
AI 编程代理把 GitHub 顶到容量压力:这事和 Java 后端有什么关系?
过去一周,技术圈有一条新闻很值得开发者看一眼:Business Insider 报道称,Microsoft 正在借助 AWS 资源来缓解 GitHub 因 AI 编程需求暴涨带来的容量压力。微软发言人确认 GitHub 正在采用多云策略,但没有点名 AWS。
这条新闻有传播点:微软、GitHub、AWS、AI 编程、容量不足,几个关键词放在一起,很容易变成云厂商八卦。但从开发者视角看,它真正值得关注的不是“微软竟然找亚马逊帮忙”,而是另一个信号:
AI 编程代理正在把软件研发从“人写代码,工具辅助”推向“人下任务,代理批量产出变更”。当这个变化开始影响 GitHub 这种基础设施的容量,说明 AI 编程已经不是 IDE 里的一个小功能,而是在改变研发系统本身的负载模型。
发生了什么
根据 Business Insider 的报道,GitHub 的开发活动正在被 AI 编程工具显著放大。报道中提到,GitHub commit 数量被预计从 2025 年的 10 亿级增长到 2026 年的 140 亿级。这个数字不一定适合被当成精确预测,但它足够说明趋势:AI 让“提交代码”这件事的边际成本下降了。
以前,一个开发者一天能写多少代码,受限于理解需求、改代码、跑测试、提交 PR、等待评审。现在,Copilot、Claude Code、Codex、Cursor 这类工具把其中一部分步骤自动化了。尤其是 coding agent,不只是补全一行代码,而是能根据 issue 或任务描述生成变更、创建分支、提交 PR,甚至并行跑多个任务。
GitHub 官方 Copilot 页面也已经把产品描述从“AI pair programmer”扩展到了更宽的研发工作流:可以在 IDE、终端、GitHub、MCP server 等位置工作,也可以把任务分配给 Copilot、Claude、Codex 等 agent,让它们在后台计划、探索和执行任务。
这意味着 GitHub 承载的不是原来那种“人类开发者手动提交”的节奏,而是越来越多 agent 驱动的代码变更、PR、CI 任务、review 事件和安全扫描。
为什么这条新闻会火
它火的原因不只是微软和 AWS 的竞争关系,而是它暴露了 AI 工程化里一个常被低估的问题:算力压力不只发生在模型训练和推理层,也会传导到开发者基础设施。
很多人讨论 AI 编程时,关注的是“它能不能写出正确代码”。这当然重要。但企业真正落地后,还会遇到另一组问题:
| 变化 | 对研发系统的影响 |
|---|---|
| agent 可以并行提交多个 PR | review、CI、分支管理压力上升 |
| 代码生成速度变快 | 质量门禁更容易成为瓶颈 |
| 变更数量增加 | 仓库、构建、制品、安全扫描成本上升 |
| 工具接入更多上下文 | 权限、审计、数据边界更复杂 |
| 多 agent 协作 | 冲突、重复实现、需求偏移更常见 |
这才是 Java 后端开发者应该关心的地方。AI 编程工具不是单纯提升个人效率,它会改变团队的研发吞吐量。一旦吞吐量上来,原来靠人工经验兜底的流程就会被放大出问题。
技术人真正该看什么
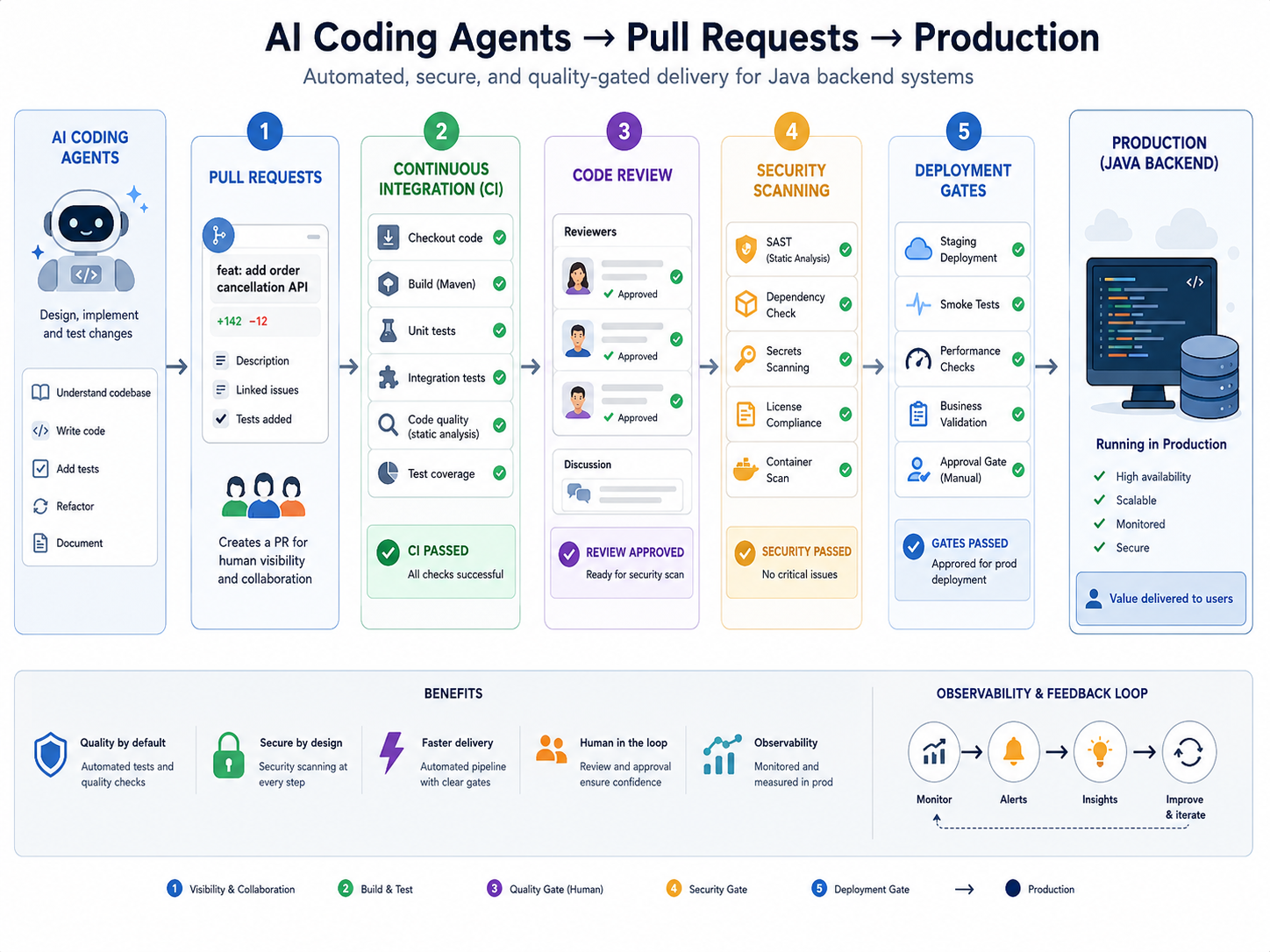
第一,要看 AI 代码产出的质量成本。
今年一些关于 AI coding agents 的实证研究已经开始关注这个问题。比如 AIDev 数据集统计了大量 agent-authored PR,用来研究真实 GitHub 项目中的 AI 代理使用情况。另有研究指出,AI 生成代码可能引入长期维护成本,问题并不总是在短期内被修复。
