
Mini-SGLang,30万行代码浓缩为5000行,大模型推理高性能教学与研究模版
SGLang发布了Mini-SGLang。

将30万行代码的庞然大物浓缩为5000行,在保留Radix Attention和Overlap Scheduling等核心特性的同时,为大模型推理提供了一个高性能的教学与研究模版。
大语言模型的推理服务正在变得越来越复杂。
为了追求极致的性能,现代推理框架如SGLang、vLLM等不断引入新的优化技术。
这些技术虽然提升了吞吐量和响应速度,但也让代码库急剧膨胀。以SGLang为例,其为了实现最先进的推理性能,代码量已逼近30万行。
庞大的代码库形成了一道无形的壁垒。
对于想要学习推理引擎底层原理的学生,或是希望快速验证新想法的研究人员来说,面对几十万行的代码往往无从下手。
牵一发而动全身的复杂依赖关系,使得任何微小的改动都可能破坏系统的隐式不变量,导致难以调试的错误。
Mini-SGLang应运而生。
这是一个轻量级却高性能的推理框架。
它继承了SGLang的核心架构,却将代码量压缩到了惊人的5000行。
它不是一个玩具,而是一个麻雀虽小五脏俱全的现代化推理引擎,旨在通过极简的代码揭示现代服务系统的复杂性。
源代码地址:
https://github.com/sgl-project/mini-sglang
为什么要构建Mini-SGLang
构建这样一个精简版引擎的初衷非常纯粹,主要是为了解决两个核心痛点:教育门槛过高与科研原型开发困难。
现有的高性能推理框架对于初学者来说过于晦涩。
数以万计的文件和模块掩盖了推理引擎真正的核心逻辑。
Mini-SGLang通过极致的模块化设计,将核心组件剥离出来。
这5000行代码是一份关于大模型推理的活体教科书。
它既支持在线推理也支持离线推理,并且没有因为精简而牺牲关键技术。
Tensor Parallelism(张量并行)、Overlap Scheduling(重叠调度)、Chunked Prefill(分块预填充)、Radix Cache(基数缓存)以及JIT CUDA Kernels(即时编译CUDA内核)等现代优化技术一应俱全。
对于系统研究者而言,Mini-SGLang提供了一个完美的中间地带。
以前研究者面临两难选择:要么在复杂的现有框架中艰难地植入新逻辑,承担破坏原有系统的风险;要么从零开始构建引擎,耗费数周时间处理前端服务器、分词器、NCCL通信等基础设施,仅仅为了对齐基线性能。
