
vLLM PD分离系列
vLLM PD分离系列
云计算基础架构 2025年05月20日 17:58 北京
PD 分离是一个推理服务化特性,主要考虑到 Prefill是计算密集型任务,Decode
是访存密集型任务,两者对硬件资源的诉求不同,因此将其分离在不同的设备上进行推理,提升推理系统的吞吐。对这部分原理介绍很多,不赘述。本文主要总结 vLLM 的 PD 分离及 KV-Cache 传输的实现细节
具体实现包括两部分:
1. 根据条件对请求进行路由分发,即常说的 Router
部分。这里的条件可以是:(1)设备上负载(请求)分布情况,负载低的设备可以接受更多的请求,负载高的设备接受少的请求;(2)设备上Prefix-Cache/KV-Cache 的亲和性,请求尽量分发到能 Cache hit 的设备上。(3)也许还有更多其他指标,待发掘。
2. 将 P 节点的 KV-Cache 传到 D 节点,即常说的 KVCache 传输。P 节点推理生成 prompt KV-Cache 传输到 D 节点推理的设备上进行 decode 推理。这里的传输可以是 P 节点和 D 节点点对点的传输,也可以通过池化数据库进行传输。
vLLM PD 分离实现
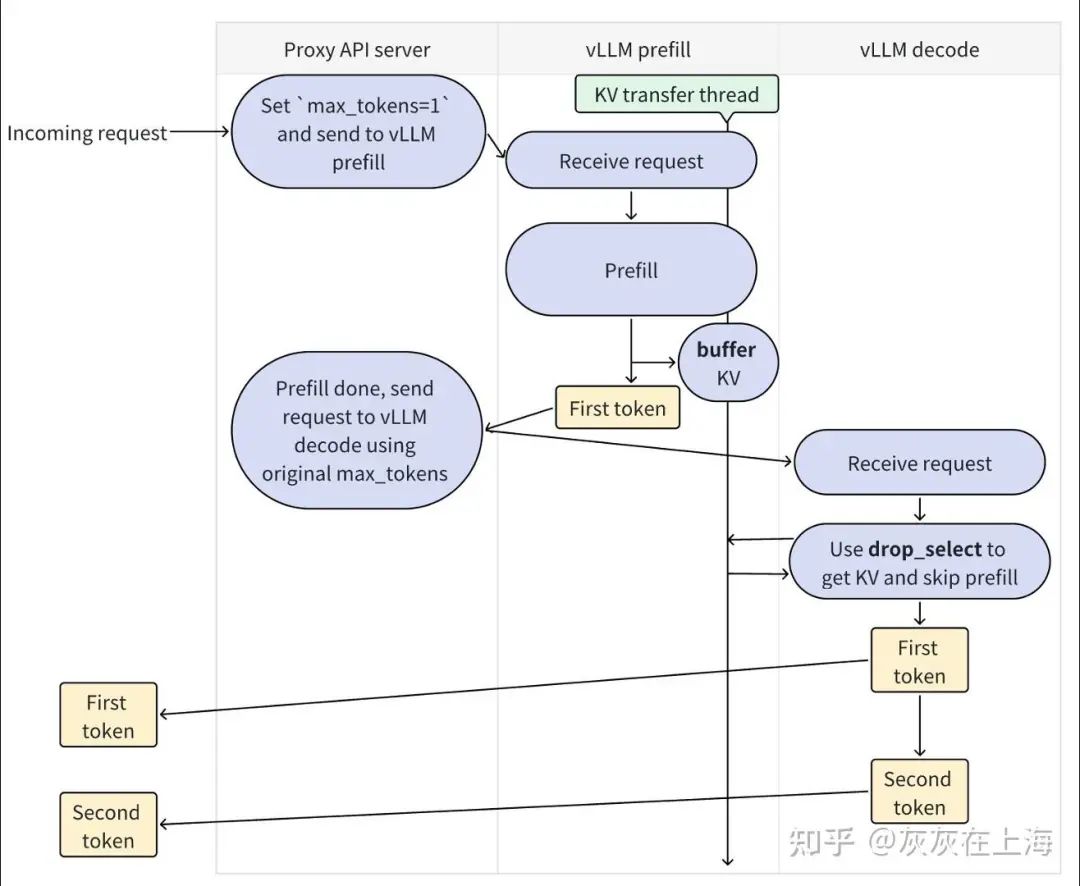
vLLM 1P1D 执行流程
截止到 vLLM 0.8.4 的版本,当前只有 1P1D 的 PD 分离方案,另外还有基于 V1 架构和 P2P 通信的 xPyD PR,基于 V1 架构也有 xPyD整体方案设计的 PR已经 merge。
整个PD 分离推理流程包含三个进程:
- Proxy API Server 进程:
接受请求,控制请求和消息在P 实例进程和 D 实例进程之间通信。
- vLLM Prefill 进程
- :
Prefill 实例推理对应的进程。
-
接受 Proxy 进程传入的请求进,行Prefill 推理;
-
独立于推理线程,单起一个线程,将 KV-Cache 异步写入 KV lookup buffer
-
;
-
生成首 token,将 token 返回给 Proxy 进程;
3. Decode 进程
:Decode 实例推理对应的进程。
-
接受Proxy进程传入的请求,进行 Decode 推理;
-
通过 drop_select API 从 P 实例拉取 KV Cache,跳过 Prefill 阶段,进行 Decode 推理;
-
同时将首 Token 和其他 Token 返回给 Proxy 进程;
KV-Cache传输原理
vLLM 官方对这部分内容的解释 KV-Cache 传输
- KV connector:
a connector that connects the KV pipe and KV lookup buffer to vLLM. Key APIs: send_kv_caches_and_hidden_states and recv_kv_caches_and_hidden_states.
