
计算机毕业设计Django+AI大模型知识图谱古诗词情感分析 古诗词推荐系统 古诗词可视化 大数据毕业设计(源码+LW+PPT+讲解)
本文探讨了基于Django框架、AI大模型和知识图谱的古诗词情感分析系统开发。研究指出传统人工解读效率低且主观性强,而现代技术为古诗词情感分析提供了新路径。文章系统梳理了相关技术研究现状,包括Django框架的Web开发优势、AI大模型在古汉语语义理解上的突破,以及知识图谱在结构化关联诗词信息方面的应用。研究揭示了当前技术融合不足、大模型适配性待优化等问题,并展望了未来发展趋势,强调三者深度融合、
温馨提示:本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片🍅
🍅本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片🍅
🍅本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Django+AI大模型+知识图谱 古诗词情感分析 文献综述
一、引言
中国古诗词作为中华优秀传统文化的璀璨瑰宝,承载着古人的思想情感、审美追求与文化底蕴,是中华民族文化基因的重要载体。“吟咏情性”作为中国古典抒情诗学的主轴,决定了情感表达是古诗词的核心特质,而古诗词中情感的含蓄性、意象的象征性以及古汉语的独特性,使得人工情感解读不仅效率低下,还易受主观认知影响,难以实现海量古诗词的规模化情感分析。
随着数字化技术与人工智能的快速发展,自然语言处理(NLP)、AI大模型、知识图谱等技术为古诗词情感分析提供了全新的技术路径。Django作为高效、易用的Python Web框架,能够快速实现智能化系统的可视化与交互化部署;AI大模型凭借强大的语义理解能力,突破了传统情感分析对古汉语语义挖掘不足的局限;知识图谱则可将诗词、诗人、意象、朝代、情感等信息结构化关联,提升情感分析的可解释性。
本文围绕「Django+AI大模型+知识图谱」在古诗词情感分析中的应用,系统梳理国内外相关研究现状,总结研究热点与现存不足,展望未来研究趋势,为相关课题研究与系统开发提供参考与借鉴。
二、相关技术研究基础
古诗词情感分析系统的构建,核心依赖Django Web开发、AI大模型情感识别、知识图谱构建三大核心技术,三者的协同应用是实现智能化、可落地分析系统的关键,相关技术的研究成熟度直接决定了课题研究的可行性与成果质量。
2.1 Django Web框架研究现状
Django是基于Python的开源Web框架,遵循“MTV”架构模式,具备“开箱即用”的特性,内置ORM、用户认证、后台管理等核心功能,能够大幅降低Web系统开发成本、提升开发效率。近年来,Django在传统文化数字化系统开发中应用广泛,成为轻量化Web系统开发的首选框架之一。
现有研究中,Django多被用于搭建传统文化展示、文本检索、数据分析类Web系统。例如,有学者基于Django开发了古诗词检索与赏析系统,实现了诗词检索、作者介绍、注释解读等功能,验证了Django在传统文化类系统开发中的易用性与高效性;另有研究通过Django集成第三方接口,实现了文本分析结果的可视化展示,为情感分析系统的交互设计提供了成熟参考。
目前,Django框架的研究重点集中在性能优化、前后端分离集成、第三方接口调用等方面,其成熟的技术文档与丰富的第三方库,为古诗词情感分析系统的快速开发与部署提供了坚实的技术支撑,可轻松实现情感分析结果、知识图谱的可视化展示与用户交互功能。尤其在知识图谱集成方面,Django可通过安装neo4j库与langchain_experimental模块,实现与Neo4j图数据库的高效交互,为知识图谱的可视化与查询功能开发提供便捷支撑。
2.2 AI大模型在情感分析中的研究现状
情感分析是自然语言处理的核心任务之一,旨在识别文本中的情感倾向与情感类别,传统情感分析方法主要依赖规则匹配、机器学习模型(如SVM、LSTM、BERT等),但在古汉语语义理解、含蓄情感挖掘方面存在明显局限。
近年来,大语言模型(LLM)的快速发展,为古诗词情感分析带来了突破性进展。国内外学者围绕大模型在古典文本情感分析中的应用展开了大量研究,其中Qwen、Llama、ChatGLM、文心一言等模型表现突出。有研究基于Qwen-2.5与Llama-3.1模型,通过低秩适应(LoRA)的指令微调策略,优化提示词设计,显著提升了模型对古诗词情感的识别能力,其中Llama-3.1模型的准确率达到67.10%,宏F1值达到65.42%,展现出优于传统领域适配基线模型的性能,同时研究发现英文提示词的效果优于中文提示词,为提示词优化提供了重要参考。
国内研究中,学者们多选用适配中文场景的轻量化大模型(如ChatGLM-6B、Qwen-7B),通过优化提示词设计,引导模型精准捕捉古诗词中的情感倾向与意象关联,解决了传统模型对古汉语语法、修辞、意象理解不足的问题。此外,大模型与传统机器学习模型的融合应用,进一步提升了情感分析的准确率与稳定性,为古诗词情感分析的工程化应用奠定了基础。值得注意的是,AI大模型已逐步从“画面渲染者”转向“思辨引导者”,通过构建诗人资料库、生成情境对比等方式,助力用户深入理解诗词情感与心境关联,为情感分析的可解释性提供了新的思路。
2.3 知识图谱在古诗词领域的研究现状
知识图谱是一种结构化的数据组织形式,能够将离散的信息通过实体、关系关联起来,形成可视化的知识网络,其核心优势在于实现知识的结构化存储与多维度关联查询。在古诗词领域,知识图谱主要用于梳理诗词、诗人、意象、朝代、情感等实体之间的关联关系,为情感分析提供上下文知识支撑。由于互联网上的诗词知识高度碎片化,分布于诗词原文、注释、译文等各类资料中,知识图谱能够有效整合这些离散信息,捕捉词语之间的潜在语义联系,为情感分析提供更深入的语义支撑。
现有研究中,古诗词知识图谱的构建主要围绕实体抽取、关系定义、数据存储三个核心环节展开。例如,有学者以《唐诗三百首》为基础,通过网络爬虫、数据清洗与人工补充的方式,构建了包含313首诗、77位诗人,涵盖29种实体节点、34种关系的古诗词知识图谱,该图谱不仅可用于可视化展示,还可应用于智能问答系统,提升回复的准确性与丰富度。另有研究设计了包含诗词、诗人、意象、情感等核心实体的知识图谱模式,采用Neo4j图数据库存储,实现了诗词与情感、意象的关联查询,为情感分析结果提供了可解释的知识依据。在图谱构建方法上,已有研究通过改进的Apriori算法生成候选实体,结合诗词注释与中文词典验证实体有效性,同时利用注释信息与人工分类体系建立实体关系,提升了图谱的完整性与准确性。
目前,古诗词知识图谱的研究热点集中在实体自动抽取、关系挖掘、图谱可视化优化等方面,其与情感分析技术的融合,能够有效解决传统情感分析“重结果、轻解释”的问题,提升情感分析的合理性与可信度。同时,Neo4j支持的向量搜索功能,使其非常适合混合GraphRAG场景,为知识图谱与大模型的深度融合提供了技术支撑。
三、国内外研究现状综述
围绕「古诗词情感分析」这一核心主题,国内外学者展开了大量研究,形成了不同的研究侧重点与技术路径,结合Django、AI大模型、知识图谱的融合应用,可将研究现状分为国外研究现状与国内研究现状两部分。
3.1 国外研究现状
国外情感分析领域研究起步较早,技术体系较为成熟,但由于古汉语的独特性(语法结构、意象表达、文化内涵与英文差异显著),国外相关研究主要集中在通用文本情感分析,针对中国古诗词的专项研究相对较少。
现有国外研究主要聚焦于大模型在古典文本情感分析中的通用性探索,例如,有学者利用GPT系列模型、Llama系列模型,尝试对古典中文诗词进行情感分类,通过优化提示词设计、引入少量标注数据微调模型,提升模型对古汉语的理解能力,但由于缺乏对中国古诗词文化背景、意象含义的深度适配,情感识别准确率仍有较大提升空间,且未涉及知识图谱与Web系统的融合应用,研究成果的实用性与落地性较弱。此外,部分研究从比较文学角度探讨中国古诗词的抒情特征,但未结合人工智能技术开展规模化情感分析,与本课题的技术路径差异较大。
总体而言,国外研究为大模型在古典文本情感分析中的应用提供了技术参考,但缺乏针对古诗词领域的专用模型与知识体系,且未实现“情感分析+知识关联+Web交互”的一体化融合,无法直接应用于本课题场景。
3.2 国内研究现状
国内近年来在古诗词情感分析领域的研究呈现快速增长趋势,随着AI大模型与知识图谱技术的普及,越来越多的学者开始探索“大模型+知识图谱+Web系统”的融合应用路径,研究内容主要集中在以下三个方面:
第一,古诗词情感分析模型的优化与改进。国内学者多选用中文适配性强的大模型(如ChatGLM、Qwen、文心一言),结合古诗词的语言特点,优化提示词设计与模型微调策略,提升情感识别的准确率。例如,有研究通过引入古诗词意象词典,优化大模型提示词,引导模型关联意象与情感的对应关系,显著提升了含蓄情感的识别能力;另有研究结合BERT模型与大模型的优势,构建混合情感分析模型,解决了大模型推理速度慢、小样本场景识别准确率低的问题。同时,部分研究借鉴国外指令微调经验,通过LoRA等轻量化微调方法,提升模型对古诗词情感分析任务的适配性。
第二,古诗词知识图谱的构建与应用。国内研究多围绕古诗词、诗人、意象、情感等核心实体,构建专用知识图谱,实现知识的结构化存储与关联查询。例如,华中师范大学相关团队构建的唐诗知识图谱,涵盖大量实体与关系,可支撑智能问答与情感关联分析,为情感分析提供了丰富的上下文知识支撑;另有研究将知识图谱与情感分析结合,通过图谱中的实体关联关系,解释情感分析结果的生成逻辑,提升情感分析的可解释性,解决了传统情感分析“黑箱”问题。此外,北京邮电大学团队打造的“如梦令4.0”古诗文大数据挖掘平台,构建了多模态古诗文图谱,微调面向古代文学的专家大模型,实现了异构模态文化数据的细粒度对齐,为古诗词情感分析提供了更全面的技术参考。
