一文详解opencv摄像头数字识别
本文的目标是实现识别摄像头图像中的数字。实际应用场景包括 车牌号识别 ,部分竞赛的 A4纸打印数字识别 。摄像头数字识别分为两个步骤:1. 提取图像中的ROI区域,如截取车牌的矩形区域,或截取A4纸的图像。2. 对ROI区域进行数字识别。数字识别相对来说较为简单,先介绍数字识别的方法和原理。
OpenCV数字识别
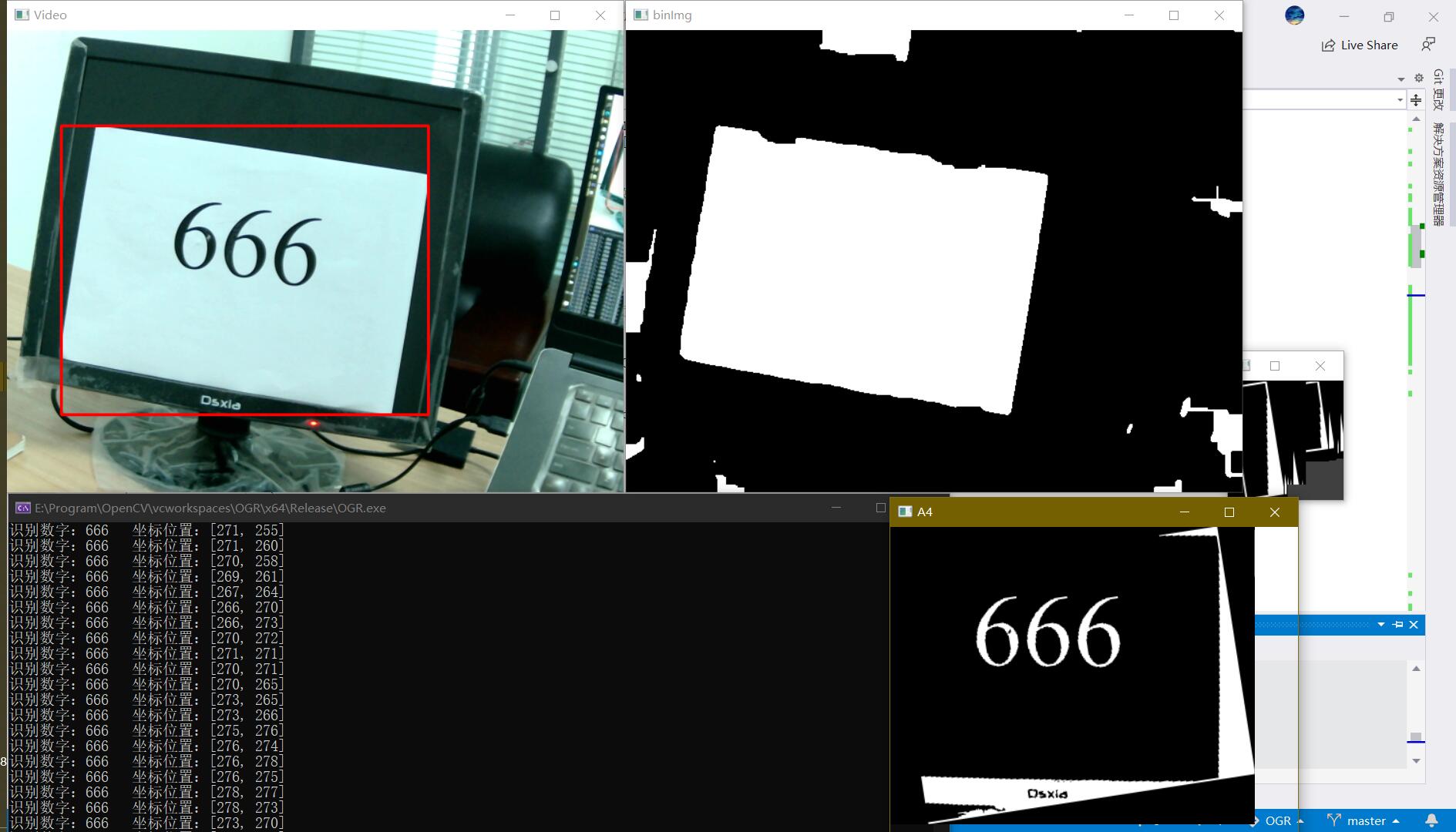
本文的目标是实现识别摄像头图像中的数字。实际应用场景包括车牌号识别,部分竞赛的A4纸打印数字识别。项目实现结果如下,完整工程文件点此下载:

