式存储和处理解决方案。这一点对于物联网应用尤为重要,因为大量设备产生的数据规模意味着带宽消耗将呈指数级增长。
理解边缘计算系统的物理架构的所有细节很困难,也超出了本书的范围。不过,从很高的层面来讲,客户端设备和物联网设备会连接到附近的边缘模块。通常,服务提供商或希望构建自己边缘网络以支持此类边缘计算操作的企业会部署许多网关和服务器。能够使用这些边缘模块的设备包括物联网传感器、笔记本电脑和计算机、智能手机和平板电脑、摄像头、麦克风,以及你能想到的任何其他设备。
理解5G与边缘计算的关系
我们之前提到过,5G的设计和开发考虑到了物联网和边缘计算。所以物联网、5G和边缘计算相互关联,协同工作,以最大化这些物联网应用的用例和性能。理论上,边缘计算可以部署在非5G网络上,但显然5G是更理想的网络选择。然而,反过来并不成立;要充分发挥5G的真正优势,就需要有边缘计算基础设施,才能真正最大化利用5G提供的一切。这很容易理解,因为如果没有边缘计算基础设施,设备产生的数据必须传输很长的距离才能进行处理,然后处理结果又要传输很长距离才能到达终端用户的应用程序或其他设备。在这种情况下,即使有5G网络,数据传输距离带来的延迟也会远远超过使用5G所带来的延迟改善。所以,对于物联网应用和需要实时分析零售数据的应用来说,边缘计算是必不可少的。
理解边缘计算与人工智能的关系
数据分析技术、机器学习和人工智能彻底改变了从物联网设备收集的零售及非零售数据的分析方式,从而获取有价值的见解。英伟达(NVIDIA)在开发新的硬件解决方案方面是先驱,不仅推动了边缘计算,还将人工智能处理发挥到极致。Jetson AGX Orin就是一个很好的例子,它展示了英伟达如何将人工智能和机器人功能整合到一个产品中。
我们不会过多讨论Jetson AGX Orin的细节,因为这既不是本书的重点,也超出了本书的范围。Jetson AGX Orin有一些特性,使其非常适合人工智能、机器人和自动驾驶汽车领域——它体积小巧、功能强大且节能。其强大的性能和高效的能源利用使其可用于人工智能应用,并支持边缘计算。特别是这个最新的型号,让开发者能够将人工智能、机器人、自然语言处理(NLP)、计算机视觉等功能整合到一个紧凑的设备中,非常适合机器人领域。该设备还有多个输入/输出接口,并且与许多不同的传感器(如MIPI、USB、摄像头等)兼容。此外,它还有额外的硬件扩展插槽,以支持存储、无线连接等功能。这个由强大GPU驱动的设备,非常适合深度学习(除了传统机器学习)以及机器人等计算机视觉应用。
购买和部署边缘计算系统
在购买和搭建边缘计算基础设施时,企业通常会选择以下两种途径之一:定制组件并在内部构建和管理基础设施,或者使用为企业提供并管理边缘服务的供应商。
在内部构建和管理边缘计算基础设施需要IT、网络和业务部门的专业知识。然后,他们可以从硬件供应商(如IBM、戴尔等)选择边缘设备,并针对特定用例设计和管理5G网络基础设施。这种选择仅对大型企业有意义,因为大型企业能从针对特定用例定制边缘计算基础设施中看到价值。至于选择第三方供应商来搭建和管理边缘计算基础设施,供应商会收取一定费用来设置硬件、软件和网络架构。这就将边缘计算基础设施这种复杂系统的管理工作交给了通用电气(GE)和西门子(Siemens)等在该领域有专业知识的公司,让客户企业能够专注于在这个基础设施之上进行开发。
利用邻近性