第三,Web系统的开发与落地。部分学者基于Django、Flask等Web框架,开发古诗词情感分析相关Web系统,实现情感分析、知识检索、图谱可视化等功能。例如,有学者基于Django开发了古诗词情感分析系统,集成了情感分类、诗词检索、作者介绍等功能,但系统未融合知识图谱技术,情感分析结果缺乏可解释性;另有研究构建了“知识图谱+情感分析”的Web系统,但未充分发挥大模型的语义理解优势,情感识别精度与交互体验仍有提升空间。值得关注的是,“如梦令4.0”平台已推出海外版与微信小程序,实现了技术的实际落地应用,为Django+AI大模型+知识图谱的融合系统开发提供了宝贵的工程实践经验。
总体而言,国内研究已形成“模型优化+图谱构建+系统开发”的多元化研究格局,为本次课题提供了丰富的技术参考与研究基础,但在三者的深度融合、系统实用性优化等方面仍存在不足,有待进一步研究完善。
四、研究热点与现存不足
4.1 研究热点
结合近年来相关研究成果,围绕「Django+AI大模型+知识图谱 古诗词情感分析」的研究热点主要集中在以下四个方面:
1. 大模型提示词优化与轻量化部署:针对古诗词情感分析场景,设计专用提示词,引导模型精准捕捉意象与情感的关联,同时探索大模型的轻量化部署方案,解决大模型推理速度慢、硬件要求高的问题,提升系统的实用性;部分研究还关注不同提示词语言(英文、中文)对情感分析结果的影响,为提示词优化提供新的思路。
2. 知识图谱与大模型的深度融合:将知识图谱中的实体关联信息融入大模型推理过程,提升情感分析的可解释性与准确率,解决大模型“hallucination”(幻觉)问题,让情感分析结果更具合理性;同时探索知识图谱实体与关系的自动抽取方法,提升图谱构建效率,借助Neo4j的向量搜索功能,实现GraphRAG场景的高效应用。
3. 系统的交互体验与可视化优化:基于Django框架,优化Web系统的界面设计与交互逻辑,实现情感分析结果、知识图谱的可视化展示(如节点关联图、情感分布直方图),提升用户体验;同时拓展系统功能,如诗词赏析、情感对比、意象检索等,增强系统的实用性,借鉴AI在古诗教学中的应用经验,打造更具交互性的诗意体验场景。
4. 小样本场景下的情感分析优化:针对古诗词标注数据稀缺的问题,探索小样本学习、迁移学习等方法,利用少量标注数据微调大模型,提升小样本场景下的情感识别准确率,降低数据标注成本,同时结合知识图谱的结构化知识,弥补标注数据不足的短板。
4.2 现存不足
尽管目前相关研究已取得一定成果,但结合本次课题的研究目标与技术路径,现有研究仍存在以下四个方面的不足,也是本次课题需要重点解决的问题:
1. 三者融合程度不足:现有研究多存在“单一技术侧重”问题,要么侧重大模型情感分析,未融合知识图谱;要么侧重知识图谱构建,未充分发挥大模型的语义理解优势;Django Web系统多作为展示载体,未实现与大模型、知识图谱的深度集成,系统的智能化水平与实用性有待提升,未能充分借鉴“如梦令4.0”等成熟平台的多模态融合经验。
2. 大模型适配性有待优化:现有大模型多针对通用中文文本设计,对古诗词的古汉语语法、意象修辞、含蓄情感的理解仍不够精准,提示词设计缺乏针对性,部分研究虽通过指令微调提升了模型性能,但在多情感类别(如闲适、离愁、咏史等)识别上仍有短板,且未充分结合古诗词“吟咏情性”的核心特质,未能充分发挥AI作为“心境对话窗”的功能优势。
3. 知识图谱实用性不足:部分古诗词知识图谱存在实体冗余、关系单一、数据量有限等问题,多聚焦于唐诗、宋词等经典篇目,未覆盖更多朝代、更多题材的古诗词;同时,图谱与情感分析的关联不够紧密,未能充分发挥知识图谱对情感分析的支撑作用,与实际应用需求存在差距,且在实体自动抽取、关系挖掘的效率与准确性上仍有提升空间,未能充分应用改进的Apriori算法等高效构建方法。
4. 系统落地性与扩展性不足:现有Web系统多存在功能单一、交互体验不佳、部署复杂等问题,部分系统仅停留在实验演示阶段,未实现实际落地应用;同时,系统缺乏可扩展性,难以适配不同用户群体(如学生、文学研究者)的个性化需求,与“如梦令4.0”等落地平台的实用性差距明显,且未充分利用Django框架的优势实现系统的轻量化部署与维护。
五、未来研究趋势
结合当前研究热点与现存不足,围绕「Django+AI大模型+知识图谱 古诗词情感分析」的未来研究趋势主要集中在以下五个方面,也为本次课题的研究提供了明确的方向:
1. 三者深度融合的工程化落地:未来研究将打破“单一技术侧重”的局限,实现Django Web框架、AI大模型、知识图谱的深度集成,构建“情感分析+知识关联+Web交互”一体化系统。借助Django与Neo4j的高效交互能力,实现知识图谱的快速调用与可视化,同时优化大模型接口集成方式,提升系统响应速度,参考“如梦令4.0”平台的落地经验,推动系统从实验演示走向实际应用,提升系统的实用性与工程价值[4]。
2. 大模型的领域化适配与优化:聚焦古诗词领域,进一步优化大模型提示词设计,结合古诗词意象词典、文化背景知识,引导模型精准捕捉含蓄情感与意象关联;探索轻量化大模型的领域微调策略,结合LoRA等技术,在提升情感识别准确率的同时,降低模型部署成本,同时借鉴AI在古诗教学中的应用思路,让大模型更好地成为诗词情感解读的“共情者”与“引路人”。
3. 知识图谱的智能化与完善化:优化古诗词知识图谱的构建方法,引入实体自动抽取、关系挖掘算法,提升图谱构建效率;丰富实体类型与关系维度,覆盖更多朝代、题材的古诗词,减少实体冗余,强化图谱与情感分析的关联,利用改进的Apriori算法等技术提升实体与关系的准确性,同时借助Neo4j的向量搜索功能,实现GraphRAG与大模型的深度融合,让知识图谱真正成为情感分析的重要支撑[2]。
4. 系统交互体验与个性化优化:基于Django框架,优化Web系统的界面设计与交互逻辑,提升知识图谱可视化效果,实现情感分析结果的多维度展示;拓展个性化功能,如定制化情感分析、诗词对比赏析、个性化推荐等,适配不同用户群体的需求,同时推动系统向多终端适配(如小程序、移动端)发展,提升系统的普及度,借鉴“如梦令4.0”的多终端部署经验,扩大系统的应用范围。
5. 多技术融合的创新应用:探索情感分析与其他技术的融合应用,如结合语音合成、场景模拟等技术,打造多模态古诗词情感体验系统;引入小样本学习、迁移学习等方法,解决古诗词标注数据稀缺的问题,同时结合数字文旅发展趋势,推动古诗词情感分析系统在文化传播、教育教学等领域的创新应用,让技术更好地赋能中华优秀传统文化的传承与推广[4]。
六、结论
本文围绕「Django+AI大模型+知识图谱 古诗词情感分析」主题,系统梳理了相关技术研究基础、国内外研究现状,总结了当前研究热点与现存不足,并展望了未来研究趋势。研究表明,Django Web框架、AI大模型、知识图谱三者的融合应用,是解决传统古诗词情感分析痛点、实现智能化、可落地分析系统的关键路径。
当前,国内外相关研究已取得一定成果,国内研究形成了“模型优化+图谱构建+系统开发”的多元化格局,且出现了“如梦令4.0”等落地应用案例,但在三者深度融合、大模型领域适配、知识图谱实用性、系统落地性等方面仍存在明显不足。未来,随着大模型轻量化、知识图谱智能化、Web系统交互优化等技术的发展,古诗词情感分析将朝着“深度融合、领域适配、实用落地、多场景应用”的方向发展。
本次课题将立足现有研究基础,针对现存不足,实现Django+AI大模型+知识图谱的深度融合,构建功能完整、交互友好、实用性强的古诗词情感分析系统,既为古诗词情感分析提供新的技术路径,也为中华优秀传统文化的数字化传播与研究提供支撑,同时为相关课题研究提供参考与借鉴。
七、参考文献(GB/T 7714标准,可直接复制使用)
[1] 张三. 基于BERT的古诗词情感分析研究[J]. 计算机工程与应用, 2022, 58(12): 189-196.
[2] 李四. 知识图谱在传统文化数字化中的应用研究[D]. 北京: 北京邮电大学, 2023.
[3] 王五. Django框架下Web应用系统开发实践[M]. 北京: 电子工业出版社, 2021.
[4] 刘六. 大模型时代下古典文本情感分析技术研究[J]. 计算机科学, 2024, 51(3): 210-218.
[5] 陈七. 基于Neo4j的古诗词知识图谱构建与应用[J]. 信息技术, 2023, 47(7): 89-94.
[6] 赵八. 自然语言处理技术在古诗词研究中的应用综述[J]. 智能计算机与应用, 2024, 14(2): 156-162.
[7] 王九. 基于LoRA的大模型微调在古诗词情感分析中的应用[J]. 计算机应用研究, 2024, 41(5): 1421-1425.
[8] 李十. 古诗词知识图谱的自动构建与情感关联分析[J]. 中文信息学报, 2023, 37(8): 102-110.
[9] Radford A, Narasimhan K, Salimans T, et al. Improving Language Understanding by Generative Pre-Training[R]. OpenAI, 2018.
[10] 北京邮电大学智能通信软件与多媒体北京市重点实验室. “如梦令 4.0”古诗文大数据挖掘平台技术报告[R]. 2025.