摄像头数字识别分为两个步骤:
- 提取图像中的ROI区域,如截取车牌的矩形区域,或截取A4纸的图像。
- 对ROI区域进行数字识别。
数字识别相对来说较为简单,先介绍数字识别的方法和原理。
一、数字识别的两种方式
1.1 轮廓提取法
实现思路为对ROI区域进行轮廓提取,然后将所有找到的轮廓与模板逐一匹配识别,相似度大于所设阈值,可视为识别成功。
寻找轮廓所使用的函数为findContours(),利用此函数将所有寻找到的轮廓保存在contours中,然后使用循环画出包围每一个轮廓的最小矩形。
利用每一个小矩形,提取图像中的每一个轮廓图像,将其与模板做差,如果差值越小,说明像素越接近,相似程度越高,以此来实现数字匹配。
//轮廓提取主函数
int main()
{
//读取一张图像,转换为灰度图并进行二值化处理
Mat srcImage = imread("E://Program//OpenCV//vcworkspaces//ogr_test//images//txt.jpg"); //读取图片
Mat dstImage, grayImage, binImage;
srcImage.copyTo(dstImage); //将读取到的图片,深拷贝为dstImage
cvtColor(srcImage, grayImage, COLOR_BGR2GRAY); //转换灰度图
threshold(grayImage, binImage, 100, 255, cv::THRESH_BINARY_INV); //转换二值图,设置阈值,高于100认为255
//寻找轮廓
vector<vector<Point>> contours; //定义轮廓和层次结构
vector<Vec4i> hierarchy;
findContours(binImage, contours, hierarchy, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_NONE); //寻找轮廓
int i = 0;
vector<vector<Point>>::iterator It;
Rect a4rect[15]; //假设最多不会超过15个轮廓
for (It = contours_rec.begin(); It < contours_rec.end(); It++) { //画出包围数字的最小矩形
a4rect[i].x = (float)boundingRect(*It).tl().x;
a4rect[i].y = (float)boundingRect(*It).tl().y;
a4rect[i].width = (float)boundingRect(*It).br().x - (float)boundingRect(*It).tl().x;
a4rect[i].height = (float)boundingRect(*It).br().y - (float)boundingRect(*It).tl().y;
if ((a4rect[i].height > 80) && (a4rect[i].width > 50) && (a4rect[i].height < 300) && (a4rect[i].width < 300)) {
rectangle(dstImage, a4rect[i], Scalar(0, 0, 255), 2, 8, 0); //在原图像中用红框画出识别到的各轮廓
rectangle(binImage, a4rect[i], Scalar(0, 0, 0), 0, 8, 0);
i++;
}
}
imshow("dstImage", dstImage);
//将图像轮廓逐一与模板匹配
Mat num[15];
int matchingNum = 0; //匹配到的数字
int matchingRate = 0; //相似率
for (int j = 0; j < i; j++) {
a4binImg(a4rect[j]).copyTo(num[j]); //提取包围数字的矩形区域至num[j]
imgMatch(num[j], matchingRate, matchingNum); //数字匹配
if (matchingRate < 400000) {
cout << "识别数字:" << matchingNum << "\t匹配率:" << matchingRate << endl;
//imwrite(to_string(matchingNum) + ".jpg", num[j]);
}
}
system("pause");
return 0;
}
两图像相减之前,需要先制作一张模板,你可以自己在记事本里敲0-9的数字,截图,使用上面的函数imwrite出来一份模板。也可以到我的github中下载,其中0.jpg-9.jpg就是模板文件。

