
vLLM推理引擎从入门到精通
1、Pytorch推理框架的缺点
- 静态连续内存分配:为每个请求的KV缓存预分配固定大小的连续内存块
- 内存浪费严重:按最大序列长度分配,实际使用远小于此,利用率常低于50%
- 无法共享内存:不同请求间的内存完全隔离,即使生成相同前缀也无法共享KV缓存
- 碎片化问题:请求的创建与释放导致内存碎片,降低可用内存总量
- 扩展性差:批处理大小受限于最坏情况的内存需求
2、理想推理框架的解决方案
- 动态内存管理:按需分配和释放内存,适应可变序列长度
- 内存共享:允许不同请求间共享相同的KV缓存块(如共享提示词前缀)
- 零碎片化:采用分页或块式管理,消除外部碎片
- 高吞吐量:支持更大的批处理规模,充分压榨GPU算力
- 低延迟:减少内存管理开销和等待时间
3、PagedAttention
(1)核心思想
PagedAttention是vLLM的灵魂,其灵感来源于操作系统中的虚拟内存和分页机制,它将每个请求的KV缓存划分为固定大小的块(Block),类似内存页,从而实现了高效灵活的内存管理。
(2)核心创新点
- 分块存储:将KV缓存分解为固定大小的块,例如每个块存储16个token的KV对
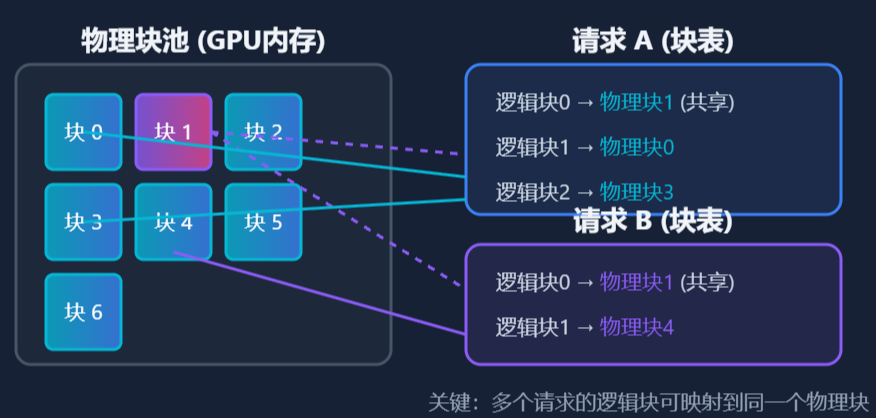
- 逻辑到物理的映射:每个请求维护一个块表(Block Table),记录其逻辑块到物理块的映射关系
- 内存共享:多个请求可以指向相同的物理块,实现前缀共享,显著减少重复计算和存储
- 高效利用:物理块池所有请求共享,按需分配和释放,几乎消除内存碎片
(3)PagedAttention核心逻辑伪代码
class PagedAttn:
def __init__(self, block_cnt, blk_sz):
self.pool = [KVBlock(blk_sz) for _ in range(block_cnt)]
self.free = list(range(block_cnt))
# 给请求分配KV块表
def alloc_req(self, req):
tbl = find_shared(req.prefix) # 复用共享前缀块
need = req.blk_num - len(tbl)
for _ in range(need):
tbl.append(self.free.pop() if self.free else evict())
return tbl
# 分页KV做注意力计算
def forward(self, req, q):
score_sum = 0
for pid in req.block_table:
k, v = self.pool[pid].k, self.pool[pid].v
score_sum += calc_attn(q, k, v)
return score_sum- 内存池pool是仓库存真实KV数据,free是空货架编号清单(只记哪些仓库格子没人用)
- 分配优先复用共享前缀块,不足则取空闲/驱逐旧块
- 前向遍历请求块表,逐个取物理KV块计算注意力合并
4、核心架构
(1)vLLM功能概述
vLLM是一个针对LLM推理设计的高吞吐量、低延迟服务引擎。
其核心创新在于引入了PagedAttention算法和高效的内存管理机制,解决了传统LLM服务中内存碎片化和利用率低下的关键瓶颈。
(2)核心架构图
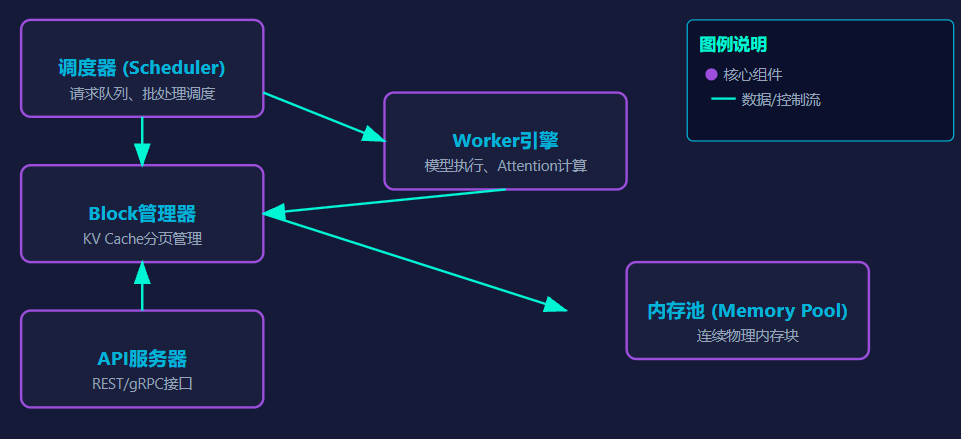
(3)核心组件功能
1)调度器
负责请求的生命周期管理和批处理优化。
关键技术:连续批处理、请求抢占、优先级队列
