
基于 LlamaIndex 与 Elasticsearch 8.x 的混合检索系统:20 种策略原理与实现
基于 LlamaIndex 与 Elasticsearch 8.x 的混合检索系统:20 种策略原理与实现
前言
RAG 系统的检索质量直接决定了大模型回答的准确性。单一检索方式(纯 BM25 或纯向量)都存在明显短板:BM25 抓不住语义同义(“请假”和“休假”匹配不上),向量检索抓不住精确关键词(专有名词、错误码)。混合检索通过多路召回 + 智能融合,把“语义”和“字面”两条路打通,是现代 RAG 系统的常见做法。
本文基于 LlamaIndex + DashScope 鉴权大模型 + Elasticsearch 8.x 运行,逐个拆解脚本中 20 种检索方式的算法原理与代码实现。其中 DashScope 仅作为运行支撑,本文不涉及其鉴权或接口细节。
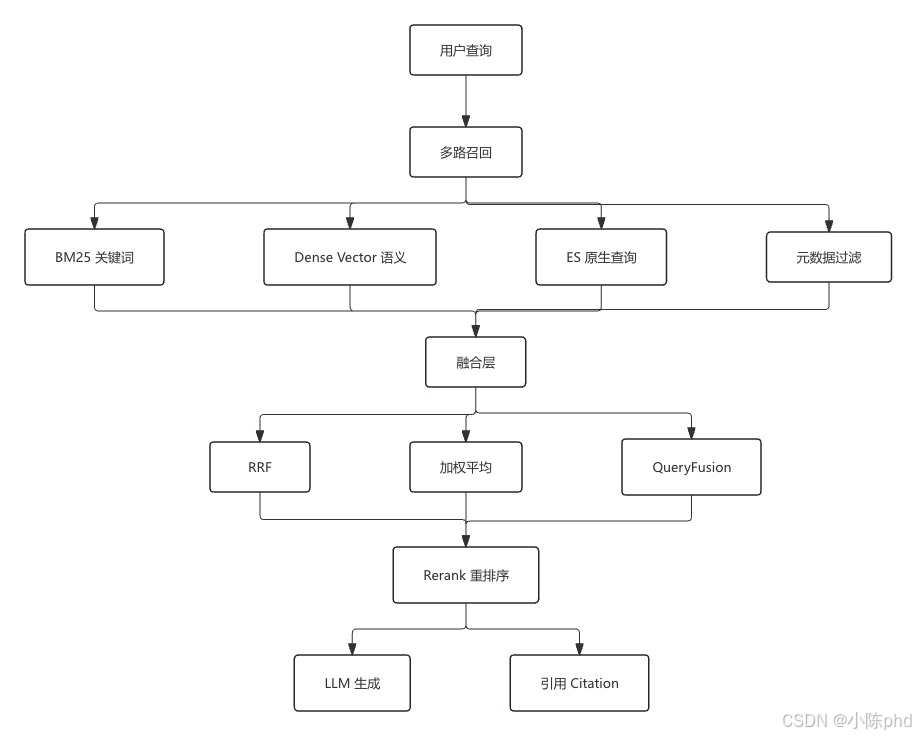
1. 核心架构:LlamaIndex × Elasticsearch
1.1 三大组件的角色分工
| 组件 | 职责 | 关键类 |
|---|---|---|
| LlamaIndex | 编排层:Reader、Retriever、QueryEngine、PostProcessor | VectorStoreIndex、Retriever |
| Elasticsearch | 存储层:倒排索引 + 向量索引 + 聚合统计 | ElasticsearchStore |
| DashScope | 模型层:Embedding(text-embedding-v3)+ LLM(qwen-plus) | DashScopeEmbedding |
LlamaIndex 通过 ElasticsearchStore 适配 ES,把"切分、嵌入、查询"全部用 LlamaIndex 抽象层包装。底层 ES 仍然用自身的 DSL(DSL 是 ES 的查询 JSON 结构),LlamaIndex 只负责"翻译"。
1.2 关键环境配置
from llama_index.core import Settings
from llama_index.embeddings.dashscope import DashScopeEmbedding, DashScopeTextEmbeddingModels
from llama_index.llms.dashscope import DashScope, DashScopeGenerationModels
# 全局配置:避免 query_engine 未指定 LLM 时回退到 OpenAI
Settings.llm = DashScope(model_name=DashScopeGenerationModels.QWEN_PLUS, api_key=os.getenv("DASHCOPE_KEY"))
Settings.embed_model = DashScopeEmbedding(
model_name=DashScopeTextEmbeddingModels.TEXT_EMBEDDING_V3,
embed_batch_size=6, embed_input_length=8192
)
说明:DashScope SDK 需要
DASHSCOPE_API_KEY环境变量名,必须双重设置dashscope.api_key = ...和os.environ["DASHSCOPE_API_KEY"],否则底层 SDK 报 401。
1.3 索引入库
splitter = SentenceSplitter(chunk_size=256, chunk_overlap=50)
VectorStoreIndex.from_documents(
docs, transformations=[splitter], embed_model=embed_model,
storage_context=StorageContext.from_defaults(
vector_store=ElasticsearchStore(index_name=INDEX_NAME, es_url=ES_URL)
),
)
SentenceSplitter 按句子切分,chunk_overlap=50 让相邻块有少量重叠避免关键信息被切断。LlamaIndex 内部会对每块调 Embedding 模型生成向量,连同文本一起写入 ES(content 字段存文本,embedding 字段存向量)。
接下来,我们逐个演示脚本中的 20 种检索方式。
2. 基础检索:BM25 与 Dense Vector
2.1 BM25 全文检索
原理
BM25(Best Matching 25)是经典的信息检索排序算法,核心思想是:
- 词频饱和(TF Saturation):词出现越多越相关,但到一定次数后增益趋平(避免"长文档得高分")
- 逆文档频率(IDF):常见词(“的”、“是”)权重低,稀有词(“事假”)权重高
- 文档长度归一化:短文档中命中关键词的相对密度更高,给予补偿
BM25 公式(Robertson 1994):
