
从 CUDA 到 ROCm:AMD 云端 AI 开发的全栈迁移与性能优化实践
摘要: AMD ROCm平台作为开源GPU计算解决方案,在AI训练与推理领域快速发展。本文系统解析ROCm的分层架构(驱动层、运行时层、编译器与框架层),重点介绍HIP编程模型与CUDA的差异及迁移策略。针对PyTorch、vLLM等主流框架,探讨ROCm适配现状与优化方案,包括性能调优技巧和常见问题排查。通过实测数据展示AMD Instinct MI300X在云端AI任务中的优势,为开发者提供从
从 CUDA 到 ROCm:AMD 云端 AI 开发的全栈迁移与性能优化实践

摘要
随着 AI 模型规模突破百亿参数,云端算力需求持续攀升,开发者对 GPU 生态的选择日益关注。AMD ROCm 作为一款开源 GPU 计算平台,近年来在 AI 训练与推理领域取得了显著进展。本文从 ROCm 软件栈的技术架构出发,系统梳理 PyTorch、vLLM、SGLang 等主流框架在 ROCm 平台上的适配现状,深入分析 CUDA 到 HIP 的代码迁移路径与工程实践,探讨高性能推理部署的优化策略,并结合 AMD Instinct MI300X 的硬件特性给出性能对标实测数据。旨在为开发者提供一份从入门到精通的云端 AI 开发全栈指南。
1. 引言
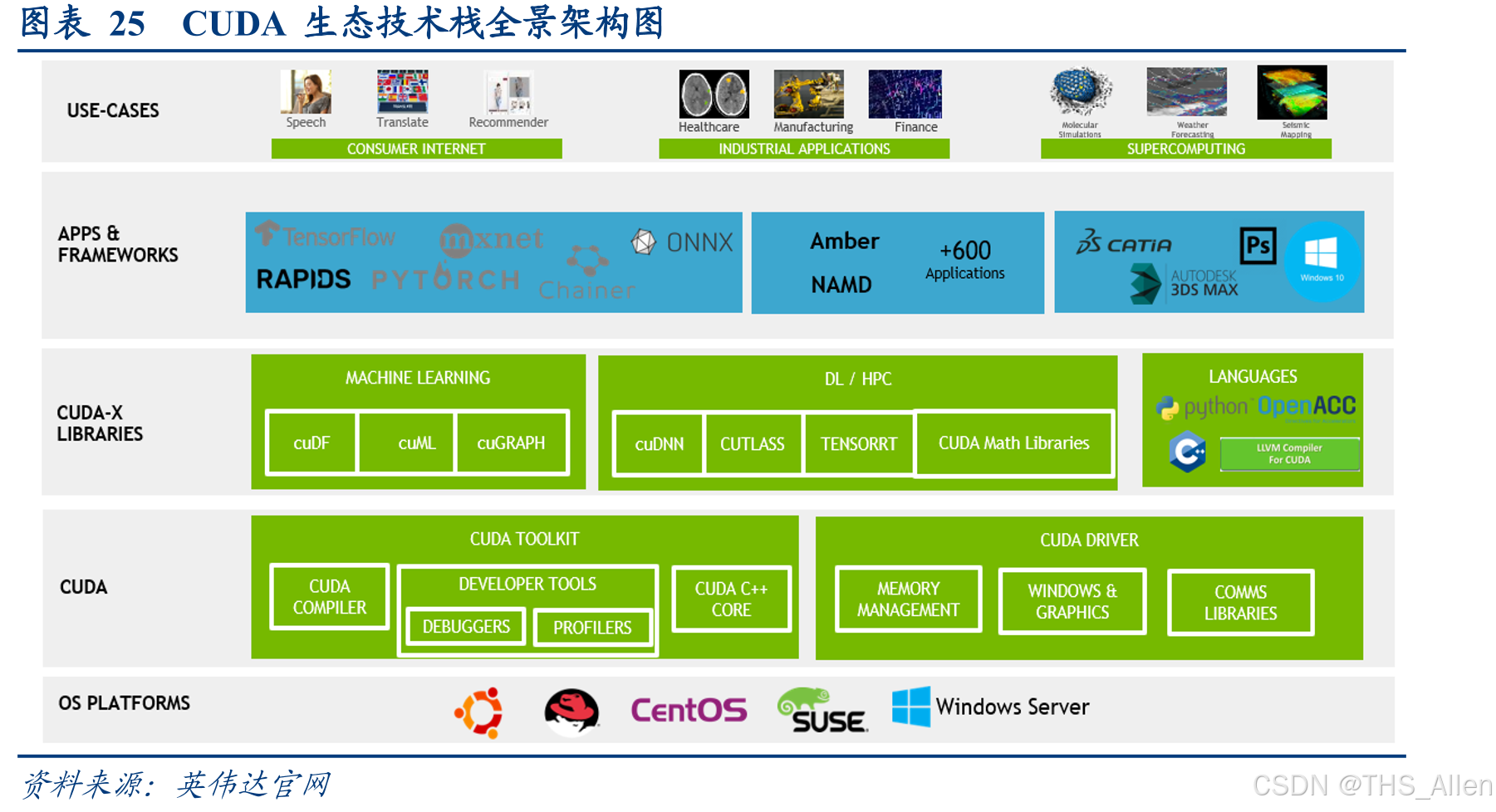
NVIDIA CUDA 长期主导 GPU 加速计算领域,但随着 AI 工作负载的多样化和算力需求的爆发式增长,单一的硬件供应商格局正在被打破。AMD 于 2016 年推出的 ROCm(Radeon Open Compute)平台,经过近十年的迭代演进,已逐步构建起一个覆盖驱动、运行时、编译器、数学库和 AI 框架的完整开源软件栈。
ROCm 的核心理念是“开放生态”——所有组件均以开源形式发布,开发者可以自由查看、修改和优化底层代码。这一策略与 CUDA 的闭源模式形成鲜明对比。截至 2025 年,ROCm 已迭代至 7.0 版本,推理性能较前代提升最高 3.8 倍,训练性能提升至 3 倍,并新增了对 FP4、FP6 低精度计算、分布式推理和 Windows 系统的支持。与此同时,搭载 192GB HBM3 显存的 AMD Instinct MI300X 加速器在硬件指标上展现出对 NVIDIA H100 的显著优势。
2. 
解析
2.1 整体架构层次
ROCm 软件栈采用分层架构设计,从底层到顶层依次为:
驱动层:包含 AMDGPU 内核驱动和 KFD(Kernel Fusion Driver),负责 GPU 设备的初始化、电源管理和内存分配。ROCm 6.0 版本开始全面采用 Filesystem Hierarchy Standard(FHS)规范,将编译器安装路径调整为 /opt/rocm-<rel>/lib/llvm,并通过符号链接保持向后兼容。
运行时层:HIP(Heterogeneous-compute Interface for Portability)是 ROCm 的核心运行时 API,提供与 CUDA 高度相似的程序设计模型。HIP 允许开发者从单一源代码构建可同时运行于 AMD 和 NVIDIA GPU 的可移植应用。
编译器与工具链层:基于 LLVM/Clang 的编译器框架,支持 OpenMP、HIP、OpenCL 等多种编程模型。ROCm 6.0 引入的 hipSPARSELt 库利用 AMD 的稀疏矩阵核心技术加速 AI 工作负载。
