
工业级推理双子星:拆解 vLLM 分页内存与 SGLang 树状复用机制
前两篇我们先是拆解了 KV Cache “空间换时间”的数学账,接着又当了一回“显存会计”,算清了多轮对话中那惊人的显存开销与碎片化导致的 OOM 噩梦。
既然传统推理框架“连续圈地、静态预分配”的做法太粗暴,工业界又是如何破局的?这一篇作为本系列的终结篇,我们将掀开工业界最耀眼的推理加速双子星——vLLM 与 SGLang 的底层黑盒,看它们如何用惊艳的工程创新拯救显存。

1. vLLM 的降维打击:PagedAttention(分页注意力)原理
2013年诞生的 vLLM 框架,其核心灵魂只有一句话:借操作系统的智慧,解大模型的显存危机。
现代计算机操作系统为了运行大于物理内存的游戏,会把内存切成无数个 4KB 的“页(Pages)”,到处乱放,再通过虚拟内存映射表让程序觉得内存是连续的。vLLM 团队把这套硬核机制搬到了 GPU 显存里,发明了 PagedAttention。
🧩 核心机制:化整为零,动态映射
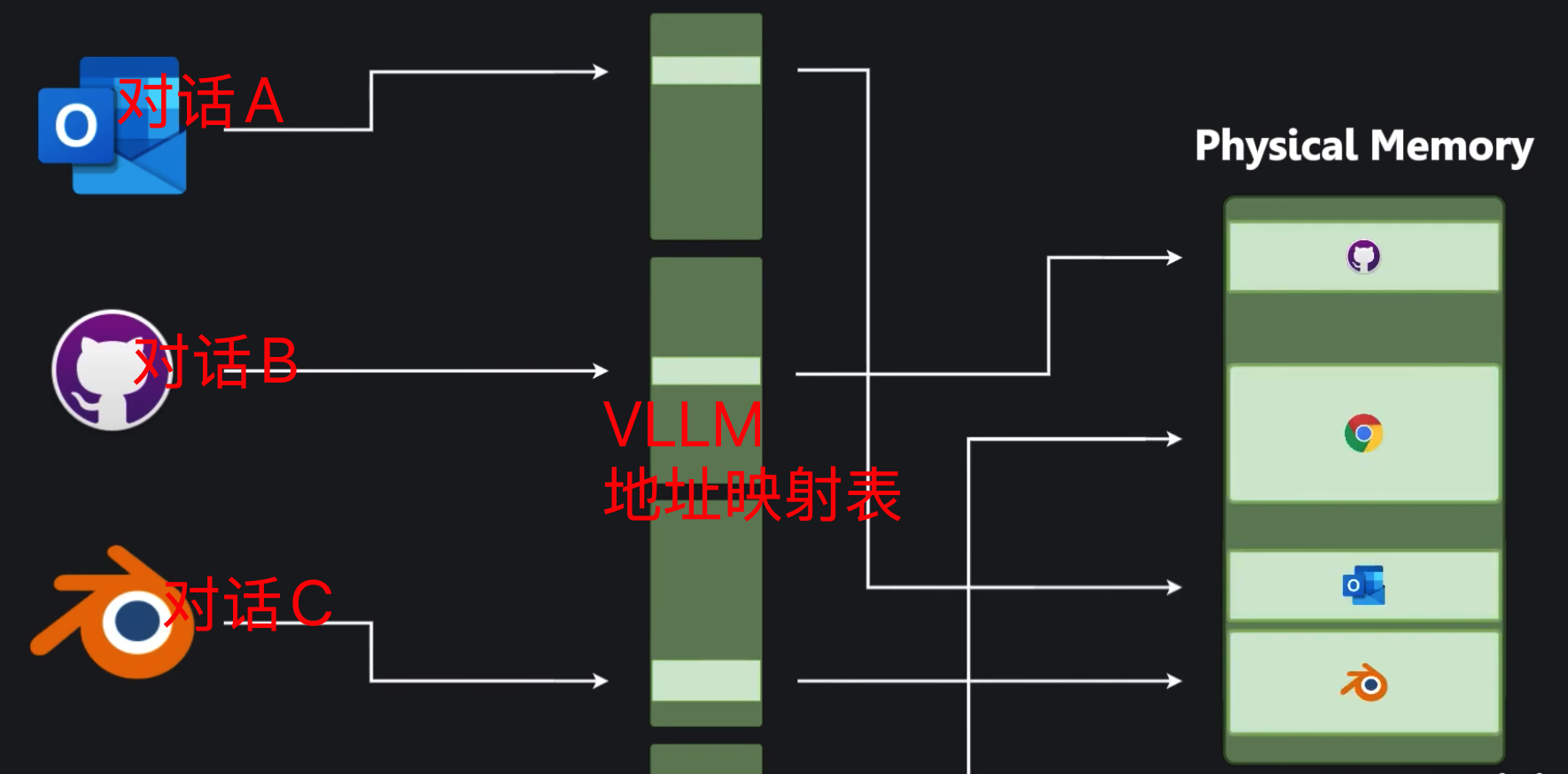
vLLM 抛弃了传统框架按 Max Length 连续圈地的粗暴做法,它在显存中开辟了一块巨大的空闲物理块池(Physical Blocks Pool)。
-
固定切块: 每一个块固定大小,雷打不动地只存放 16 个 Token 的 KV 值。
-
断而不乱的组织(Block Table):
在 vLLM 内部,每一个用户请求都拥有一张属于自己的“地图”——Block Table(块表)。块表是一个简单的二维整数张量,纯粹记录了“逻辑块”与“物理块车位号”的对应关系。在需要调用它的时候,就可以从对应的张量块里找到。
# 每一行代表一个并发请求,里面的数字就是物理块的“车位号(ID)”
block_tables = [
[102, 45, -1, -1], # 请求 0:前16个字在102号车位,17-32字在45号车位
[ 12, 88, 201, 14] # 请求 1:分散在 12, 88, 201, 14 号物理车位