score(q,d)=∑iIDF(qi)⋅f(qi,d)⋅(k1+1)f(qi,d)+k1⋅(1−b+b⋅∣d∣avgdl) \text{score}(q, d) = \sum_{i} \text{IDF}(q_i) \cdot \frac{f(q_i, d) \cdot (k_1 + 1)}{f(q_i, d) + k_1 \cdot \left(1 - b + b \cdot \frac{|d|}{\text{avgdl}}\right)} score(q,d)=i∑IDF(qi)⋅f(qi,d)+k1⋅(1−b+b⋅avgdl∣d∣)f(qi,d)⋅(k1+1)
其中:
- f(qi,d)f(q_i, d)f(qi,d):词 qiq_iqi 在文档 ddd 中的频率
- ∣d∣/avgdl|d|/\text{avgdl}∣d∣/avgdl:文档长度 / 平均文档长度
- k1k_1k1:词频饱和参数(默认 1.2,范围 0∼∞0 \sim \infty0∼∞)
- bbb:长度归一化强度(默认 0.75,范围 0∼10 \sim 10∼1,0=不归一化,1=完全归一化)
代码实现
from llama_index.vector_stores.elasticsearch import AsyncBM25Strategy
bm25_index = make_index(AsyncBM25Strategy()) # 默认 k1=1.2, b=0.75
bm25_results = get_retriever(bm25_index).retrieve(QUERY)
AsyncBM25Strategy() 是 LlamaIndex 提供的 BM25 检索策略包装。make_index() 内部把 strategy 注入到 ES 索引配置中。
优势与局限
| 优势 | 局限 |
|---|---|
| 精确关键词匹配(产品名、错误码) | 无法匹配同义词(“请假"≠"休假”) |
| 计算快、可解释(命中哪些词) | 短查询召回率低 |
| 适合专有名词、缩写、版本号 | 依赖分词器质量 |
2.2 Dense Vector 语义检索
原理
把文本通过 Embedding 模型映射到高维空间(如 1024 维),用向量距离衡量语义相似度。核心假设:“意思相近的文本在向量空间也相近”。
余弦相似度(常用度量):
cos(A,B)=A⋅B∥A∥⋅∥B∥ \cos(\mathbf{A}, \mathbf{B}) = \frac{\mathbf{A} \cdot \mathbf{B}}{\|\mathbf{A}\| \cdot \|\mathbf{B}\|} cos(A,B)=∥A∥⋅∥B∥A⋅B
取值范围 [−1,1][-1, 1][−1,1],越接近 1 越相似。其他度量:点积(DOT_PRODUCT)、欧氏距离(EUCLIDEAN)。
代码实现
from llama_index.vector_stores.elasticsearch import AsyncDenseVectorStrategy
from llama_index.core.postprocessor import SimilarityPostprocessor
vector_index = make_index(AsyncDenseVectorStrategy())
vector_results = get_retriever(vector_index, top_k=5).retrieve(QUERY)
# 关键:过滤低分节点(防止退化向量污染结果)
vector_results = SimilarityPostprocessor(similarity_cutoff=0.3).postprocess_nodes(vector_results)
核心细节:
top_k=5+similarity_cutoff=0.3组合使用。先取 5 个候选,再用相似度阈值过滤。LLaMAIndex 向量检索可能返回 score=0.0\text{score}=0.0score=0.0 的退化向量(极少数情况),必须过滤。
优势与局限
| 优势 | 局限 |
|---|---|
| 同义、近义、上下文相关都能匹配 | 计算成本高(向量比对) |
| 多语言能力(取决于 Embedding) | 对专有名词不敏感 |
| 适合长查询、口语化表达 | 不可解释(黑盒) |
3. 融合策略:把 BM25 和向量"合并"
基础检索各有所长,融合策略是混合检索的灵魂。
3.1 倒数排名融合(RRF)
原理
RRF(Reciprocal Rank Fusion)由 Cormack 等人 2009 年提出,核心思想:不直接比较分数(不同检索器分数尺度差异大),而是按排名倒数加权求和。
公式:
RRF_score(d)=∑i1k+ranki(d) \text{RRF\_score}(d) = \sum_{i} \frac{1}{k + \text{rank}_i(d)} RRF_score(d)=i∑k+ranki(d)1
其中:
- ranki(d)\text{rank}_i(d)ranki(d):文档 ddd 在第 iii 路检索中的排名(从 0 或 1 开始)
- kkk:常数(默认 60),控制"高排名 vs 低排名"的差距。kkk 越小,高排名权重越大;kkk 越大,融合越平滑