库与框架层:包括 hipBLAS(线性代数)、hipFFT(快速傅里叶变换)、RCCL(集合通信)、MIOpen(深度学习原语)等底层加速库,以及 PyTorch、TensorFlow、JAX 等主流 AI 框架的 ROCm 后端。
2.2 HIP 编程模型剖析
HIP 编程模型定义了两种执行上下文:主程序在 CPU(主机端)上运行,计算内核在 GPU(设备端)上以 SIMT(Single Instruction, Multiple Threads)模式执行。主机负责管理数据准备、内核启动和结果回收,设备则专注于大规模的并行计算。
在硬件层面,AMD GPU 采用 CU(Compute Unit)作为基本计算单元,每 CU 内部使用 wavefront(通常为 64 个线程)进行调度。这一设计与 NVIDIA 的 warp(32 个线程)存在差异,是跨平台性能调优时需要特别关注的一个关键点。HIP 7.0 的预览版本已在此方面做出了重大改进,旨在使 HIP C++ API 与 CUDA C++ 更加紧密地对齐,从而简化跨平台编程。
2.3 版本迭代与关键里程碑
表:ROCm 主要版本特性对比
| 版本 | 发布时间 | 关键特性 |
|---|---|---|
| ROCm 5.x | 2022-2023 | 稳定支持 MI200 系列,初步支持 PyTorch 训练 |
| ROCm 6.0 | 2024 | MI300 系列首次支持,hipSPARSELt 稀疏计算库,上游框架集成 |
| ROCm 6.1-6.2 | 2024 H2 | 性能优化,扩展 GPU 架构支持 |
| ROCm 7.0 | 2025 Q3 | HIP 7.0 API,FP4/FP6/FP8 支持,分布式推理,Windows 与消费级显卡扩展 |
3. 主流 AI 框架在 ROCm 上的适配与实践
3.1 PyTorch on ROCm:训练与微调
PyTorch 是 ROCm 生态中适配最成熟的深度学习框架。AMD 通过官方的 rocm/pytorch-training Docker 镜像提供预优化的训练环境,内置 PyTorch 2.9.0、Transformer Engine、Flash Attention v2.8.3、hipBLASLt 以及 Triton 编译器,覆盖从 Llama 4 Scout 17B 到 Llama 3.1 405B 等主流模型的训练场景。
从开发者反馈来看,PyTorch on ROCm 的日常使用体验已趋于平滑。社区讨论指出,ROCm 与 PyTorch 的组合在推理场景中表现稳定,而训练环节尽管存在少量兼容性问题,但在主流模型上已可正常运行。ROCm 7.0 引入的对称内存(Symmetric Memory)机制通过降低多 GPU 训练中的通信瓶颈,进一步提升了吞吐性能。
3.2 vLLM on ROCm:高性能推理服务
vLLM 是目前最广泛采用的大语言模型推理引擎之一,AMD 正在积极为其贡献 ROCm 后端支持。然而,vLLM 的大部分优化仍然面向 NVIDIA GPU。Moreh 团队针对这一现状发布了 Moreh vLLM——一个在 AMD GPU 上深度优化的 vLLM 分支。评测数据显示,在 Llama 3.3 70B 模型的推理测试中,Moreh vLLM 的平均吞吐量比原生 vLLM 高 1.68 倍,首个 token 延迟(TTFT)降低 2.02 倍,每个输出 token 的时间(TPOT)降低 1.59 倍。
3.3 SGLang on ROCm:解耦式推理架构