性能影响:吞吐量提升2~10倍,降低尾延迟
- 请求队列:管理待处理、运行中和已完成的请求
- 连续批处理:动态将新增请求加入运行中的批次,提高GPU利用率
- 优先级调度:支持基于优先级或SLA的调度策略
2)Block管理器
将KV Cache划分为固定大小的块(Block),并像操作系统管理物理内存一样管理这些块。
关键技术:KV Cache分页、块映射表、共享块
性能影响:内存利用率提升至80%,支持超长上下文
- 分页机制:将每个序列的KV Cache映射到非连续的物理块
- 零碎片化:块可被不同序列共享和重用,消除内存碎片
- 高效调度:支持请求的即时抢占和恢复
3)Worker引擎
执行模型前向传播的核心计算单元。
关键技术:融合内核、算子优化、CUDA Graph
性能影响:降低计算开销,提升单请求速度
- 模型加载与执行
- 优化的Attention内核:集成针对PagedAttention优化的CUDA内核
- 并行计算:充分利用GPU的并行计算能力
4)内存池
预分配和管理连续的GPU内存。
关键技术:预分配、块缓存、内存复用
性能影响:消除内存分配开销,减少碎片
- 预分配:启动时分配大块连续的GPU内存
- 块分配器:将内存池划分为固定大小的块供PagedAttention使用
- 内存统计:实时监控内存使用情况和碎片率
5、请求处理流程
一个用户请求在vLLM中的完整生命周期:
1.请求接收与解析:API服务器接收REST/gRPC请求,解析出prompt、生成参数等,并创建一个新的请求对象放入调度器的等待队列
2.调度与批处理:调度器根据策略(如FCFS、优先级)从等待队列中选择一批请求。它检查内存池中是否有足够的空闲块来容纳这些请求的KV Cache
3.块分配与映射:Block Manager为每个请求的序列分配物理块(可能来自空闲块或共享/回收获得),并建立逻辑序列到物理块的映射表
4.模型执行:Worker Engine将当前批次的请求(包含提示词和对应的块映射信息)送入GPU进行计算。优化的Attention内核根据映射表高效地访问分散地KV Cache块。
5.Token生成与流式返回:生成一个Token后,结果返回给用户(流式或非流式),同时新的KV Cache被写入已分配地块中。调度器判断请求是否完成(达到最大长度或生成结束符)。
6.资源回收:请求完成后,其占用地块被标记为可回收。Block Manager可能会将这些块加入空闲列表,或延迟回收以供未来序列共享使用。
6、动态批处理功能
(1)传统静态批处理
静态批处理核心思想是将多个请求打包乘一个固定大小的批次,一次性送入GPU进行计算,以充分利用GPU的并行计算能力,提高硬件利用率。其缺点是:
1.请求阻塞:一个批次必须等待其中最慢的请求完成后,才能释放资源处理下一个批次,快请求被慢请求拖累
2.资源利用率波动大:请求的输入/输出差异巨大,导致GPU计算和显存使用极不均衡产生大量空闲时间
3.无法适应动态负载:批处理大小固定,无法根据实时请求流量进行弹性伸缩,低峰期资源闲置,高峰期请求排队
4.长尾延迟高:单个慢请求会阻塞整批任务,不少用户需要长时间等待回复,聊天等交互场景体验很差。
(2)动态批处理
核心思想:以单token生成步为循环单位,每轮动态重组批次;请求生成即刻退出,新请求随时插入批次,无固定批次枷锁。
关键技术优势:
1.消除阻塞:每个请求独立推进,互不等待
2.高吞吐与低延迟兼得:GPU持续饱和工作,同时单个请求的端到端延迟显著降低
3.弹性伸缩:批次大小随请求数量动态变化,完美适应负载波动
(3)核心步骤
1.接收新请求:拉取新用户请求,存入等待队列