为什么有效:
- 不依赖原始分数(BM25 分数可能是 0~10,向量分数可能是 0~1)
- 排名是单调变换(排名不因分数尺度变化而改变)
- 多路都在前列的文档自然得分高
代码实现
def rrf_fuse(results_dict, k=60, top_k=2):
"""手动 RRF 融合(ES 免费版不支持内置 RRF)"""
scores, nodes = {}, {}
for ns in results_dict.values():
for rank, n in enumerate(sorted(ns, key=lambda x: x.score or 0, reverse=True)):
t = n.node.get_content()
nodes[t] = n
scores[t] = scores.get(t, 0) + 1.0 / (rank + k)
return [_set_score(nodes[t], s) for t, s in
sorted(scores.items(), key=lambda x: x[1], reverse=True)[:top_k]]
说明:ES 8.x 的
AsyncDenseVectorStrategy(hybrid=True)内部用 RRF,但需要付费版。免费版(basic)只能手动实现,本文采用的就是手动版本。
应用场景
- 跨语言检索(不同检索器分数尺度差异大)
- 多模态融合(文本 + 图像检索)
- 多索引查询(不同来源的异构数据)
3.2 加权平均融合
原理
把每路检索分数按预设权重加权求和。简单直接,但要求所有检索器的分数在同一尺度(或经过 min-max 归一化)。
公式:
final_score(d)=∑iwi⋅normalized_scorei(d) \text{final\_score}(d) = \sum_{i} w_i \cdot \text{normalized\_score}_i(d) final_score(d)=i∑wi⋅normalized_scorei(d)
代码实现
def weighted_fuse(results_dict, weights, top_k=2):
"""加权平均融合"""
scores, nodes = {}, {}
for src, ns in results_dict.items():
for n in ns:
t = n.node.get_content()
nodes[t] = n
scores[t] = scores.get(t, 0) + (n.score or 0) * weights.get(src, 1.0)
return [_set_score(nodes[t], s) for t, s in
sorted(scores.items(), key=lambda x: x[1], reverse=True)[:top_k]]
# 调用:让向量检索权重更高
weighted_fuse({"bm25": bm25_results, "vector": vector_results},
{"bm25": 0.3, "vector": 0.7})
与 RRF 的对比
| 维度 | RRF | 加权平均 |
|---|---|---|
| 分数要求 | 不需要(只看排名) | 需要同尺度 |
| 实现复杂度 | 简单 | 需要归一化 |
| 调参难度 | 低(k 固定 60 即可) | 高(每路权重都要调) |
| 业务可解释性 | 弱(“为什么这条排第一”) | 强(“vector 权重 0.7”) |
| 适用场景 | 多路异构检索 | 同尺度分数融合 |
3.3 QueryFusionRetriever(LlamaIndex 内置)
原理
LlamaIndex 提供的开箱即用融合器,底层支持三种模式:
reciprocal_rerank(默认):RRFsimple:简单拼接llm:用 LLM 智能重排
num_queries > 1 时会先用 LLM 改写查询(Query Rewriting),生成多个变体查询再分别检索。
代码实现
from llama_index.core.retrievers import QueryFusionRetriever
fusion = QueryFusionRetriever(
retrievers=[get_retriever(bm25_index), get_retriever(vector_index)],
similarity_top_k=2, # 最终返回 2 个
num_queries=1, # 不改写查询(=1 时直接用原查询)
mode="reciprocal_rerank", # RRF 模式
llm=llm, # 必填!QueryFusion 内部需要 LLM
)
fusion.retrieve(QUERY)
注意:
QueryFusionRetriever内部会调用 LLM 做查询改写(即使num_queries=1也会校验 LLM),必须显式传llm参数。如果用默认 OpenAI,国内必报 401。
4. ES 原生查询:DSL 七种武器