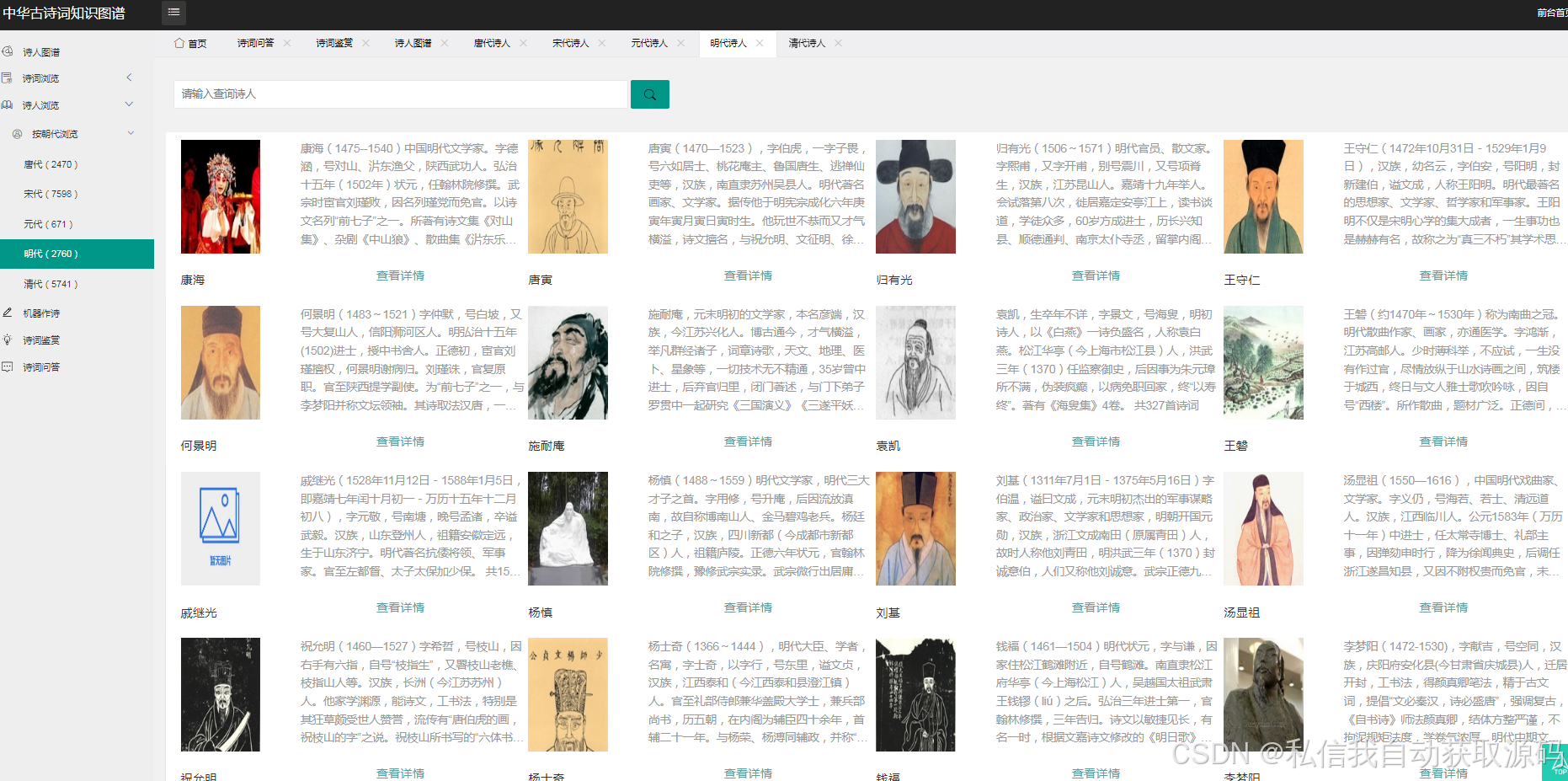
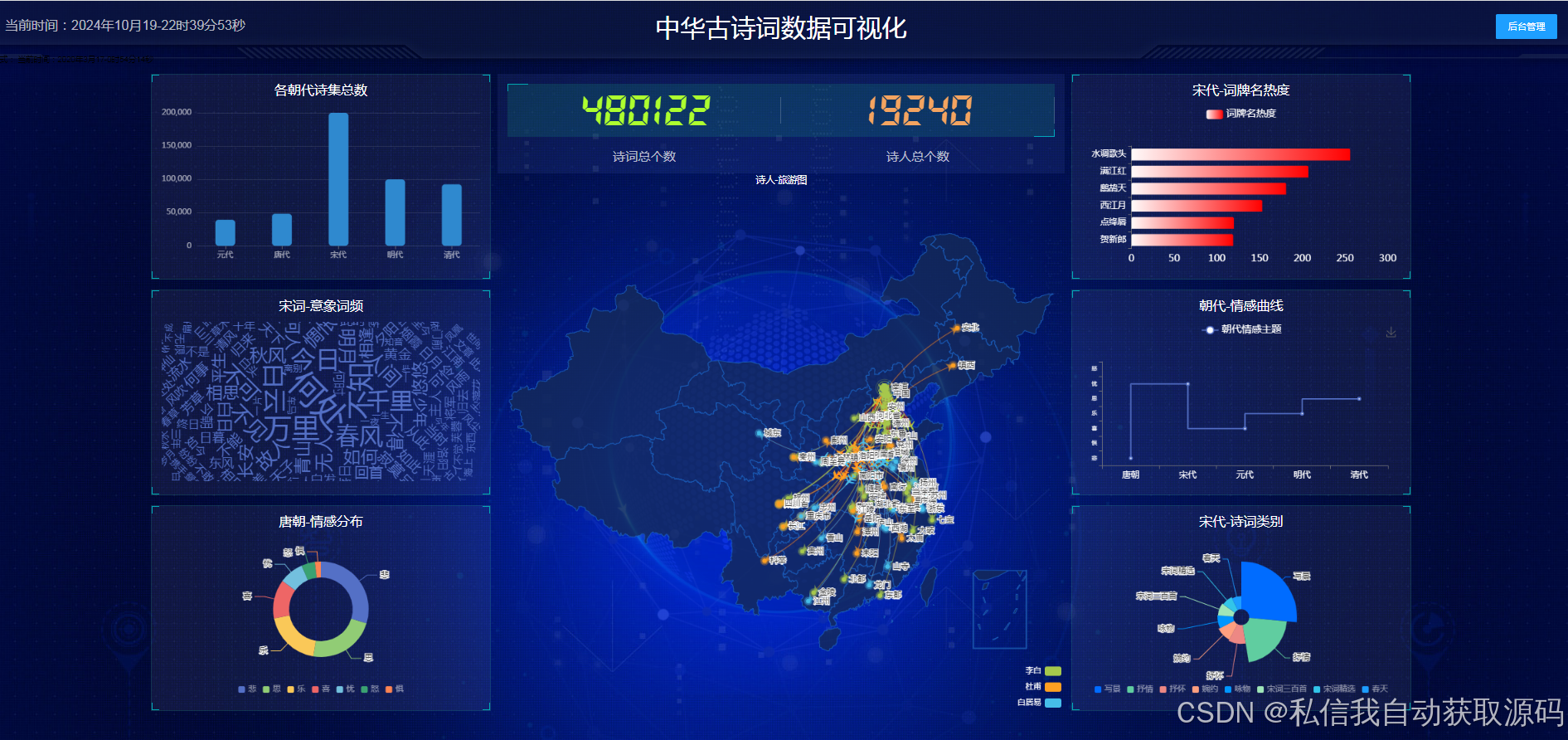
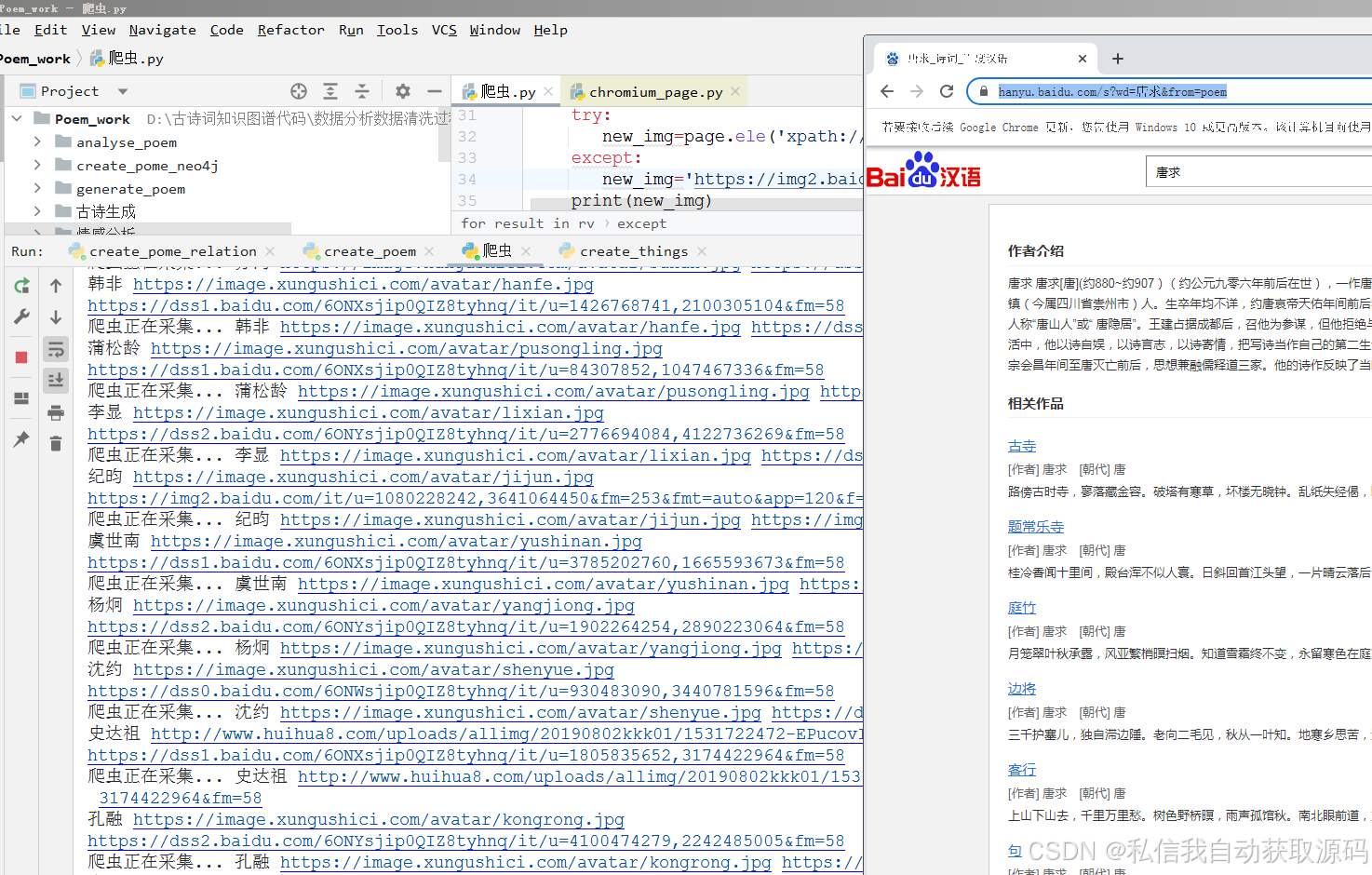
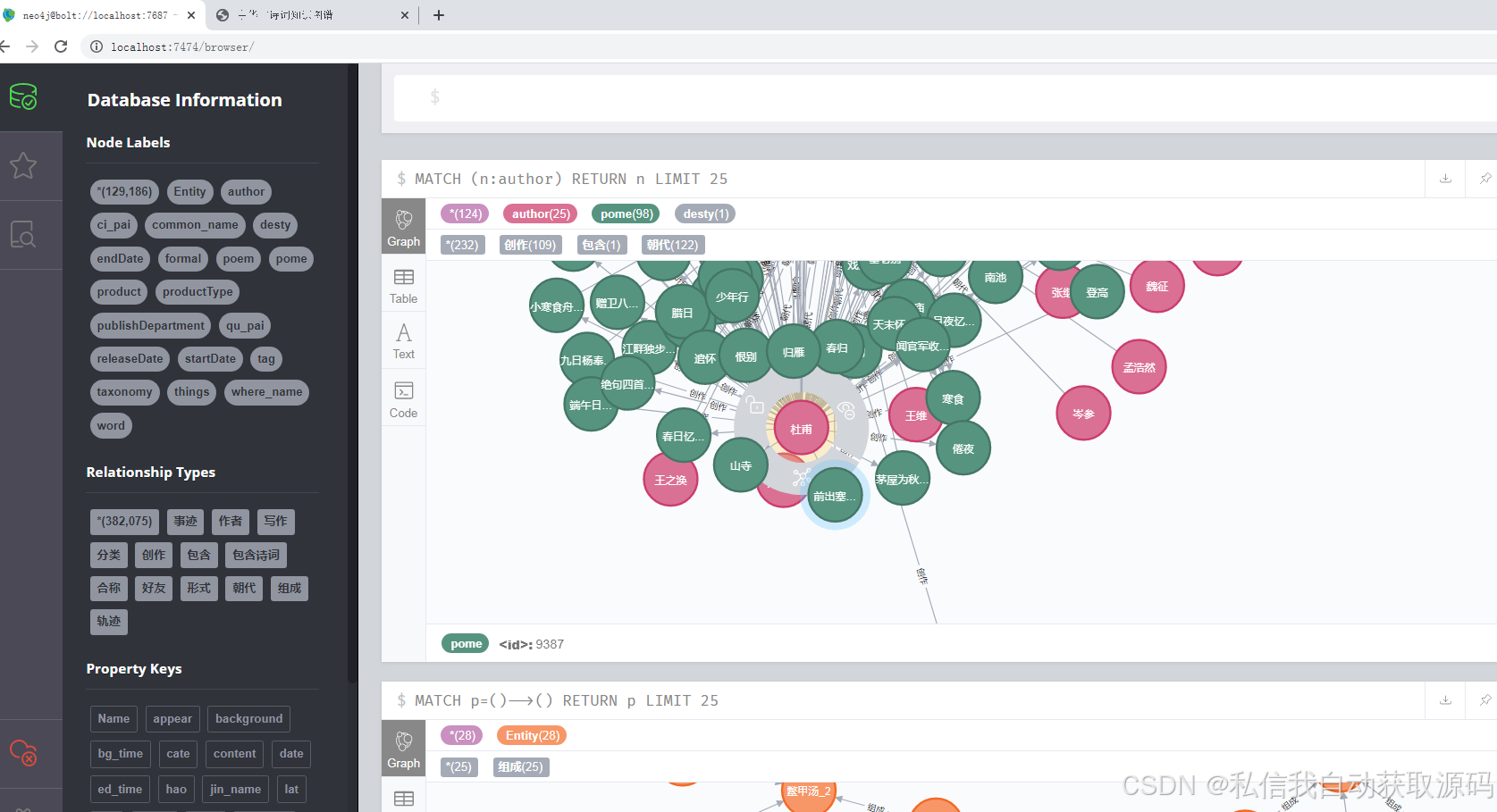
