
基于pytorch深度学习框架开发多模态情感分析 语音模态与文本模态特征注意力融合
本文提出了一种基于PyTorch的多模态情感分析方法,融合语音和文本特征进行情感分类。系统采用预训练的多语言BERT模型处理文本数据,Wav2Vec2模型提取语音特征,通过注意力机制实现特征融合。实验使用EATD_Corpus数据集(包含negative、neutral、positive三类样本),构建了包含文本编码器、语音特征提取器和多模态分类器的完整架构。文章详细介绍了环境搭建、数据预处理、模
·
基于pytorch深度学习框架开发多模态情感分析 语音模态与文本模态特征注意力融合
多模态情感分析 语音模态与文本模态特征注意力融合 基于pytorch深度学习框架开发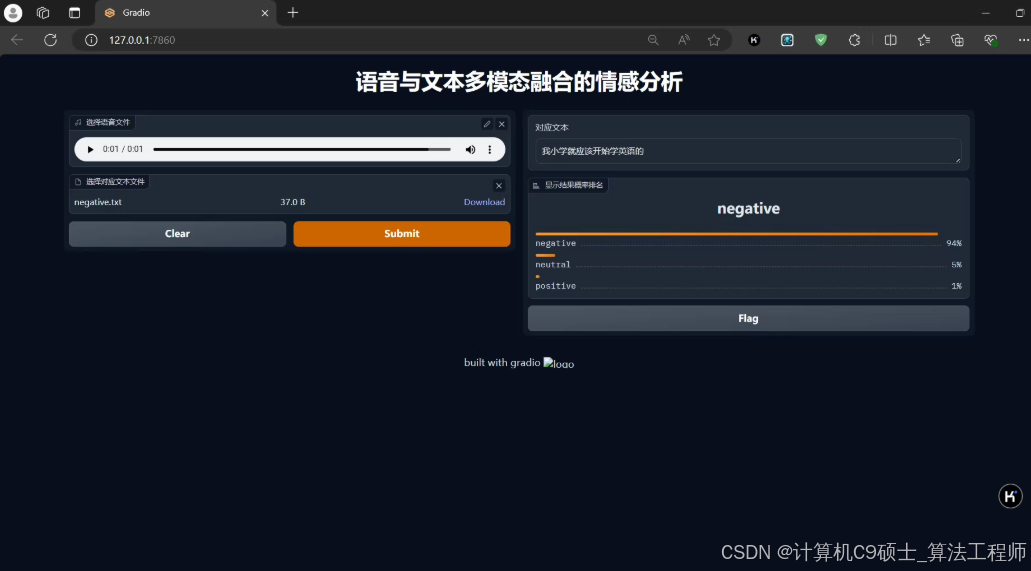
文本编码器采用预训练的多语言bert模型,beause数据集中包含中英两个语言的文本,需要基于该模型做微调
语音特征提取器采用预训练的wav2vec2模型
项目所用的数据集为EATD_Corpus数据集,包含三类样本,分别为negative、neutral、positive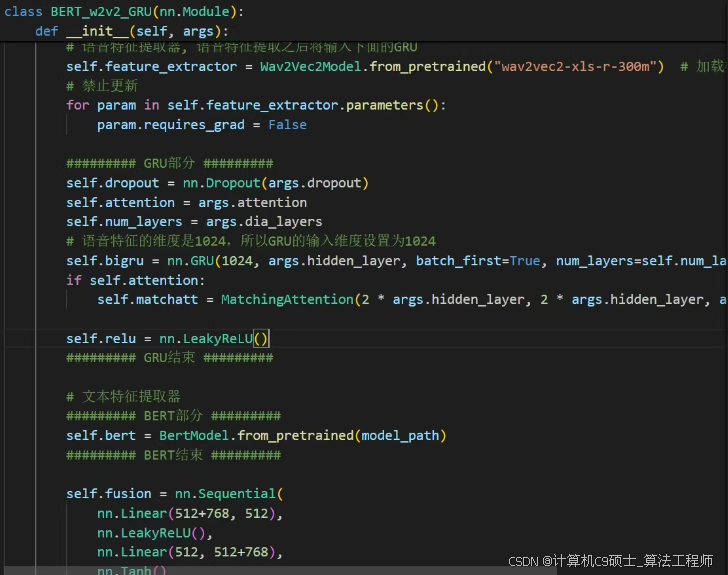
1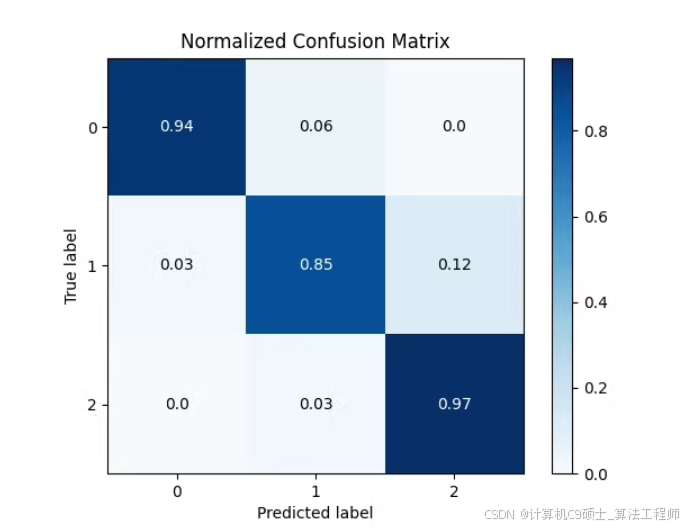
实现一个多模态情感分析项目,结合语音和文本模态,并使用注意力机制融合特征,可以分为以下几个步骤:
- 环境搭建
- 数据预处理
- 模型构建
- 训练与评估
- 部署
1. 环境搭建
确保安装了以下依赖:
- PyTorch
- Transformers (用于BERT和Wav2Vec2)
- Gradio (用于前端展示)
pip install torch torchvision torchaudio transformers gradio
2. 数据预处理
假设你已经有了EATD_Corpus数据集,包含音频文件和对应的文本。
import os
import pandas as pd
# 加载数据集
def load_dataset(data_dir):
audio_files = []
texts = []
labels = []
for label in ['negative', 'neutral', 'positive']:
label_dir = os.path.join(data_dir, label)
for file in os.listdir(label_dir):
if file.endswith('.wav'):
audio_files.append(os.path.join(label_dir, file))
with open(os.path.join(label_dir, file.replace('.wav', '.txt')), 'r') as f:
texts.append(f.read().strip())
labels.append(label)
return pd.DataFrame({'audio': audio_files, 'text': texts, 'label': labels})
data_dir = 'path/to/your/dataset'
df = load_dataset(data_dir)
3. 模型构建
文本编码器(BERT)
from transformers import BertTokenizer, BertModel
class TextEncoder(nn.Module):
def __init__(self, bert_model_name='bert-base-multilingual-cased'):
super(TextEncoder, self).__init__()
self.tokenizer = BertTokenizer.from_pretrained(bert_model_name)
self.model = BertModel.from_pretrained(bert_model_name)
def forward(self, text):
inputs = self.tokenizer(text, return_tensors='pt', padding=True, truncation=True)
outputs = self.model(**inputs)
return outputs.last_hidden_state.mean(dim=1)
语音特征提取器(Wav2Vec2)
from transformers import Wav2Vec2Processor, Wav2Vec2Model
class AudioEncoder(nn.Module):
def __init__(self, wav2vec2_model_name='facebook/wav2vec2-base-960h'):
super(AudioEncoder, self).__init__()
self.processor = Wav2Vec2Processor.from_pretrained(wav2vec2_model_name)
self.model = Wav2Vec2Model.from_pretrained(wav2vec2_model_name)
def forward(self, audio_file):