//获取所有像素点和,用于求两图像相减后所得图像的所有像素之和
int getPixelSum(Mat& image){
int a = 0;
for (int row = 0; row < image.rows; row++) {
uchar* current_pixel = image.ptr<uchar>(row);
for (int col = 0; col < image.cols; col++) {
a += *current_pixel++; //指针遍历像素点反转颜色
}
}
return a;
}
//模板匹配函数,两图像做差
int imgMatch(Mat& image, int& rate, int& num) {
Mat imgSub;
double min = 10e6;
num = 0;
rate = 0;
for (int i = 0; i < 10; i++) {
Mat templatimg = imread("E:/Program/OpenCV/vcworkspaces/OGR/images/" + std::to_string(i) + ".jpg", IMREAD_GRAYSCALE);
resize(image, image, Size(32, 48), 0, 0, cv::INTER_LINEAR); //将两图像大小调至相同
resize(templatimg, templatimg, Size(32, 48), 0, 0, cv::INTER_LINEAR);
absdiff(templatimg, image, imgSub);
rate = getPixelSum(imgSub);
if (rate < min) {
min = rate;
num = i;
}
}
return num;
}
1.2 行列扫描法
此方法主要参考opencv 数字识别详细教程这篇文章,在此感谢LTG01大佬的无私分享。
基本过程为:
- 将图像二值化处理,使数字部分为白色,其余部分为黑色。
- 对一个图像先逐行扫描求和,如果第一行像素和为0,则继续向下扫描,直到碰到像素和不为0的行,将行数记下来,此为数字的顶部。
- 继续向下扫描,此时会从上到下逐渐扫描数字所在的每一行,当行像素和再次为0时,再将行数记录下来,代表已经到了数字的底部,将顶部与底部之间的区域截取出来。
- ,对截取出来的图像进行逐列扫描求和,过程同上,记录出数字的左右列号,根据左右列号即可从刚才截取出的图像中,取出包含数字的最小图像。
- 利用此最小图像与模板匹配。

int main()
{
//读取图像并进行二值化处理
Mat src = imread("E:/Program/OpenCV/vcworkspaces/ogr_test/images/txt.jpg",IMREAD_GRAYSCALE);
Mat grayImage; //定义Mat对象用于存储每一帧数据
threshold(src, grayImage, 100, 255, THRESH_BINARY_INV); //转换二值图,设置阈值,高于50认为255
imshow("grayimg", grayImage);
//进行行列扫描
Mat leftImg, rightImg, topImg, bottomImg;
int topRes = cutTop(grayImage, topImg, bottomImg); //对二值图像逐行扫描,获得行像素之和>0的部分topImg,以及剩余部分bottomImg
int matchNum = -1, matchRate = 10e6;
while (topRes == 0) //当仍存在行像素和>0的部分时
{
int leftRes = cutLeft(topImg, leftImg, rightImg); //对行像素之和>0的部分topImg逐列扫描,获得列像素之和>0的部分leftImg,以及剩余部分rightImg
while (leftRes == 0) {
imgMatch(leftImg, matchNum, matchRate); //数字识别
//getSubtract(topImg);
imshow("num", leftImg);
if (matchRate < 300000) {
cout << "识别数字:" << matchNum << "\t\t匹配度:" << matchRate << endl;
//imwrite(to_string(matchingNum) + ".jpg", num[j]);
}
Mat srcTmp = rightImg.clone();
leftRes = cutLeft(srcTmp, leftImg, rightImg); //对剩余部分rightImg继续逐列扫描
}
Mat srcTmp = bottomImg.clone();
topRes = cutTop(srcTmp, topImg, bottomImg); //对剩余部分bottomImg继续逐行扫描
}
waitKey(0);
destroyAllWindows();;
return 0;
}
有关扫描法识别数字的完整代码见我的Github的scan分支。
二、提取图像中的ROI区域
提取ROI区域的步骤如下:
- 读取摄像头每一帧图像
- 对图像进行二值化处理
- 对图像进行形态学处理
- 设置限制条件寻找目标区域,并框选(这一步是重点)
2.1 读取摄像头图像
摄像头的读取原理在之前的文章中已有介绍《摄像头视频的读取与存储》。主要使用函数为 capture.read(),此函数用于捕获视频的每一帧,并返回刚刚捕获的帧。示例程序如下:
int main()
{
VideoCapture capture(0); //创建VideoCapture类,打开电脑默认摄像头传参0,如果有外置摄像头参数为1
int frame_width = capture.get(CAP_PROP_FRAME_WIDTH); //获取摄像头的宽、高、帧数、FPS
int frame_height = capture.get(CAP_PROP_FRAME_HEIGHT);
Mat frame; //定义Mat对象用于存储每一帧数据
while (capture.isOpened()) {
capture.read(frame); //逐帧读取视频
//flip(frame, frame, 1); //将读取的视频左右反转
if (frame.empty()) { //如果视频结束或未检测到摄像头则跳出循环
break;
}
imshow("Video", frame); //每次循环显示一帧图像,frame就是每帧图像
char k = waitKey(333); //两帧读取的间隔时间
if (k == 'q') { //按下q键退出循环
break;
}
}
capture.release(); //释放视频
system("pause");
return 0;
}

