
Ollama 安装部署教程:5 分钟在本地跑起 DeepSeek 大模型

如果你关注 AI 领域,大概率已经听说过 DeepSeek、Qwen、Gemma 这些名字。但每次想试用,要么得注册各种云平台,要么担心数据上传到第三方。Ollama 解决的就是这个问题——它让你在自己的电脑上直接跑大模型,一条命令安装,一条命令拉模型,全程本地运行。本文带你从零开始,把 Ollama 部署起来并跑通第一个对话。
一、项目背景
Ollama 是一个开源的本地大语言模型运行工具,核心能力是将 LLM 的推理过程完全放在本地执行。它封装了 llama.cpp 等底层推理引擎,向上提供统一的命令行接口和 REST API,让开发者不需要关心模型格式转换、量化、GPU 加速等底层细节。
核心功能:
- 一键拉取和运行主流开源模型(DeepSeek、Qwen、Gemma、Llama 等)
- 提供兼容 OpenAI 格式的 REST API,方便接入各类应用
- 支持 GPU 加速(CUDA/Metal/ROCm)
- 内置模型管理(列表、删除、复制、自定义 Modelfile)
- 可集成 Claude Code、Codex、OpenCode 等编程助手
适合场景:本地 AI 聊天、代码辅助、文档问答、API 服务搭建,以及任何不想把数据传出本机的 AI 应用开发。
官方GitHub的项目地址:
https://github.com/ollama/ollama
二、本文环境说明
- 操作系统:Windows 11 / Ubuntu 22.04(本文以 Docker 方式统一,跨平台通用)
- Docker 版本:Docker 24.x+,Docker Compose v2
- 部署方式:Docker(最低门槛,一行命令启动)
- 是否为简化方案:是,本文采用 Docker 快速部署,生产环境调优请参考官方文档
- 硬件要求:CPU 即可运行小模型(如 gemma4:2b);GPU 推荐用于 7B 以上模型
三、安装前准备
3.1 基础依赖检查
确认 Docker 已安装并正常运行:
docker --version
docker compose version
如果尚未安装 Docker,Windows 用户推荐 Docker Desktop,Linux 用户使用官方一键脚本:
curl -fsSL https://get.docker.com | sh
3.2 获取项目代码
Ollama 提供官方 Docker 镜像,无需克隆源码即可使用:
docker pull ollama/ollama
3.3 安装前注意事项
- 确保 11434 端口未被占用(Ollama API 默认端口)
- 模型文件较大(7B 模型约 4-5 GB),预留至少 20 GB 磁盘空间
- 如需 GPU 加速,Docker 需安装 nvidia-container-toolkit
四、安装与部署
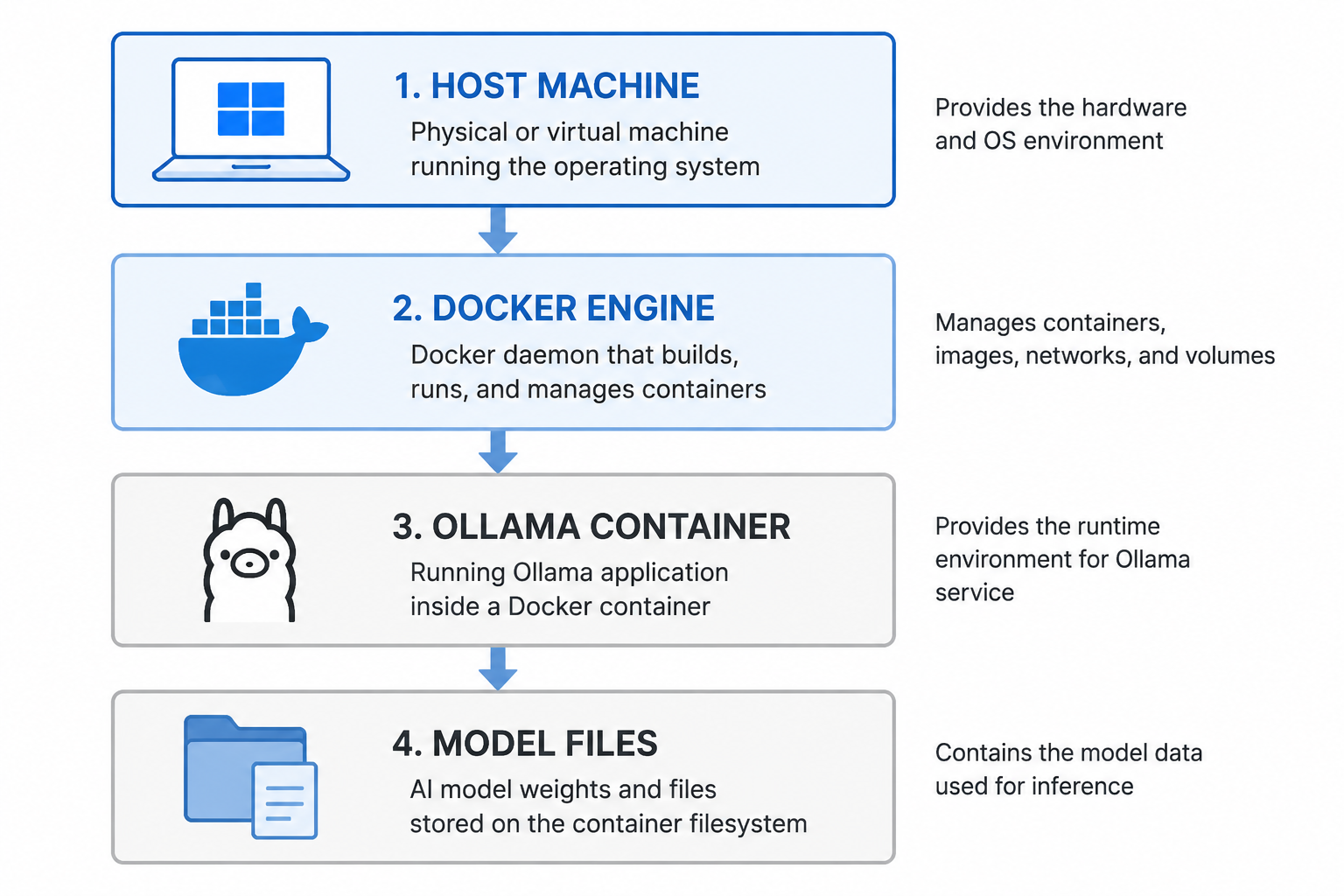
4.1 启动 Ollama 容器
CPU 模式(通用,无需额外配置):
docker run -d --name ollama -p 11434:11434 -v ollama_data:/root/.ollama ollama/ollama
参数说明:
-d:后台运行--name ollama:容器命名为 ollama-p 11434:11434:映射 API 端口-v ollama_data:/root/.ollama:持久化模型文件,避免容器删除后重新下载
GPU 模式(NVIDIA 显卡):
docker run -d --gpus all --name ollama -p 11434:11434 -v ollama_data:/root/.ollama ollama/ollama
4.2 验证容器状态
docker ps | grep ollama
看到 STATUS 为 Up 即表示启动成功。
4.3 非 Docker 安装方式(备选)
如果不想用 Docker,可以直接安装:
Windows(PowerShell 管理员模式):
irm https://ollama.com/install.ps1 | iex
Linux / macOS:
curl -fsSL https://ollama.com/install.sh | sh
五、配置说明
5.1 核心配置
Ollama 的配置主要通过环境变量控制。Docker 部署时可在 docker run 中通过 -e 传入:
| 环境变量 | 说明 | 默认值 |
|---|---|---|
OLLAMA_HOST |
API 监听地址 | 127.0.0.1:11434 |
OLLAMA_MODELS |
模型存储路径 | /root/.ollama/models |
OLLAMA_KEEP_ALIVE |
模型驻留内存时间 | 5m(5分钟后卸载) |
OLLAMA_NUM_PARALLEL |