ES 自身的查询 DSL(Domain Specific Language)是检索领域的事实标准。LlamaIndex 帮你处理切分、嵌入,但精细化查询仍需直接调用 ES API。
4.1 字段加权(multi_match)
原理
同一查询在不同字段的重要性不同。比如搜索"Python 教程",title 字段命中比 content 字段命中更相关。ES 用 ^N 表示权重倍数。
代码
es_query({"query": {"multi_match": {
"query": "请假",
"fields": ["content^3"], # content 字段权重 3
"type": "best_fields" # 取单字段最高分
}}, "size": 1})
best_fields vs most_fields:
best_fields:取最高分(适合字段互斥)most_fields:累加所有字段分数(适合字段互补)
调高/调低效果
- 短查询(1~2 词)
title^5, content^1效果显著 - 长查询(10+ 词)权重影响小,可不设
- 别超过
^10,会让分数爆炸
4.2 布尔查询(bool)
原理
组合多个子查询,支持 must(必须)、should(应该)、must_not(必须不)、filter(不过滤分数)。复杂查询场景中,绝大部分都基于 bool。
代码
es_query({"query": {"bool": {
"must": [{"match": {"content": "请假"}}], # 必须命中"请假"
"should": [{"match": {"content": "提前"}}], # 应该命中"提前"(加权)
"must_not": [{"match": {"content": "婚"}}], # 必须不包含"婚"
}}, "size": 1})
核心细节:ES 默认
standard analyzer把"婚假"拆成["婚", "假"]两个 token。must_not必须用单字才能精准过滤。
filter vs must 的区别
| 维度 | must | filter |
|---|---|---|
| 是否算分 | ✅ | ❌(只过滤) |
| 缓存 | 不缓存 | 会缓存(性能更好) |
| 适用 | 影响相关性的条件 | 时间范围、状态过滤 |
4.3 短语查询(match_phrase)
原理
要求查询的词按指定顺序连续出现,slop 参数允许中间有 N 个其他词。slop=0 是严格连续,slop=2 允许间隔 2 个词。
代码
es_query({"query": {"match_phrase": {
"content": {"query": "提前", "slop": 0} # 严格匹配"提前"两字相邻
}}, "size": 1})
注意:中文分词后是单字"提"+“前”。如果用"提前申请" + slop=1,会误命中"申…请"(因为"申"在"请"前 1 个位置)。严格场景用 slop=0 + 单字查询。
4.4 通配符查询(wildcard)
原理
* 匹配任意字符串(0 或多个字符),? 匹配单个字符。底层是正则表达式,性能差,慎用。
代码
es_query({"query": {"wildcard": {
"content.keyword": {"value": "*事假*", "boost": 1.5} # 必须用 keyword 字段
}}, "size": 1})
核心细节:
text字段被分词后没有"事假"这个 token。通配符只能在keyword子字段上(不分析、整词作为 token)。
性能警告
通配符查询无法使用倒排索引,要扫描所有文档:
*事假(前缀无 *):可以用索引事假*(后缀无 *):可以用索引*事假*(两端有 *):必须全表扫描,性能较低,慎用
4.5 模糊查询(fuzzy)
原理
基于 Levenshtein 距离(编辑距离)匹配相似词。fuzziness=AUTO 自动根据词长度调整允许的编辑距离(短词 0,长词 2)。
代码
es_query({"query": {"fuzzy": {
"content": {"value": "请", "fuzziness": 1, "prefix_length": 0}
}}, "size": 1})
核心细节:中文分词后是单字,模糊查询也只能针对单字。如果想匹配"请假如"(“假如"是"假"的错别字),实际应查询"假"而不是"请假如”。
适用场景
- 拼写纠错(“苹果手要” → “苹果手机”)
- OCR 错误文本检索
- 口语化输入
4.6 高亮查询(highlight)
原理
返回匹配结果的前后片段并标记关键词。需要在查询时声明 highlight 块,ES 会从 _source 提取匹配片段并用 <em> 标签包裹。
代码
r = es_client.search(index=INDEX_NAME, body={
"query": {"match": {"content": "请假"}},
"highlight": {
"fields": {"content": {"pre_tags": ["<em>"], "post_tags": ["</em>"]}}
},
