
全栈开发与大模型应用部署经验分享(Vue3 + FastAPI + GLM-4V 构建的 AI Vocab Agent)
开发了一款基于大模型的英语单词记忆工具 AI Vocab Agent,通过词根词缀分析、近义词关联和可视化图谱帮助用户高效背单词。工具支持从Word文档提取生词(含图片转文本)、生成记忆法和例句,并利用ECharts展示词根网络。开发中解决了孤立单词向量检索偏差(改用查询扩展优化关联)和长文本延迟(预加载机制)等问题。项目已开源并部署在线Demo,寻求相关实习机会。
最近女朋友在集中背英语单词,背的时候老是说之前背过一个一样意思的,老是想不起来。
我就产生了一个想法:现在的大模型语言能力这么强,能不能让它在背单词时,直接帮我梳理出词根词缀、实用的记忆法,并且把意思相近的词自动串联起来? 如果能按语义和词根把单词连成一张网,记一个词就能顺带复习一串词,记起来应该会快很多,也更牢固。
顺着这个思路,我边学边敲,做了一个带有前后端界面的小工具,AI Vocab Agent。目前代码已经开源,也部署了一个在线版本。
🔗 GitHub 源码:[https://github.com/liyang-27/ai-vocab-agent/]
(如果觉得有帮助,希望能给个 Star 支持一下新人)
🌍 在线体验:[https://daduduvocab-y4ddq1r9.edgeone.cool?eo_token=06131af2b9740669695ee455db5268bd&eo_time=1778303368 ]
(由于腾讯云域名链接仅提供3小时限时预览,如想体验网站请留言。)
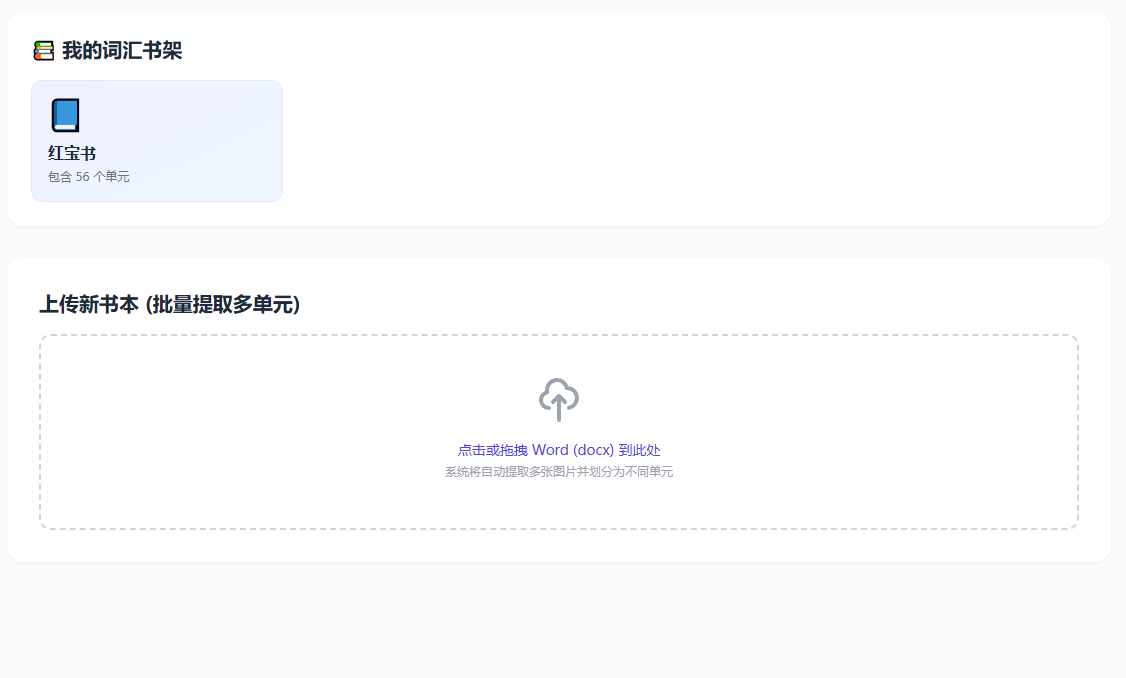