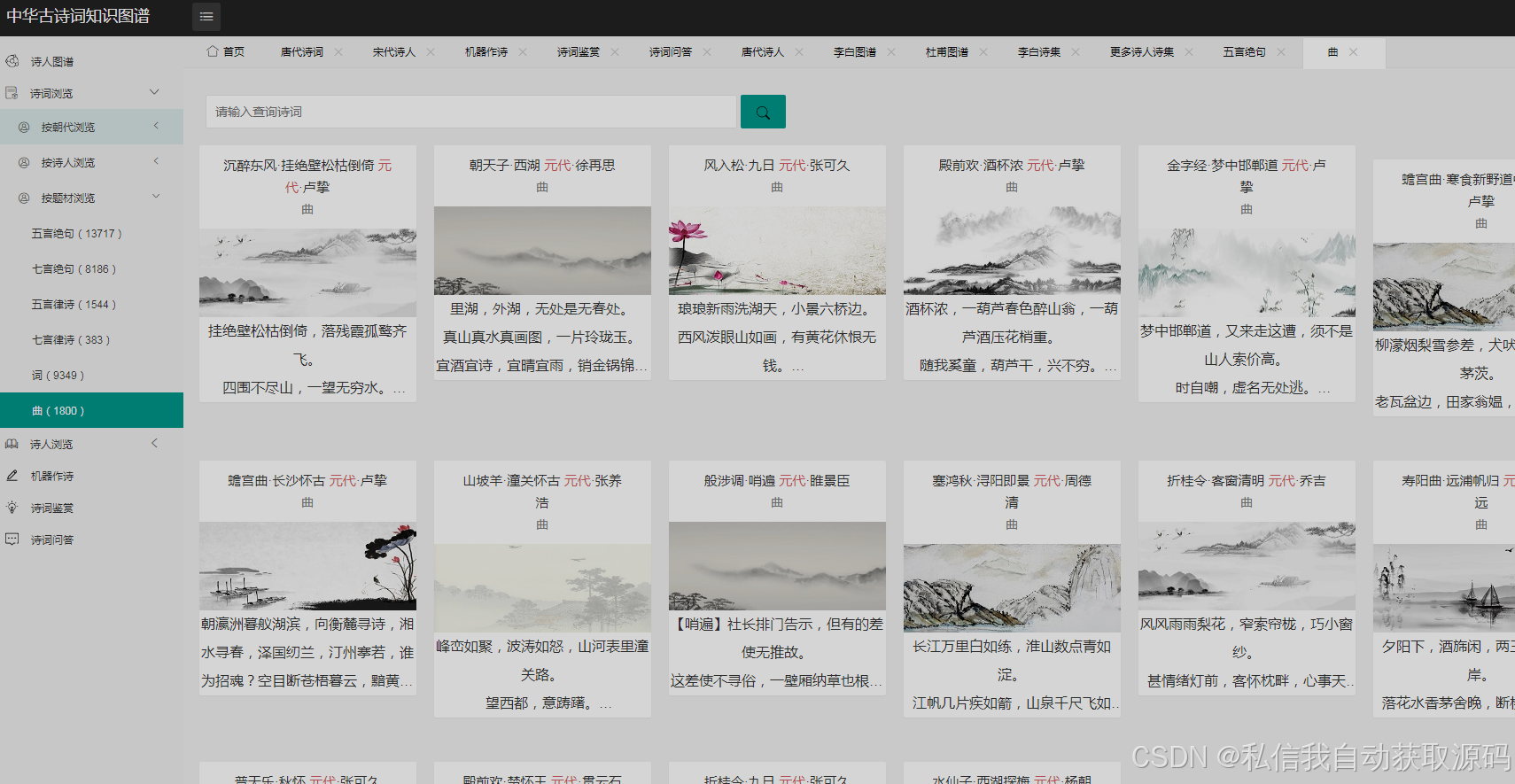
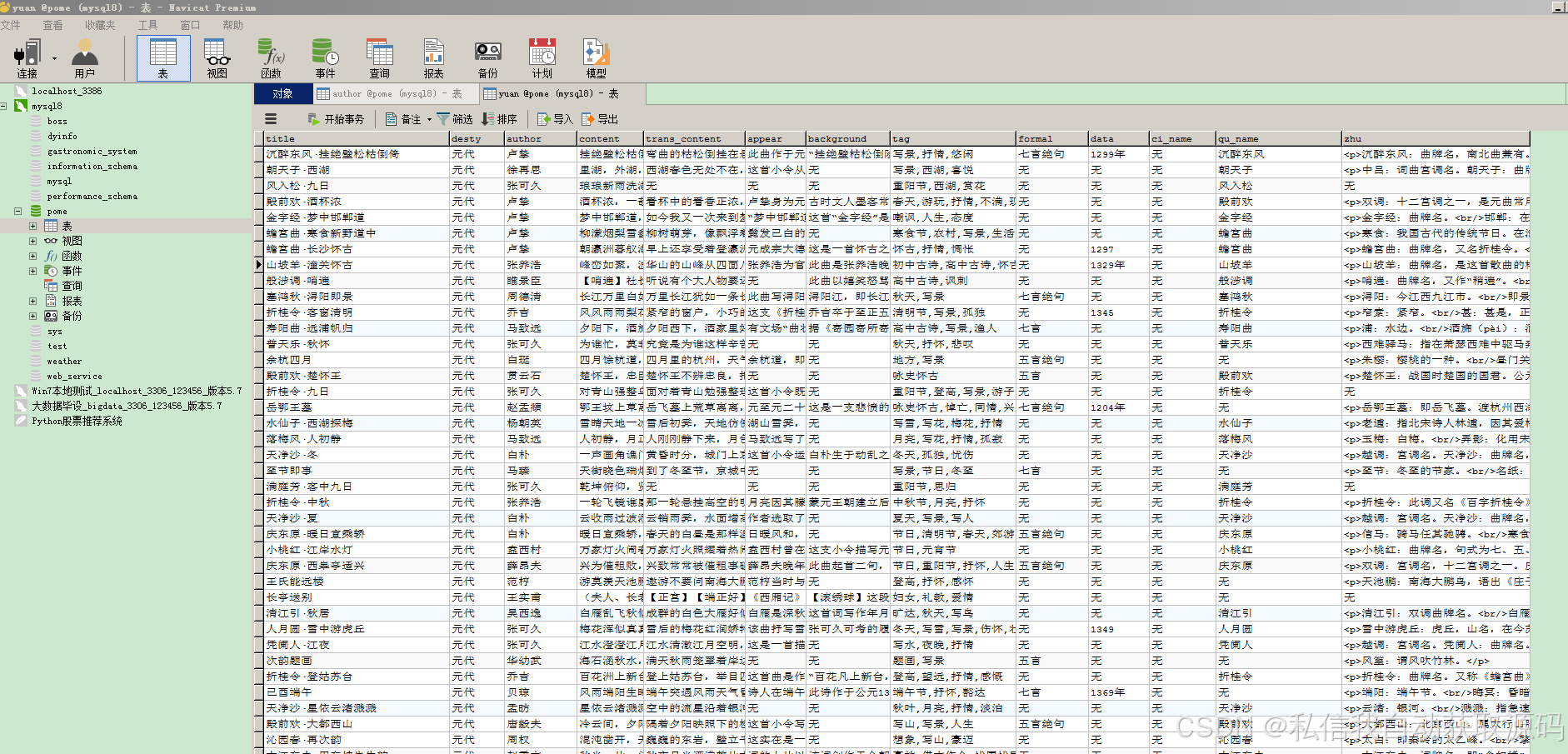
运行截图

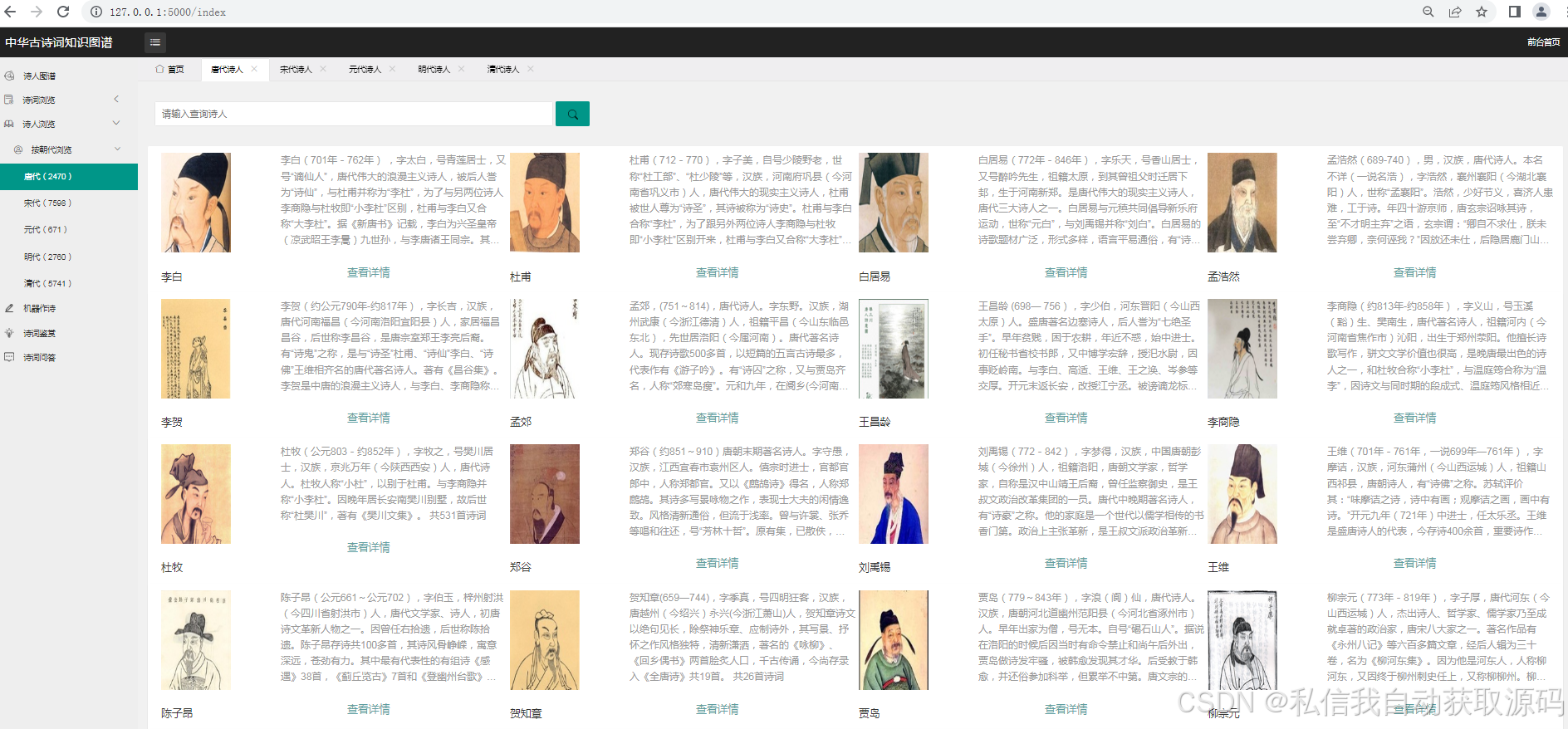