"size": 1,
})
print(f"高亮: {r['hits']['hits'][0].get('highlight', {}).get('content', [])}")
在 RAG 中的应用
- 前端展示"匹配了哪些关键词"
- 调试检索质量(一眼看出为什么命中)
- 生成"为什么推荐这条"的可解释性
4.7 函数评分(function_score)
原理
在原始查询分数基础上,叠加额外函数(权重、随机性、衰减)调整最终分数。适合"特定条件加权"(如新文章加权、热门文档加权)。
代码
es_query({"query": {"function_score": {
"query": {"match": {"content": "请假"}}, # 基础查询
"functions": [
{"filter": {"match": {"content": "提前"}}, "weight": 2.0} # 含"提前"权重 ×2
],
"score_mode": "sum", # 多函数分数求和
"boost_mode": "multiply" # 与基础查询分数相乘
}}, "size": 1})
常用函数
| 函数 | 用途 | 示例 |
|---|---|---|
weight |
简单加权 | 特定标签文档 ×2 |
field_value_factor |
用字段值计算 | 文档浏览数 ×0.1 |
random_score |
引入随机性 | 实现多样化推荐 |
decay_function |
时间/距离衰减 | 越新的文档分数越高 |
5. 中文分词:适配与查询绕路
5.1 问题的本质
ES 默认 standard analyzer 对英文友好(按空格分词),但对中文是按字拆分:
POST /hybrid_demo/_analyze
{"analyzer": "standard", "text": "事假需提前申请"}
# 输出 tokens: ["事", "假", "需", "提", "前", "申", "请"]
这导致一系列问题:
| 查询 | 预期 | 实际(standard) | 原因 |
|---|---|---|---|
通配符 *事假* |
命中"事假"相关内容 | ❌ 无结果 | "事假"不是 token |
| must_not 婚假 | 排除婚假文档 | ❌ 实际排除"婚"或"假" | "婚假"被拆字 |
| 短语"提前申请" slop=1 | 命中"提前申请" | ❌ 命中"申…请" | "申"在"请"前 1 个位置 |
| 模糊 请假如 | 找错别字 | ❌ 无结果 | "请假如"不是 token |
5.2 解决方案
方案 A:安装 IK 中文分词器
# ES 8.x 安装 IK
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.10.0/elasticsearch-analysis-ik-8.10.0.zip
# 创建索引时指定 analyzer
PUT /hybrid_demo
{
"settings": {
"analysis": {
"analyzer": {"ik_max_word": {"tokenizer": "ik_max_word"}}
}
},
"mappings": {
"properties": {
"content": {"type": "text", "analyzer": "ik_max_word"}
}
}
}
方案 B:用 content.keyword 字段(绕过分词)
适用场景:通配符、精确匹配
# 通配符查 keyword 字段(不分词,整词作为 token)
es_query({"query": {"wildcard": {"content.keyword": {"value": "*事假*"}}}})
方案 C:用单字查询(适配分词结果)
适用场景:布尔、短语、模糊
# must_not 用单字
{"must_not": [{"match": {"content": "婚"}}]}
# 短语用单字 + slop=0
{"match_phrase": {"content": {"query": "提前", "slop": 0}}}
# 模糊用单字
{"fuzzy": {"content": {"value": "请", "fuzziness": 1}}}
5.3 选型建议
- 中文为主:可装 IK 分词器 + 同义词库
- 脚本 demo:用
content.keyword+ 单字查询绕过分词限制 - 多语言:用
ik_smart(粗粒度分词)+ik_max_word(细粒度索引)
6. 调参对比:让检索更精准
6.1 BM25 参数(k1k_1k1, bbb)
参数语义
-
k1k_1k1(词频饱和参数,默认 1.2,范围 0∼30 \sim 30∼3):
- k1=0k_1=0k1=0:词频不影响分数(只看是否出现)
- k1=∞k_1=\inftyk1=∞:词频线性影响(出现 10 次是 1 次的 10 倍)
- k1=1.2k_1=1.2k1=1.2:经典推荐值,平衡词频影响
-
bbb(长度归一化,默认 0.75,范围 0∼10 \sim 10∼1):
