
Hot 100 --- 排序链表
本文概览:本文以LeetCode经典题目"排序链表"为例,从暴力选择最小节点的思路入手,分析为什么 O(n log n) 的时间复杂度自然指向归并排序,再结合代码讲解如何用快慢指针拆分链表、递归排序左右链表并合并两个有序链表
一、题目
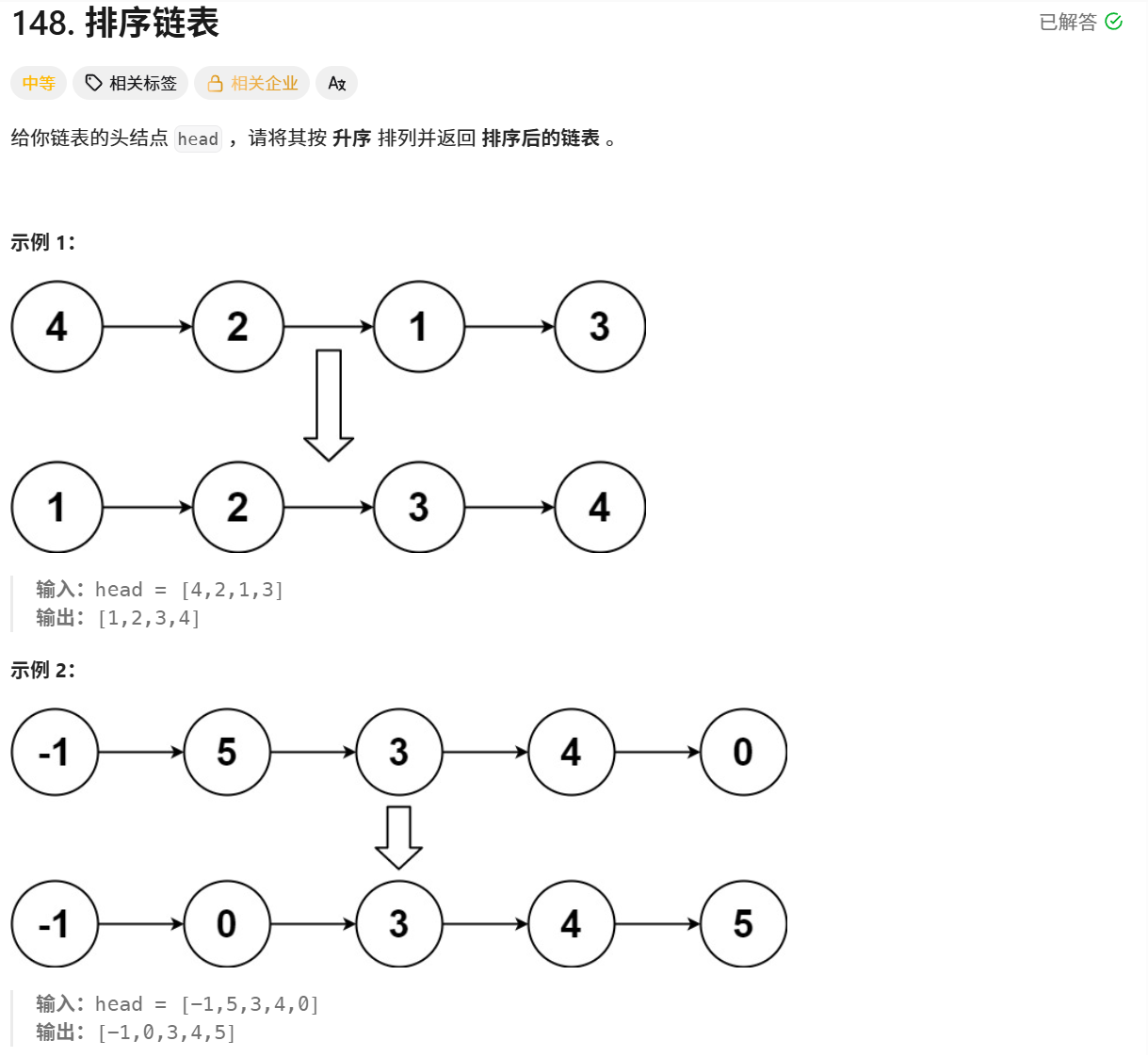
二、题目分析
给定链表的头节点 head,要求将链表按升序排列,并返回排序后的链表
目标:对原本无序的链表进行排序
题目难点:要求时间复杂度为 O(n log n),并尽量满足常数级空间复杂度
链表排序和数组排序不太一样。数组可以随机访问,很多排序算法写起来比较方便;但链表只能从前往后遍历,无法通过下标直接访问某个位置,所以更适合使用归并排序
思路概览
Java实现代码如下
public ListNode sortList(ListNode head) {
// 递归出口
if (head == null || head.next == null) {
return head;
}
// 初始化快慢指针
ListNode slow = head;
ListNode fast = head.next;
// 快慢指针找到中间节点
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
// mid 是右半部分的头节点
ListNode mid = slow.next;
// 断开左半部分和右半部分的连接
slow.next = null;
ListNode left = sortList(head);
ListNode right = sortList(mid);
// 合并两个有序链表
return merge(left, right);
}
private ListNode merge(ListNode left, ListNode right) {
ListNode dummy = new ListNode(0);
ListNode cur = dummy;
while (left != null && right != null) {
if (left.val < right.val) {
cur.next = left;
left = left.next;
} else {
cur.next = right;
right = right.next;
}
cur = cur.next;
}
// 合并剩余的节点
cur.next = left != null ? left : right;
return dummy.next;
}
思路简要说明
-
分割链表:使用快慢指针找到链表中点,将链表切成左右两半
-
递归排序:分别对左半部分和右半部分继续执行排序,直到每个子链表只剩一个节点
-
合并有序链表:当左右链表都已经有序后,使用双指针将它们合并成一个有序链表