我们在前面的章节中已经隐含地讨论过这一点,现在我们将在此明确讨论。物联网应用的一个关键要求是实现超低延迟性能,而实现这一目标的关键在于利用物联网用例中涉及的不同设备和应用之间的邻近性。毫不奇怪,边缘计算是物联网应用利用邻近性的关键,它可以最小化从数据采集到处理以及与其他设备或客户端应用共享结果之间的延迟。正如我们之前所见,非边缘计算基础设施的最大瓶颈在于数据中心和处理资源与数据来源及结果目的地之间的距离。随着分布在数英里之外的更多分布式数据中心的出现,这个问题变得更糟,最终导致极高的延迟和滞后。显然,将边缘计算资源放置得更靠近数据源是推动物联网应用普及、拓展物联网用例,以及将物联网业务扩展到大量设备和用户的关键。
降低云成本
这也是我们之前讨论过的一点,但在本节我们将正式探讨它。目前有数十亿的物联网设备,它们不断产生数据流。任何有效的物联网驱动型企业都需要具备良好的扩展性,以应对设备和客户端数量的大幅增长,这会导致边缘计算记录和处理的数据量呈指数级增长,并且结果要传输到其他设备和客户端。依赖集中式云基础设施的数据密集型架构,无法以经济高效的方式支持物联网应用,数据和云基础设施本身也成为企业开支的重要部分。显然,解决方案是找到一个低成本的边缘解决方案(第三方的或内部构建的),并利用它来满足物联网数据采集、存储和处理的需求。这消除了与云解决方案进行数据传输相关的成本,还可以提高边缘计算的可靠性并显著降低成本。
我们将通过下图总结物联网应用的当前和未来状态,以此结束对低延迟物联网应用的讨论:
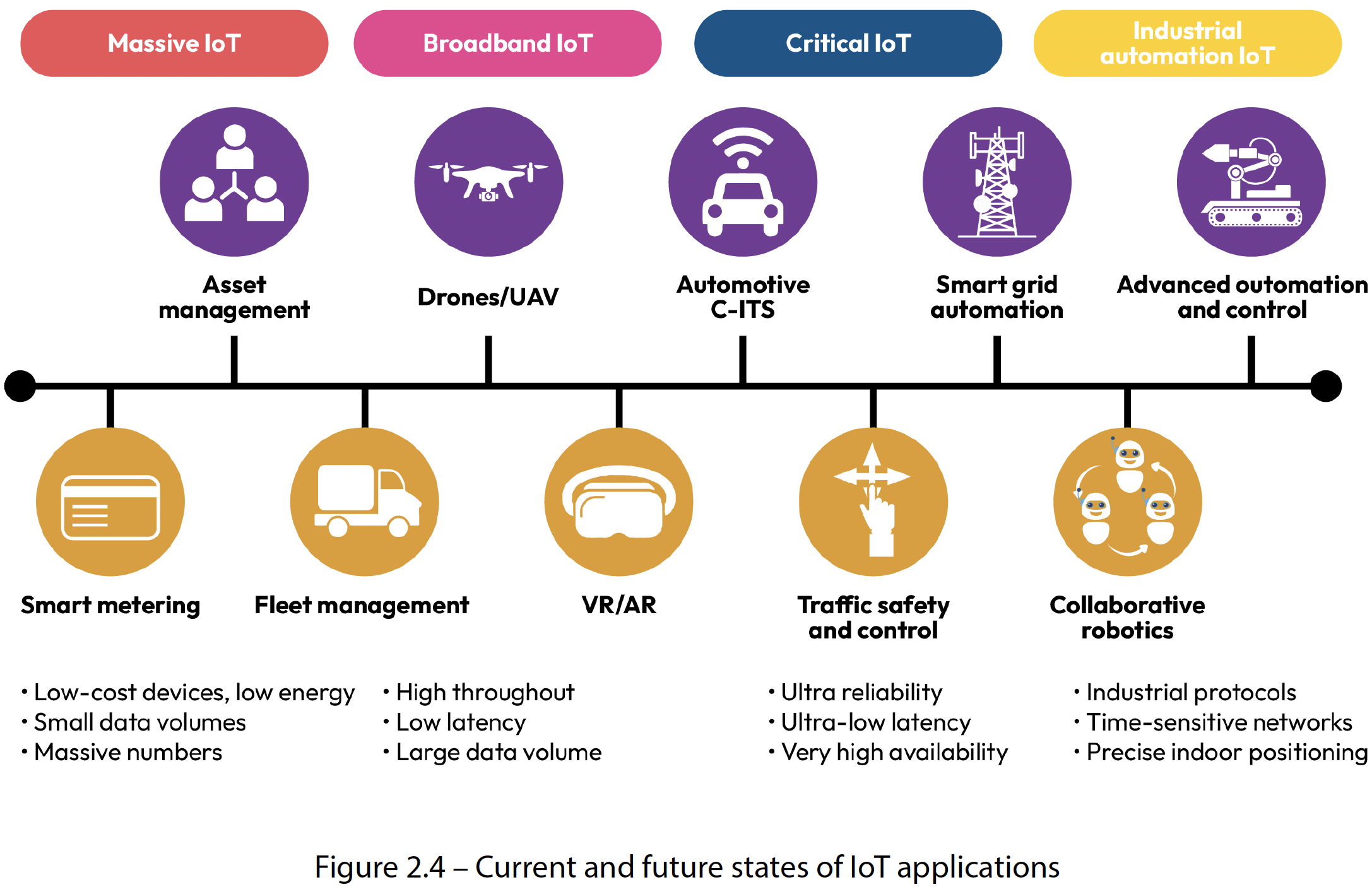
图2.4 物联网应用的当前和未来状态
探索低延迟电子交易
低延迟应用的最后一个例子是用于低延迟电子交易和超低延迟电子交易(也称为高频交易,HFT)的应用。在本书的后续部分,我们将用C++从头开始构建一个完整的端到端低延迟电子交易系统。因此,在本节中,我们将简要讨论电子交易应用实现低延迟性能的重要注意事项,然后在后续章节中深入探讨具体细节。对于有兴趣的读者来说,Sebastian Donadio、Sourav Ghosh和Romain Rossier所著的《Developing High-Frequency Trading Systems》是一本深入了解低延迟电子交易系统的优秀书籍。本书的重点是用C++从头开始设计和构建每个组件,以学习低延迟应用开发,而那本书可以作为高频交易业务背后更多理论的良好参考。
理解现代电子交易中对低延迟的需求
随着电子交易的现代化和高频交易的兴起,低延迟对于这些应用比以往任何时候都更加重要。在许多情况下,降低延迟能直接增加交易收入。在某些情况下,市场参与者不断竞相降低延迟,以在市场中保持竞争优势。在极端情况下,如果参与者在追求尽可能低延迟的竞争中落后,可能会面临倒闭。
现代电子市场中的交易机会转瞬即逝,因此只有那些能够处理市场数据、发现机会并迅速做出反应发送订单的市场参与者才能盈利。反应不够迅速意味着只能抓住较小的机会份额,通常只有最快的参与者才能获得全部利润,而其他速度较慢的参与者则一无所获。这里还有一个微妙之处,如果参与者对市场事件反应不够迅速,还可能在交易中处于不利地位,输给那些能够快速反应的人。在这种情况下,交易利润不仅会降低,交易收入甚至可能为负(即亏损)。为了更好地理解这一点,让我们以本书中会构建的做市和流动性获取算法为例进行说明。
简单来说,做市算法会在市场中下达订单,其他参与者在需要时可以与之交易。因此,做市算法需要不断重新评估其活跃订单,并根据市场情况调整价格和数量。而流动性获取算法并不总是在市场中有活跃订单,它会等待机会出现,然后与市场中做市算法的活跃订单进行交易。高频交易市场可以简单地看作是做市算法和流动性获取算法之间的持续博弈,因为它们自然处于对立的立场。
