
Comake D1 开发板 开源算法 MobileSAM 万物分割算法 实战
MobileSAM是一种针对移动设备优化的轻量级图像万物分割模型, 能够实现对任意物体的识别与分割。它是在SAM(Segment Anything Model)基础上进行优化的, 旨在保持高质量分割结果的同时, 降低计算复杂度和内存占用, 以便在资源受限的移动设备上能够高效运行
MobileSAM
1 概述¶
1.1 背景介绍¶
MobileSAM是一种针对移动设备优化的轻量级图像万物分割模型, 能够实现对任意物体的识别与分割。它是在SAM(Segment Anything Model)基础上进行优化的, 旨在保持高质量分割结果的同时, 降低计算复杂度和内存占用, 以便在资源受限的移动设备上能够高效运行。
该模型的整体性能情况如下所示:
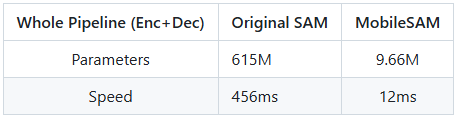
详情可参考MobileSAM官方说明:
https://github.com/ChaoningZhang/MobileSAM
MobileSAM开源模型的下载地址如下:
https://github.com/ChaoningZhang/MobileSAM/blob/master/weights/mobile_sam.pt
1.2 使用说明¶
Linux SDK-alkaid中默认带了已经预先转换好的离线模型及板端示例, 相关文件路径如下:
-
板端示例程序路径
Linux_SDK/sdk/verify/opendla/source/vlm/mobilesam -
板端离线模型路径
Linux_SDK/project/board/${chip}/dla_file/ipu_open_models/vlm/mobilesam_sim.img -
板端测试图像路径
Linux_SDK/sdk/verify/opendla/source/resource/bus.jpg
如果用户不需要转换模型可直接跳转至第3章节。
2 模型转换¶
2.1 onnx模型转换¶
-
python环境搭建
$conda create -n mobilesam python==3.10 $conda activate mobilesam $git clone git@github.com:ChaoningZhang/MobileSAM.git $cd MobileSAM $pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple注意:这里提供的python环境搭建, 仅作为参考示例, 具体搭建过程请参考官方源码运行教程:
https://github.com/ChaoningZhang/MobileSAM/blob/master/README.md -
模型测试
-
编写模型测试脚本
scripts/predict.pyfrom mobile_sam import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor model_type = "vit_t" sam_checkpoint = "./weights/mobile_sam.pt" device = "cuda" if torch.cuda.is_available() else "cpu" mobile_sam = sam_model_registry[model_type](checkpoint=sam_checkpoint) mobile_sam.to(device=device) mobile_sam.eval() predictor = SamPredictor(mobile_sam) predictor.set_image(<your_image>) masks, _, _ = predictor.predict(<input_prompts>) -
运行模型测试脚本, 确保mobilesam环境配置正确。
$python ./scripts/predict.py
-
-
模型导出
-
修改模型脚本
- 在mobile_sam/utils/onnx.py中第108行处修改onnx模型输入
@torch.no_grad() def forward( self, images: torch.Tensor, point_coords: torch.Tensor): point_labels = torch.tensor([1]).unsqueeze(0) embed_dim = self.model.prompt_encoder.embed_dim embed_size = self.model.prompt_encoder.image_embedding_size mask_input_size = [4 * x for x in embed_size] mask_input = torch.zeros(1, 1, *mask_input_size) has_mask_input = torch.tensor([1]) # get img embedding features = self.model.image_encoder(images) sparse_embedding = self._embed_points(point_coords, point_labels) dense_embedding = self._embed_masks(mask_input, has_mask_input) masks, scores = self.model.mask_decoder.predict_masks( image_embeddings=features, image_pe=self.model.prompt_encoder.get_dense_pe(), sparse_prompt_embeddings=sparse_embedding, dense_prompt_embeddings=dense_embedding, ) if self.use_stability_score: scores = calculate_stability_score( masks, self.model.mask_threshold, self.stability_score_offset ) if self.return_single_mask: masks, scores = self.select_masks(masks, scores, point_coords.shape[1]) return masks, scores
- 在mobile_sam/utils/onnx.py中第108行处修改onnx模型输入
-
编写模型转换脚本