]
这样做的好处是,vllm对所有对话都进行了管理,而且把一个大的显存空间切分为很多小的块,在基本不影响开销的情况喜爱。换来了对kvcache更高利用率和连续批处理;
2. SGLang 的百步穿杨:RadixTree(基数树注意力)原理
如果说 vLLM 完美解决了单个请求内显存怎么精细化分块的问题,那么 SGLang 则把目光投向了另一个更高级的维度:跨请求之间、多轮对话之间,大量重复的上下文凭什么不能复用?
在多轮对话或者 RAG(检索增强生成)场景下,几十个用户可能都在共享同一个长达 2000 字的系统提示词(System Prompt),或者同一个用户在反复提问。
- vLLM 的做法(APC机制): 对每 16 个 Token 计算 Hash,匹配到了就复用。这在线性前缀时有用,但在错综复杂的多轮对答和树状 Agent 协作时,线性的 Hash 表开始捉肘见襟。
- SGLang 的做法: 抛弃平铺的 Hash 表,改用了一种经典的数据结构——Radix Tree(基数树)。
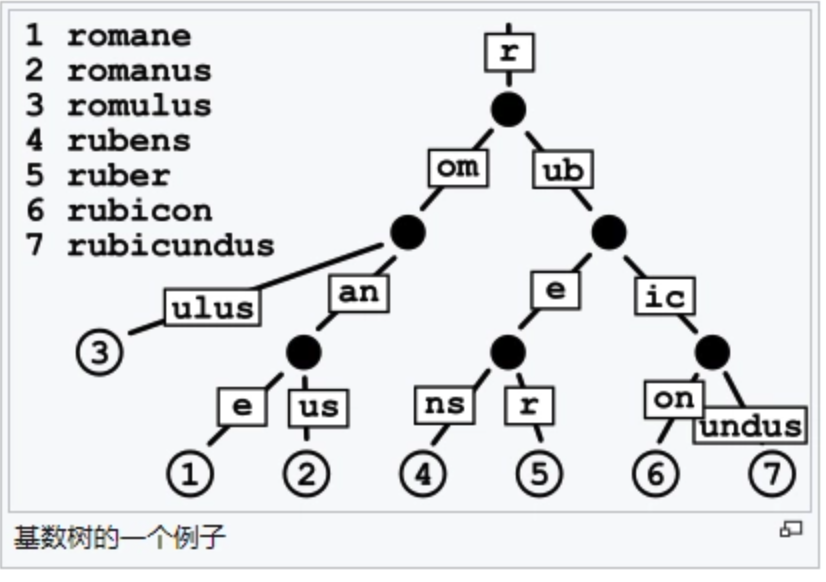
🌳 核心机制:顺着树枝找缓存
在 SGLang 的世界里,文本长句变成了树的“树干”与“树枝”,而每个节点都指向已经计算好的物理显存块。
- 树干(共享公共前缀): 所有人刚进聊天室时,公共的 System Prompt 算完一次 KV 后,作为这棵树的“主干”被死死锁住。所有并发用户的请求,其底层的 Block 直接指向这段公共物理内存,不仅免去了重复存储的空间,更直接跳过了这几千个字在 Prefill 阶段的巨额计算!
- 树枝(多轮对话分支): 用户 A 聊了三句,形成了分叉 A;用户 B 聊了三句,形成了分叉 B。当同一个用户开始新一轮对话时,SGLang 不需要去对暗号,而是顺着这棵树的节点路径“走顺风路”,无缝继承上一轮留下的所有 KV Cache。
- 精准的 LRU 淘汰: 当显存真的满了需要踢掉旧缓存时,系统能一眼看出哪些是聊完就走的“绿叶节点(边缘对话)”,优先抹去它们释放空间;而“树干(高频公共前缀)”则永远常青。