- b=0b=0b=0:完全不做长度归一化(短文档没优势)
- b=1b=1b=1:完全归一化(长文档没优势)
- b=0.75b=0.75b=0.75:经典推荐值
代码
# 调高 k1 让高频词更相关,调低 b 让短文档得分更高
tuned_bm25 = make_index(AsyncBM25Strategy(k1=1.5, b=0.5))
调参经验
- 短查询为主 → 调高 k1(1.5~2.0)
- 文档长度差异大 → 调低 b(0.5)
- 数据集特定(医学、法律)→ 在验证集上 grid search
6.2 距离度量对比(COSINE / DOT_PRODUCT / EUCLIDEAN)
原理
向量相似度有多种度量方式:
| 度量 | 公式 | 含义 | 适用 |
|---|---|---|---|
| COSINE | A⋅B∣A∣⋅∣B∣\frac{\mathbf{A} \cdot \mathbf{B}}{|\mathbf{A}| \cdot |\mathbf{B}|}∣A∣⋅∣B∣A⋅B | 方向相似度,忽略向量长度 | 文本语义检索(最常用) |
| DOT_PRODUCT | A⋅B\mathbf{A} \cdot \mathbf{B}A⋅B | 同时考虑方向和长度 | 已归一化的向量 |
| EUCLIDEAN | ∣A−B∣|\mathbf{A} - \mathbf{B}|∣A−B∣ | 空间几何距离 | 图像检索、聚类 |
代码
from elasticsearch.helpers.vectorstore._utils import DistanceMetric
for name, metric in [
("COSINE", DistanceMetric.COSINE),
("DOT_PRODUCT", DistanceMetric.DOT_PRODUCT),
("EUCLIDEAN", DistanceMetric.EUCLIDEAN_DISTANCE),
]:
with suppress_stderr():
res = make_index(AsyncDenseVectorStrategy(distance=metric))\
.as_retriever(similarity_top_k=1, embed_model=embed_model)\
.retrieve(QUERY)
if res: print(f"{name}: {res[0].score:.4f}")
核心细节:EUCLIDEAN 在 ES 8.x 中名为
EUCLIDEAN_DISTANCE(不是L2_NORM),调用错会抛AttributeError。
选择策略
- 文本检索:COSINE(默认推荐)
- Embedding 已 L2 归一化:DOT_PRODUCT(计算更快,等价于 COSINE)
- 不确定:用 COSINE 不会错
7. 过滤增强:元数据筛选
原理
在向量检索前先用结构化字段(分类、标签、时间)过滤,缩小搜索空间。常用于"按权限过滤"(多租户系统)、“按时间过滤”(新闻系统)、“按分类过滤”(电商系统)。
代码
from llama_index.core.vector_stores import MetadataFilters, ExactMatchFilter
meta_index = VectorStoreIndex.from_documents([
Document(text="事假需提前1个工作日申请", metadata={"category": "leave", "level": "员工"}),
Document(text="年休假需提前7个工作日申请", metadata={"category": "leave", "level": "经理"}),
Document(text="婚假需提前7个工作日申请", metadata={"category": "wedding"}),
], embed_model=embed_model)
# 过滤:只检索 category=leave 的文档
filtered = meta_index.as_retriever(
similarity_top_k=2,
filters=MetadataFilters(filters=[ExactMatchFilter(key="category", value="leave")])
).retrieve("请假")
与 ES 映射配合
ES 中元数据字段建议用 keyword 类型(不分析、精确匹配):
- 数字/枚举:整数直接匹配
- 字符串:必须
keyword字段(不能用text字段,text 会被分词)
在 RAG 中的应用
- 权限控制:根据用户身份加
ExactMatchFilter(key="department", value=user.dept) - 时间窗口:
RangeFilter(key="publish_date", gte="2024-01-01") - 多条件组合:
MetadataFilters(filters=[...], condition="and")或"or"
8. 重排序:Cross-Encoder 精排
原理