在这种情况下,做市算法如果在修改市场中的活跃订单时速度较慢就会赔钱。例如,根据市场情况很明显短期内市场价格会上涨,做市算法会试图调整或取消其可能被执行的卖出订单,因为它不再想以这些价格卖出。与此同时,流动性获取算法会尝试查看是否可以发送买入订单,以该价格与做市商的卖出订单进行交易。在这场竞争中,如果做市算法比流动性获取算法慢,它将无法修改或取消其卖出订单。如果流动性获取算法速度慢,它也无法与它想要交易的订单成交,这可能是因为其他(更快的)算法抢先成交,或者是做市商及时调整了订单。这个例子应该能让你清楚地认识到,延迟直接影响电子交易的收入。
对于高频交易,客户端的交易应用程序可以在10微秒以内的延迟内接收和处理市场数据、分析信息、寻找机会并向交易所发送订单,并且使用现场可编程门阵列(Field - Programmable Gate Arrays,FPGA)可以将延迟降低到1微秒以内。FPGA是一种特殊的硬件芯片,可以重新编程,能够直接在芯片上构建极其专业的低延迟功能。理解FPGA的细节以及开发和使用FPGA是一个高级话题,超出了本书的范围。
虽然我们在前面的例子中提到了交易性能和收入,但低延迟在电子交易业务的其他方面也很重要,只是可能不那么明显。显然,交易收入和性能仍然是交易应用的主要关注点;对于长期业务连续性来说,另一个重要要求是实时风险管理。由于每个电子市场都有许多交易工具,并且每个工具的价格在一天中不断变化,风险管理系统需要处理来自所有交易所和全天所有可用产品的大量数据。
此外,由于公司在所有这些产品和交易所采用高频交易策略,公司在每个产品上的头寸在一天内会迅速变化。实时风险管理系统需要根据市场价格评估公司在所有这些产品上不断变化的风险敞口,以跟踪全天的利润、损失和风险。风险评估指标和系统本身可能非常复杂;例如,在期权交易中,通常会运行蒙特卡罗模拟,试图实时或接近实时地找出最坏情况下的风险评估。一些风险管理系统还负责在自动交易策略超出任何风险限制时将其关闭。这些风险系统通常会添加到多个组件中——中央风险系统、订单网关和交易策略本身——但我们将在本书后面的内容中了解这些细节。
在电子交易中实现最低延迟
在本节中,我们将简要讨论实现低延迟电子交易系统的一些高层次的思路和概念。当然,在接下来的章节中构建电子交易生态系统时,我们会通过示例更详细地探讨这些内容。
优化交易服务器硬件
配备强大的交易服务器以支持低延迟交易操作是第一步。通常,这些服务器的处理能力取决于交易系统进程的架构,比如我们预期运行多少个进程、预计消耗多少网络资源,以及这些应用程序预计占用多少内存。一般来说,在交易繁忙时期,低延迟交易应用程序具有CPU使用率高、内核使用率(系统调用)低、内存消耗低,以及网络资源使用率相对较高的特点。CPU寄存器、缓存架构和容量也很重要,通常情况下,如果可能的话,我们会尽量选择更大的规格,不过这些成本可能相当高。像非统一内存访问(Non-Uniform Memory Access,NUMA)、处理器指令集、指令流水线和指令并行性、缓存层次结构详细架构、超线程技术,以及超频CPU等高级因素,虽然常常会被考虑,但这些都属于极其高级的优化技术,超出了本书的讨论范围。
网络接口卡、交换机和内核旁路