并发请求数 | 1 |
5.2 最小可用配置
大多数场景下默认配置即可使用。如果需要允许局域网内其他设备访问 API:
docker run -d --name ollama -p 11434:11434 -e OLLAMA_HOST=0.0.0.0:11434 -v ollama_data:/root/.ollama ollama/ollama
5.3 容易踩坑的配置点
- OLLAMA_HOST 设为 0.0.0.0 后,任何能访问该端口的设备都可以调用 API,注意防火墙
- 模型存储路径:Docker 部署时已通过 volume 持久化,非 Docker 部署模型默认存在
~/.ollama/models,迁移时直接拷贝该目录即可 - KEEP_ALIVE 过短:频繁加载/卸载模型会显著增加首次响应延迟,建议设为
24h如果内存充裕
六、跑通第一个 Demo
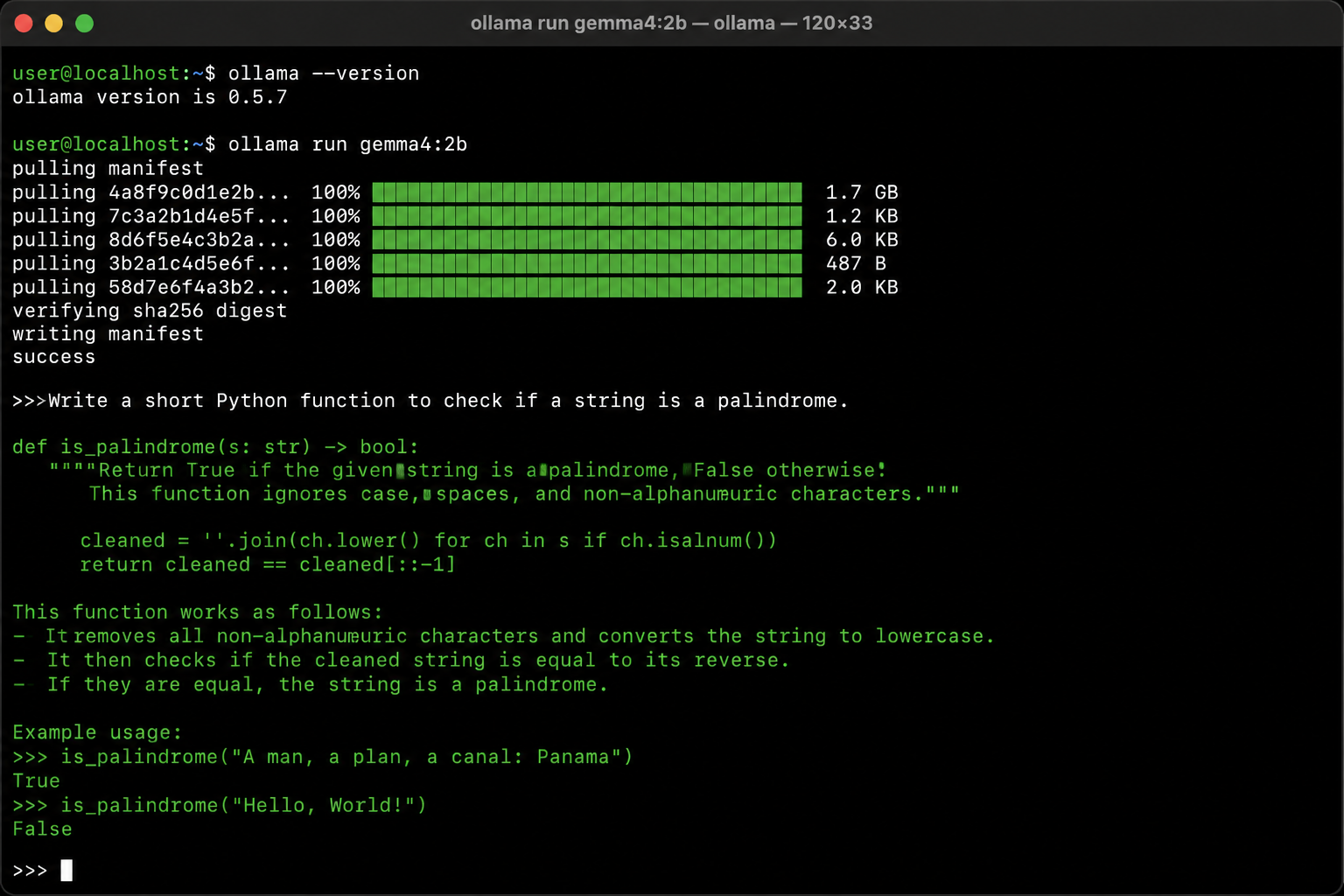
6.1 拉取模型
进入容器执行 ollama 命令:
docker exec -it ollama ollama pull gemma4:2b
gemma4:2b 是 Google 推出的轻量模型,约 1.6 GB,适合快速验证。也可以换成其他模型:
# DeepSeek 系列
docker exec -it ollama ollama pull deepseek-r1:7b
# 阿里 Qwen 系列
docker exec -it ollama ollama pull qwen3:4b
6.2 运行对话
docker exec -it ollama ollama run gemma4:2b
进入交互式对话界面后,直接输入问题即可:
>>> 用 Python 写一个快速排序
6.3 预期结果
模型会逐字输出代码和解释。看到模型正常回复即表示部署成功。按 Ctrl+D 或输入 /bye 退出对话。
七、效果验证
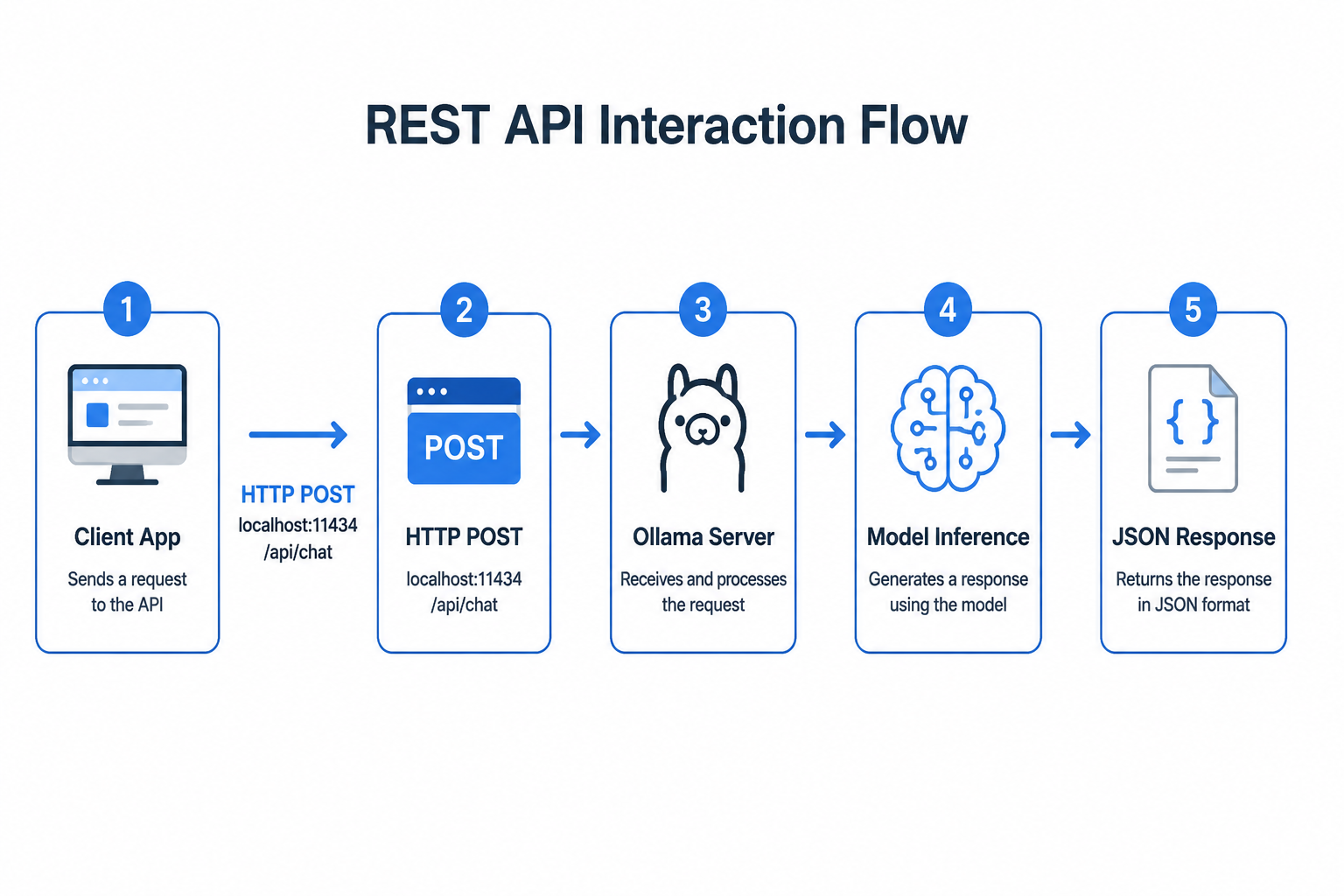
7.1 验证方式一:查看模型列表
docker exec -it ollama ollama list
输出示例:
NAME ID SIZE MODIFIED
gemma4:2b abc123def456 1.6 GB 2 minutes ago
7.2 验证方式二:REST API 调用
curl http://localhost:11434/api/chat -d '{