向量检索是"粗排"(快但不够准),Rerank 是"精排"(慢但准)。原理是 Cross-Encoder:把"查询+文档"拼在一起送入 BERT 类模型,输出 0~1 的相关性分数。比向量检索的双塔模型(bi-encoder)准确率高 10~20%。
双塔 vs 交叉编码器:
- Bi-Encoder:query 和 doc 分别编码 → 向量比对(快)
- Cross-Encoder:query+doc 联合编码 → 直接打分(准)
本地实现(bge-reranker-base)
from llama_index.core.postprocessor import SentenceTransformerRerank
LOCAL_RERANK_PATH = "/Users/chenweifeng/modelscope_cache/Xorbits/bge-reranker-base"
rerank = SentenceTransformerRerank(model=LOCAL_RERANK_PATH, top_n=2)
query_engine = vector_index.as_query_engine(
similarity_top_k=5, # 粗排取 5 个
node_postprocessors=[rerank] # 精排保留 2 个
)
response = query_engine.query(QUERY)
选型建议
| 模型 | 大小 | 速度 | 准确度 | 适用 |
|---|---|---|---|---|
bge-reranker-base |
1.1GB | 中 | 高 | 中文场景常用 |
bge-reranker-large |
2.5GB | 慢 | 更高 | 准确度优先 |
gte-rerank (DashScope) |
API | 中 | 高 | 不想本地部署 |
说明:脚本中用
bge-reranker-base本地模型(路径见LOCAL_RERANK_PATH),该模型可从 ModelScope 镜像下载。
9. 智能检索:自动化与可解释
9.1 AutoRetriever:自动路由
原理
让 LLM 自动决定"应该用什么过滤条件"+“检索什么内容”。用户提供 VectorStoreInfo(含 metadata 字段描述),LLM 根据查询自动生成过滤表达式。
代码
from llama_index.core.retrievers import VectorIndexAutoRetriever
from llama_index.core.vector_stores.types import VectorStoreInfo, MetadataInfo
auto = VectorIndexAutoRetriever(
index=vector_index,
vector_store_info=VectorStoreInfo(
content_info="员工手册",
metadata_info=[
MetadataInfo(name="file_name", type="str", description="文件名"),
# 可继续加 author, date 等
],
),
llm=llm,
similarity_top_k=2,
)
result = auto.retrieve("经理可以请什么假?")
工作流程
- LLM 看到查询"经理可以请什么假?" + metadata 描述
- LLM 生成:
filter={"level": "经理"}+ 改写查询 - 内部调用 vector_index 并应用过滤
- 返回过滤后的结果
适用场景
- 多租户权限过滤
- 时间范围 + 分类组合
- 用户不需要知道 metadata schema
9.2 CitationQueryEngine:带引用的问答
原理
在生成的答案中标注引用来源(如"事假需提前申请[1]"),让用户能追溯答案依据。LLM 在生成时会插入 [1]、[2] 标记,对应 source_nodes 列表。
代码
from llama_index.core.query_engine import CitationQueryEngine
from llama_index.core import get_response_synthesizer
engine = CitationQueryEngine(
retriever=get_retriever(vector_index),
response_synthesizer=get_response_synthesizer(response_mode="compact"),
citation_chunk_size=256,
)
resp = engine.query(QUERY)
print(f"回答: {resp.response}") # 含 [1][2] 引用标记
print(f"来源: {len(resp.source_nodes)} 个节点")
实际输出示例
回答: 员工因私事必须本人处理时,可申请事假[1]。需提前申请并获得直属主管批准[1];
如遇紧急情况,可事后补办手续[2]。事假为无薪假[1]。
来源:
[1] "事假需提前1个工作日申请,按日扣除工资..."
