
LM Studio 之高级篇 LM Link
上一篇对LM Studio初体验后,打开了LM Link竟然有惊喜。
LM Studio的链接功能(LM Link) 是其核心特性之一,主要用于远程设备间的模型共享与协作,同一用户可以免费支持5台设备,让你可以在本地调用远程设备(如服务器或高性能主机)上的模型,就像使用本地模型一样。即然是这样,我不就可以用家里电脑上的显卡来养单位电脑上的小龙虾了吗?好奇的试了一下竟然是真的可以。其联网原理大概是类似vpn+b2b技术。
安装过程是这样的:
首先注册用户,在测试期间注册用户还要排队,我大概排了一个小时,现在可能不用排队了。国内用户只能使用邮箱或使用github帐号注册。
注册完成后使用命令启动服务和登陆:
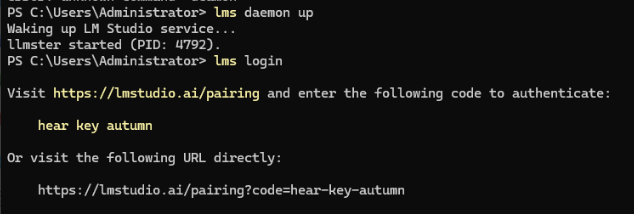
如上图将显示的URL复制到浏览器上,点两个确认就行了。
打开windows上的 LM Studio 界面点击LM Link图标后,可以看到自己的电脑设备已在线,在界面上点击蓝色加号(+)图标:
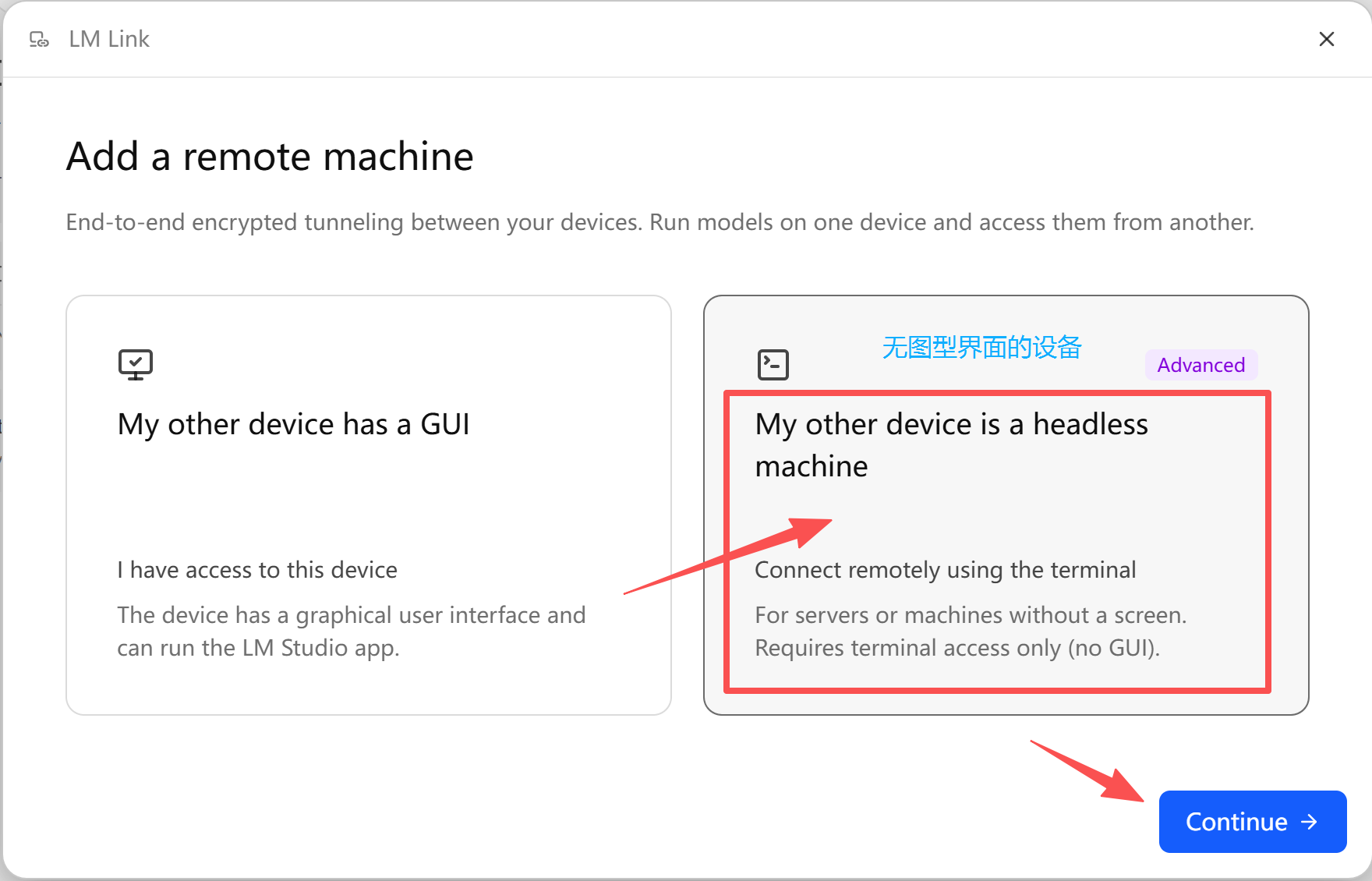
选择我的另一台设备不带GUI界面的,点Continue下一步:
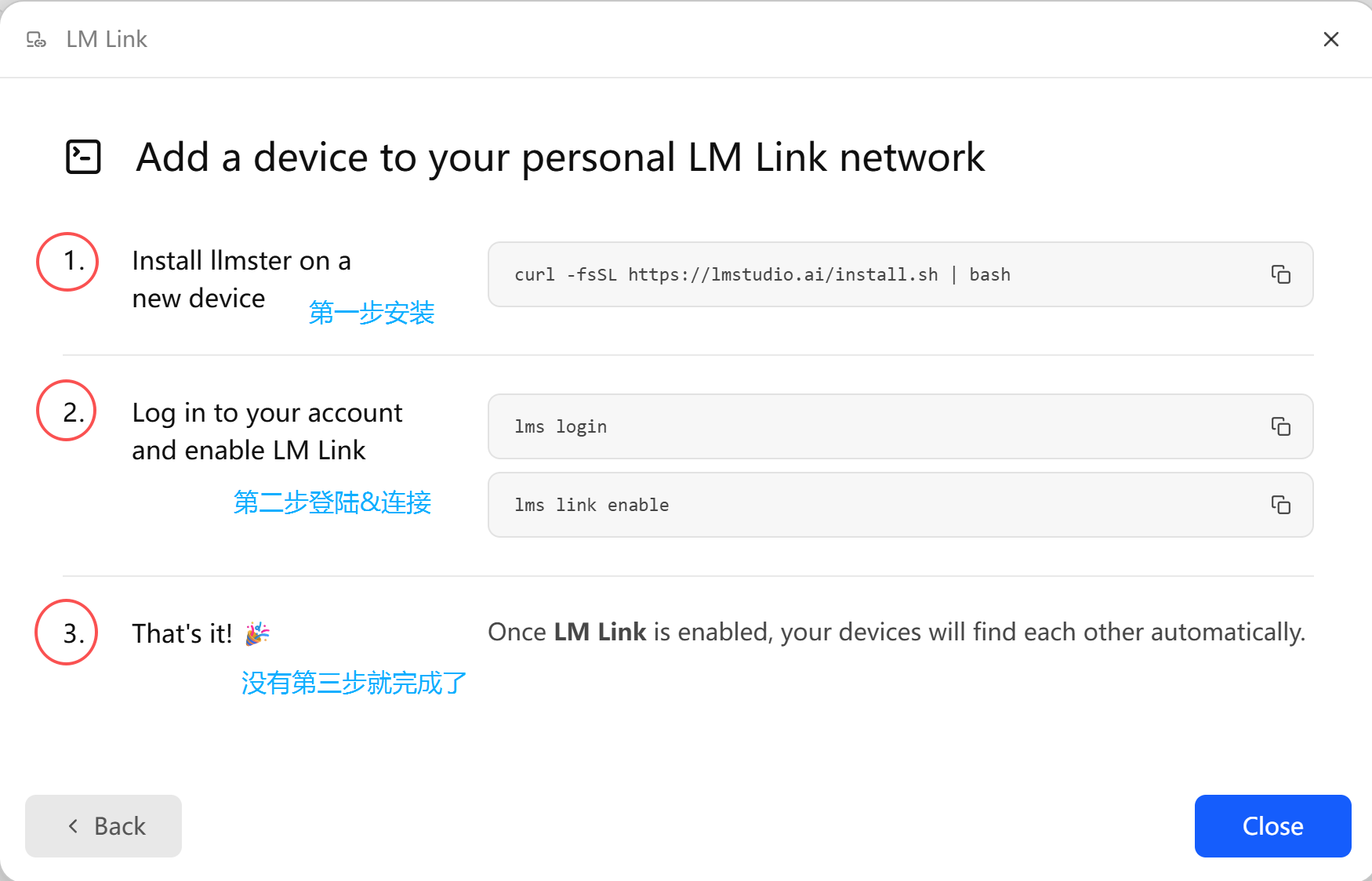
按照图示的三步,分别进行,用同一个用户登陆就行了。
我在另一台设备因为是linux服务器,操作系统是 centos stream 10,c++版本较新,所以安装的很顺利,如果是旧版本没有GLIBCXX_3.4.30可能要升级C++的Lib,可参考我另一篇文章,正常应该如下图:
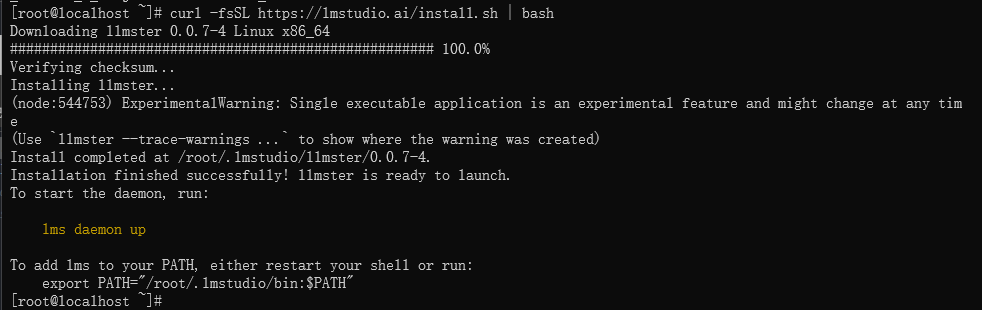
装完后按照提示,lms daemon up,服务就启动了,然后登陆同一个帐户。只需要把lms login显示的URL复制到浏览器里(不一定要用本机的浏览器),选择邮箱或github授权,就可以了,也不需要密码。
完成后回到windows LM Studio 界面,即可看到新设备了。如果没有,试试lms lmlink enable命令。
起动一个对话:lms chat
/model显示所有两台设备上下载的模型。选一个远程设备的试一下,能够正常聊天。
起动本地接口服务:lms server start
可以适用opent ai的服务器接口,如:https//127.0.0.1:1234/v1
将URL链接配置到小龙虾openclaw里,即可使用两台设备的本地模型无限token了。
注意一点装载本地模型时上下文默认是4096,如果让小龙虾使用,要把上下文设长一点儿,如:
lms load -c 10240 #代表10k上下文。
再选择模型。
上下文的大小,不能超过模型限制,一般新模型象qwen3.5可以200k,也不能超过显卡显存限制,可以通过windows的LM Studio界面,通过CTRL + L 配置装载模型,设置上下文时能同时显示需要占用的显存大小,如果超过限制,装载模型时容易造成死机。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)