注意:这份代码是递归归并排序,时间复杂度满足 O(n log n)。如果严格计算递归调用栈,空间复杂度是 O(log n);如果题目严格要求 O(1) 额外空间,需要使用自底向上的迭代归并。本文重点讲解这份递归写法,因为它最符合从思路到代码的理解过程
三、思路详解
暴力解法入手
最直接的想法是:每次遍历链表,找到当前链表中的最小节点,把它取出来接到新链表后面,然后继续在旧链表中寻找下一个最小节点
这个过程类似选择排序:
原链表:4 → 2 → 1 → 3
第1轮:找到最小值1,取出,结果链表:1
第2轮:找到最小值2,取出,结果链表:1 → 2
第3轮:找到最小值3,取出,结果链表:1 → 2 → 3
第4轮:找到最小值4,取出,结果链表:1 → 2 → 3 → 4
这个思路虽然直观,但问题很明显:
- 每找一个最小节点,都要遍历一遍剩余链表
- 删除旧链表中的最小节点,还要维护它前一个节点的指针
- 整体操作非常繁琐
复杂度上也不理想:
- 时间复杂度:O(n²),每一轮都要扫描剩余节点
- 空间复杂度:如果重新创建新链表节点,空间复杂度也会增加;如果原地摘节点,指针操作又会更复杂
所以这种方法不适合本题
为什么想到归并排序?
题目要求时间复杂度是 O(n log n)。看到这个复杂度,很自然会想到几种经典排序算法:快速排序、堆排序、归并排序
但对于链表来说,归并排序非常合适,原因是:
- 链表适合拆分:用快慢指针可以找到中点,把链表拆成两半
- 链表适合合并:合并两个有序链表时,只需要改
next指针,不需要像数组那样频繁移动元素 - 归并排序符合分治思想:先把大链表拆成小链表,小链表天然有序,再逐层合并
归并排序的核心思想就是:
先分:把链表不断拆成左右两半
再治:当每段链表只剩一个节点时,它天然有序
后合:把两个有序链表合并成一个更大的有序链表
这正好适合链表排序
分治过程怎么理解?
假设链表是:
4 → 2 → 1 → 3
归并排序会先不断拆分:
4 → 2 → 1 → 3
拆成:
4 → 2 1 → 3
继续拆:
4 2 1 3
当每个链表只剩一个节点时,它们天然有序
然后开始合并:
4 和 2 合并成:2 → 4
1 和 3 合并成:1 → 3
再合并:
2 → 4 和 1 → 3
最终得到:1 → 2 → 3 → 4
所以归并排序的关键不是一开始就把链表排好,而是不断拆到最小,再一层一层合并回来
第一步:找到中点并拆分链表
代码中使用快慢指针找到链表中点:
ListNode slow = head;
ListNode fast = head.next;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
这里 slow 每次走一步,fast 每次走两步。当 fast 到达末尾时,slow 就在链表中间附近
为什么 fast 初始化为 head.next,而不是 head?