"model": "gemma4:2b",
"messages": [{"role": "user", "content": "你好,请用一句话介绍你自己"}],
"stream": false
}'
返回 JSON 中包含 message.content 字段即为正常。
7.3 验证方式三:Python SDK 调用
pip install ollama
from ollama import chat
response = chat(model='gemma4:2b', messages=[
{'role': 'user', 'content': '你好'}
])
print(response.message.content)
三种方式任一成功,说明 Ollama 部署完全正常。
八、常见报错与解决方案
8.1 端口被占用
错误现象:Error starting userland proxy: listen tcp4 0.0.0.0:11434: bind: address already in use
原因分析:11434 端口已被其他程序占用。
解决方案:
# 查看端口占用
netstat -ano | findstr 11434 # Windows
lsof -i :11434 # Linux/Mac
# 更换映射端口
docker run -d --name ollama -p 11435:11434 -v ollama_data:/root/.ollama ollama/ollama
8.2 模型下载缓慢或失败
错误现象:pull model manifest: dial tcp: lookup registry.ollama.ai: no such host
原因分析:网络环境导致无法访问 Ollama 模型仓库。
解决方案:配置镜像加速或使用代理:
docker run -d --name ollama -p 11434:11434 \
-e HTTP_PROXY=http://your-proxy:port \
-e HTTPS_PROXY=http://your-proxy:port \
-v ollama_data:/root/.ollama ollama/ollama
8.3 GPU 不可用
错误现象:模型加载后推理极慢,或日志显示 level=WARN msg="GPU not available"
原因分析:Docker 未配置 GPU 支持,或宿主机缺少 NVIDIA 驱动。