-
KV connector:P 模型实例和 D 模型实例之间传输 KV-Cache 的通道。 P 实例的ModelRunner 通过调用 send_kv_caches_and_hidden_states往 look buffer 中写入 KV-Cache,该操作是异步的。实现原理如图:
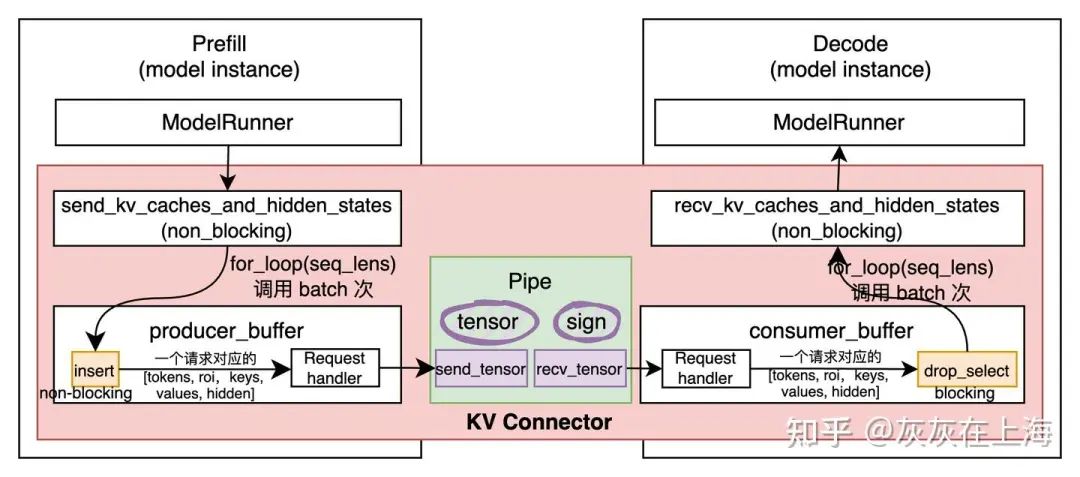
SimpleConnector:点对点传输原理
2. KV lookup buffer: a lookup buffer for KV caches. Key: the tokens, value: the KV caches (and/or hidden states). Key APIs: insert and drop_select (similar to SQL semantics).
