
PyTorch学习笔记——PyTorch简介
引言
本系列文章是七月在线的<PyTorch入门与实战>课程的一个笔记。
本文用的PyTorch版本是1.7.1。
什么是PyTorch
PyTorch是一个基于Python的计算库,它有以下特点:
- 类似NumPy,但是可以使用GPU
- 可以定义深度学习模型
Tensor
Tensor类似于Numpy的ndarray,唯一的区别是可以在GPU上加速运算。
下面举一些应用的例子,看起来就像Numpy一样:
构建Tensor
torch.empty(2, 3)

这里应该输出的是未初始化的数值,
这里优点懵逼,empty函数应该不会返回全零的数值,但是确实返回了,有点奇怪,以后知道为什么再来补充。
- 构建一个随机初始化的矩阵
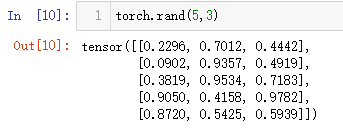
torch.rand(5,3)
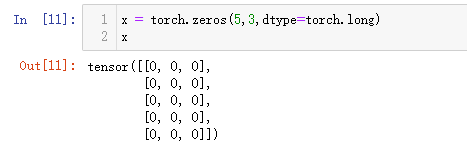
- 构建一个全0,类型为long的矩阵
x = torch.zeros(5,3,dtype=torch.long)
x
torch.long返回的是torch.int64,这个要注意一下。64位的整型确实也是长整型了。
如果不指定dtype,默认为torch.float。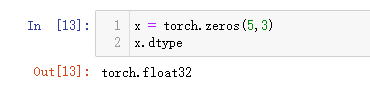
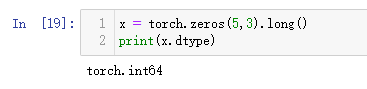
也可以调用long()函数直接转换为long类型:
x = torch.zeros(5,3).long()
print(x.dtype)
- 从数据直接构建tensor
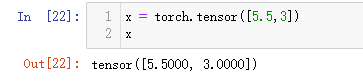
x = torch.tensor([5.5,3])
x
- 从tensor构建tensor
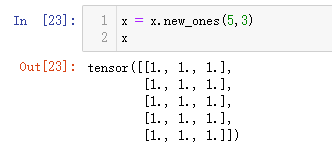
x = x.new_ones(5,3)
x
x = torch.randn_like(x, dtype=torch.float)
x

产生了一个和x形状相同的tensor,并且随机初始化。
获取tensor的形状
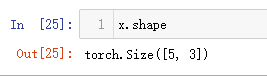
和numpy用法一样。
操作
tensor支持很多种运行。先来看下加法运算:

可以直接使用x+y,也可以调用torch.add(x,y)。
其实你调用x+y,PyTorch会帮你转换为torch.add(x,y)。
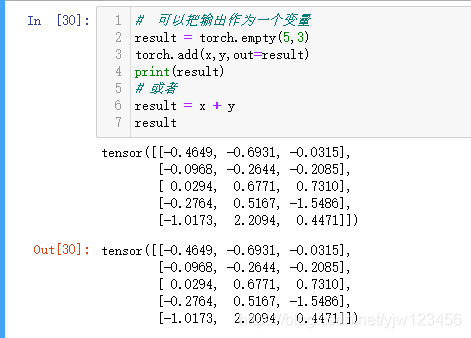
# 可以把输出作为一个变量
result = torch.empty(5,3)
torch.add(x,y,out=result)
print(result)
# 或者
result = x + y
result
接下来介绍原地加法,即不返回新对象,直接修改原对象:
# 把x加到y中
y.add_(x)
y

还有各种类似numpy的花式索引操作都可以在tensor上使用。

x[1:,1:] # 去掉第0行,去掉第0列

tensor中类似numpy的reshape操作是通过view函数去做的,比如:
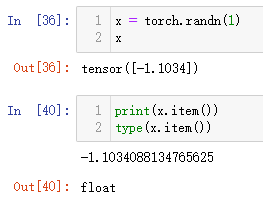
如果你有一个只有一个元素的tensor,可以使用.item()方法把里面的value变成python数值:
x = torch.randn(1)
print(x.item())
type(x.item())
Tensor和Numpy之间的转化
