

Oracle数据库:oracle组函数,聚合函数,多行函数,avg,sum,min,max,count,group by,having
Oracle数据库:oracle组函数,聚合函数,多行函数,avg,sum,min,max,count,group by,having
Oracle数据库:oracle组函数,聚合函数,多行函数,avg,sum,min,max,count,group by,having
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
oracle系列文章:
【1】Oracle数据库:啥是oracle数据库?你为啥要学oracle?
【2】Oracle数据库:oracle 11g安装教程,已安装好的oracle各个文件夹的作用,oracle用户权限怎么样
【3】Oracle数据库:oracle启动,oracle客户端工具plsql安装教程和使用方法
【4】Oracle数据库:创建表空间,创建新用户,给用户分配对象、角色和系统权限,登录新用户建表
【5】Oracle数据库:链接配置,包括sqlnet.ora里面的transnames.ora配置数据库标识符SID,listener暂时简单了解
【6】Oracle数据库:net configureation assistant工具配置监听listener,配置本地网络访问服务器上的数据库
【7】Oracle数据库:oracle字符类型、数字类型、创建表表名的命名规则
【8】Oracle数据库:约束条件:主键约束、唯一约束、检查约束、非空约束、外键约束、默认值填写
【9】Oracle数据库:表的关系:一对多,一对一,多对多,一一继承和修改的关系,表不是重点,重点是数据和约束关系
【10】Oracle数据库:sql语言结构,数据查询语言DQL,select * from table;算术,别名,连接,去重等操作
【11】Oracle数据库:约束行限制where语句,判断条件,比较条件,字符串日期格式,in,like,escape,null语句
【12】Oracle数据库:逻辑运算and,or,not和各种运算的优先级控制
【13】Oracle数据库:排序order by语句,select from where order by的执行先后顺序,各种样例
【14】Oracle数据库:oracle函数,单行函数,多行函数,upper,lower,initcap,字符串函数
【15】Oracle数据库:数字函数,日期函数,round,trunc,mod,months_between,add_months,next_day,last_day,sysdate
【16】Oracle数据库:oracle数据类型转换to_char()日期和数字转字符,to_number()字符转数字,to_date()字符转日期函数
【17】Oracle数据库:oracle函数嵌套,nvl函数,nvl2函数,nullif函数,coalesce合并函数
【18】Oracle数据库:条件表达式case when then else end,decode函数,oracle单行函数练习示例
【19】Oracle数据库:oracle多表查询,等值连接,非等值连接,自连接的sql语句和规则
【20】Oracle数据库:oracle外连接left/right/full outer join on,oracle扩展的左右外连接展示符号(+)
【21】Oracle数据库:自然连接natural join,using语句,注意避免写交叉连接
【22】Oracle数据库:oracle内连接inner join on,多表查询各种自链接、内连接、外连接的练习示例
oracle组函数,聚合函数,多行函数

单行函数是处理多行,输出多行
分组聚合函数是处理多行,输出一行
这种就是要底层的取max函数了


这些我们在数据结构与算法中讲太多了
这都是弱鸡操作


可能里面会用单行函数操作一波
嵌套好说
AVG和SUM搞数字类型的处理


干一波
SQL> select avg(salary) avg, sum(salary) sum from employees;
AVG SUM
---------- ----------
6461.83177 691416
既然没有group by分组
那就是默认对整个表做一个组来计算
这种返回的结果就一条
这就是分组函数
min和max函数

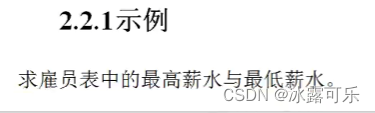
SQL> select min(salary) min, max(salary) max from employees;
MIN MAX
---------- ----------
2100 24000
太easy
SQL> select min(last_name) min, max(last_name) max from employees;
MIN MAX
------------------------- -------------------------
Abel Zlotkey
里面都会自动排序的
SQL> select min(hire_date) min, max(hire_date) max from employees;
MIN MAX
----------- -----------
2001/1/13 2008/4/21
好说
组函数的使用要注意的地方
avg和sum,你想要投影名字,这种单行函数,是不行的
因为它返回结果很多,没法跟你一个结果放一起
select last_name,salary, avg(salary) avg, sum(salary) sum from employees
ORA-00937: 不是单组分组函数
gg
回头我们用group by再分组的列那搞清楚这个事情
count函数,返回表中的行数