inputs = self.processor(audio_file, return_tensors='pt')
outputs = self.model(**inputs)
return outputs.last_hidden_state.mean(dim=1)
多模态融合模型
import torch.nn as nn
class MultimodalEmotionClassifier(nn.Module):
def __init__(self, text_encoder, audio_encoder):
super(MultimodalEmotionClassifier, self).__init__()
self.text_encoder = text_encoder
self.audio_encoder = audio_encoder
self.attention = nn.MultiheadAttention(768, num_heads=8)
self.fc = nn.Linear(768 * 2, 3)
def forward(self, text, audio):
text_features = self.text_encoder(text)
audio_features = self.audio_encoder(audio)
# Attention mechanism
text_features = text_features.unsqueeze(1)
audio_features = audio_features.unsqueeze(1)
fused_features, _ = self.attention(text_features, audio_features, audio_features)
fused_features = fused_features.squeeze(1)
output = self.fc(torch.cat((text_features, fused_features), dim=1))
return output
4. 训练与评估
import torch
from torch.utils.data import Dataset, DataLoader
class EATDDataset(Dataset):
def __init__(self, df, text_encoder, audio_encoder):
self.df = df
self.text_encoder = text_encoder
self.audio_encoder = audio_encoder
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
row = self.df.iloc[idx]
text = row['text']
audio_file = row['audio']
label = row['label']
text_feature = self.text_encoder(text)
audio_feature = self.audio_encoder(audio_file)
return text_feature, audio_feature, label
# 数据加载
dataset = EATDDataset(df, TextEncoder(), AudioEncoder())
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 模型实例化
model = MultimodalEmotionClassifier(TextEncoder(), AudioEncoder())
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# 训练循环
num_epochs = 10
for epoch in range(num_epochs):
for text_features, audio_features, labels in dataloader:
optimizer.zero_grad()
outputs = model(text_features, audio_features)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
5. 部署
使用Gradio进行前端展示。
import gradio as gr
def predict_emotion(text, audio_file):
text_feature = text_encoder(text)
audio_feature = audio_encoder(audio_file)
output = model(text_feature, audio_feature)
_, predicted = torch.max(output, 1)
return predicted.item()
iface = gr.Interface(fn=predict_emotion, inputs=["text", "file"], outputs="label")
iface.launch()
总结
基本框架:基于PyTorch的多模态情感分析系统。同学可根据具体需求进一步优化和扩展功能,biru zhege添加更多的模型层、改进注意力机制等。

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)