注意Torch Tensor和Numpy Array会共享内存,所以改变其中一项也会改变另一项。
下面介绍把Torch Tensor转变成Numpy Array: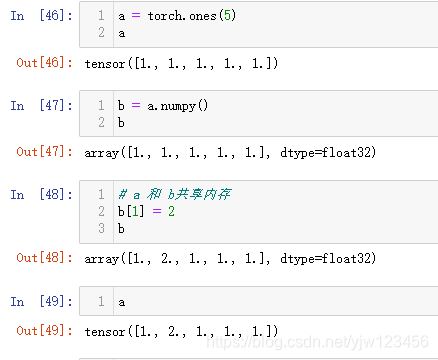
把Numpy Array转成Torch Tensor:

要注意有些写法不会共享内存,如下:
CUDA Tensor
使用.to()方法,tensor可以被移动到别的device上。
首先看是否支持cuda:
torch.cuda.is_available()

device = torch.device('cuda')
y = torch.ones_like(x,device=device)
x = x.to(device)
z = x + y
print(z)
print(z.to('cpu',torch.double)) #把z转到CPU上

好了,1+1=2介绍完了,现在开始进入微积分(开个玩笑)。
用Numpy实现两层神经网络
一个全连接ReLU神经网络,一个隐藏层,用x来预测y,使用L2 Loss。
h = W 1 X a = m a x ( 0 , h ) y ^ = W 2 a h = W_1 X \\ a = max(0,h) \\ \hat{y} = W_2a h=W1Xa=max(0,h)y^=W2a
使用numpy来实现前向传播、计算loss、反向传播。
N = 64 #
D_in = 1000 # 输入64 x 1000维
H = 100 # 100个隐藏单元
D_out = 10 #输出100维
# 创建训练数据
x = np.random.randn(N,D_in)
y = np.random.randn(N,D_out)
w1 = np.random.randn(D_in,H)
w2 = np.random.randn(H,D_out)
learning_rate = 1e-6
for t in range(500):
# 前向传播
h = x.dot(w1) # N,D_in x D_in,H -> N,H
h_relu = np.maximum(h,0)
y_pred = h_relu.dot(w2) # N,H x H,D_out => N,D_out
# 计算损失
loss = np.square(y_pred - y).sum() # ((y_pred-y)^2)
print(t,loss)
# 反向传播
# 计算梯度
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.T.dot(grad_y_pred)
grad_h_relu = grad_y_pred.dot(w2.T)
grad_h = grad_h_relu.copy()
grad_h[h<0] = 0
grad_w1 = x.T.dot(grad_h)
# 更新权重
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
输出:
0 33058043.32704551
1 27306044.962097257
2 23909073.28911867
3 19852906.85944085
4 14985129.67658587
5 10252450.856964976
6 6608375.582434638
7 4187973.310883059
8 2727896.0805685716
9 1868128.4849799518
10 1357048.7119993488
11 1038980.4194490338
12 829421.9653141748
13 682361.1309192695
...