[2] "紧急情况可事后补办手续..."
适用场景
- 医疗、法律、金融等可解释性要求高的领域
- 减少 LLM 幻觉(用户可核查来源)
- 学术研究、报告生成
10. 统计分析:索引聚合
原理
ES 的聚合(Aggregation)类似 SQL 的 GROUP BY,可以统计每个分类有多少文档、每个时间段有多少条记录等。常用于:
- 数据分析(“哪个文件最多”)
- 监控(“索引增长趋势”)
- 检索辅助(先聚合后检索)
代码
r = es_client.search(index=INDEX_NAME, body={
"size": 0, # 不返回文档,只要聚合
"aggs": {
"by_file": { # 聚合名
"terms": { # terms 聚合(类似 GROUP BY)
"field": "metadata.file_name.keyword", # 按 file_name 分组
"size": 10 # 取前 10
}
}
}
})
print(f"总文档数: {r['hits']['total']['value']}")
for bucket in r["aggregations"]["by_file"]["buckets"]:
print(f" {bucket['key']}: {bucket['doc_count']} 个")
常用聚合类型
| 类型 | 用途 | 示例 |
|---|---|---|
terms |
分组统计 | 每个文件多少文档 |
date_histogram |
时间分布 | 每天/每月多少条 |
avg / sum / min / max |
数值统计 | 平均文档长度 |
nested |
嵌套字段聚合 | 评论的回复数 |
11. 总结:20 种检索方式原理速查
| 编号 | 方式 | 原理 | 适用场景 |
|---|---|---|---|
| 2.1 | BM25 | 词频 + 逆文档频率 + 长度归一化 | 关键词检索、专有名词 |
| 2.2 | Dense Vector | Embedding + 余弦相似度 | 语义检索、同义匹配 |
| 3.1 | 手动 RRF | 排名倒数加权求和 | 多路异构融合 |
| 3.2 | 加权平均 | 分数 ×\times× 权重求和 | 同尺度分数融合 |
| 3.3 | QueryFusion | LlamaIndex 内置 RRF | 快速上手混合检索 |
| 4.1 | 字段加权 | ^N 提升字段权重 |
title vs body 区分 |
| 4.2 | 布尔查询 | must + should + must_not | 复杂条件组合 |
| 4.3 | 短语查询 | 严格词序 + slop 容错 | 固定短语、成语 |
| 4.4 | 通配符 | * / ? 正则匹配 |
前缀搜索、模糊模式 |
| 4.5 | 模糊查询 | 编辑距离 | 拼写纠错、OCR 文本 |
| 4.6 | 高亮查询 | 标记匹配片段 | 可解释性展示 |
| 4.7 | 函数评分 | filter + weight / decay | 时效性、热门加权 |
| 5.1 | BM25 调参 | k1 / b 参数 | 数据集适配 |
| 5.2 | 距离度量 | COSINE / DOT / L2 | 向量模型适配 |
| 6 | 元数据过滤 | keyword 字段精确匹配 | 权限、分类、时间 |
| 7.1 | bge-reranker | Cross-Encoder 精排 | 准确度优先 |
| 8.1 | AutoRetriever | LLM 自动选过滤 | 多租户、动态 schema |
| 8.2 | CitationQuery | 答案带 [1][2] 引用 |
医疗、法律、报告 |
| 9 | 索引聚合 | terms / histogram / avg | 监控、统计 |
总结:脚本中演示的 20 种检索方式覆盖了单路检索、多路融合、ES 原生 DSL、调参、过滤、重排序、智能检索、统计等全场景。理解每种检索的算法原理,才能根据具体业务选择合适的方案。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)