解决方案:
# 确认宿主机驱动
nvidia-smi
# 安装 nvidia-container-toolkit(Linux)
sudo apt install nvidia-container-toolkit
sudo systemctl restart docker
# 重新以 GPU 模式启动
docker run -d --gpus all --name ollama -p 11434:11434 -v ollama_data:/root/.ollama ollama/ollama
九、进阶说明
- 更多模型:访问 ollama.com/library 浏览全部可用模型
- 自定义模型:通过 Modelfile 调整系统提示词、温度参数,参考
ollama create命令 - OpenAI 兼容接口:Ollama 提供
/v1/chat/completions端点,可直接替换 OpenAI SDK 的 base_url - 接入 Web UI:推荐 Open WebUI,Docker 一行命令即可获得 ChatGPT 风格的交互界面
- 生产部署:配合 Nginx 反向代理 + systemd 守护,将 Ollama 作为团队内部 API 服务
- 源码阅读:核心推理引擎基于 llama.cpp,入口在
server/目录
十、总结
本文从 Docker 安装 Ollama 开始,到拉取模型、跑通对话、调用 API,覆盖了一个开发者从零到"能用"的完整路径。Ollama 的设计哲学就是降低门槛——不需要懂模型量化、不需要配 CUDA 环境、不需要写推理代码,一条命令就能让大模型在本地跑起来。
对于大多数个人开发者和中小团队来说,做到本文这一步已经足够日常使用。如果你想把 Ollama 接入自己的应用,它的 REST API 和 Python/JS SDK 也非常友好,基本就是改个 URL 的事情。
十一、继续深入
- 想做生产部署的开发者:关注 GPU 调优、并发配置、Nginx 反向代理
- 想研究源码的工程师:从 llama.cpp 推理引擎和 Ollama 的 server 层入手
- 想做业务接入的团队:利用 REST API 或 Python SDK 将 Ollama 集成到现有系统
- 想做二次开发的用户:研究 Modelfile 自定义模型、开发 Ollama 插件

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)