2.筛选活跃请求:遍历正在运行的请求,剔除已生成完毕的请求,剩余未结束请求加入本轮计算批次
3.调度新增请求:从等待队列挑选可调度请求,加入运行列表与本轮批次
4.模型单步推理:批次送入GPU执行前向,给每个请求追加生成token
5.返回流式结果:输出本轮生成的token,进入下一轮循环
7、内存高级优化技巧
1.连续块分配
为同一请求分配物理连续的块,提高内存访问局部性
2.预取策略
预测即将需要的块并提前分配,隐藏内存分配延迟
3.分层内存管理
区分热数据和冷数据,将不活跃块(针对滑动窗口注意力机制)移至低速内存
4.动态块大小调整
根据请求特征动态调整块大小,适应不同序列长度
8、推理流程
(1)Prefill阶段
功能:负责处理用户输入的完整提示词(prompt),为后续的解码阶段准备初始的KV Cache。
工作流程:
1.提示词token经嵌入层,得到初始隐状态
2.逐层遍历Transformer:
- 完成QKV投影与注意力运算,输出融合特征attn_output,同时返回本层K、V张量
- 分批物理页两块,将K、V存入分层KV Cache
- attn_output送入前馈网络,更新隐状态传入下一层
3.取末尾隐状态计算logits,采样生成首个输出token
4.返回首token与完整KV缓存,进入Decode迭代
(2)Decode阶段
功能:自回归生成。每次迭代生成一个token,并利用Prefill阶段准备好的KV Cache避免重复计算。
工作流程:
1.单一生成token做嵌入,得到单步隐状态
2.逐层遍历Transformer:
- 读取该层历史KV缓存
- 复用旧KV,仅增量计算新token注意力,输出新K、V与融合特征
- 特征送入前馈网络,更新隐状态传递下层
3.收集每层新增KV,追加更新全局KV缓存
4.末尾隐状态算logits,采样得到下一个token
5.返回新token与更新后的KV缓存,循环迭代生成
(3)混合阶段
功能:在实际生产环境中需要同时处理Prefill请求(新请求)和Decode请求(进行中的请求),混合阶段负责智能调度这两种不同类型的计算任务。
混合调度策略:
1.优先级调度:Decode请求通常具有更高优先级,以减少延迟
2.资源分区:动态分配计算资源给Prefill和Decode任务
3.内存感知调度:考虑KV Cache内存使用情况做出调度决策
4.抢占式调度:允许高优先级Decode请求中断长时间Prefill计算
9、FlashAttention
(1)核心思想
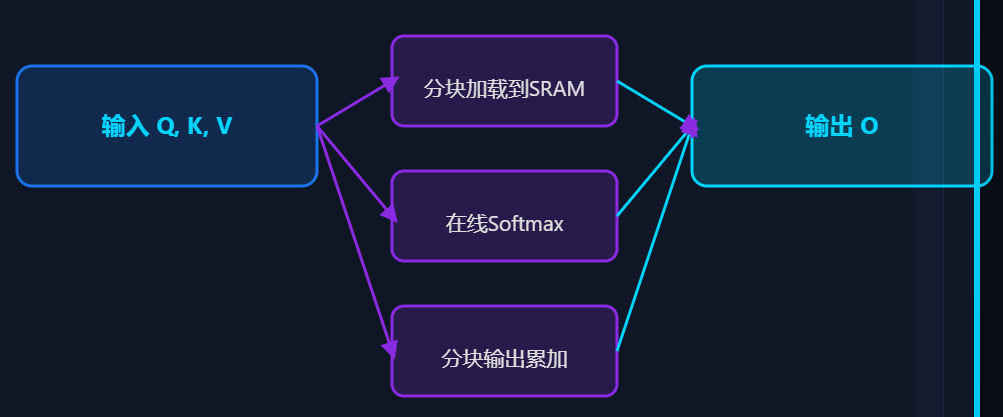
它是一种重新设计注意力计算顺序的算法,避免实例化庞大的中间注意力矩阵,通过分块计算在SRMA(高速缓存)中完成大部分操作,显著减少HBM访问。
(2)集成方式
1.内核级融合:将矩阵乘法、Softmax、掩码应用、Dropout等操作融合到单个CUDA内核中
2.内存布局优化:确保Q、K、V张量在内存中连续存储,以最大化内存吞吐量
3.动态适配:根据GPU型号(如A100、H100)和输入形状自动选择最优的分块大小
(3)两级分块策略
1)序列分块
将长序列分割为多个子序列:将Q序列分为多个块,每个块独立计算注意力
2)KV分块
在每个Q块内,对K、V进行分块加载:滑动窗口加载K、V块,在线更新Softmax归一化因子
(4)在线Softmax与重计算
分块计算的关键挑战是Softmax的归一化需要全局信息。
1.为每个Q块维护两个累加器:指数和(sum_exp)和最大值(max)
2.处理每个K、V块,更新局部最大值和指数和
