轻松玩转开源大语言模型bloom(二)
本期用实例介绍两种通用的文字生成解码策略:greedy search和beam search。
前言
书接上文,我们已经可以通过简单的示例来使用bloom的文字生成功能,那文字生成的策略具体有哪些呢?我们该如何控制bloom来生成我们想要的效果呢?本文将从解码策略开始,介绍两种最基础的策略:greedy search(贪婪搜索)和beam search(粒子束搜索)。
贪婪搜索
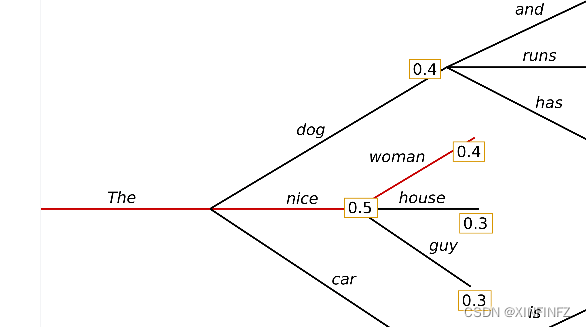
贪婪搜索的策略很简单,由于词是一个接一个生成的,在每次生成词的后面都选择计算出的概率最高的那一个词连在一起就可以了,在这里我引用一下别人的图:
输入是The,第一个选择概率最高为0.5的nice,第二次选择该分支下概率最高为0.4的woman,总分支概率为0.5x0.4=0.2。
使用hugging face的model.generate示例如下:
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
a1 = time.time()
checkpoint = "bigscience/bloom-1b1"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
inputs = tokenizer.encode("我和我的猫都很想你", return_tensors="pt") #prompt
outputs = model.generate(inputs,min_length=150,max_length=200)
print(tokenizer.decode(outputs[0])) #使用tokenizer对生成结果进行解码
a2 = time.time()
print(f'time cost is {a2 - a1} s')
注意看本例中只使用了min_length和max_length这两个参数,默认不设置其他影响策略的参数情况下会使用贪婪搜索。
生成效果如下所示:

可以发现一开始还正常,后面就变成了无意义的重复,这是使用这种策略最明显的缺点。
粒子束搜索
粒子束,顾名思义,即一整个句子的联合概率,在这里我们先假设num_beams=2,即有两条粒子束的情况:
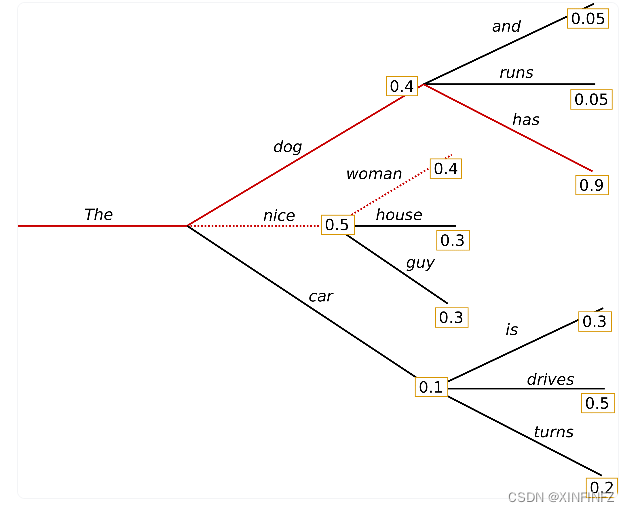
可以看到概率最高的实线是0.4*0.9=0.36,比我们原来使用贪婪搜索得到的0.2的那条虚线概率要大,粒子束搜索的好处就在这里,可以考虑到后面概率高的词,比如这里0.9概率的has。当然,粒子束搜索从本质上说只是限定部分的广度优先搜索罢了,它是启发式的,没法得到全局最优解,所以该有的毛病它一样有。
使用hugging face的model.generate示例如下:
outputs = model.generate(inputs,min_length=150,max_length=200,
num_beams=5,early_stopping=True)
和贪婪搜索在使用上的区别仅仅是设定了num_beams的数量和早停机制。当早停设为True时,一旦num_beams找到了足够的候选粒子束,就会停止搜索,如果为False,那么会增加一个启发式的搜索,当不太可能找到候选时会停止搜索,如果设置为never,只有确定不会再有更好的候选时会停止搜索。
生成效果如下所示:

效果很差,不仅包含重复,时间还比刚刚慢上30S,增大num_beams可能使效果变好,但时间的增加也是成倍增加,比如当num_beams=10时的效果:

限制粒子束搜索
在这里我只介绍两个技巧,设定条件限制重复词汇和强制生成我们想要的词汇,更多的技巧请自行参阅huggingface的文档。
限制重复词汇:
outputs = model.generate(inputs,min_length=150,max_length=200,num_beams=5,
no_repeat_ngram_size=2,early_stopping=True)
即设置no_repeat_ngram_size参数,表示最多重复的词汇数。
生成效果如下:
我和我的猫都很想你,想你的时候,我就会想起你。
猫咪,我爱你。 我爱你,我的小猫。
你是我生命中不可缺少的一部分,你是我生命中的阳光,你的出现,让我的生活多了一抹亮丽的色彩,使我的生命更加丰富多彩。
你的到来,给了我无尽的快乐和幸福,让我感到无比的幸福和快乐。
在你的陪伴下,我不再孤单,不再寂寞,我在你的怀抱中,感受到了家的温暖,感受到家的亲切,感到家的温馨。
我的生命因你而更加精彩,因为有了你的存在,使我的人生更加充实,更加有意义。
因为有你在我身边,我才感到生活的意义,才感到生命的价值。因为有你的相伴,我对生活充满了信心,对未来充满了希望。</s>
time cost is 97.57852363586426 s
强制生成想要的词汇:
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
a1 = time.time()
checkpoint = "bigscience/bloom-1b1"
force_words = ["回家"] #强制词汇
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
force_words_ids = tokenizer(force_words, add_special_tokens=False).input_ids #装载
inputs = tokenizer.encode("我和我的猫都很想你", return_tensors="pt")
outputs = model.generate(inputs,force_words_ids=force_words_ids,min_length=150,max_length=200,num_beams=5,no_repeat_ngram_size=2,early_stopping=True)
print(tokenizer.decode(outputs[0]))
a2 = time.time()
print(f'time cost is {a2 - a1} s')
这里我们强制要求生成的故事里包含回家的词汇,然后用force_words_ids控制。
生成效果如下:
我和我的猫都很想你。 猫咪:你什么时候回来?
狗狗:明天。 我:哦,好。 明天,明天,我一定回来。
狗:好,再见。 小狗:再见,小猫。 你什么时候回家? 小猫:今天。 今天,今天,我今天一定回家。
天黑了,狗和猫都睡着了。 一天过去了,猫和狗都睡得香甜。
第二天一大早,天刚蒙蒙亮,就听见狗的叫声,原来是猫回来了。
狗对猫说:"猫,你今天怎么这么晚才回家呢?"
猫对狗说:"我昨天晚上没睡好觉,所以今天才迟到。"
狗说:"那你为什么不早一点回来呢?""我明天还要上班呢!"
猫回答道。 "上班?"
狗又问道,"你明天要上班吗?" "是的,我要上班。""那为什么还迟迟不回来?" "我怕
time cost is 115.72432279586792 s
可以看到整个故事确实按照我们的要求生成了。
后记
下期我们将介绍更多的解码策略。隔了这么久才更新是因为上周得了甲流,真比新冠还难受,我推荐各位如果得了尽早尽快的吃奥司他韦,有和我一样有基础病(咽炎)的这种就同时吃阿莫西林抑菌。
引用
https://huggingface.co/blog/how-to-generate
https://huggingface.co/docs/transformers/generation_strategies
https://huggingface.co/blog/constrained-beam-search

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐

 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)