494 3.3368635042855157e-07
495 3.1730953226992523e-07
496 3.0174761428522727e-07
497 2.8695042620658437e-07
498 2.728817325560072e-07
499 2.595043643636618e-07
可以看到,损失值是越来越低的。
用PyTorch实现两层神经网络
N = 64 #
D_in = 1000 # 输入64 x 1000维
H = 100 # 100个隐藏单元
D_out = 10 #输出100维
# 创建训练数据
x = torch.randn(N,D_in)
y = torch.randn(N,D_out)
w1 = torch.randn(D_in,H)
w2 = torch.randn(H,D_out)
learning_rate = 1e-6
for t in range(500):
# 前向传播
h = x.mm(w1) # N,D_in x D_in,H -> N,H
h_relu = h.clamp(min=0)
y_pred = h_relu.mm(w2) # N,H x H,D_out => N,D_out
# 计算损失
loss = (y_pred - y).pow(2).sum().item() # ((y_pred-y)^2)/m
print(t,loss)
# 反向传播
# 计算梯度
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.T)
grad_h = grad_h_relu.clone()
grad_h[h<0] = 0
grad_w1 = x.t().mm(grad_h)
# 更新权重
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
上面代码简单的把numpy转换为torch版本。
我们来看一下上面用到了还未了解的函数。
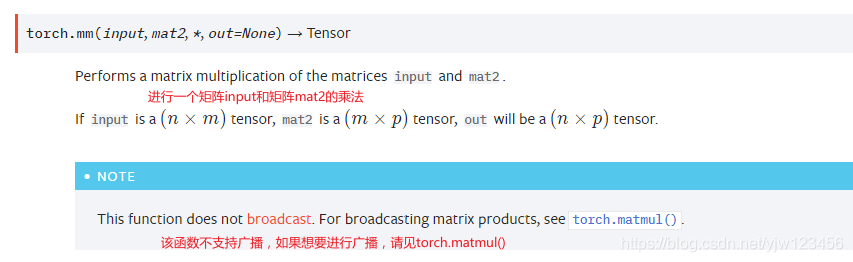
torch.mm替换的是numpy.dot,进行矩阵乘法。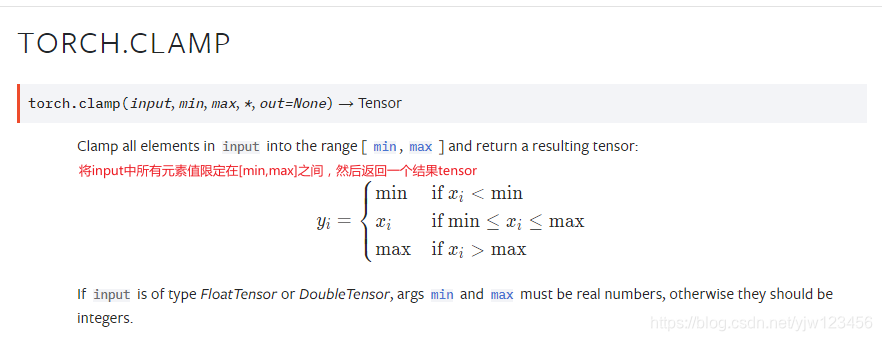
torch.clamp相当于是np.maximum和np.minimum的一个结合版,将取值限定在[min,max]之间。
其实PyTorch可以自己计算梯度,我们就可以不用自己去计算。
N = 64 #
D_in = 1000 # 输入64 x 1000维
H = 100 # 100个隐藏单元
D_out = 10 #输出100维
# 创建训练数据
x = torch.randn(N,D_in)
y = torch.randn(N,D_out)
w1 = torch.randn(D_in,H,requires_grad=True) # requires_grad需要计算梯度信息
w2 = torch.randn(H,D_out,requires_grad=True)
learning_rate = 1e-6
for t in range(500):
# 前向传播
y_pred = x.mm(w1).clamp(min=0).mm(w2)
# 计算损失
loss = (y_pred - y).pow(2).sum()# ((y_pred-y)^2)/m
print(t,loss.item())
# 反向传播
loss.backward() # 计算所有参数的梯度
# 更新权重
with torch.no_grad(): #表示下面的代码不会被计算梯度,不然 减法与乘法也会计算梯度
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
w1.grad.zero_() # 梯度模型会累加,这里需要清零,防止累加,以重新计算
w2.grad.zero_()
输出:
0 34800328.0
1 32638446.0
2 32001572.0
3 28535760.0
4 21404746.0
5 13589234.0
6 7713025.5
7 4305244.0
8 2556010.0
9 1680423.5
...