2.2 对图像进行二值化处理
通过每个像素的颜色分量将图片进行二值化。正常曝光情况下A4纸的BGR均为215左右,车牌的颜色信息大约为B=138,G=63,R=23。但是在不同环境下颜色信息可能会有偏差,因此需要将条件在一定程度上放宽,再通过其他一些条件来准确查找目标区域。
//图像二值化
void binaryProc(Mat& image) {
unsigned char pixelB, pixelG, pixelR; //记录各通道值
unsigned char DifMax = 40; //基于颜色区分的阈值设置
unsigned char WhiteMax = 50; //判断白色
unsigned char B = 215, G = 215, R = 215; //各通道的阈值设定,针对与A4纸
int i = 0, j = 0;
for (i = 0; i < image.rows; i++) //通过颜色分量将图片进行二值化处理
{
for (j = 0; j < image.cols; j++)
{
pixelB = image.at<Vec3b>(i, j)[0]; //获取图片各个通道的值
pixelG = image.at<Vec3b>(i, j)[1];
pixelR = image.at<Vec3b>(i, j)[2];
if ((abs(B - pixelB) < DifMax) && (abs(G - pixelG) < DifMax) && (abs(R - pixelR) < DifMax) && abs(pixelB - pixelG) < WhiteMax && abs(pixelG - pixelR) < WhiteMax && abs(pixelB - pixelR) < WhiteMax)
{ //将各个通道的值和各个通道阈值进行比较
image.at<Vec3b>(i, j)[0] = 255; //符合颜色阈值范围内的设置成白色
image.at<Vec3b>(i, j)[1] = 255;
image.at<Vec3b>(i, j)[2] = 255;
}
else
{
image.at<Vec3b>(i, j)[0] = 0; //不符合颜色阈值范围内的设置为黑色
image.at<Vec3b>(i, j)[1] = 0;
image.at<Vec3b>(i, j)[2] = 0;
}
}
}
}

2.3 形态学处理
可以看出二值画处理后已经比较明显完整的显示出A4纸区域,但是仍然存在一些噪点,此时进行形态学处理,以消除这些噪点干扰。对图像先膨胀再腐蚀,可以填充细小空间,连接临近物体和平滑边界。
//形态学处理
void morphTreat(Mat& binImg) {
Mat BinOriImg; //形态学处理结果图像
Mat element = getStructuringElement(MORPH_RECT, Size(5, 5)); //设置形态学处理窗的大小
GaussianBlur(binImg, binImg, Size(5, 5), 11, 11);
dilate(binImg, binImg, element); //进行多次膨胀操作
dilate(binImg, binImg, element);
dilate(binImg, binImg, element);
dilate(binImg, binImg, element);
dilate(binImg, binImg, element);
erode(binImg, binImg, element); //进行多次腐蚀操作
erode(binImg, binImg, element);
erode(binImg, binImg, element);
erode(binImg, binImg, element);
erode(binImg, binImg, element);
//imshow("形态学处理后", BinOriImg); //显示形态学处理之后的图像
cvtColor(binImg, binImg, CV_BGR2GRAY); //将形态学处理之后的图像转化为灰度图像
threshold(binImg, binImg, 100, 255, THRESH_BINARY); //灰度图像二值化
}
矩形窗的大小与膨胀腐蚀的次数会影响处理结果,处理完的结果大致如下。

2.4 设置限制条件寻找目标区域
经过形态学处理,图像中已经可以明显看到A4纸所在的区域,但是图像中仍然不可避免存在其他与A4纸颜色接近的物体,在这里也会显示为白色。这时就需要我们根据A4纸区域的特点设置限制条件,从这些白色区域中找到代表A4纸所在的区域。
在这里我使用的限制条件主要有以下几个:
- 矩形面积在一定范围内
- 长宽比A4纸为1.414,一定程度放宽后作为限制条件
- 短边长度在一定范围内
首先寻找图像中的轮廓,利用轮廓面积初步判断,对轮廓面积符合条件的进一步获取其外接矩形。计算此矩形的各个参数(顶点坐标、长宽、面积、倾斜角度等),然后根据限制条件对此矩形进行判别。
如果矩形区域符合条件,那么就需要将其截取出来,并根据先前计算的倾斜角度将A4纸图像摆正,便于后续对其中的数字进行识别。旋转图像的函数需要一些数学知识,旋转前后的图像的长宽有一定函数关系。(h’、w’为旋转后图像高、宽)