Mini-SGLang解决了这个问题。
它既处理了基础设施的繁重工作,又保持了足够的灵活性。
研究人员可以利用它快速验证新的系统构想,利用其提供的OpenAI兼容接口和基准测试工具,轻松地与SGLang、vLLM或TensorRT-LLM等成熟引擎进行端到端的性能对比。
对于内核开发者,它甚至提供了细粒度的NVTX注释,这对性能分析和内核调试具有极高的价值。
系统架构与核心特性
Mini-SGLang沿用了SGLang的高级系统架构设计。
整个系统由三个主要部分组成:处理请求的前端API服务器、负责文本处理的分词器服务器,以及每个GPU上独立的后端调度器。这种分离式的设计保证了系统的扩展性和模块间的解耦。
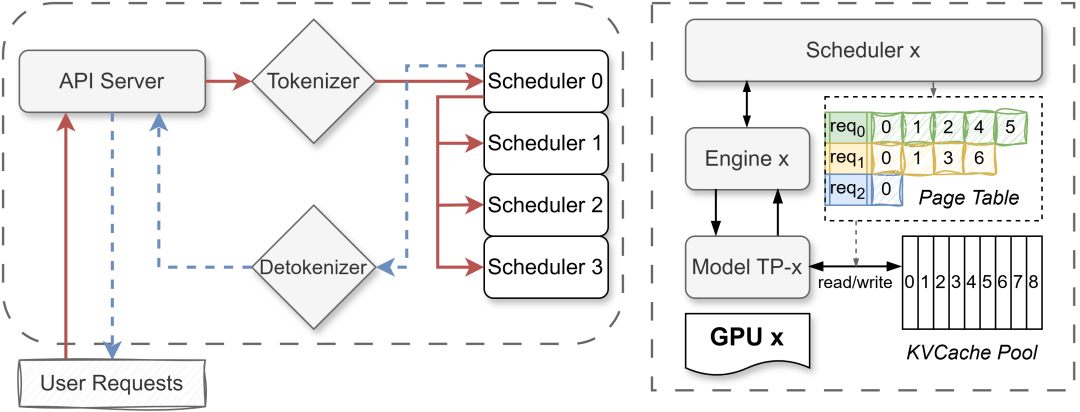
在具体的特性实现上,Mini-SGLang开箱即支持Llama-3和Qwen-3等主流模型,并且通过OpenAI兼容的API,使得用户可以无缝迁移现有的应用。
但其真正的威力在于内部的调度机制和计算内核。
大模型推理不仅仅是GPU的计算任务。
在实际运行中,CPU承担了大量繁琐的工作,包括批处理调度、内存管理以及令牌处理。
在未经优化的系统中,GPU经常需要等待CPU完成这些准备工作才能开始计算。
这种等待会导致GPU处于空闲状态,直接拉低了整体的推理吞吐量。
Mini-SGLang引入了与SGLang类似的重叠调度机制(Overlap Scheduling)。
其核心思想是并行化。
当GPU正在全力计算当前批次的请求时,CPU并不闲着,而是立即开始准备下一个批次的请求数据。
通过这种流水线式的作业方式,CPU的处理开销被GPU的计算时间完美掩盖。
从Nsight Systems的性能分析图中可以清晰地看到这种差异。
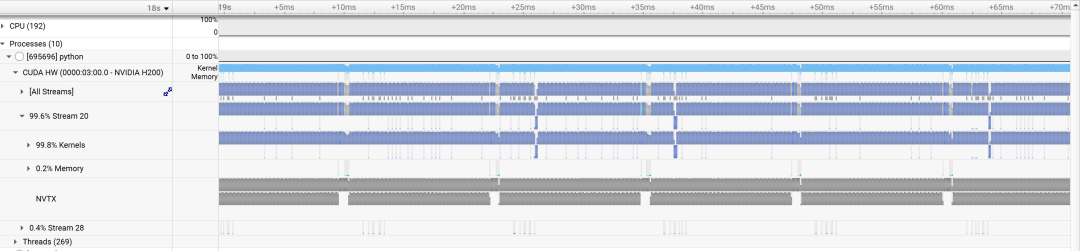
上图展示了开启重叠调度后的执行情况。可以看到,GPU的时间轴被填满,计算任务紧密连接,几乎没有空隙,CPU的开销被完全隐藏在GPU计算的阴影之下。
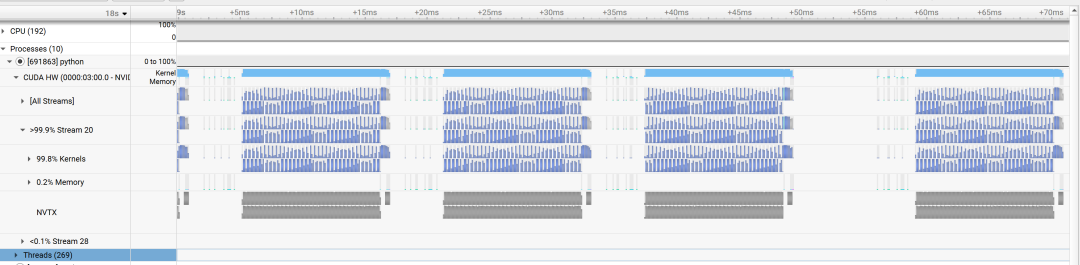
作为对比,上图展示了非重叠执行的情况。GPU在完成一段计算后,必须等待CPU处理完下一段数据,导致时间轴上出现了明显的空白间隙(GPU Stalls)。这些间隙就是性能的流失。