- KV lookup buffer:
存放 KV-Cache 的 lookup buffer。如果是 P2P 直连的方案,则每个实例对应的设备上有单独的 lookup buffer (HBM),两个 lookup 通过 Pipe 传输数据。
- 数据结构:
用一个字典描述 token 的 KV-Cache,其中字典的 Key 根据 req_id和 TP rank 生成全局唯一的 hash_id,字典的 Value 为 KV-cache/hidden states本身。需要 lookup buffer 而不是 FIFO 的原因,请求在 P 实例和 D 实例上的执行顺序可能不同,P 实例是 A->B->C,D 实例是C->B->A。所以 loopup buffer 的读写都是以单请求为单位,而不是一组 batch 后的请求为单位。
- insert/drop_select:
insert 为写 Cache 操作,是异步的(non-blocking),drop_select是读操作,是同步的(blocking),因为必须等KV-Cache 拿到后,才能进行 decode 推理。这里的 insert 和 drop_select都是作用于单个请求,对于从 schedule 得到的 batch 组请求,会 for-loop batch 次写操作到 buffer,传输也是以单个请求为单位,读取 buffer 拉取 KV-cache 也是以单个请求为单位。drop_select可能存在性能问题。
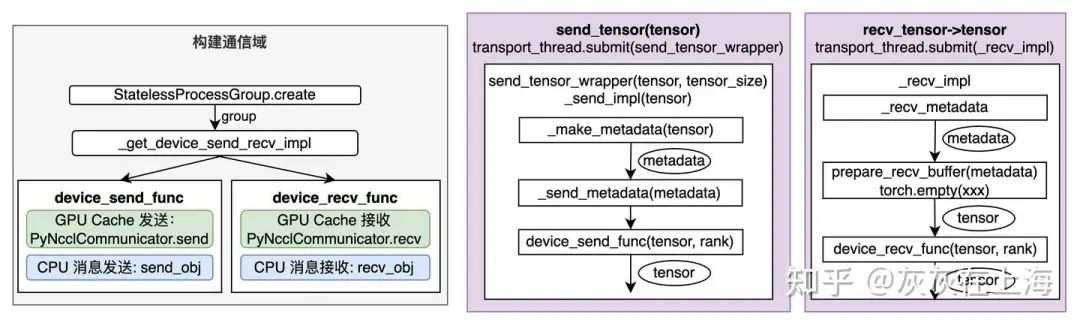
- PyNcclPipe类的实现:
首先构建通信域,GPU 侧的KV-Cache发送通过 PyNcclCommunicator,CPU 侧的控制消息传输是通过 CPU 侧的 send_obj和recv_obj进行消息传输。
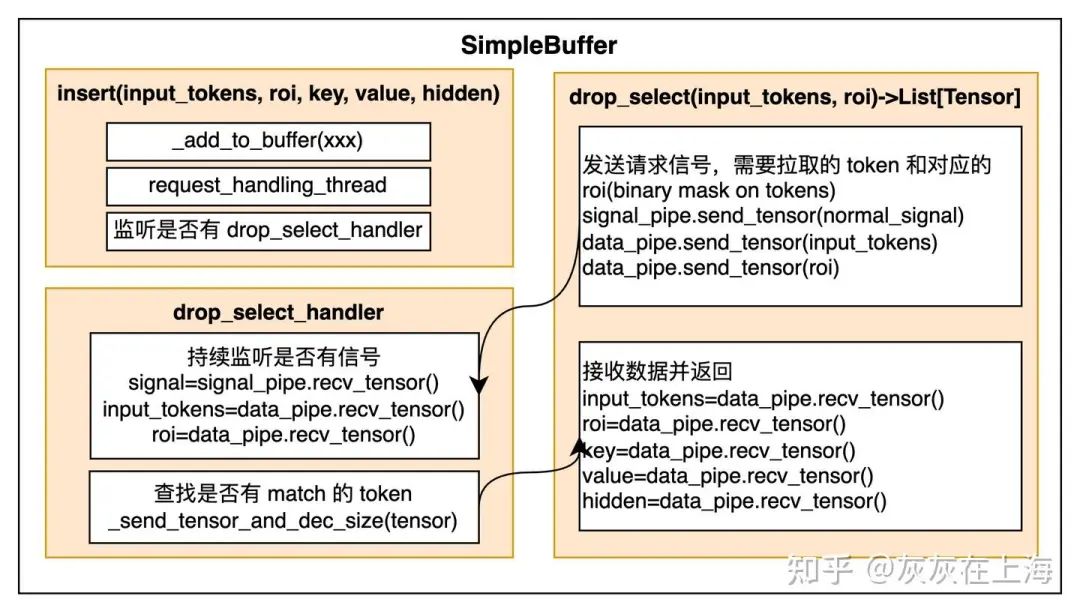
KVLookupBuffer
3. KV pipe: a FIFO pipe for torch.tensor transmission. Key APIs: send_tensor and recv_tensor.
- KV pipe物理意义:
一个先进先出的队列,先入队的先发送。KV pipe 层可以 bypass,如果有内存资源池的功能 (如redis 或 RDMA database)。
- KV pipe 类的定义:
传输的是 torch Tensor,包括三个函数 send_tensor、recv_tensor、close kv_pipe 源码。send_tensor和 recv_tensor分别发送消息和接受消息。close 函数表示关闭 pipe,释放资源。KVLookupBuffer 类的实现:
阅读 1158

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)