根据返回的结果集中的所有数据计算
有where限制,就是限制之后的结果计算all
SQL> select count(*) from employees;
COUNT(*)
----------
107
表有107行
SQL> select count(*) from employees where commission_pct is not null;
COUNT(*)
----------
35
有条件,就是条件筛选之后的,因为条件语句的执行比select早
SQL> select count(*) from employees e where e.last_name like '%a%';
COUNT(*)
----------
52
有52个含有a字符的名字

相当于颗粒度细致了些许

SQL> select count(commission_pct) from employees e where e.department_id=80;
COUNT(COMMISSION_PCT)
---------------------
34
是count中指定的参数x不为null,节约了一个 is not null
懂?

剔除重复行
SQL> select count(distinct e.department_id) from employees e;
COUNT(DISTINCTE.DEPARTMENT_ID)
------------------------------
11
SQL> select count(*) from employees e;
COUNT(*)
----------
107
SQL> select count(e.department_id) from employees e;
COUNT(E.DEPARTMENT_ID)
----------------------
106
107个数据
1个的部门是null
但是重复去掉后
拢共就11个部门
组函数就这几个,就很简单
组函数会忽略null值,通过nvl,nvl2转化为真实的数值


直接就忽略了null
不管
SQL> select avg(commission_pct) from employees;
AVG(COMMISSION_PCT)
-------------------
0.222857142857143
SQL> select count(commission_pct) from employees;
COUNT(COMMISSION_PCT)
---------------------
35
只有35个人有佣金的
那其他的null默认忽略了
你想将这些null转化为某个值的话
可以的

就转化0了
SQL> select count(nvl(commission_pct,0)) from employees;
COUNT(NVL(COMMISSION_PCT,0))
----------------------------
107
SQL> select avg(nvl(commission_pct,0)) from employees;
AVG(NVL(COMMISSION_PCT,0))
--------------------------
0.0728971962616822
这个值小多了,为啥呢,分母大了哈哈哈哈哈哈
懂???
知道组函数默认干掉null了吧
创建分组:group by

一组一组搞,这样很舒服
比如男生的平均薪资,女生的平均薪资,这样就要分为俩组
或者部门分开,再算薪资平均值
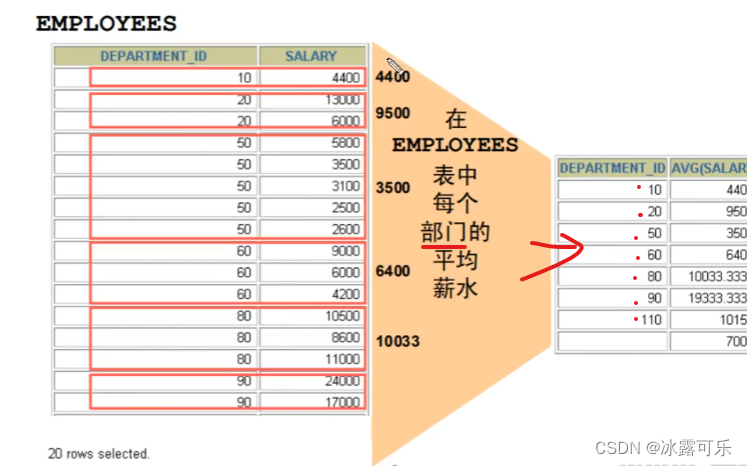