用户可以通过设置环境变量 MINISGL_DISABLE_OVERLAP_SCHEDULING=1 来关闭这一功能,从而进行消融实验,亲身体验这一机制带来的性能差异。
高性能内核与即时编译技术
为了确保在计算层面的极致性能,Mini-SGLang集成了一系列最先进的注意力内核。
在NVIDIA Hopper架构的GPU上,它采用了FlashAttention-3作为预填充(Prefill)阶段的内核,利用其极高的并行度加速首词生成。
而在解码(Decode)阶段,则使用了FlashInfer内核,以优化逐词生成的延迟。
不仅如此,Mini-SGLang紧随FlashInfer和SGLang的步伐,集成了即时编译(JIT)内核技术。
在Python与底层C++/CUDA代码的交互上,它抛弃了传统的PyTorch接口,转而采用TVM FFI(Function Foreign Interface)。
TVM FFI的设计更加轻量级,能够显著减少Python调用底层函数时的开销,这对于需要频繁调用内核的推理任务至关重要。
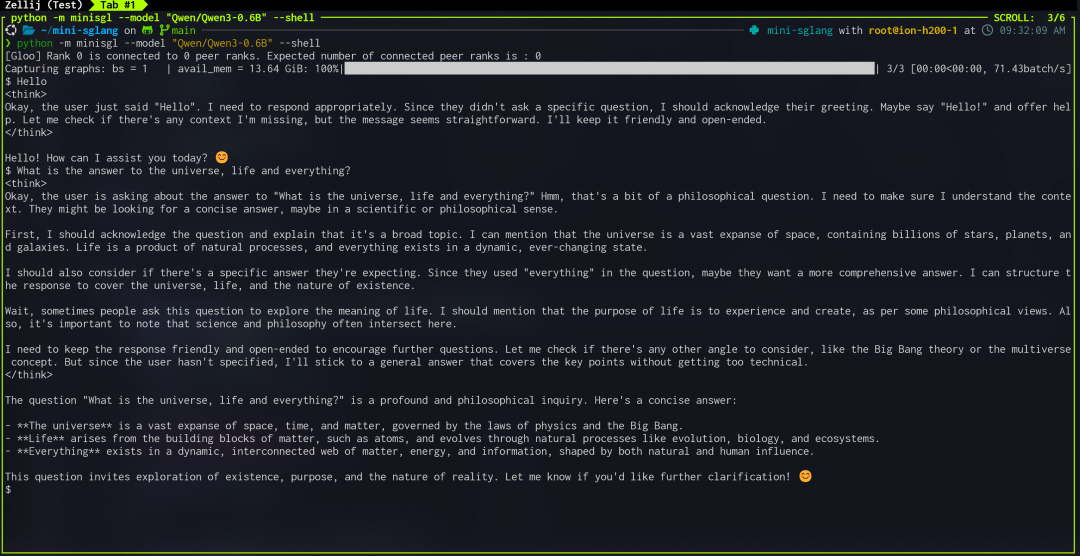
Mini-SGLang不仅仅是一个后台引擎,它还提供了便捷的交互工具。
通过内置的Shell模式,用户可以直接在命令行中与大模型进行对话。
这省去了搭建独立客户端的麻烦,使得测试模型行为和调试变得异常简单。
为了验证Mini-SGLang的性能,团队进行了严谨的基准测试,涵盖了离线吞吐量和在线服务延迟两个维度。
在离线推理吞吐量的测试中,对比对象选择了Nano-vLLM。
测试在单张NVIDIA H200 GPU上进行,使用了Qwen3-0.6B和Qwen3-14B模型。选择Qwen3系列是因为Nano-vLLM基线目前的兼容性限制。
测试结果以每秒生成的令牌数(tokens per second)为指标。
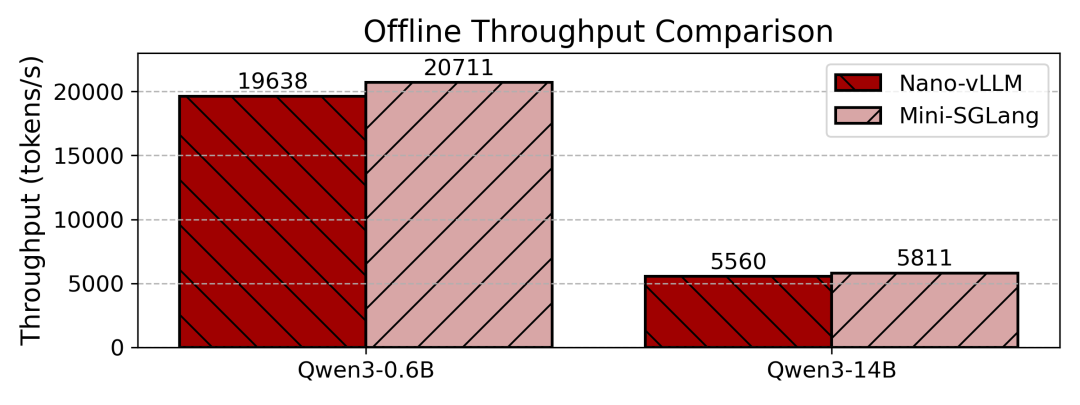
结果显示,Mini-SGLang在两个模型尺寸上均持续领先于Nano-vLLM。这一优势主要归功于前文提到的重叠调度机制,它有效地消除了CPU带来的瓶颈。
在线服务延迟的测试则更加贴近真实生产环境。
对比对象是全功能的SGLang。