3.最终通过重缩放(rescaling)得到正确的Softmax输出
10、分布式推理
(1)背景
LLM参数太大,单个GPU内存已无法容纳整个模型。通过Tensor Parallelism(TP)和Pipeline Parallelism(PP)等并行策略,将模型高效分布到多个GPU上,同时通过先进的通信优化技术,最大限度地降低并行带来的开销。
(2)TP实现
张量并行:将单个权重矩阵在列维度和行维度上切分,分布到多个GPU上。每个GPU持有模型的一部分参数,并执行相应的部分计算,通过All-Reduce通信操作聚合结果。
核心原理:
- 层内并行:针对Transformer中的线性层(如QKV投影、FFN)进行切分
- 分片计算:每个GPU计算分片结果,前向传播需要All-Gather,后向传播需要Reduce-Scatter
- 内存均衡:每个GPU只存储部分参数和激活值,显著降低单卡内存需求
(3)PP实现
流水线并行:将模型按层划分到多个GPU上,每个GPU负责模型的一个连续层块,以微批次(micro-batch)流水线方式执行,隐藏通信延迟,提高设备利用率。
工作模式:
- 前向传播:每个GPU完成自身层块的计算,将激活值传递给下游GPU。点对点发送的通信。
- 后向传播:梯度从下游GPU反向传递回上游GPU。点对点发送的通信。
- 优化器步骤:每个GPU独立更新自己持有的参数。无通信。
(4)通信优化
| 技术 | 原理 | 收益 |
|---|---|---|
| 通信与计算重叠 | 在计算的同时,异步进行梯度或激活的通信。 | 隐藏大部分通信延迟 |
| 梯度融合 | 将多个小张量的梯度合并为一个大的张量再进行通信。 | 减少通信次数,提高带宽利用率 |
| 分层All-Reduce | 在节点内使用NVLink,节点间使用InfiniBand,分层优化。 | 适应异构网络拓扑 |
| 通信调度优化 | 根据计算图依赖,智能调度通信操作顺序。 | 避免资源争用,减少等待 |
11、vLLM新模型适配方法
1)继承基类
从vllm.model_executor.models.BaseModel或同类模型(如LLaMAForCausalLM)继承,定义模型类
2)实现forward
重写前向传播,确保输入(input_ids, positions, kv_caches, attn_metadata)和输出(logits)符合vLLM规范
3)加载权重
在__init__中通过load_weights加载Hugging Face格式或自定义权重,并确保支持张量并行(TP)
12、Beam Search
(1)运行机制
1.初始化
束集合:{(输入前缀,累计对数得分=0, 长度=L)}
2.循环体(重复直到终止)
1)展开:对束中每个候选,取模型输出概率最高的前V个token,生成K * V个新序列
2)计分:计算每个新序列的累计对数概率,并立即进行长度归一化:
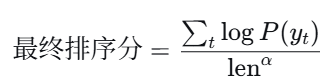
其中为长度惩罚系数,用于抵消长句天然分低的偏差
3)剪枝:将所有新候选按上述最终排序分降序排列,截断保留前K个
4)迭代:将保留的K个序列作为下一轮的输入,返回步骤1)
3.终止条件
达到预设最大长度(manx_tokens)或全部候选均生成结束符([EOS])。
(2)为什么用Log
连乘导致数值下溢,改用Log累加,,数值安全
(3)为什么必须加长度惩罚
Log值均为负数,句子越长累加值越小。不加惩罚,模型回病态地偏好短句。通常取1.0。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)