这是为了让链表在偶数长度时,slow 停在左半部分的最后一个节点,方便断开链表
例如:
4 → 2 → 1 → 3
如果 fast = head.next,最后 slow 会停在节点 2:
4 → 2 | 1 → 3
↑
slow
这样就可以:
ListNode mid = slow.next;
slow.next = null;
得到:
左半部分:4 → 2
右半部分:1 → 3
mid 是右半部分的头节点,slow.next = null 是非常关键的一步,它真正把原链表断成了两个独立链表
如果不执行 slow.next = null,左链表仍然会连着右链表,递归时就无法正确缩小问题规模,甚至可能导致无限递归
第二步:递归排序左右链表
拆分完成后,代码继续递归排序左右两边:
ListNode left = sortList(head);
ListNode right = sortList(mid);
这里要注意:此时的 left 和 right 不是简单的原始左右链表,而是排序之后的左右链表头节点
也就是说:
left = sortList(head) // 返回排好序的左链表
right = sortList(mid) // 返回排好序的右链表
递归什么时候停止?
if (head == null || head.next == null) {
return head;
}
当链表为空或只有一个节点时,它天然有序,直接返回即可
这就是归并排序中"分到最小"的终点
第三步:合并两个有序链表
当左右两边都排好序后,就可以合并了
return merge(left, right);
合并两个有序链表的思路很简单:
- 比较
left.val和right.val - 谁小,就把谁接到结果链表后面
- 被接走的链表指针向后移动
- 重复这个过程,直到其中一条链表为空
代码如下:
private ListNode merge(ListNode left, ListNode right) {
ListNode dummy = new ListNode(0);
ListNode cur = dummy;
while (left != null && right != null) {
if (left.val < right.val) {
cur.next = left;
left = left.next;
} else {
cur.next = right;
right = right.next;
}
cur = cur.next;
}
cur.next = left != null ? left : right;
return dummy.next;
}
这里的 dummy 是哑节点,用来简化结果链表的拼接。cur 始终指向结果链表的尾节点
比如合并:
left: 2 → 4
right: 1 → 3
过程如下:
| 步骤 | left | right | 选择 | 结果链表 |
|---|---|---|---|---|
| 1 | 2 | 1 | 1更小 | 1 |
| 2 | 2 | 3 | 2更小 | 1 → 2 |
| 3 | 4 | 3 | 3更小 | 1 → 2 → 3 |
| 4 | 4 | null | 接上剩余left | 1 → 2 → 3 → 4 |
最后这句:
cur.next = left != null ? left : right;
表示其中一个链表为空后,另一个链表剩下的部分已经是有序的,直接接到结果链表后面即可
完整递归流程示例
以 4 → 2 → 1 → 3 为例:
sortList(4→2→1→3)
├── sortList(4→2)
│ ├── sortList(4) → 4
│ ├── sortList(2) → 2
│ └── merge(4,2) → 2→4
├── sortList(1→3)
│ ├── sortList(1) → 1
│ ├── sortList(3) → 3
│ └── merge(1,3) → 1→3
└── merge(2→4, 1→3) → 1→2→3→4
可以看到,排序是在合并时完成的。拆分只是把问题规模变小,真正让链表有序的是每一层的 merge
四、复杂度分析
-
时间复杂度:O(n log n)
- 每一层递归都要合并所有节点,总共 O(n)
- 链表每次被分成两半,递归层数约为 O(log n)
- 所以总时间复杂度为 O(n log n)
-
空间复杂度:O(log n)
- 这份递归写法需要递归调用栈
- 如果严格要求常数级额外空间,需要改写为自底向上的迭代归并排序
五、总结
这道题的关键是看到时间复杂度要求 O(n log n),自然想到归并排序
链表归并排序的核心流程是:
- 用快慢指针找到中点
- 断开链表,分成左右两半
- 递归排序左右链表
- 合并两个有序链表
其中最关键的代码是:
ListNode mid = slow.next;
slow.next = null;
ListNode left = sortList(head);
ListNode right = sortList(mid);
return merge(left, right);
这几行代码完整体现了归并排序的"分、治、合"过程
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)