497 0.00012732129835058004
498 0.0001249550114152953
499 0.00012262548261787742
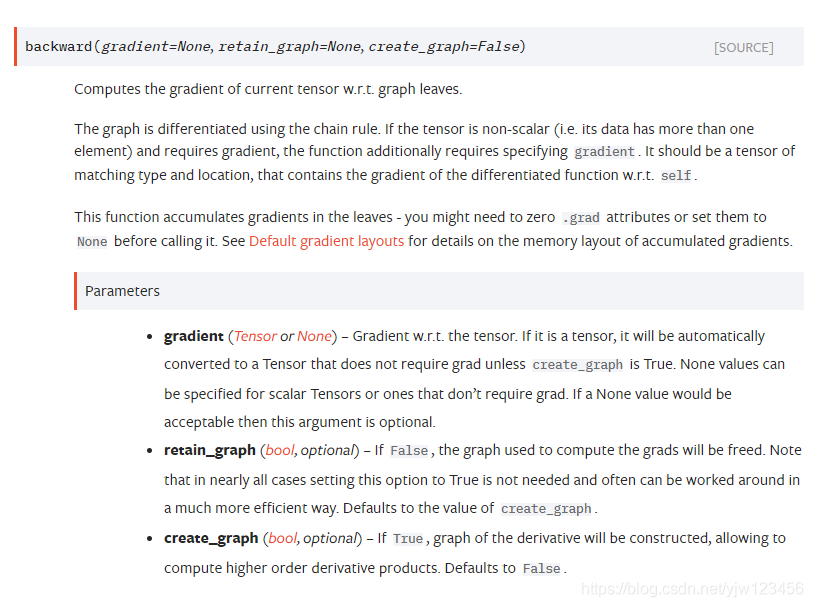
这就是backward的文档说明,其中也提到了需要对.grad属性调用zero操作。
使用PyTorch:nn来实现神经网络
PyTorch作为一个机器学习框架,必然预先定义好一些神经网络结构,因此我们可以直接使用。
import torch.nn as nn # nn就是神经网络 nerual network
N = 64 #
D_in = 1000 # 输入64 x 1000维
H = 100 # 100个隐藏单元
D_out = 10 #输出100维
# 创建训练数据
x = torch.randn(N,D_in)
y = torch.randn(N,D_out)
# 创建神经网络模型
model = nn.Sequential(
nn.Linear(D_in,H),
nn.ReLU(),
nn.Linear(H,D_out)
)
learning_rate = 1e-6
# model = model.cuda() 在cuda上计算
loss_fn = nn.MSELoss(reduction='sum') #损失函数
for t in range(500):
# 前向传播
y_pred = model(x)
# 计算损失
loss = loss_fn(y_pred,y)
print(t,loss.item())
model.zero_grad() # 把模型内参数的梯度清零
# 反向传播
loss.backward() # 计算所有参数的梯度
# 更新权重
with torch.no_grad(): #表示下面的代码不会被计算梯度,不然 减法与乘法也会计算梯度
for param in model.parameters():
param -= learning_rate * param.grad
输出:
0 679.17529296875
1 678.6298217773438
2 678.0850830078125
...