SGLang 采用 Prefill–Decode 解耦技术,为 ROCm 平台上的大规模推理提供了更高效的方案。ROCm 7.0 发布时,AMD 提供了针对 MXFP4 和 FP8 格式优化的 SGLang Docker 镜像,以及经过 AMD Quark 量化工具优化的 DeepSeek R1、Llama 3.3 70B、Llama 3.1-405B 等生产可用的量化模型。这些预置资源有效降低了开发者在 ROCm 上部署大模型的门槛。
4. CUDA 到 ROCm 的迁移实战
4.1 迁移路径总览
从 CUDA 迁移到 ROCm,开发者有三条主要技术路径可选:
HIPify 自动化迁移:HIPify 工具是 AMD 官方推荐的自动化解决方案,提供两种模式。hipify-perl 执行基于文本模式的替换,将 cudaMalloc 自动转换为 hipMalloc,将 cudaDeviceSynchronize 转换为 hipDeviceSynchronize,适合快速扫描和简单代码库。hipify-clang 则基于 Clang 编译器进行语义级别的精确转换,能够处理更复杂的模板和宏定义。
HIP 原生开发:对于新项目,直接使用 HIP API 编写可移植代码是更佳选择。HIP 7.0 将进一步缩小与 CUDA 的 API 差异,AMD 预计 HIP 7.0 可支持 90% 以上的 CUDA 内核直接编译。开发者还可以借助 AI 辅助工具描述代码逻辑,由 AI 智能映射 CUDA 指令到 HIP 等价实现。
框架层抽象迁移:对于使用 PyTorch、JAX 等高层框架的开发者,迁移工作主要在环境配置层面——安装 ROCm 版本的 PyTorch,验证 torch.backends.rockm.is_available() 返回 True,即可基本实现代码零修改运行。
4.2 内核级迁移的工程实践
对于包含自定义 CUDA 内核的项目,迁移工作更为复杂。以 FlashAttention-4 内核的 HIP 迁移为例,其核心挑战在于 CUDA 的 warp-level 原语(如 __shfl_sync)到 HIP 的等价转换,以及 AMD CDNA 架构特有的 wavefront 执行模型适配。
关键工程参数包括:
- 设置
HIP_VISIBLE_DEVICES=0限制单 GPU 测试 - 使用
-O3 -g编译标志启用优化和调试 - 将默认 wavefront 大小从 64 调整为 32 以匹配 CUDA 的 warp 习惯
迁移后预期存在 15–20% 的初始性能损失,可通过以下手段缓解:调整数据布局使全局内存读写以 128 字节(AMD cache line 大小)为单位;利用共享内存缓冲区预取数据块(典型大小 16KB);启用 hipBLASLt 进行矩阵乘法的自动内存合并。
4.3 常见踩坑与调试技巧
根据社区实践经验,ROCm 环境下最常遇到的问题集中在版本兼容性和环境变量配置上。稳定性排查的黄金法则是确保 ROCm 驱动、PyTorch 版本、系统内核三者严格匹配。当出现 CUDA 相关错误时,优先使用 ldd 命令检查二进制文件的动态链接库依赖,确认链接的是 ROCm 而非 CUDA 运行时。
在系统配置层面,建议在 /etc/environment 中添加 HSA_OVERRIDE_GFX_VERSION=11.0.0 和 HIP_VISIBLE_DEVICES=0 等环境变量,并使用 rocprof 工具监控内核执行情况。对于 Windows 用户,WSL2 环境下 ROCm 的安装仍有较多兼容性问题,建议优先使用原生 Linux 或 Docker 容器方案。
5. 云端高性能部署与性能优化
5.1 AMD 开发者云快速入门