这和很多 Java 项目里的体验是一致的:AI 写 CRUD、DTO、测试样例、配置文件很快,但一旦进入事务边界、并发控制、缓存一致性、权限模型、异常语义,它就不再只是“能跑”这么简单。
第二,要看研发平台是否能承接更高频率的变更。
如果一个团队引入 AI agent 后,每天 PR 数翻倍,真正被考验的是这些能力:
- CI 是否足够快,否则开发者会在排队中失去收益。
- 单元测试和集成测试是否可信,否则 AI 产出的错误会进入主干。
- Code Review 是否有明确规则,否则 reviewer 会被低质量 PR 淹没。
- 分支策略是否清晰,否则 agent 并行开发会制造冲突。
- 安全扫描和依赖检查是否自动化,否则 AI 可能引入不合规代码。
- 日志、审计、权限是否完整,否则很难追踪“谁让 agent 做了什么”。
第三,要看工具链是否正在向多云、多模型、多代理方向演进。
这次 GitHub 容量压力背后,其实也能看到一个趋势:AI 应用越往工程深处走,越难只依赖单一模型、单一云或单一工具。模型侧要做路由和降级,平台侧要做弹性和隔离,企业侧要做权限和审计。
这和我们平时讲 AI 工程化是同一件事,只是发生在更大的平台上。
对 Java 后端团队的启发
如果你是 Java 后端开发者,不必因为这条新闻立刻去追某个新工具。但它提醒我们,接下来学习 AI 编程工具时,不应该只问“怎么让它帮我写代码”,还要问“怎么让它安全地进入团队流程”。
比较现实的做法是从低风险任务开始:
- 让 AI agent 处理测试补充、文档更新、简单重构,而不是一上来改核心交易链路。
- 对 agent 生成的 PR 打标签,单独统计通过率、返工率和线上问题。
- 对关键模块设置更严格的保护规则,比如必须人工 reviewer 通过。
- 在 Java 项目中强化 Checkstyle、SpotBugs、Error Prone、依赖漏洞扫描、架构规则校验。
- 把 CI 时间、失败原因、PR 修改轮次纳入观察,不要只看“生成了多少代码”。
尤其是 Spring Boot 和微服务项目,代码量往往不是最大问题。真正难的是业务边界、数据一致性、事务传播、幂等、权限、兼容性和线上可观测性。AI 可以生成代码,但它不天然理解你们公司过去几年踩过的坑。
所以,AI agent 最适合先成为“受控贡献者”,而不是“自动合并者”。
这件事离普通开发者远吗
如果只看“微软是否用 AWS”,那确实和大多数开发者距离很远。但如果看“AI 编程正在放大研发系统负载”,它其实已经很近了。
很多团队会在接下来一年遇到类似问题,只是规模更小:PR 变多、review 变累、CI 变慢、重复实现变多、生成代码质量参差不齐。原来一个高级开发能靠经验把住的口子,现在可能需要流程、工具和指标一起兜住。
对个人开发者来说,AI 编程工具当然值得用。但更值得训练的是判断力:哪些任务可以交给 agent,哪些任务只能让它辅助;哪些代码看起来正确但会埋工程风险;哪些流程必须自动化,否则效率提升会变成维护成本。
这条新闻真正有意思的地方在于,它把“AI 写代码”从个人效率话题,推到了研发基础设施话题。以后评价一个团队会不会用 AI,不是看它装了几个插件,而是看它能不能把 AI 产出的变更纳入测试、审查、安全、发布和回滚体系里。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)