💡 主要功能
-
生词提取:可以直接把包含单词截图的 Word 文档传上去,后端会利用有视觉能力的大模型(智谱的glm-4v-plus)提取出纯单词,并自动分类建库。(因为女朋友自己截的图放到word中了,才有这个功能)
-
图谱记忆:按单元背诵时,大模型会把同词根的单词归类,前端用 ECharts 渲染成星状图。点击某个单词,会展示大模型生成的释义、记忆法以及例句。
-
近义词关联:在看一个单词时,系统会扫描你的全局词库,如果有意思相近的旧词,会高亮展示出来,帮你把新旧知识关联起来。
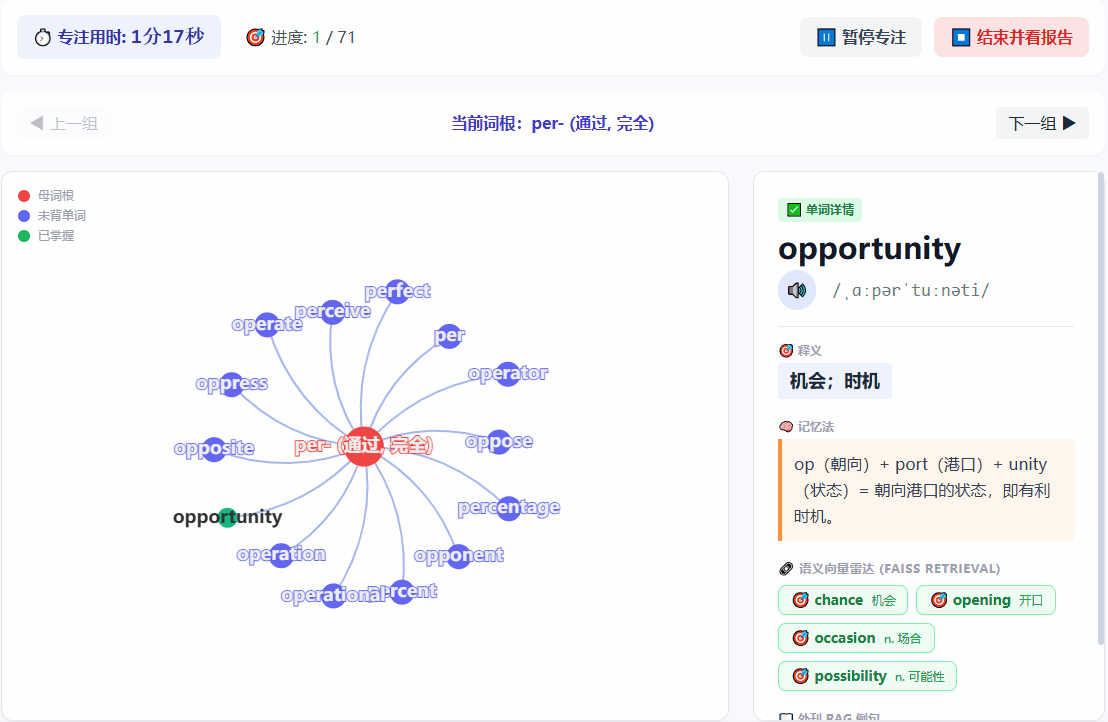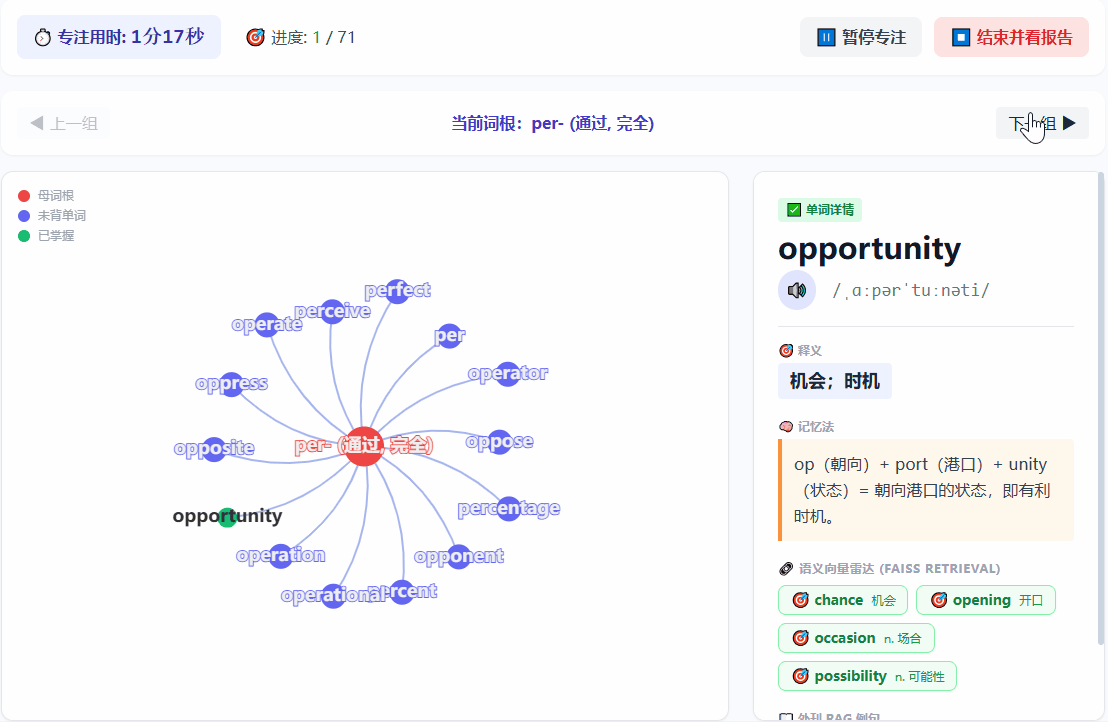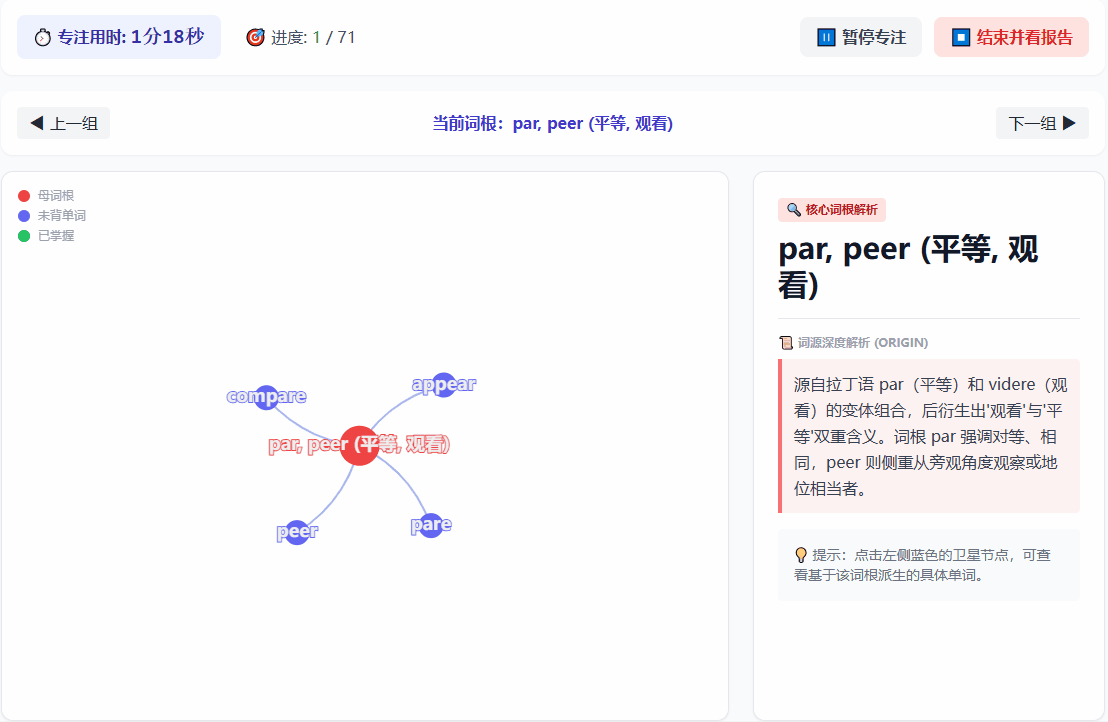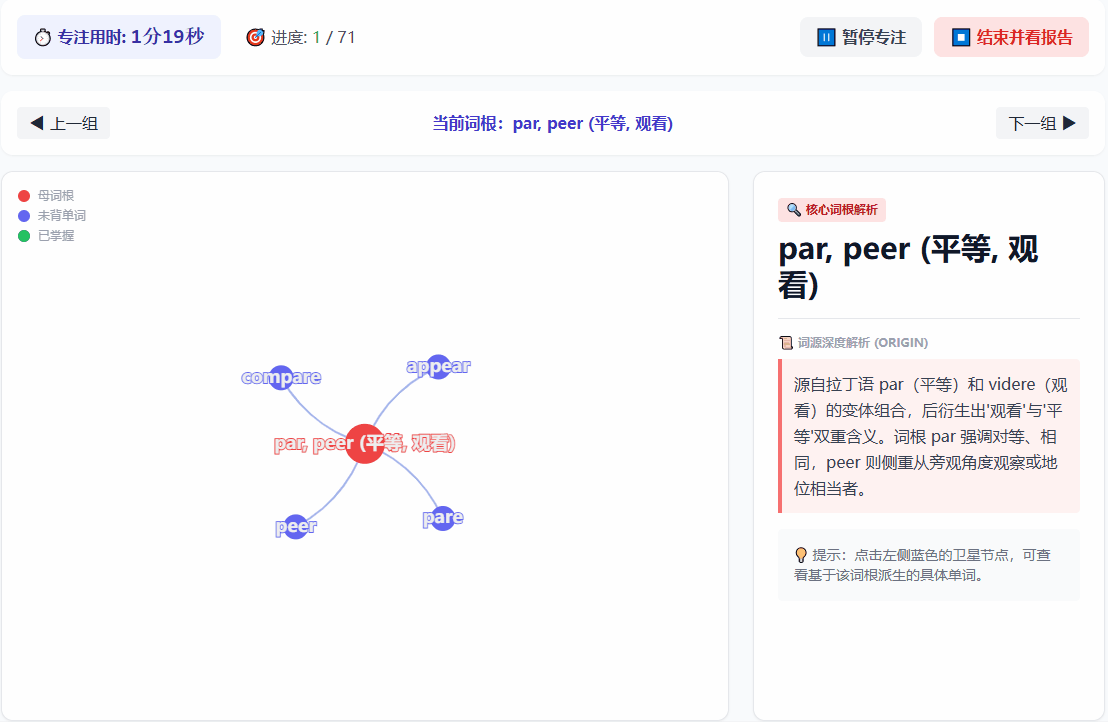
-
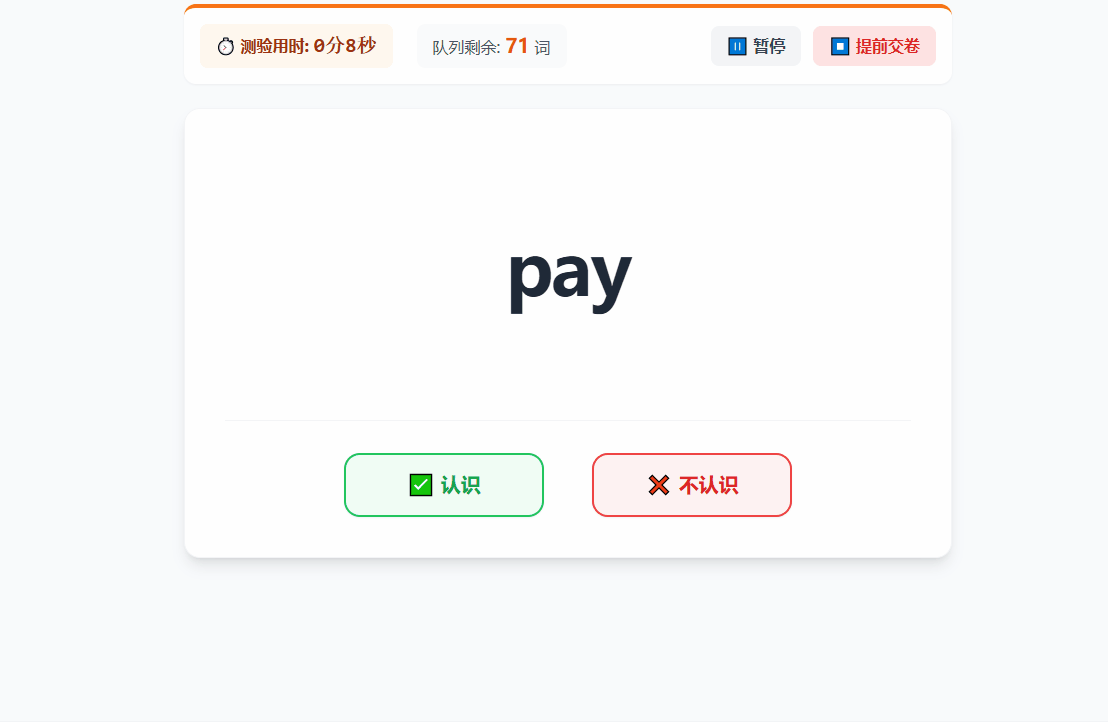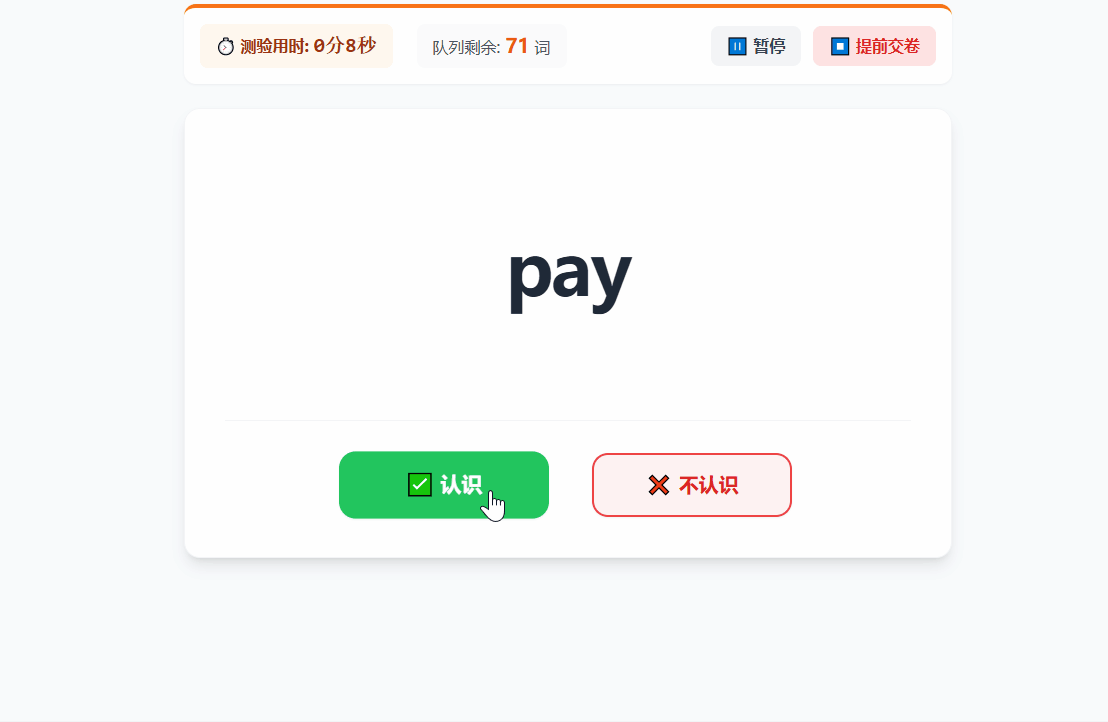