3. 推理优化的其他前沿版图
除了 vLLM 的分页和 SGLang 的树状复用这两大工程奇迹,近几年大模型在架构设计层面和软硬协同层面也自自带了防溢出 Buff:
-
模型本身的基因改良:GQA(分组查询注意力)
过去的模型采用 MHA(每个 Attention 头都有独立的 KV),现在主流的模型(如 Qwen2.5, Llama3)基本全面标配 GQA (Grouped-Query Attention)。它让 8 个或更多个 Query 头共享同一组 Key/Value 头。这直接在数学源头上,把 KV Cache 的体积砍到了原来的 1/4 甚至 $1/8。
-
数据精度的极限压缩:KV Cache 量化
既然模型权重可以量化,KV Cache 同样可以。目前工业界开始广泛落地 FP8 甚至 INT4 的 KV Cache 量化。把躺在显存里的 K 和 V 浮点数矩阵压缩成更低的位宽,显存占用瞬间减半,单卡能塞下的 Batch Size 再次翻倍。
🏁 系列总结与工程沉淀
纵观《彻底搞懂大模型推理加速》这三部曲,我们完成了从数学公式到物理显存,再到工业落地的全链路复盘:
- 第一篇: 我们明白了为了消灭 Decode 阶段O}(N^2)的重复矩阵乘法,模型无奈选择用空间换时间,诞生了 KV Cache。
- 第二篇: 我们手算账本,看清了多轮对话的滚雪球效应以及传统连续内存管理导致的巨额碎片,这是 OOM 的万恶之源。
- 第三篇: 我们见证了现代开源工程师们如何用操作系统的分页老智慧(vLLM)和高级数据结构(SGLang)把显存利用率榨干到极致。
大模型工程化的路还很长,从模型训练的“降维打击”,到软硬件交付时的“全链路调优”,内存管理与算子优化永远是永恒的主题。希望这个系列能帮你彻底拨开大模型推理的显存迷雾,在未来的调优与架构设计中,多一份底气,少几次 OOM!

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)