scripts/export.py:import os,sys sys.path.append(os.getcwd()) import torch from torch.nn import functional as F from torchvision.transforms.functional import resize, to_pil_image from mobile_sam import sam_model_registry from mobile_sam.utils.onnx import SamOnnxModel from mobile_sam import sam_model_registry, SamPredictor import argparse import warnings import cv2 import numpy as np import matplotlib.pyplot as plt from typing import Tuple,Optional import onnx import onnxsim try: import onnxruntime # type: ignore onnxruntime_exists = True except ImportError: onnxruntime_exists = False parser = argparse.ArgumentParser( description="Export the SAM prompt encoder and mask decoder to an ONNX model." ) parser.add_argument( "--checkpoint", type=str, required=True, help="The path to the SAM model checkpoint." ) parser.add_argument( "--output", type=str, required=True, help="The filename to save the ONNX model to." ) parser.add_argument( "--model-type", type=str, required=True, help="In ['default', 'vit_h', 'vit_l', 'vit_b']. Which type of SAM model to export.", ) parser.add_argument( "--return-single-mask", action="store_true", help=( "If true, the exported ONNX model will only return the best mask, " "instead of returning multiple masks. For high resolution images " "this can improve runtime when upscaling masks is expensive." ), ) parser.add_argument( "--opset", type=int, default=16, help="The ONNX opset version to use. Must be >=11", ) parser.add_argument( "--quantize-out", type=str, default=None, help=( "If set, will quantize the model and save it with this name. " "Quantization is performed with quantize_dynamic from onnxruntime.quantization.quantize." ), ) parser.add_argument( "--gelu-approximate", action="store_true", help=( "Replace GELU operations with approximations using tanh. Useful " "for some runtimes that have slow or unimplemented erf ops, used in GELU." ), ) parser.add_argument( "--use-stability-score", action="store_true", help=( "Replaces the model's predicted mask quality score with the stability " "score calculated on the low resolution masks using an offset of 1.0. " ), ) parser.add_argument( "--return-extra-metrics", action="store_true", help=( "The model will return five results: (masks, scores, stability_scores, " "areas, low_res_logits) instead of the usual three. This can be " "significantly slower for high resolution outputs." ), ) def run_export( model_type: str, checkpoint: str, output: str, opset: int, return_single_mask: bool, gelu_approximate: bool = False, use_stability_score: bool = False, return_extra_metrics=False, ): print("Loading model...") sam = sam_model_registry[model_type](checkpoint=checkpoint) onnx_model = SamOnnxModel( model=sam, return_single_mask=return_single_mask, use_stability_score=use_stability_score, return_extra_metrics=return_extra_metrics, ) if gelu_approximate: for n, m in onnx_model.named_modules(): if isinstance(m, torch.nn.GELU): m.approximate = "tanh" embed_dim = sam.prompt_encoder.embed_dim embed_size = sam.prompt_encoder.image_embedding_size mask_input_size = [4 * x for x in embed_size] dummy_inputs = { "images": torch.randn(1, 3, 1024, 1024, dtype=torch.float), "point_coords": torch.randint(low=0, high=1024, size=(1, 1, 2), dtype=torch.int), } _ = onnx_model(**dummy_inputs) output_names = ["masks", "scores"] with warnings.catch_warnings(): warnings.filterwarnings("ignore", category=torch.jit.TracerWarning) warnings.filterwarnings("ignore", category=UserWarning) with open(output, "wb") as f: print(f"Exporting onnx model to {output}...") torch.onnx.export( onnx_model, tuple(dummy_inputs.values()), f, export_params=True, verbose=False, opset_version=opset, do_constant_folding=True, input_names=list(dummy_inputs.keys()), output_names=output_names, ) new_name = "./weights/mobilesam_sim.onnx" model_onnx = onnx.load(f.name) # load onnx model onnx.checker.check_model(model_onnx) # check onnx model model_onnx, check = onnxsim.simplify(model_onnx) onnx.save(model_onnx, new_name) if onnxruntime_exists: ort_inputs = {k: to_numpy(v) for k, v in dummy_inputs.items()} # set cpu provider default providers = ["CPUExecutionProvider"] ort_session = onnxruntime.InferenceSession(output, providers=providers) _ = ort_session.run(None, ort_inputs) print("Model has successfully been run with ONNXRuntime.") def to_numpy(tensor): return tensor.cpu().numpy() if __name__ == "__main__": args = parser.parse_args() run_export( model_type=args.model_type, checkpoint=args.checkpoint, output=args.output, opset=args.opset, return_single_mask=args.return_single_mask, gelu_approximate=args.gelu_approximate, use_stability_score=args.use_stability_score, return_extra_metrics=args.return_extra_metrics, ) # Using an ONNX model ort_session = onnxruntime.InferenceSession(args.output) checkpoint = "./weights/mobile_sam.pt" model_type = "vit_t" image = cv2.imread('./images/picture1.jpg') image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) target_size = (1024, 1024) input_image = np.array(resize(to_pil_image(image), target_size)) input_image_torch = torch.as_tensor(input_image) input_image_torch = input_image_torch.permute(2, 0, 1).contiguous()[None, :, :, :] input_image_torch = np.array(preprocess(input_image_torch)) sam = sam_model_registry[model_type](checkpoint=checkpoint) sam.to(device='cpu') predictor = SamPredictor(sam) predictor.set_image(image) image_embedding = predictor.get_image_embedding().cpu().numpy() input_point = np.array([[400, 400]]) input_label = np.array([1]) # Add a batch index, concatenate a padding point, and transform. # onnx_coord = np.concatenate([input_point, np.array([[0.0, 0.0]])], axis=0)[None, :, :] # onnx_label = np.concatenate([input_label, np.array([-1])], axis=0)[None, :].astype(np.float32) onnx_coord = input_point[None, :, :] # onnx_label = input_label[None, :].astype(np.float32) onnx_coord = predictor.transform.apply_coords(onnx_coord, image.shape[:2]).astype(np.int32) # Create an empty mask input and an indicator for no mask. # onnx_mask_input = np.zeros((1, 1, 256, 256), dtype=np.float32) # onnx_has_mask_input = np.zeros(1, dtype=np.float32) orig_im_size = np.array(image.shape[:2], dtype=np.float32) # Package the inputs to run in the onnx model ort_inputs = { "images": input_image_torch, "point_coords": onnx_coord, } # Predict a mask and threshold it. masks, scores = ort_session.run(None, ort_inputs) print("masks", mask) print("scores", scores) masks = mask_postprocessing(torch.tensor(masks), torch.tensor(orig_im_size)) masks = masks > predictor.model.mask_threshold index = np.argmax(scores) masks = masks[0][index] cv2.imwrite('./mask.png', (np.array(masks).astype(np.int32)*255).reshape(770,769,-1)*np.random.random(3).reshape(1,1,-1)) -
运行模型转换脚本, 会在
weights目录下生成mobilesam_sim模型$python ./scripts/export.py \ --checkpoint ./weights/mobile_sam.pt \ --model-type vit_t \ --output ./weights/mobile_sam.onnx
-
2.2 离线模型转换¶
2.2.1 预&后处理说明¶
-
预处理
转换成功的mobile_sam.onnx模型输入信息如下图所示, 要求输入图像的尺寸为 (1, 3, 1024, 1024), 此外需要将像素值归一化到 [0, 1] 范围内。
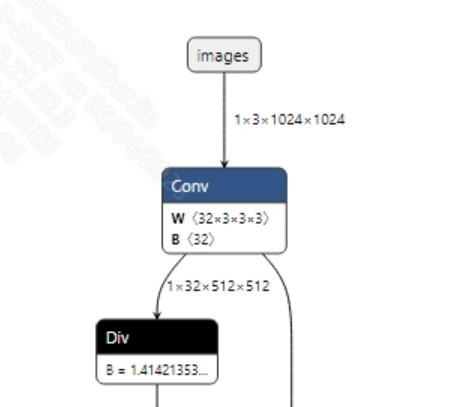
-
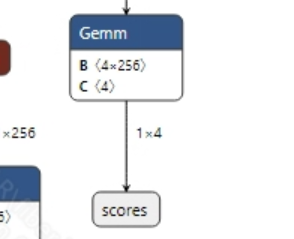
后处理
mobile_sam.onnx模型的输出信息如下图所示, 该模型有两个输出