需要支持超低延迟交易应用程序(尤其是那些必须读取大量市场数据、更新网络数据包并进行处理的应用程序)的交易服务器,需要专门的网络接口卡(Network Interface Cards,NICs)和交换机。这类应用程序偏好的网络接口卡需要具备极低的延迟性能、低抖动,以及大缓冲区容量,以便在处理市场数据突发情况时不会丢包。此外,适用于现代电子交易应用程序的理想网络接口卡支持一种特别低延迟的路径,能够避免系统调用和缓冲区复制,这被称为内核旁路(kernel bypass)。例如Solarflare公司提供的OpenOnload以及像ef_vi和TCPDirect这样的API,在使用其网络接口卡时可以绕过内核;Exablaze则是另一种支持内核旁路的专用网络接口卡。网络交换机出现在网络拓扑的各个位置,用于支持交易服务器之间、相距较远的交易服务器之间,以及交易服务器与电子交易所服务器之间的互联互通。对于网络交换机,一个重要的考虑因素是交换机能够支持的缓冲区大小,以便缓存需要转发的数据包。另一个重要要求是交换机接收数据包并将其转发到正确接口之间的延迟,即交换延迟(switching latency)。交换延迟通常非常低,一般在几百纳秒的量级,但这适用于通过交换机的所有入站或出站流量,所以需要始终保持低延迟,以免对交易性能产生负面影响。
理解多线程、锁、上下文切换和CPU调度
在上一章中,我们讨论了带宽和低延迟这两个密切相关但在技术层面有所不同的概念。有时人们会错误地认为,线程数量更多的架构总是具有更低的延迟,但事实并非总是如此。多线程在低延迟电子交易系统的某些领域有其价值,在本书构建的系统中我们也会用到它。但关键在于,在高频交易(HFT,High-Frequency Trading )系统中使用额外线程时需要谨慎,因为虽然增加线程通常能为有需求的应用程序提高吞吐量,但有时也可能会增加应用程序的延迟。随着线程数量的增加,我们必须考虑并发和线程安全问题,如果需要使用锁来实现线程之间的同步和并发控制,这会增加额外的延迟和上下文切换(context switches)开销。上下文切换并非没有成本,因为调度器和操作系统必须保存被切换出的线程或进程的状态,并加载下一个要运行的线程或进程的状态。许多锁的实现是基于内核系统调用,这比用户空间例程的成本更高,从而进一步增加了高度多线程应用程序的延迟。为了实现最佳性能,我们尽量让CPU调度器少做甚至不做工作(即被调度运行的进程和线程永远不会被上下文切换出去,而是持续在用户空间中运行)。此外,将特定的线程和进程固定到特定的CPU核心上是很常见的做法,这可以消除上下文切换,也无需操作系统寻找空闲核心来调度任务,进而提高内存访问效率。
动态分配内存和管理内存
动态内存分配(Dynamic memory allocation)是在运行时请求任意大小的内存块。从高层次来看,动态内存的分配和释放由操作系统负责,操作系统会遍历一个空闲内存块列表,尝试分配一个与程序请求大小相同的连续内存块。动态内存的释放则是将释放的内存块添加到操作系统管理的空闲块列表中。随着程序的运行,内存碎片化程度越来越高,遍历这个列表所带来的延迟也会越来越高。此外,如果动态内存的分配和释放在同一关键路径上,那么每次都会产生额外的开销。这就是我们之前讨论过的选择C++作为构建低延迟和资源受限应用程序首选语言的主要原因之一。在本书后面构建自己的交易系统时,我们将探讨动态内存分配对性能的影响,以及避免这种影响的技术。
静态链接与动态链接,编译时与运行时