496 483.9840087890625
497 483.69195556640625
498 483.40020751953125
499 483.1089782714844
可以看到计算得到的损失值还是挺大的,我们后面会看为什么。
先来看一下上面代码出现的新函数。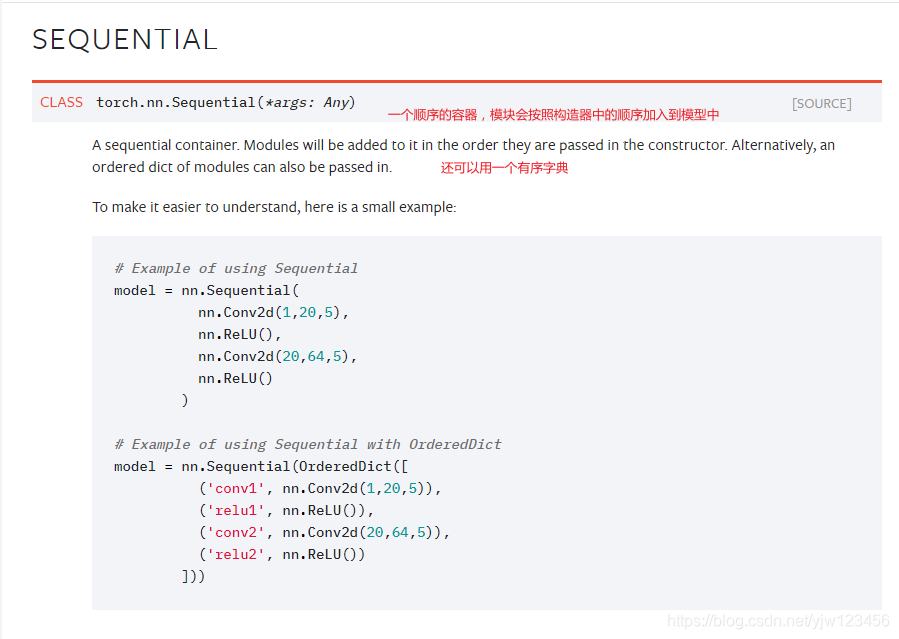
Sequential和Keras中的类似,

Linear就是进行线性变换,相当于计算 W X + b WX + b WX+b。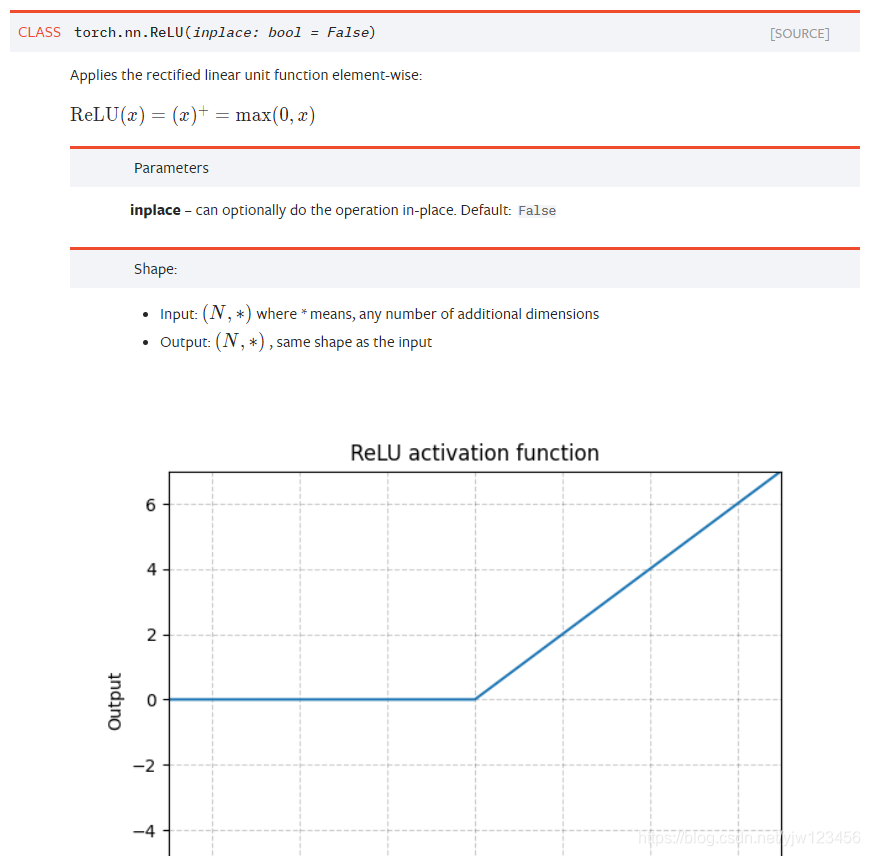
ReLU对输入进行元素级别的ReLU操作,作为一个激活函数。

nn.MSELoss计算MSE损失。
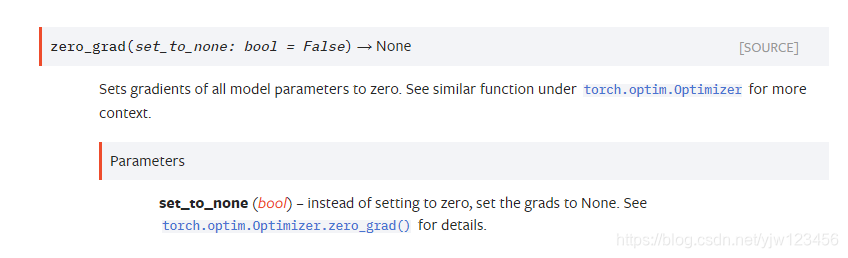
zero_grad设置模型内所有参数的梯度为零。
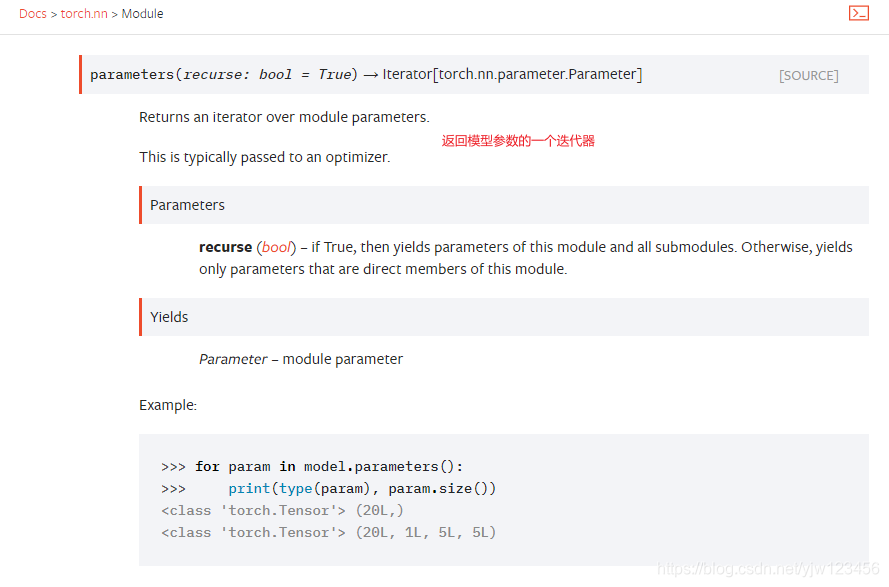
parameters返回模型参数的一个迭代器。
接下来来看为什么损失值没怎么下降。
猜测可能是与参数初始化有关,因此将模型参数用高斯分布进行随机初始化,看效果如何。
import torch.nn as nn # nn就是神经网络 nerual network
N = 64 #
D_in = 1000 # 输入64 x 1000维
H = 100 # 100个隐藏单元
D_out = 10 #输出100维
# 创建训练数据,这里是对训练数据进行随机初始化,高斯
x = torch.randn(N,D_in)
y = torch.randn(N,D_out)
model = nn.Sequential(
nn.Linear(D_in,H),
nn.ReLU(),
nn.Linear(H,D_out)
)
# 对参数进行高斯分布初始化
nn.init.normal_(model[0].weight) # 第0层就是线性层
nn.init.normal_(model[2].weight)# 第2层也是线性层
learning_rate = 1e-6
# model = model.cuda() 在cuda上计算
loss_fn = nn.MSELoss(reduction='sum') #损失函数
for t in range(500):
# 前向传播
y_pred = model(x)
# 计算损失
loss = loss_fn(y_pred,y)
print(t,loss.item())
model.zero_grad() # 把模型内参数的梯度清零
# 反向传播
loss.backward() # 计算所有参数的梯度
# 更新权重
with torch.no_grad(): #表示下面的代码不会被计算梯度,不然 减法与乘法也会计算梯度
for param in model.parameters():
param -= learning_rate * param.grad
输出:
0 30616396.0
1 27122208.0
2 26273386.0
3 24223140.0
4 19665302.0
5 13720840.0
6 8501692.0
7 4974603.5
8 2950860.5
...