//图像旋转
void rotateProc(Mat& image, double angle) {
Mat M;
int h = image.rows;
int w = image.cols;
M = getRotationMatrix2D(Point2f(w / 2, h / 2), angle, 1.0); //定义变换矩阵M
double cos = abs(M.at<double>(0, 0)); //求cos值
double sin = abs(M.at<double>(0, 1)); //求sin值
int nw = abs(cos * w - sin * h) / abs(cos * cos - sin * sin); //计算新的长、宽
int nh = abs(cos * h - sin * w) / abs(cos * cos - sin * sin);
M.at<double>(0, 2) += (nw / 2 - w / 2); //计算新的中心
M.at<double>(1, 2) += (nh / 2 - h / 2);
warpAffine(image, image, M, Size(nw, nh), INTER_LINEAR, 0, Scalar(0, 0, 0));
//imshow("Rotation", dst);
}
/************************** 提取A4纸区域并识别数字 *****************************/
double length, area, rectArea; //定义轮廓周长、面积、外界矩形面积
double long2Short = 0.0; //长边/短边
Rect rect; //外界矩形
RotatedRect box; //外接矩形
CvPoint2D32f pt[4]; //矩形定点变量
Mat pts; //矩形定点变量
double axisLong = 0.0, axisShort = 0.0;//矩形的长边和短边
double Length; //中间变量
float angle = 0; //记录倾斜角度
double location_x = 0.0;
double location_y = 0.0;
vector<vector<Point>> contours;
vector<Vec4i>hierarchy;
findContours(binImg, contours, hierarchy, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE);
for (int i = 0; i < contours.size(); i++)
{
//绘制轮廓的最小外接矩形
length = arcLength(contours[i], true); //获取轮廓周长
area = contourArea(contours[i]); //获取轮廓面积
if (area > 2000 && area < 300000) //矩形区域面积大小判断,符合条件的继续
{
rect = boundingRect(contours[i]); //计算矩形边界
box = minAreaRect(contours[i]); //获取轮廓的矩形
boxPoints(box, pts); //获取矩形四个顶点坐标(左上,右上,右下,左下)
for (int row = 0; row < pts.rows; row++) { //从列表中依次读出四个顶点坐标
pt[row].x = pts.at<uchar>(row, 0);
pt[row].y = pts.at<uchar>(row, 1);
}
angle = box.angle; //得到倾斜角度
if (angle > 45) { //对于逆时针偏转的情况,倾斜角度为-(90-angle)
angle = angle - 90;
}
axisLong = sqrt(pow(pt[1].x - pt[0].x, 2) + pow(pt[1].y - pt[0].y, 2)); //计算长轴(勾股定理)
axisShort = sqrt(pow(pt[2].x - pt[1].x, 2) + pow(pt[2].y - pt[1].y, 2)); //计算短轴(勾股定理)
if (axisShort > axisLong) //如果短轴大于长轴,交换数据
{
Length = axisLong;
axisLong = axisShort;
axisShort = Length;
}
rectArea = axisLong * axisShort; //计算矩形的实际面积
long2Short = axisLong / axisShort; //计算长宽比
// 长宽比A4纸为1.414,利用长宽比、矩形面积和短边长度作为限制条件
if (long2Short > 1 && long2Short < 1.8 && rectArea > 5000 && rectArea < 300000 && axisShort > 50)
{
rectangle(frame, rect, Scalar(0, 0, 255), 2, 8, 0); //在摄像头图像中画出矩形区域
if (rect.width > 100 && rect.height > 100 && axisShort>100) { //缩小矩形范围,便于数字识别
rect.x += 40;
rect.y += 40;
rect.width -= 40;
rect.height -= 40;
}
imshow("Video", frame); //显示摄像头拍摄画面
location_x = rect.x + rect.width / 2; //获得矩形中心坐标,即A4纸中心坐标
location_y = rect.y + rect.height / 2;
Mat a4Img = frame(rect); //提取A4纸区域
Mat a4binImg;
cvtColor(a4Img, a4binImg, CV_BGR2GRAY); //将A4纸区域转化为灰度图像
threshold(a4binImg, a4binImg, 120, 255, THRESH_BINARY); //灰度图像二值化
colorReverse(a4binImg); //颜色反转
rotateProc(a4binImg, angle); //根据前所计算角度,对图像进行旋转,保证数字水平存在
imshow("A4", a4binImg);
/******************* 数字识别方法 ********************/
//所获得的a4binImg就是经过二值化处理后的A4纸区域
//使用上面介绍的数字识别方法即可级别
/*****************************************************/
}
}
}



分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐


 33
33 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)