测试环境为4张H200 GPU,部署了Qwen3-32B模型,并开启了4路张量并行(Tensor Parallelism)。测试负载重放了包含1000个请求的真实Qwen追踪数据,重点观测吞吐量、P90首字延迟(TTFT)以及词间延迟(TBT)。
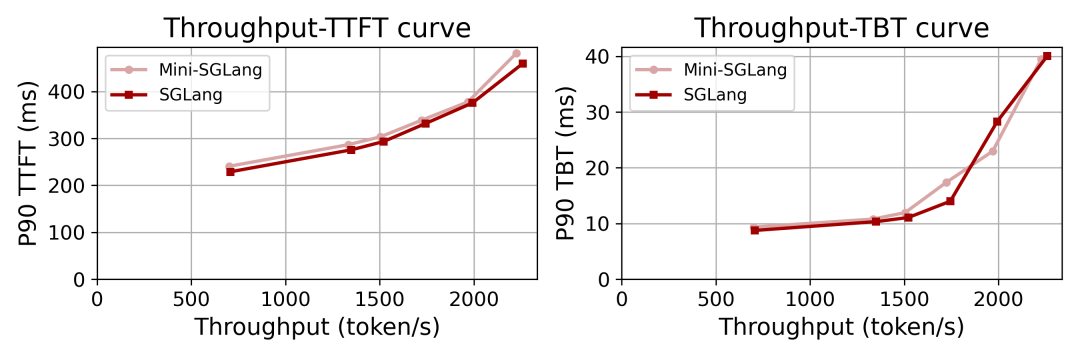
数据表明,Mini-SGLang实现了与SGLang几乎完全一致的性能表现。这证明了轻量化设计并没有以牺牲性能为代价。无论是高吞吐量还是低延迟,Mini-SGLang都经受住了考验。
为了保证结果的可复现性,所有的基准测试脚本都已经开源。用户可以使用简单的命令启动服务进行验证:
# 启动 Mini-SGLangpython -m minisgl --model "Qwen/Qwen3-32B" --tp 4 --cache naive # 启动 SGLangpython3 -m sglang.launch_server --model "Qwen/Qwen3-32B" --tp 4 \ --disable-radix --port 1919 --decode-attention flashinferMini-SGLang通过精心的设计和对核心技术的精准把握,成功地将最先进的推理能力封装在一个易于理解、易于扩展的精简框架中。
无论是为了通过阅读源码掌握LLM推理的精髓,还是为了在坚实的基础上快速构建研究原型,Mini-SGLang都是一个不可多得的工具。
Mini-SGLang的母项目SGLang(Structured Generation Language)是一个致力于提高大语言模型推理效率和可控性的开源项目。它不仅关注底层的推理加速,还设计了一种专门的领域特定语言,用于处理复杂的结构化生成任务。
SGLang最著名的贡献之一是提出了Radix Attention技术,这是一种基于前缀树(Trie)管理的KV缓存机制,极大地提高了多轮对话和复杂Prompt下的缓存复用率。
Mini-SGLang剥离了复杂的上层语言特性,保留了底层的推理精华,才得以实现如此高的性能密度。
探索Mini-SGLang,就是探索现代大模型推理技术的本质。
参考资料:
https://lmsys.org/blog/2025-12-17-minisgl/
END

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)