493 0.00010636092338245362
494 0.00010499860945856199
495 0.0001035616296576336
496 0.00010203068086411804
497 0.0001005657686619088
498 9.947990474756807e-05
499 9.810829942580312e-05
果然,理解神经网络的权重初始化这篇文章诚不欺我。
PyTorch:optim
注意到上面的代码中,我们需要自己去更新模型的参数,感觉有点很白痴。optim就提供了优化方法。
import torch.nn as nn # nn就是神经网络 nerual network
N = 64 #
D_in = 1000 # 输入64 x 1000维
H = 100 # 100个隐藏单元
D_out = 10 #输出100维
# 创建训练数据,这里是对训练数据进行随机初始化,高斯
x = torch.randn(N,D_in)
y = torch.randn(N,D_out)
model = nn.Sequential(
nn.Linear(D_in,H),
nn.ReLU(),
nn.Linear(H,D_out)
)
# 对参数进行高斯分布初始化
nn.init.normal_(model[0].weight) # 第0层就是线性层
nn.init.normal_(model[2].weight)# 第2层也是线性层
learning_rate = 1e-4
# model = model.cuda() 在cuda上计算
loss_fn = nn.MSELoss(reduction='sum') #损失函数
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate)
for t in range(500):
# 前向传播
y_pred = model(x)
# 计算损失
loss = loss_fn(y_pred,y)
print(t,loss.item())
optimizer.zero_grad() # 把模型内参数的梯度清零
# 反向传播
loss.backward() # 计算所有参数的梯度
# 更新权重
optimizer.step() # 一步更新
torch.optim实现了大量的优化算法。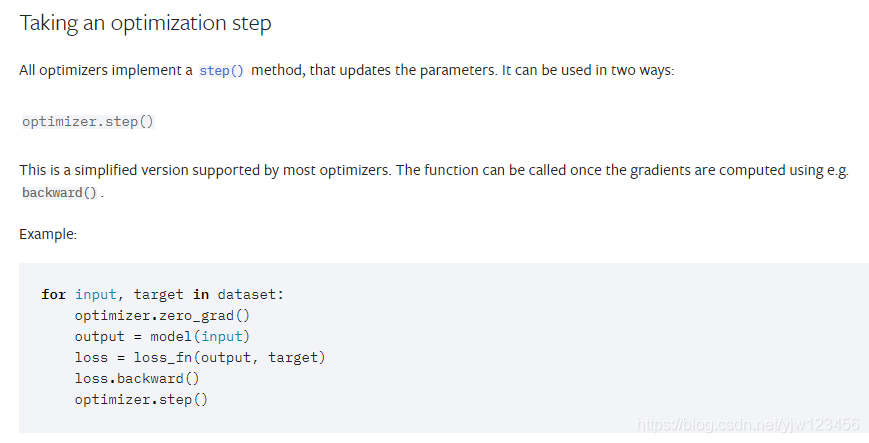
PyTorch的文档真的很详细,基本都会有例子说明,这一点点个赞!
上面说的是需要调用step()方法去进行参数的更新,通常在backward()方法后面,注意这里用optimizer自己的zero_grad()方法。
然后看下输出:
0 28090116.0
1 28015916.0
2 27941828.0
3 27867866.0
...
495 6882543.5
496 6861694.0
497 6840917.0
498 6820213.5
499 6799559.0
额,真是令人崩溃,增加了优化器模型又坏了。
好吧,保持耐心,找到原因。
上面我们加了权重的初始化,我们把这个初始化去掉,看看效果如何。
# 对参数进行高斯分布初始化
#nn.init.normal_(model[0].weight) # 第0层就是线性层
#nn.init.normal_(model[2].weight)# 第2层也是线性层
注释掉上面这两行代码,输出:
0 674.1737670898438
1 657.3617553710938
2 641.1337890625
3 625.3301391601562
4 609.9922485351562
5 595.1806640625
...