masks和scores, 维度分别是(1, 4, 256, 256)和(1, 4)。获取到模型输出后, 需要先对scores进行处理, 筛选出scores中概率最大的索引值, 然后再传给masks进行分割掩码生成。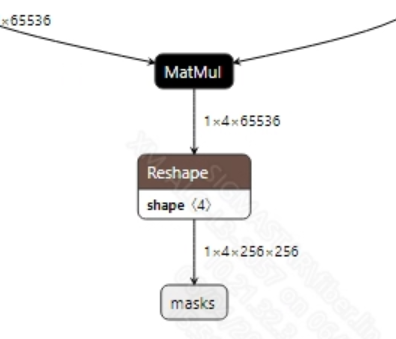
2.2.2 offline模型转换流程¶
注意:1)OpenDLAModel对应的是压缩包image-dev_model_convert.tar解压之后的smodel文件。2)转换命令需要在docker环境下运行, 请先根据Docker开发环境教程, 加载SGS Docker环境。
-
拷贝onnx模型到转换代码目录
$cp ./weights/mobile_sam.onnx OpenDLAModel/vlm/mobilesam/onnx -
转换命令
$cd IPU_SDK_Release/docker $bash run_docker.sh #进入到docker环境下的OpenDLAModel目录 $cd /work/SGS_XXX/OpenDLAModel $bash convert.sh -a vlm/mobilesam -c config/vlm_mobilesam.cfg -p SGS_IPU_Toolchain(绝对路径) -s false -
最终生成的模型地址
output/${chip}_${时间}/mobilesam_sim.img output/${chip}_${时间}/mobilesam_sim_fixed.sim output/${chip}_${时间}/mobilesam_sim_float.sim
2.2.3 关键脚本参数解析¶
- input_config.ini
[INPUT_CONFIG]
inputs = images,point_coords; #onnx 输入节点名称, 如果有多个需以“,”隔开;
training_input_formats = RGB,RAWDATA_S16_NHWC; #模型训练时的输入格式, 通常都是RGB;
input_formats = BGRA,RAWDATA_S16_NHWC; #板端输入格式, 可以根据情况选择BGRA或者YUV_NV12;
quantizations = TRUE,TRUE; #打开输入量化, 不需要修改;
mean_red = 123.675; #均值, 跟模型预处理相关, 根据实际情况配置;
mean_green = 116.28; #均值, 跟模型预处理相关, 根据实际情况配置;
mean_blue = 103.53; #均值, 跟模型预处理相关, 根据实际情况配置;
std_value = 58.395:57.12:57.375; #方差, 跟模型预处理相关, 根据实际情况配置;
[OUTPUT_CONFIG]
outputs = masks,scores; #onnx 输出节点名称, 如果有多个需以“,”隔开;
dequantizations = TRUE,TRUE; #是否开启反量化, 根据实际需求填写, 建议为TRUE。设为False, 输出为int16; 设为True, 输出为float32
- vlm_mobilesam.cfg
[MOBILESAM]
CHIP_LIST=pcupid #平台名称, 必须和板端平台一致, 否则模型无法运行
Model_LIST=mobilesam_sim #输入onnx模型名称
INPUT_SIZE_LIST=0 #模型输入分辨率
INPUT_INI_LIST=input_config.ini #配置文件
CLASS_NUM_LIST=0 #填0即可
SAVE_NAME_LIST=mobilesam_sim.img #输出模型名称
QUANT_DATA_PATH=images_list.txt #量化图片路径
2.3 模型仿真¶
-
获取float/fixed/offline模型输出
$bash convert.sh -a vlm/mobilesam -c config/vlm_mobilesam.cfg -p SGS_IPU_Toolchain(绝对路径) -s true执行上述命令后, 会默认将
float模型的输出tensor保存到vlm/mobilesam/log/output路径下的txt文件中。此外, 在vlm/mobilesam/convert.sh脚本中也提供了fixed和offline的仿真示例, 用户在运行时可以通过打开注释代码块, 分别获取fixed和offline模型输出。 -
模型精度对比
在保证输入和上述模型相同的情况下, 进入2.1章节搭建好的环境, 直接运行
MobileSAM/scripts/export.py脚本即可获取pytorch模型对应节点的输出tensor, 进而和float、fixed、offline模型进行对比。此外需要特别注意的是, 原始模型的输出格式是
NCHW, 而float/fixed/offline模型输出的格式是NHWC。
3 板端部署¶
3.1 程序编译¶
示例程序编译之前需要先根据板子(nand/nor/emmc, ddr型号等)选择deconfig进行sdk整包编译, 具体可以参考alkaid sdk sigdoc《开发环境搭建》文档。
-
编译板端mobilesam示例。
$cd sdk/verify/opendla $make clean && make source/vlm/mobilesam -j8 -
最终生成的可执行文件地址
sdk/verify/opendla/out/${AARCH}/app/prog_vlm_mobilesam
3.2 运行文件¶
运行程序时, 需要先将以下几个文件拷贝到板端
- prog_vlm_mobilesam
- bus.jpg
- mobilesam_sim.img
3.3 运行说明¶
-
Usage:
./prog_vlm_mobilesam image model pointW pointH(执行文件使用命令) -
Required Input:
- image: 图像文件夹/单张图像路径
- model: 需要测试的offline模型路径
- pointW: 点在图像上的X坐标
- pointH: 点在图像上的Y坐标
-
Optional Input:
- threshold: 检测阈值(0.0~1.0, 默认为0.5)
-
Typical output:
./prog_vlm_mobilesam resource/bus.jpg models/mobilesam_sim.img 270 600 client [758] connected, module:ipu found 1 images! [0] processing resource/bus.jpg... fillbuffer processing... net input width: 1024, net input height: 1024 img model invoke time: 635.592000 ms postprocess time: 41.640000 ms out_image_path: ./output/752093/images/bus.png ------shutdown IPU0------ client [758] disconnected, module:ipu

4 立即开始
加入Comake开发者社区
主页地址: CoMake开发者社区
SDK下载: CoMake开发者社区
文档中心: CoMake开发者社区
马上购买 : 首页-Comake开发者社区商店
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)