链接(Linking)是将高级编程语言源代码转换为目标架构机器码过程中的编译或转换步骤。链接将可能位于不同库中的代码片段连接在一起,这些库可以是代码库内部的库,也可以是外部独立库。在链接步骤中,我们有两种选择:静态链接(Static linking)或动态链接(Dynamic linking)。 动态链接是指链接器在链接时不会将库中的代码合并到最终的二进制文件中。相反,当主应用程序首次需要共享库中的代码时,会在运行时进行解析。显然,在首次调用共享库代码时,运行时会产生特别大的额外开销。更大的缺点是,由于编译器和链接器在编译和链接时没有将代码合并进去,它们无法进行可能的优化,从而导致整个应用程序的效率可能较低。 静态链接是指链接器将应用程序代码和库依赖代码整理到一个二进制可执行文件中。这样做的好处是库在编译时已经链接好,因此在应用程序启动执行之前,操作系统无需在运行时启动阶段查找并解析依赖关系,加载相关库。更大的好处是,这为程序在编译和链接时进行深度优化创造了机会,从而在运行时实现更低的延迟。与动态链接相比,静态链接的缺点是应用程序二进制文件会大得多,而且每个依赖相同外部库集的应用程序二进制文件,都会将所有外部库代码编译并链接到自身二进制文件中。为了最大程度降低运行时的性能延迟,超低延迟电子交易系统通常会静态链接所有依赖库。 在上一章中,我们讨论了编译时与运行时处理,这种方式试图将尽可能多的处理工作转移到编译阶段,而不是在运行时进行。这会增加编译时间,但运行时的性能延迟会低得多,因为很多工作在编译时已经完成。在接下来的几章以及本书构建C++电子交易系统的过程中,我们将详细探讨C++在这方面的具体情况。
总结
在本章中,我们研究了不同业务领域的低延迟应用程序。目的是了解低延迟应用程序如何影响不同领域的业务,以及这些应用程序的一些共同之处,比如硬件需求和优化、软件设计、性能优化,以及为满足这些性能要求所采用的不同创新技术。
我们首先详细研究的是实时、低延迟的在线视频流应用程序。我们讨论了不同的概念,探究了高延迟的来源,以及它对性能和业务的影响。最后,我们讨论了不同的技术、解决方案和平台,这些因素共同助力低延迟视频流应用程序取得成功。
接下来我们研究的应用程序与视频流应用程序有很多重叠之处,即离线和在线视频游戏应用程序。我们介绍了一些适用于离线和在线游戏应用程序的额外概念和注意事项,并解释了它们对用户体验的影响,进而对业务表现的影响。我们讨论了在试图最大化这些应用程序性能时需要考虑的众多因素,涵盖了许多与直播视频流应用程序相关的因素,以及针对游戏应用程序的额外硬件和软件方面的考虑。 然后,我们简要讨论了物联网设备以及零售数据收集和分析应用程序对低延迟性能的要求。这是一项相对较新且发展迅速的技术,在未来十年可能会继续迅猛发展。目前在物联网设备方面有很多研究和进展,随着研究的深入,我们也发现了新的商业理念和应用案例。我们讨论了5G无线和边缘计算技术如何打破传统的集中式数据存储和处理模式,以及这对物联网设备和应用程序为何至关重要。 本章最后我们还简要讨论了低延迟电子交易和高频交易应用程序。我们的讨论较为简短,重点关注了最大化低延迟和超低延迟电子交易应用程序性能的高层次理念。之所以这样做,是因为在本书的后续章节中,我们将从头开始构建一个完整的端到端C++低延迟电子交易生态系统。在构建过程中,我们将通过示例和性能数据,深入讨论、理解并实现所有不同的低延迟C++概念和理念,所以关于这个应用程序还有很多内容值得期待。
从对不同低延迟应用程序的讨论出发,接下来我们将更深入地探讨C++编程语言。我们将讨论如何正确使用C++实现低延迟性能,探讨现代C++的不同特性,以及如何充分发挥现代C++编译器优化的强大功能。
更多推荐
 10
10 0
0- 0



 已为社区贡献93条内容
已为社区贡献93条内容

所有评论(0)