495 1.4623940947089409e-09
496 1.3596783698943682e-09
497 1.2750263067573542e-09
498 1.199627730485986e-09
499 1.1304185365546005e-09

去掉这个初始化就好了。
其实我怀疑是学习率过小导致的,因为迭代次数才500次,学习率过小可能导致收敛的慢。所以我试出了一个学习率,也可以:
import torch.nn as nn # nn就是神经网络 nerual network
N = 64 #
D_in = 1000 # 输入64 x 1000维
H = 100 # 100个隐藏单元
D_out = 10 #输出100维
# 创建训练数据,这里是对训练数据进行随机初始化,高斯
x = torch.randn(N,D_in)
y = torch.randn(N,D_out)
model = nn.Sequential(
nn.Linear(D_in,H),
nn.ReLU(),
nn.Linear(H,D_out)
)
# 对参数进行高斯分布初始化
nn.init.normal_(model[0].weight) # 第0层就是线性层
nn.init.normal_(model[2].weight)# 第2层也是线性层
learning_rate = 0.1 #这里使用0.1
# model = model.cuda() 在cuda上计算
loss_fn = nn.MSELoss(reduction='sum') #损失函数
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate)
for t in range(500):
# 前向传播
y_pred = model(x)
# 计算损失
loss = loss_fn(y_pred,y)
print(t,loss.item())
optimizer.zero_grad() # 把模型内参数的梯度清零
# 反向传播
loss.backward() # 计算所有参数的梯度
# 更新权重
optimizer.step() # 一步更新
输出:
0 35122628.0
1 9007808.0
2 11289078.0
3 7871112.0
4 4859111.5
5 3874125.0
6 3529964.25
7 3013442.0
8 2430617.5
9 2018074.125
...
487 8.862493814376649e-07
488 8.110216640488943e-07
489 1.0448329703649506e-06
490 7.924213605292607e-07
491 1.0169571851292858e-06
492 8.30444832899957e-07
493 9.588303555574385e-07
494 8.980438224170939e-07
495 9.702524721433292e-07
496 9.406043659510033e-07
497 1.023696995616774e-06
498 1.0201848681390402e-06
499 1.1045899555028882e-06
也还行,在500步内收敛了,虽然刚开始损失值很大。注意这里没有取消参数的初始化。
PyTorch:自定义nn Module
在本节,我们来探讨下如何基于nn.Module自定义一个网络模型。
import torch.nn as nn # nn就是神经网络 nerual network
N = 64 #
D_in = 1000 # 输入64 x 1000维
H = 100 # 100个隐藏单元
D_out = 10 #输出100维
# 创建训练数据,这里是对训练数据进行随机初始化,高斯
x = torch.randn(N,D_in)
y = torch.randn(N,D_out)
# 继承自nn.Module
class TwoLayerNet(nn.Module):
def __init__(self,D_in,H,D_out):
super(TwoLayerNet,self).__init__()
self.linear1 = nn.Linear(D_in,H,bias=False)
self.linear2 = nn.Linear(H,D_out,bias=False)
def forward(self, x):
y_pred = self.linear2(self.linear1(x).clamp(min=0))
return y_pred
model = TwoLayerNet(D_in,H,D_out)
learning_rate = 1e-4
# model = model.cuda() 在cuda上计算
loss_fn = nn.MSELoss(reduction='sum') #损失函数
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate)
for t in range(500):
# 前向传播
y_pred = model(x)
# 计算损失
loss = loss_fn(y_pred,y)
print(t,loss.item())
optimizer.zero_grad() # 把模型内参数的梯度清零
# 反向传播
loss.backward() # 计算所有参数的梯度
# 更新权重
optimizer.step() # 一步更新
输出:
0 674.8458251953125
1 658.4599609375
2 642.609619140625
3 627.2831420898438
4 612.4089965820312
5 598.072998046875
6 584.0977172851562
7 570.501220703125
...
494 1.353284915239783e-06
495 1.2663750794672524e-06
496 1.1854531294375192e-06
497 1.1091022997788968e-06
498 1.0375715646659955e-06
499 9.713454574011848e-07
参考
下面是硬广告,这是七月在线的<PyTorch入门与实战>课程的一个笔记,个人觉得讲得也不错,团购只需要49元,相比动不动300左右的课程来说,还是可以考虑的。
感兴趣的同学可以扫描购买。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)