AMD Developer Cloud 是体验 Instinct GPU 的最便捷途径,提供三种虚拟机配置模式:裸机操作系统(Bare OS)适合从零搭建自定义环境;Quick Start 镜像预装 ROCm 和 Docker 运行时;JupyterLab 环境则提供开箱即用的交互式开发体验。
以单 GPU 实例为例,完整的启动流程包括:登录开发者云控制台 → 选择 GPU Plan → 选择 Quick Start 镜像(推荐包含 vLLM/SGLang 的预配置版本)→ 添加 SSH Key → 一键创建虚拟机。
5.2 推理性能优化:QuickReduce 实战
多 GPU 场景中,All-reduce 通信往往是推理性能的瓶颈。QuickReduce 是一个面向 ROCm 的高性能 All-reduce 库,利用 AMD CDNA3 架构的向量指令集,在通信内核中内嵌压缩与解压缩操作。其支持的量化方案包括 FP8、Q8、Q6 和 Q4(4 位整数量化,块大小 32)。以传输 8 MB FP16 数据为例,Q4 方案可将数据量压缩至 2.25 MB(其中 2 MB 为量化数据,256 KB 为缩放因子),实现近 3.6 倍的数据压缩比。在 vLLM 和 SGLang 的集成中,QuickReduce 最高实现了 3 倍的 All-reduce 加速。
5.3 性能对标实测数据
表:AMD Instinct MI300X vs. NVIDIA H100 硬件规格与推理性能(Llama 3 70B FP8 推理)
| 指标 | MI300X | H100 | 优势 |
|---|---|---|---|
| 显存容量 | 192 GB HBM3 | 80 GB HBM3 | 2.4× |
| 理论算力 | 1,307 TFLOPS (FP16) | 989 TFLOPS (FP16) | 1.32× |
| 显存带宽 | 5.3 TB/s | 3.35 TB/s | 1.58× |
| Token 吞吐量(相同并发) | 较 H200 高 75% | — | 1.75× |
| 延迟 | 较 H200 低 60% | — | 2.5× |
数据来源:
此外,Kog 推理引擎在 MI300X 上实现了最高 3.5 倍 的 token 生成速度提升(对比 vLLM 和 TensorRT-LLM 在同类竞品 GPU 上的表现),在 1B-7B 参数的小模型上表现尤为突出。
6. 开源贡献与生态展望
ROCm 社区的开源治理模式正在快速发展。从提交第一个 PR 到参与核心组件的开发,贡献路径包括:修复文档中的 API 示例错误、为 hipBLAS 等底层库提交性能补丁、向 vLLM/SGLang 等上游框架贡献 ROCm 适配代码。
随着 HIP 7.0 的即将发布,HIP API 与 CUDA 的进一步对齐将显著降低跨平台开发成本;ROCm 对 Windows 和消费级 Radeon 显卡的扩展,也有望将 AMD AI 生态从云端延伸至桌面开发场景。
7. 结语
从 ROCm 6.0 的基础设施建设到 7.0 的性能飞跃,AMD 在云端 AI 领域的布局已从追赶进入并跑阶段。本文从软件栈架构、框架适配、代码迁移和性能优化四个维度,系统梳理了 ROCm 平台上云端 AI 开发的核心技术栈。对于开发者而言,掌握 HIP 编程模型、熟悉 ROCm 环境配置和性能调优工具链,不仅是解锁 AMD 硬件算力的关键,也是在日益多元化的 AI 计算生态中保持技术竞争力的必要储备。随着 ROCm 开放生态的持续繁荣,云端 AI 开发的全栈能力正在迎来开源重构的新阶段。

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)