
使用 SGLang本地部署Deepseek R1
一、简介
![]()
最近Deepseek R1也是非常的火,正好最近无事可干,那么就本地跑一下这个玩一下吧
官方Github有各种推理平台的部署教程,有具体需求的可以看一下,本篇只是一篇个人的免踩坑快速部署过程
相信能够看到这篇博客的对他的性能已经有了一定的了解了,那么我也不多介绍了(其实是因为我也没看)
由于我的笔记本太过鸡肋,所以就跑一个蒸馏后的7B模型试试吧
由于大部分优秀的推理框架还是基于Linux的,所以使用的是WSL2安装了Ubuntu20.04来本地部署
直接部署在Windows还是不建议了,Deepseek给出的那些框架大部分都是不支持Windows的,我试了两个没跑通,最终还是转回Linux了
使用的是目前最优的SGLang框架GitHub - sgl-project/sglang: SGLang is a fast serving framework for large language models and vision language models.
二、环境配置
本博客使用的环境为
系统 Ubuntu 20.04
显卡 3060-Laptop
CUDA 12.4
Pytorch 2.5.1
Python 3.10
首先安装SGLang推理架构
需要注意的是,环境必须满足Python≥3.10 and <3.13
conda create -n SGLang python=3.10 -y
conda activate SGLangpip install --upgrade pip
pip install "sglang[all]" --find-links https://flashinfer.ai/whl/cu118/torch2.4/flashinfer/可能会有报错说连接不上服务器
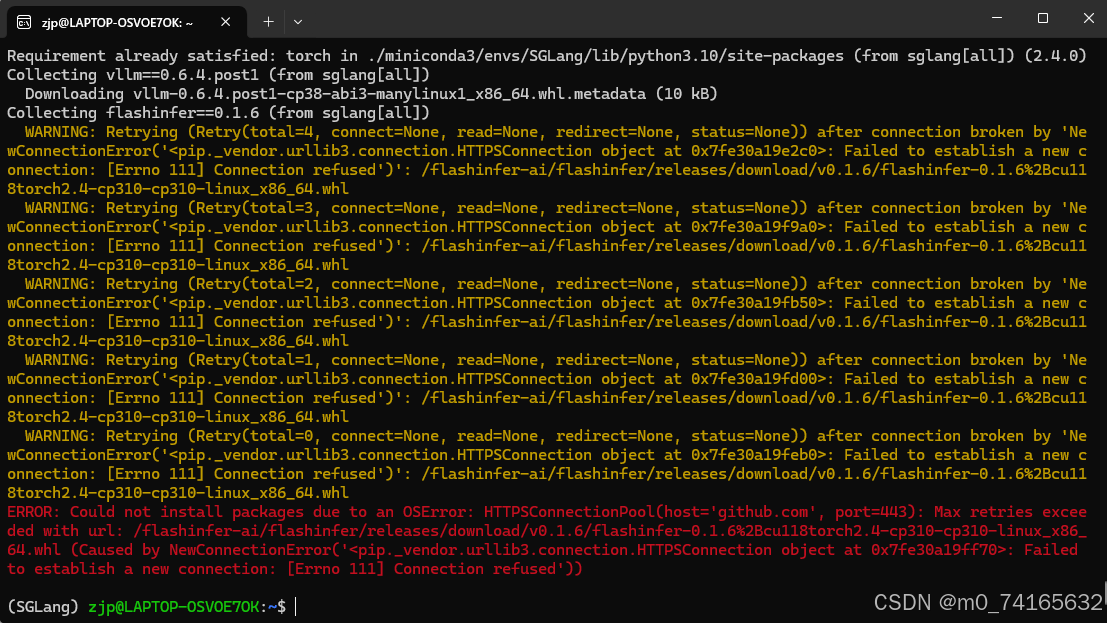
观察红色报错我们发现是flashinfer没有下载成功
这时候需要手动去https://flashinfer.ai/whl/cu118/torch2.4/flashinfer/下载报错里面说的对应版本的flashinfer,我这个需要的是flashinfer-0.1.6+cu118torch2.4-cp310-cp310然后再本地安装