where之后紧跟group by,先分组
再去做order by

where是总共条件拿数据
然后分组
分组完默认升序排序
列别名后执行,因为数据取出来在前面
having子句约束分组的结果,不能用where

SQL> select department_id,job_id,sum(salary) from employees group by department_id,job_id order by sum(salary);
DEPARTMENT_ID JOB_ID SUM(SALARY)
------------- ---------- -----------
10 AD_ASST 4400
20 MK_REP 6000
40 HR_REP 6500
SA_REP 7000
110 AC_ACCOUNT 8300
70 PR_REP 10000
30 PU_MAN 11000
110 AC_MGR 12008
100 FI_MGR 12008
20 MK_MAN 13000
30 PU_CLERK 13900
90 AD_PRES 24000
60 IT_PROG 28800
90 AD_VP 34000
50 ST_MAN 36400
100 FI_ACCOUNT 39600
50 ST_CLERK 55700
80 SA_MAN 61000
50 SH_CLERK 64300
80 SA_REP 243500
20 rows selected
我们首先,按照部门,工作级别来分组
然后如果你想要再约束一下sum,过滤这个sum大于5000的菜显示的话
这时,不能用where,而只能用having
SQL> select department_id,job_id,sum(salary) from employees group by department_id,job_id having sum(salary)>5000 order by sum(salary) ;
DEPARTMENT_ID JOB_ID SUM(SALARY)
------------- ---------- -----------
20 MK_REP 6000
40 HR_REP 6500
SA_REP 7000
110 AC_ACCOUNT 8300
70 PR_REP 10000
30 PU_MAN 11000
110 AC_MGR 12008
100 FI_MGR 12008
20 MK_MAN 13000
30 PU_CLERK 13900
90 AD_PRES 24000
60 IT_PROG 28800
90 AD_VP 34000
50 ST_MAN 36400
100 FI_ACCOUNT 39600
50 ST_CLERK 55700
80 SA_MAN 61000
50 SH_CLERK 64300
80 SA_REP 243500
19 rows selected
看见having的牛逼之处了吗
其实就是分组函数下的where
你用where就不对了

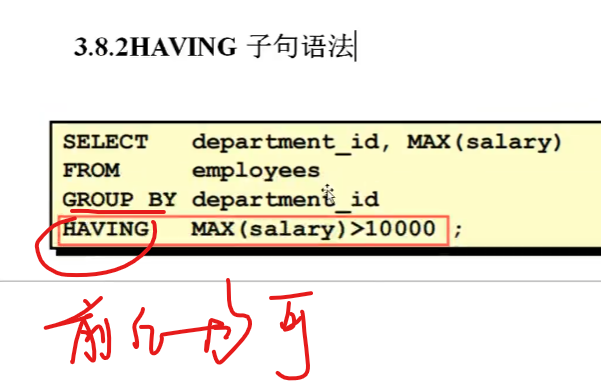
having也可以放在group by左边
常规下放在having之后,这样逻辑上很好理解

按照部门分组
SQL> select department_id,max(e.salary) from employees e group by department_id having max(e.salary)>10000;
DEPARTMENT_ID MAX(E.SALARY)
------------- -------------
100 12008
30 11000
90 24000
20 13000
110 12008
80 14000
6 rows selected
你要是不过滤
就可能比较多
SQL> select department_id,max(e.salary) from employees e group by department_id;
DEPARTMENT_ID MAX(E.SALARY)
------------- -------------
100 12008
30 11000
7000
90 24000
20 13000
70 10000
110 12008
50 8200
80 14000
40 6500
60 9000
10 4400
12 rows selected

要平均薪水
SQL> select e.department_id,avg(e.salary) from employees e group by department_id having max(e.salary)>10000;
DEPARTMENT_ID AVG(E.SALARY)
------------- -------------
100 8601.33333333
30 4150
90 19333.3333333
20 9500
110 10154
80 8955.88235294
6 rows selected
不过滤的
SQL> select e.department_id,avg(e.salary) from employees e group by department_id;
DEPARTMENT_ID AVG(E.SALARY)
------------- -------------
100 8601.33333333
30 4150
7000
90 19333.3333333
20 9500
70 10000
110 10154
50 3475.55555555
80 8955.88235294
40 6500
60 5760
10 4400
12 rows selected
懂?
好说having
总结
提示:重要经验:
1)
2)学好oracle,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)