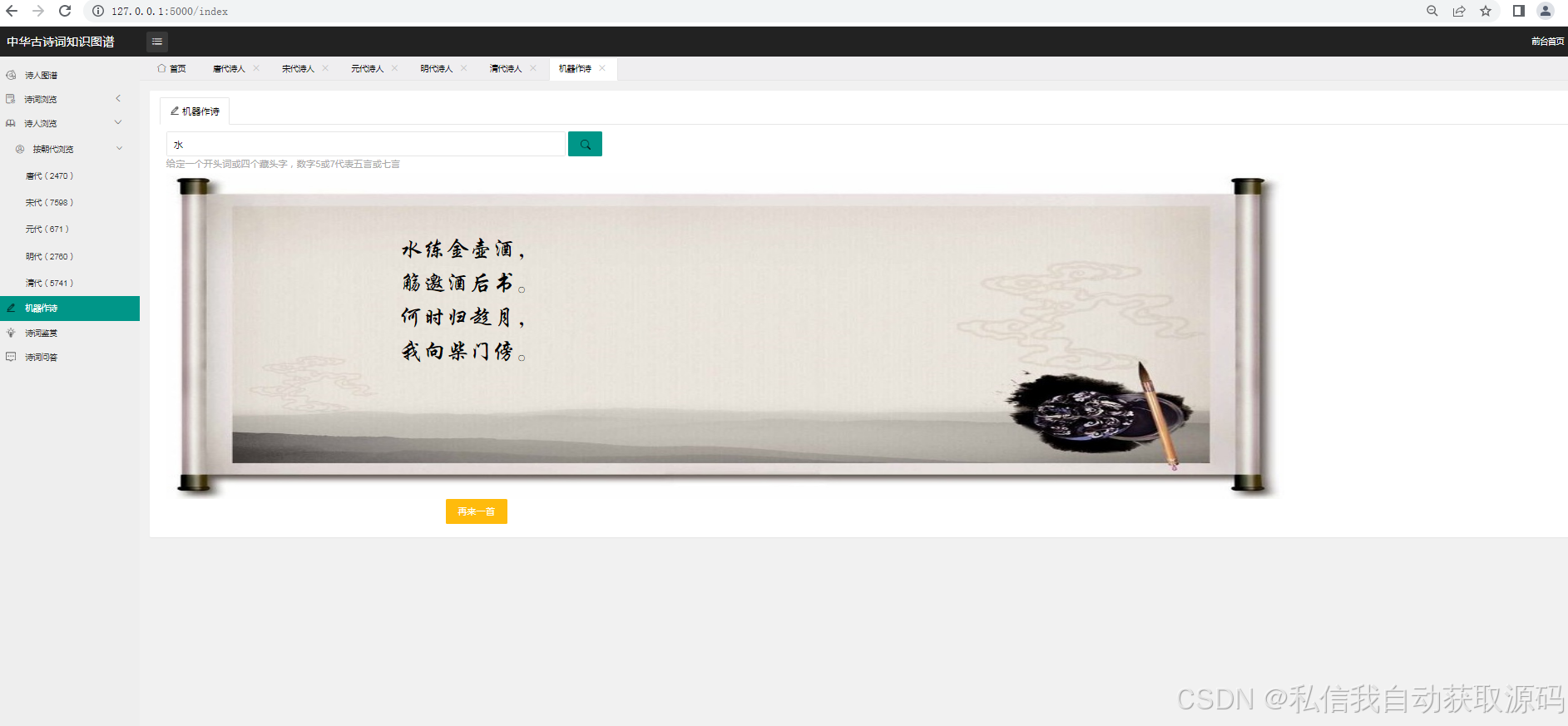
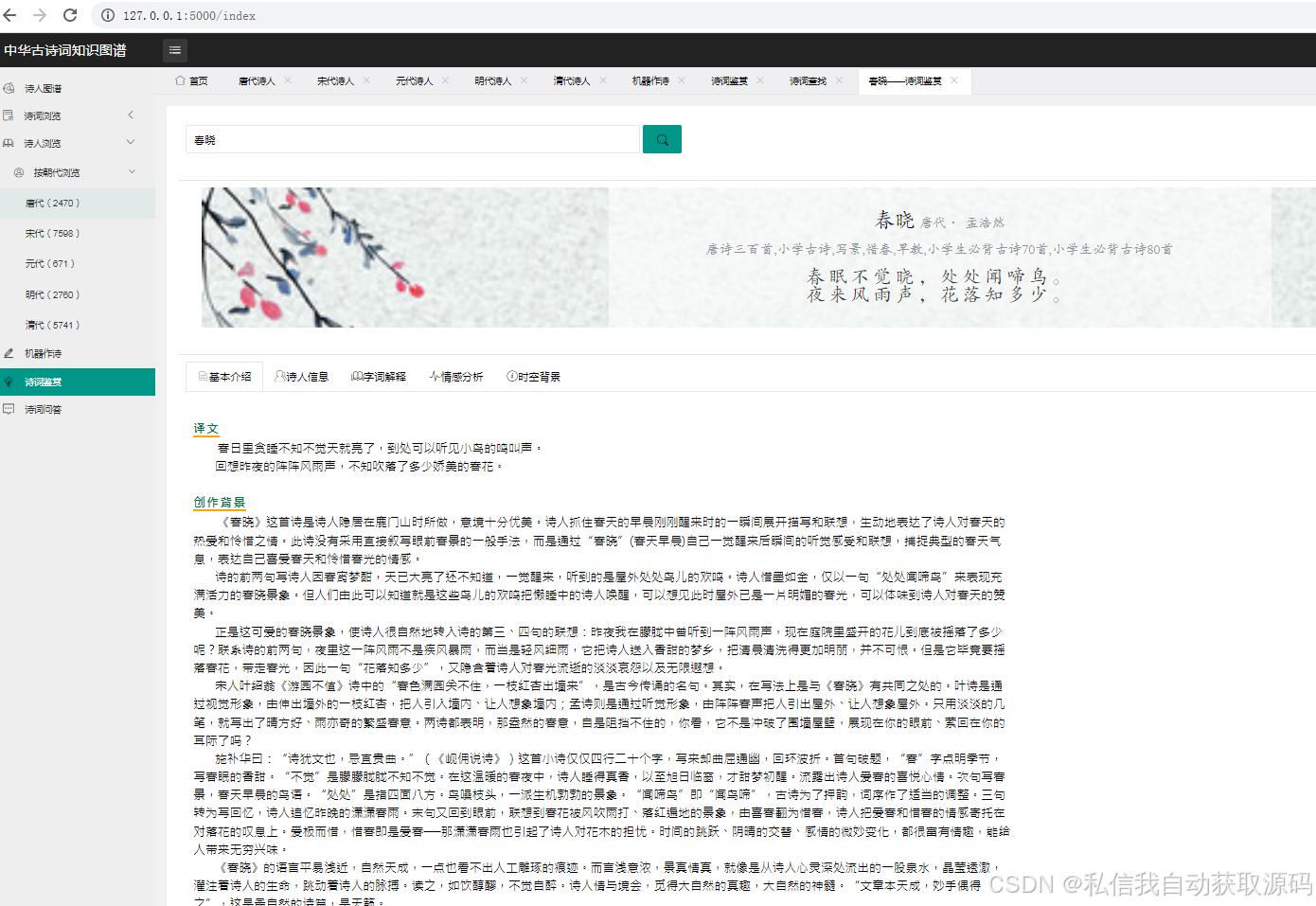
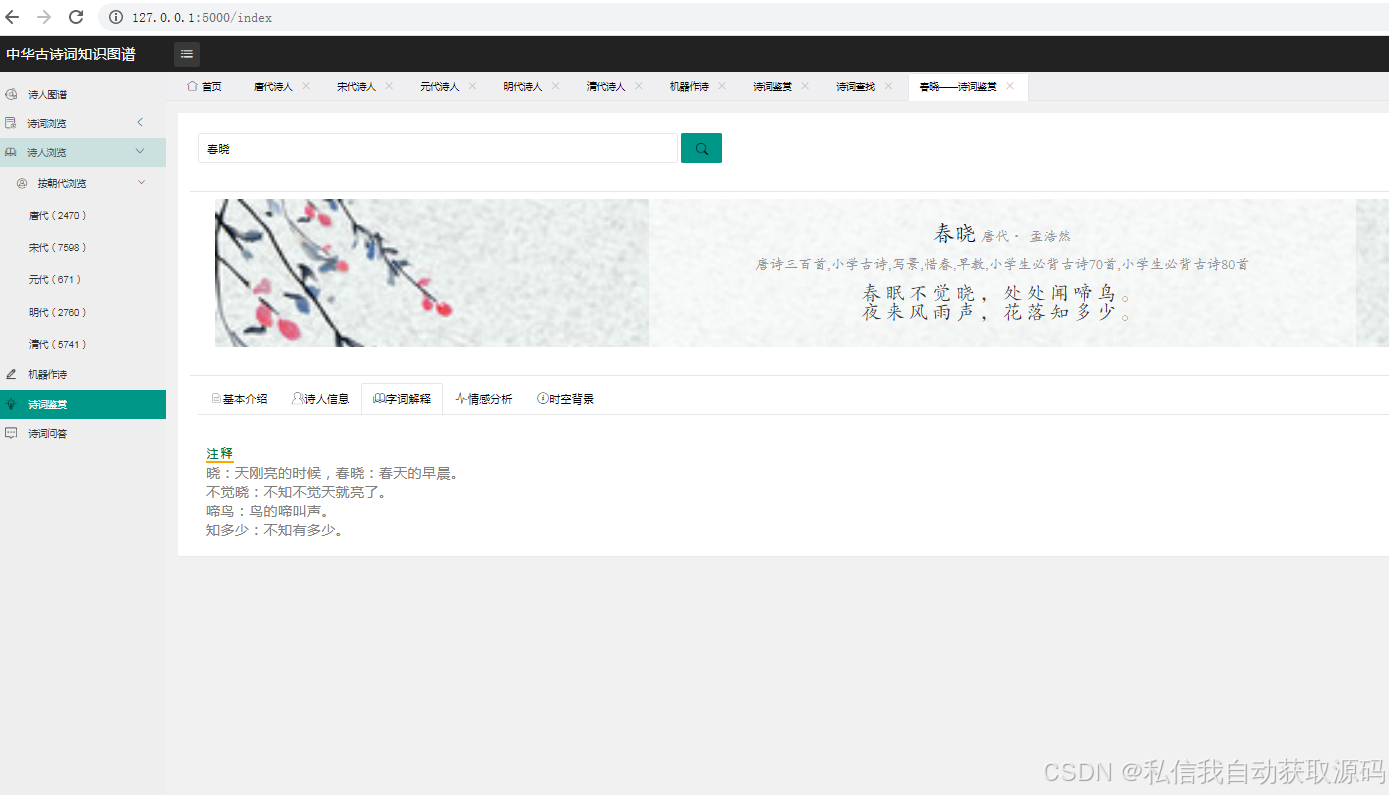
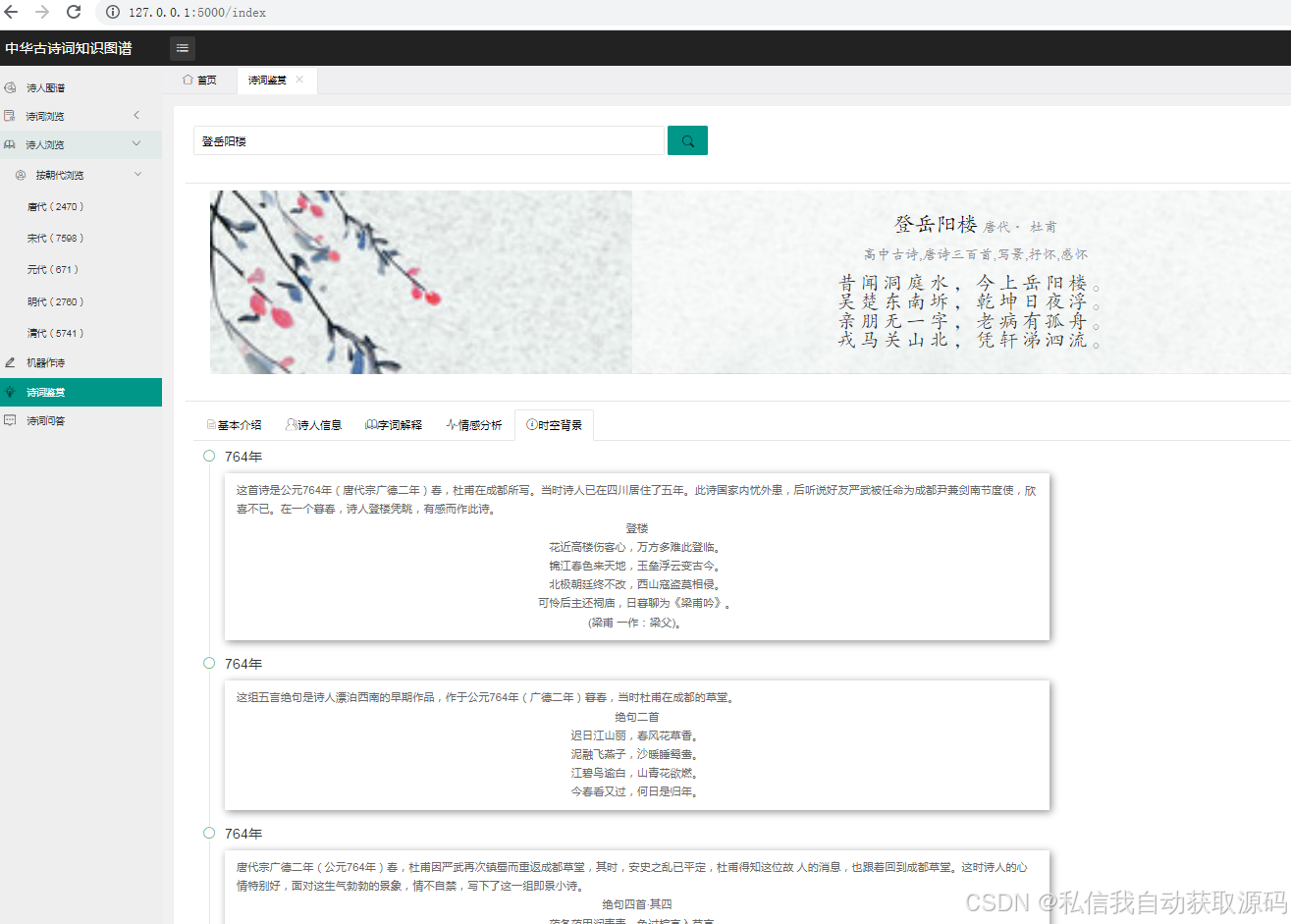