这时候我们再执行一次上面的安装代码来安装未安装的包
pip install "sglang[all]" --find-links https://flashinfer.ai/whl/cu118/torch2.4/flashinfer/三、下载模型
首次执行会自动下载所需模型
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --trust-remote-code --tp 1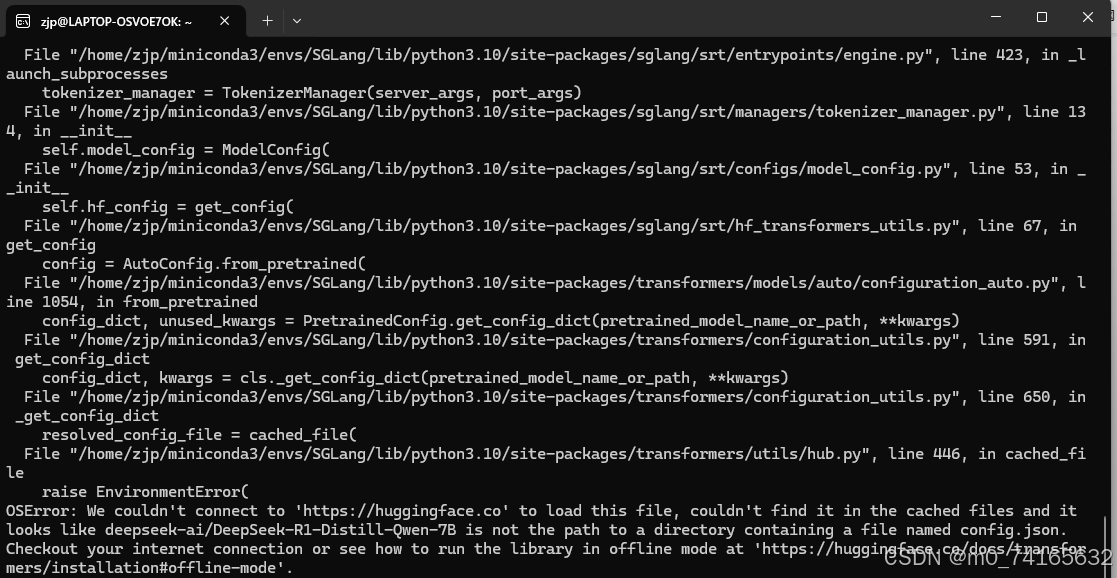
如果报上述错误下载不了的话,使用下面的有临时环境变量的指令下载
HF_ENDPOINT="https://hf-mirror.com" python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --trust-remote-code --tp 1想跑其他模型的话可以去官方Github:GitHub - deepseek-ai/DeepSeek-R1找对应的模型名称修改一下就行
第一次下载很慢而且有时候会有网络超时,不用管他,让它慢慢下载就好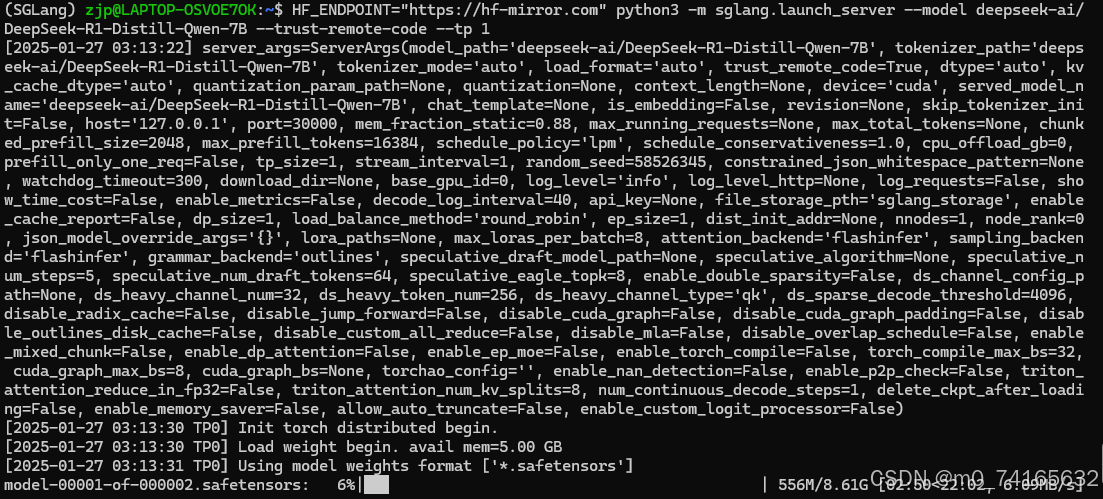
如果实在等不及的或者一直下载很慢的,可以去官网https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B/tree/main先手动下载对应的那两个很大的模型文件然后放到下面这个路径,然后再运行代码下载那些小文件
\home\用户名\.cache\huggingface\hub\models--deepseek-ai--DeepSeek-R1-Distill-Qwen-7B\snapshots\一个很长的文件夹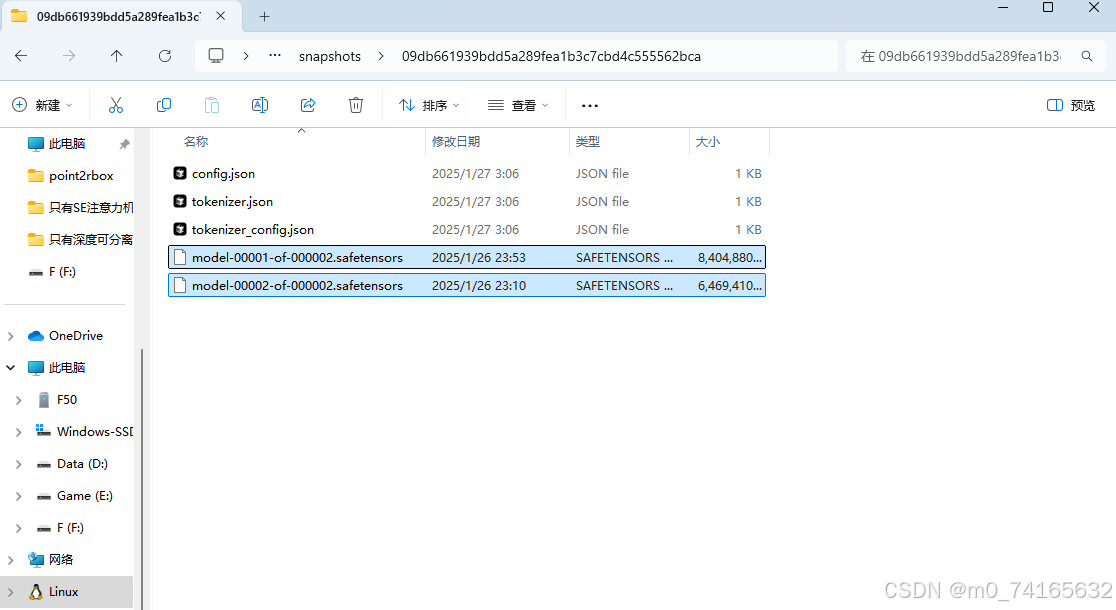
四、推理
下载完模型后,运行代码推理
HF_ENDPOINT="https://hf-mirror.com" python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --trust-remote-code --tp 1教程结束

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)