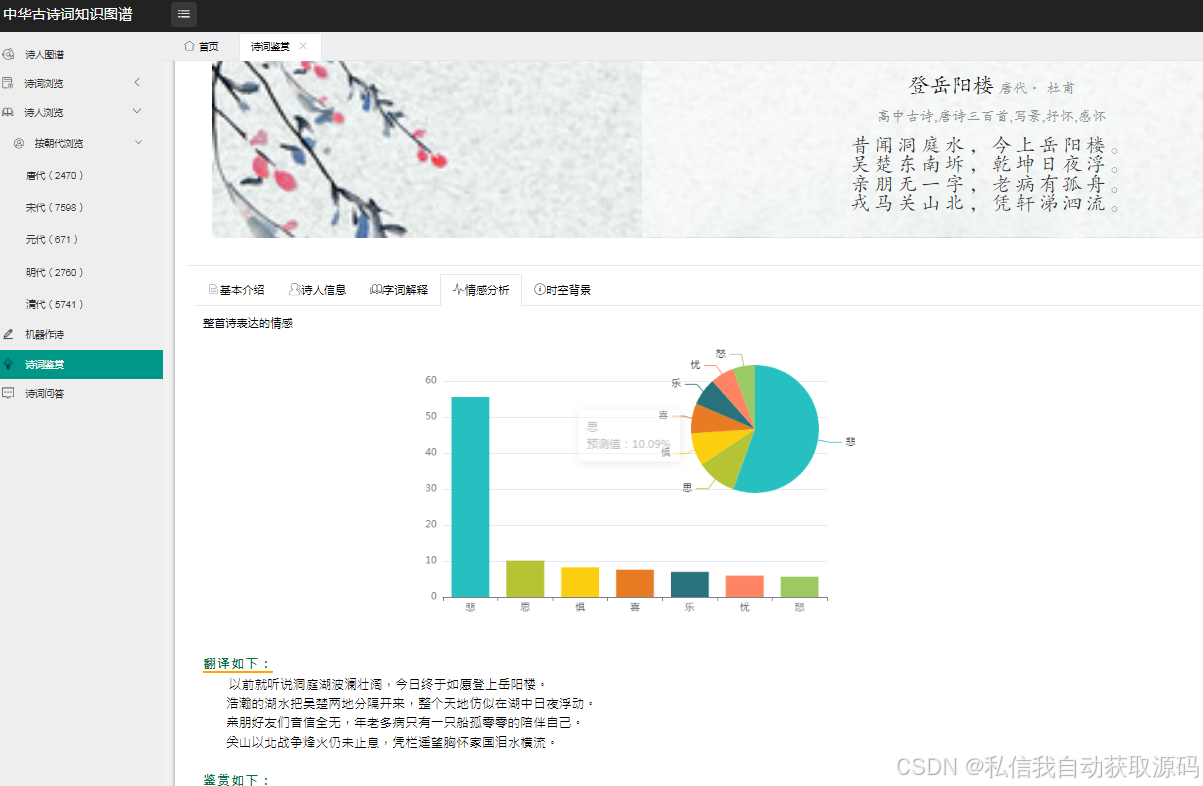
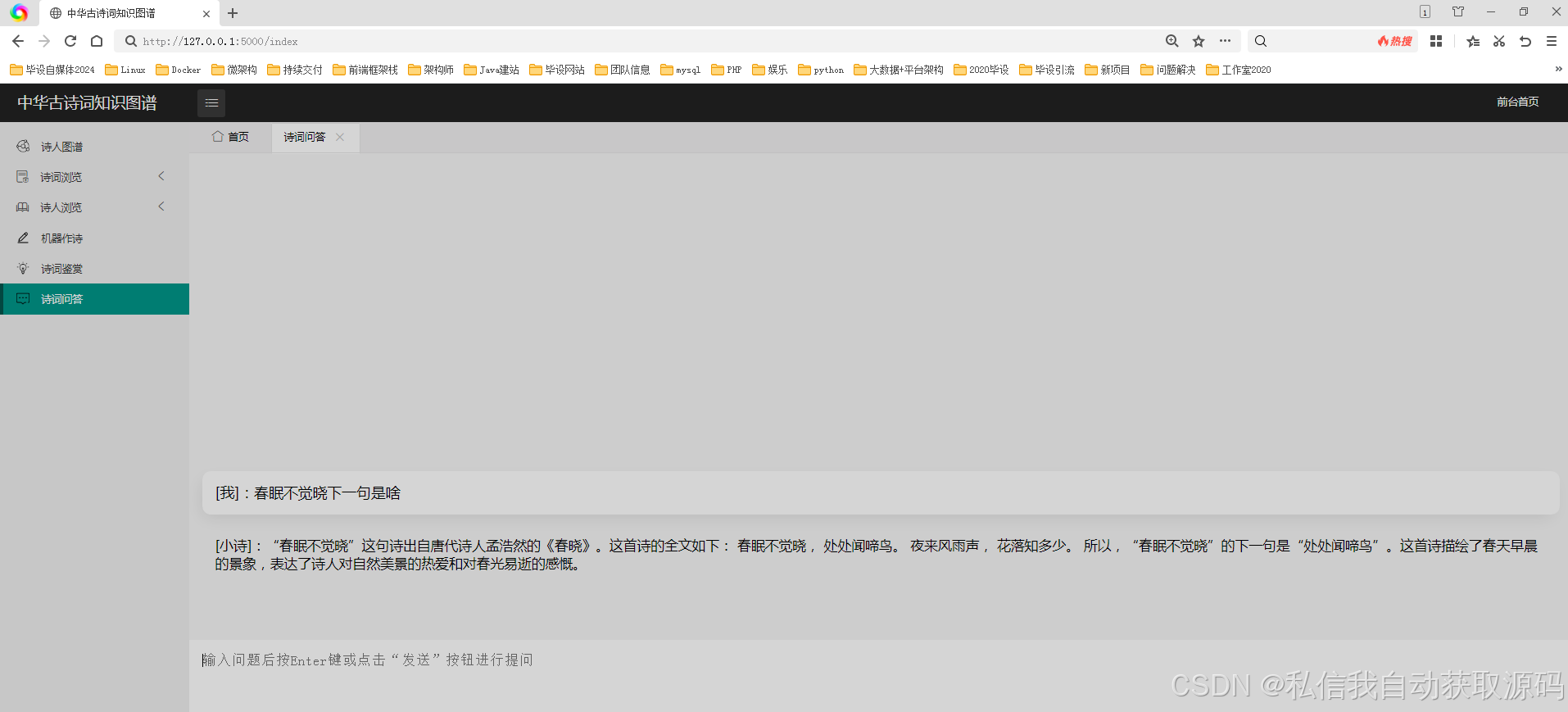
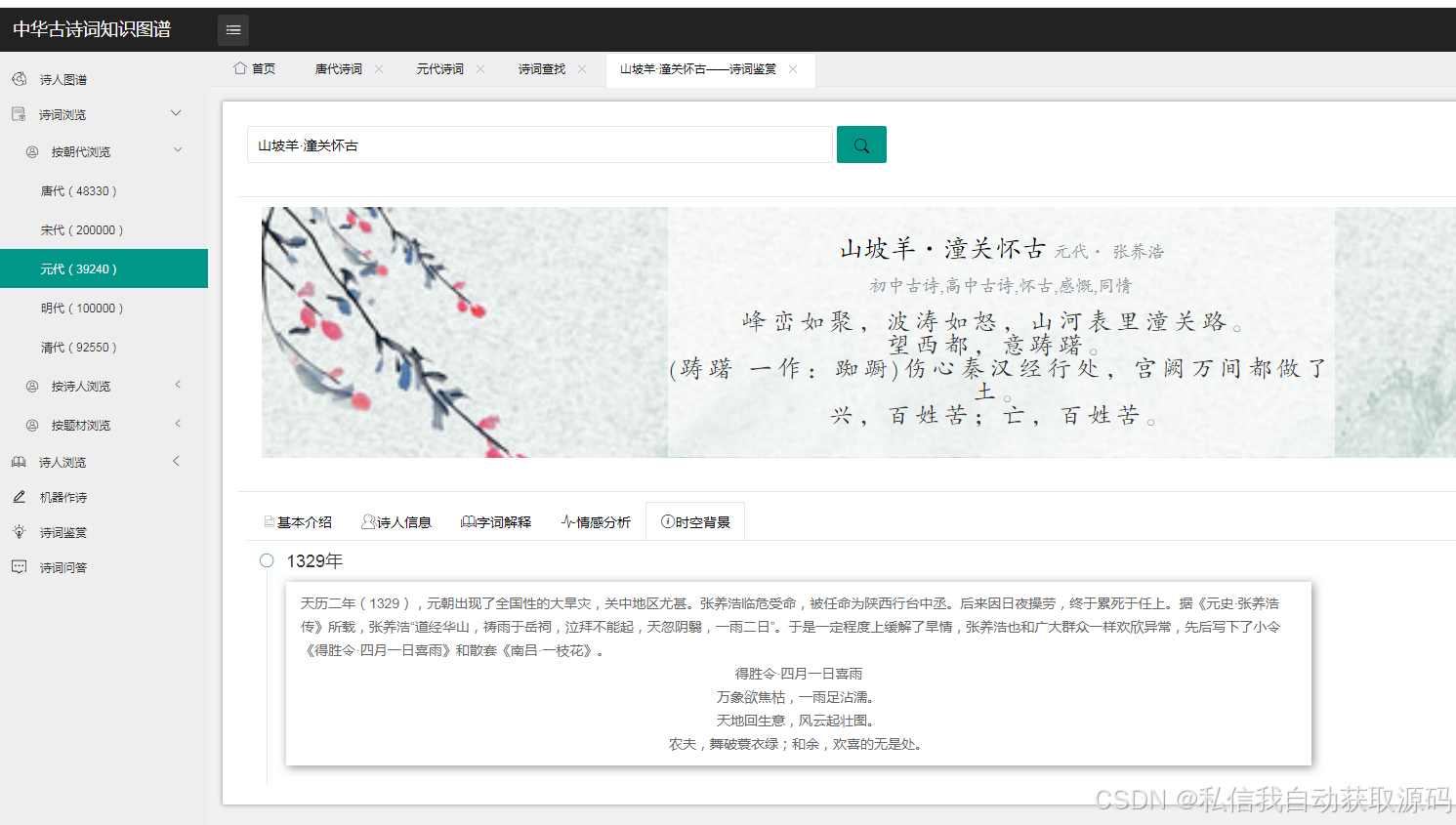
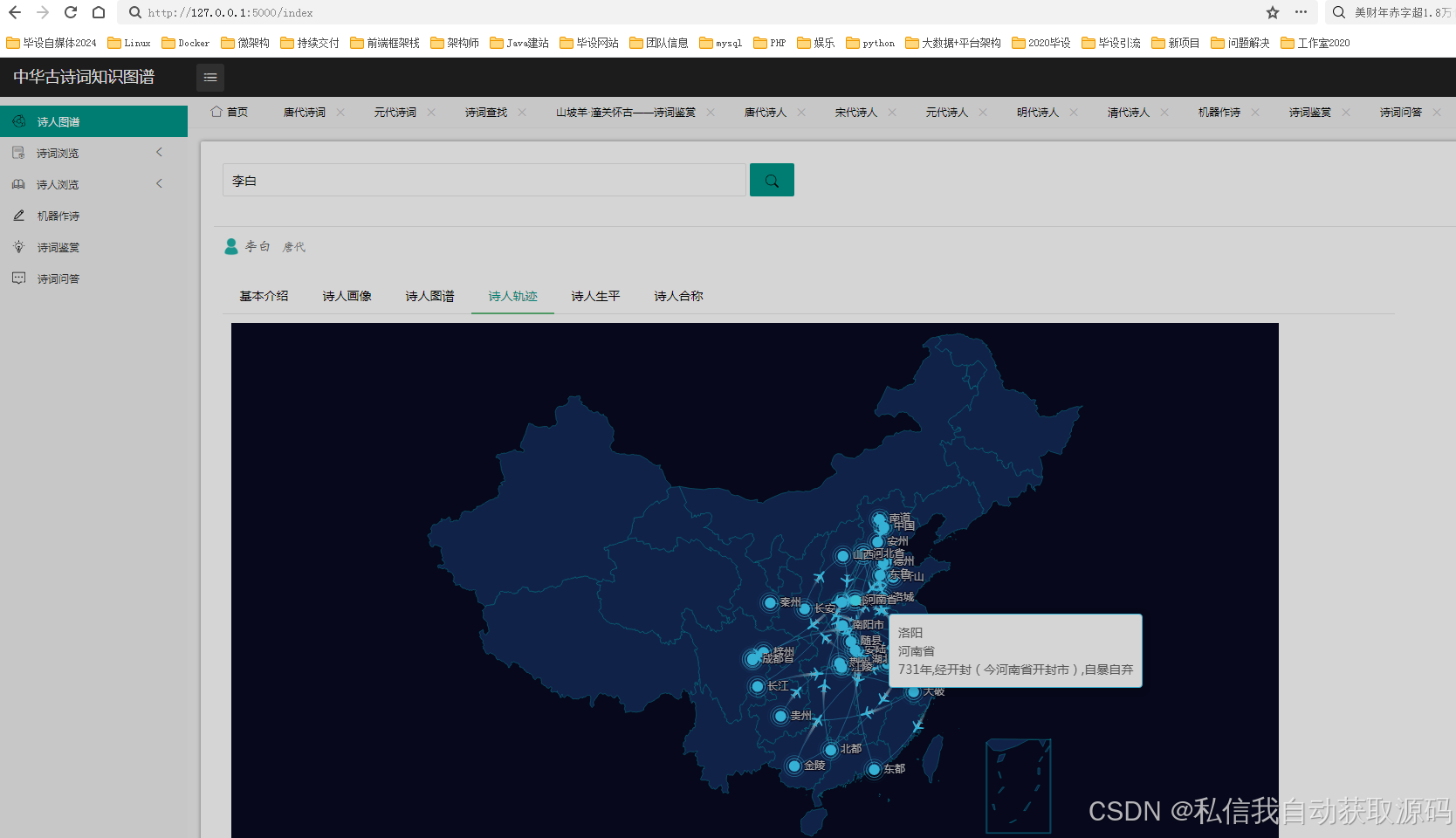
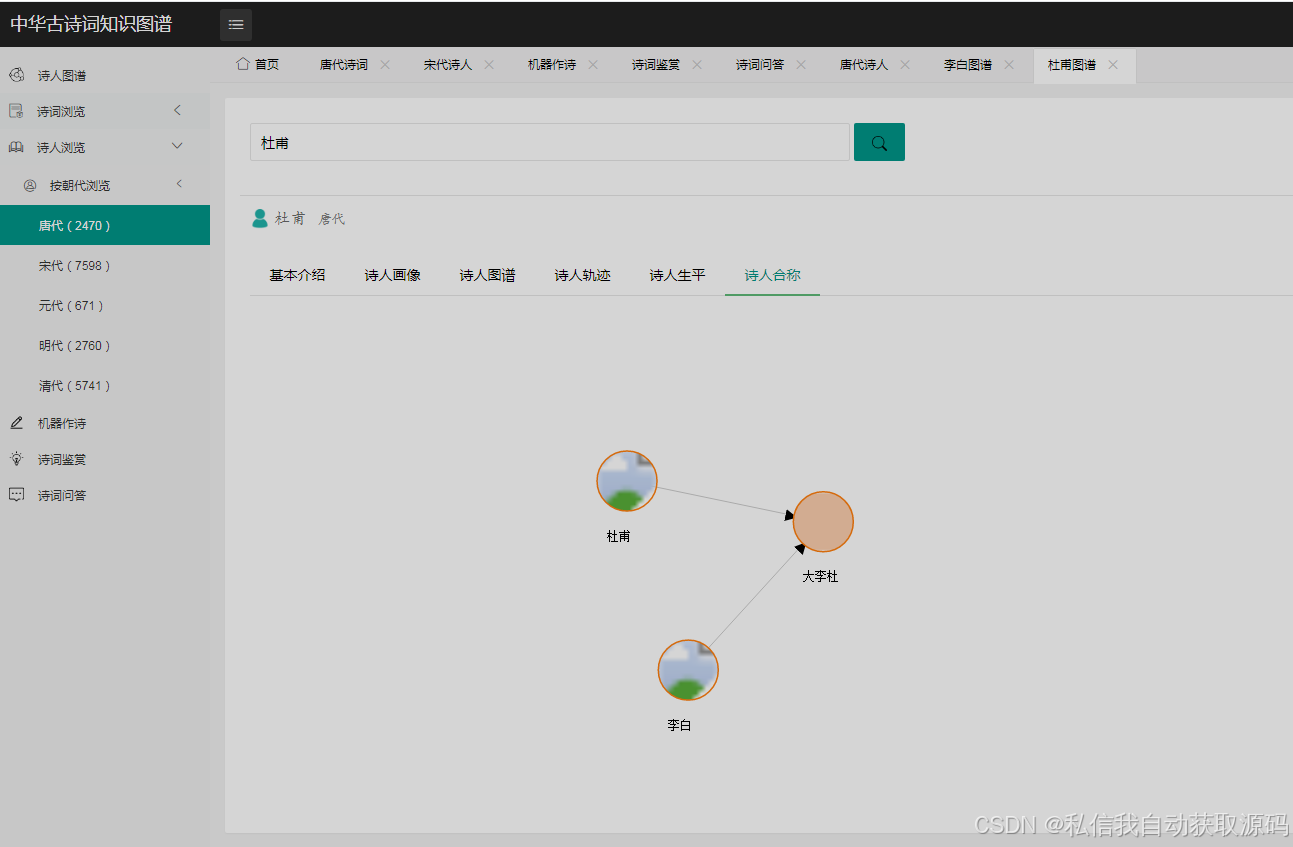
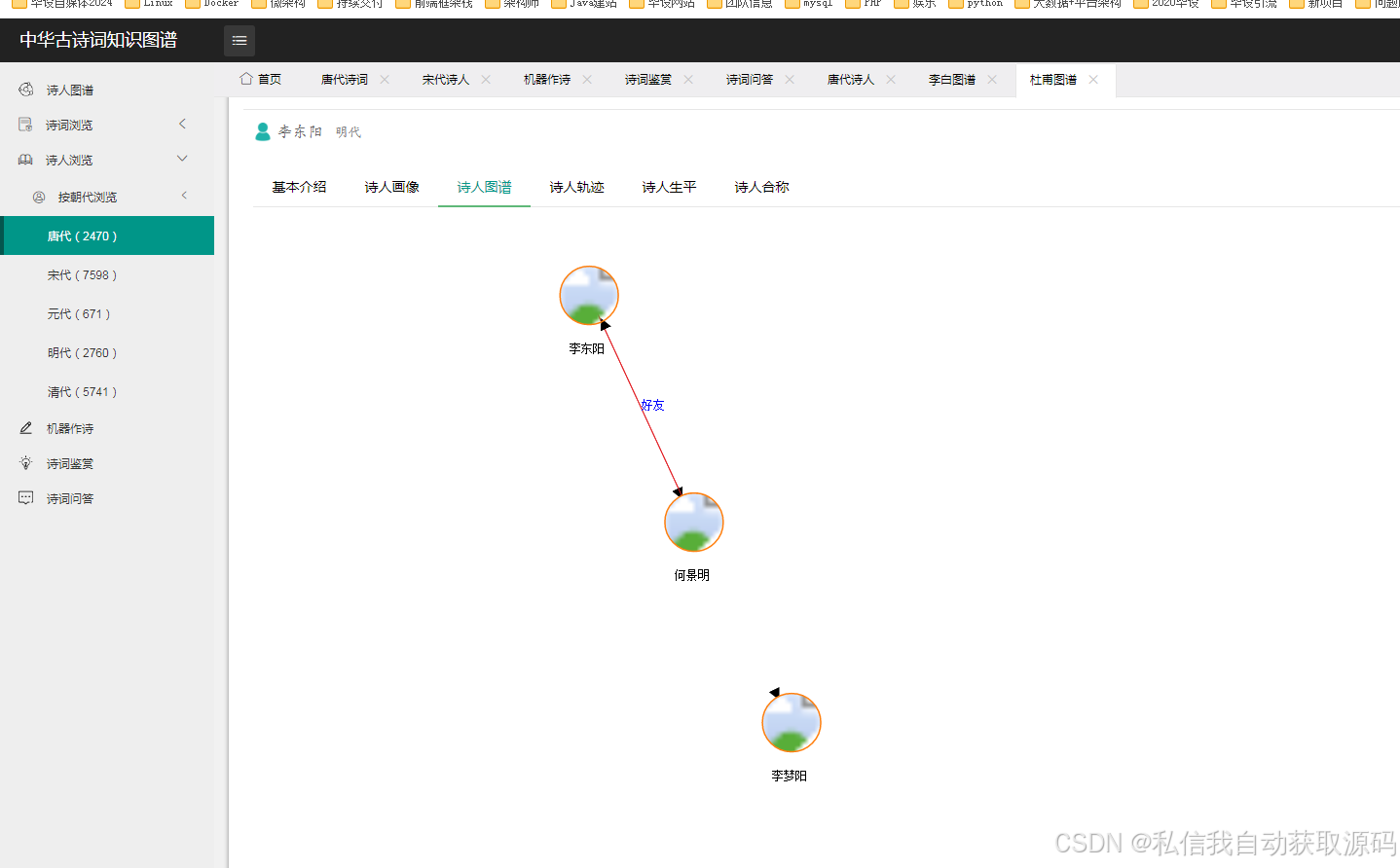
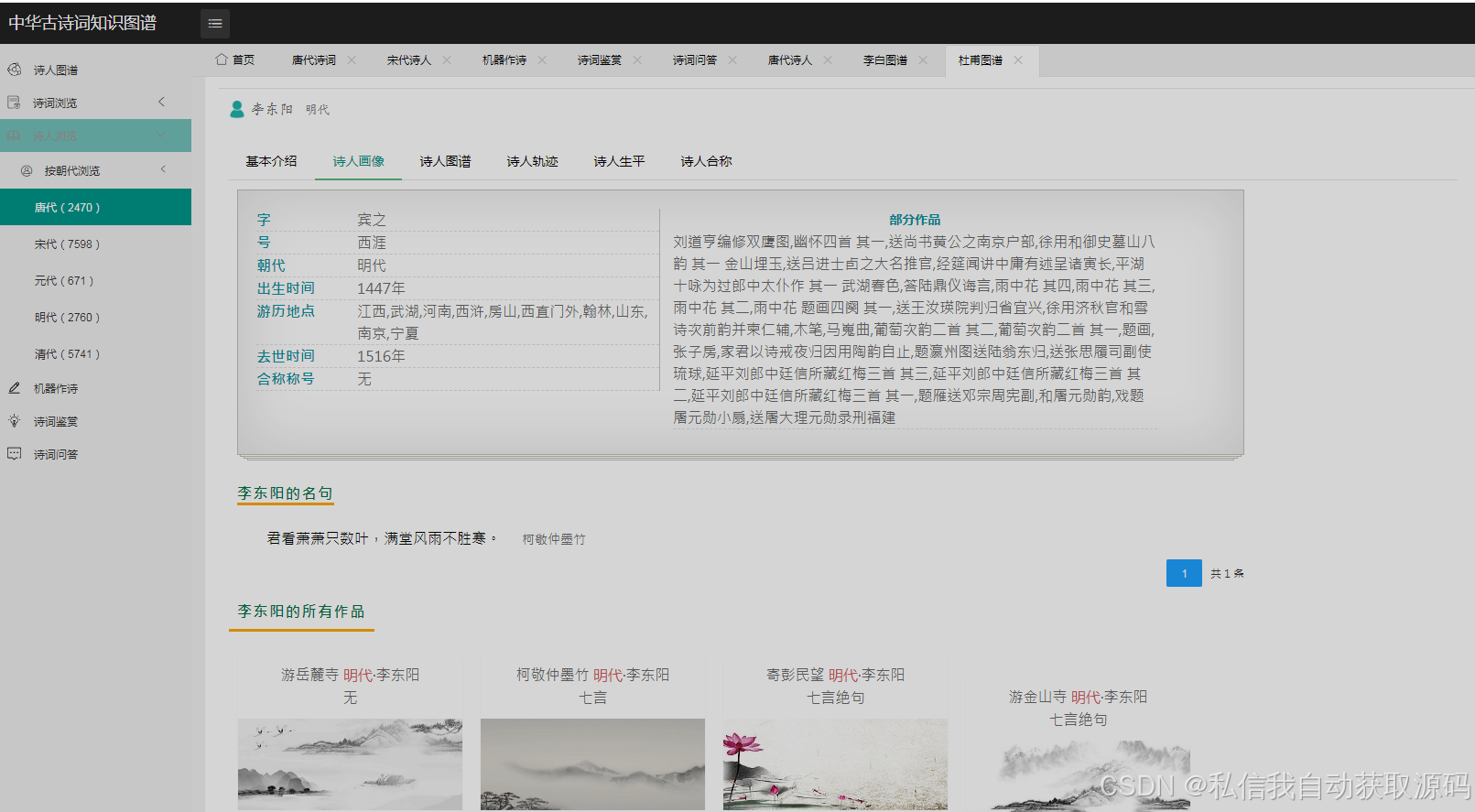
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,本人主页置顶文章开头有 CSDN 平台官方提供的学长联系方式的名片。🍅
点赞、收藏、关注,不迷路
更多推荐
 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)