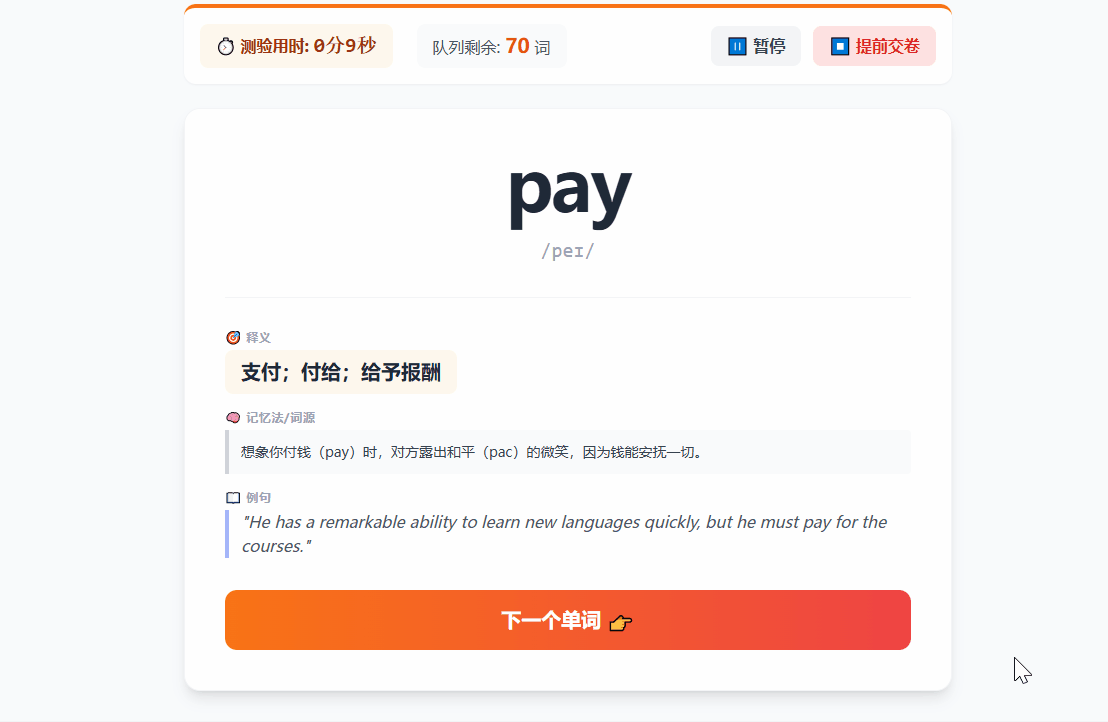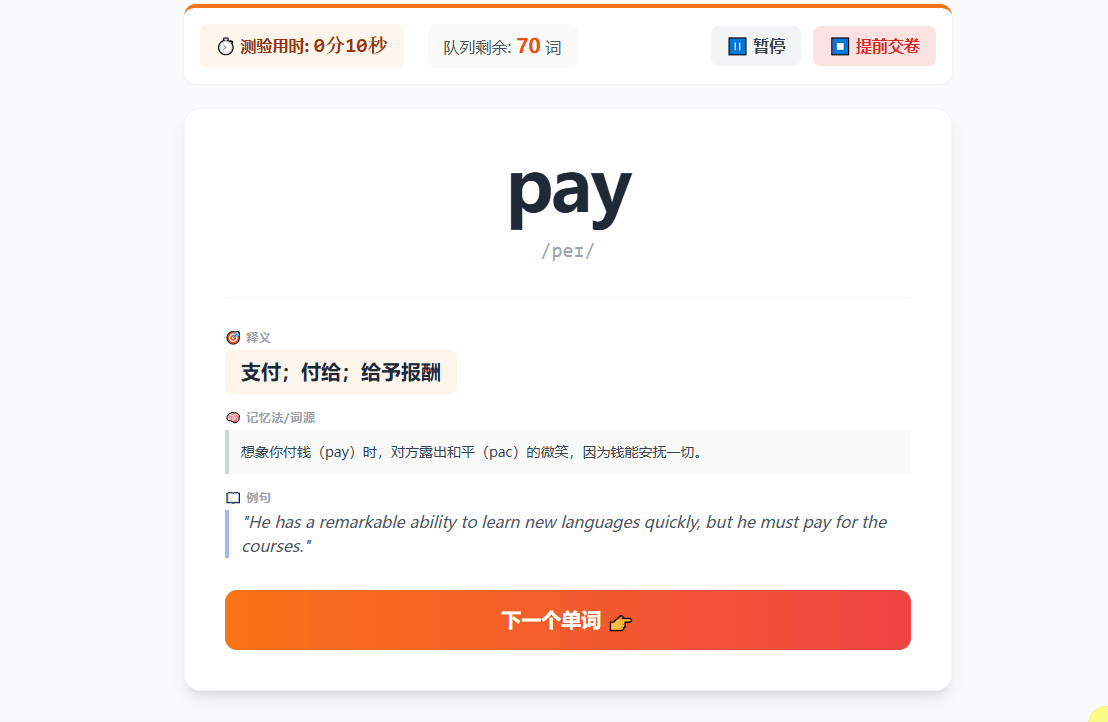
简单的复习测试:基于认识/不认识的逻辑做了一个闪卡测试,后台会记录每个词的停留时间作为复习依据。
🛠️ 开发中遇到的一些坑与改进
在把想法变成代码的过程中,发现大模型开发并不只是调 API 那么简单,实际落地时遇到了几个比较有意思的工程问题:
1. 孤立单词的向量检索偏差
在做“近义词自动关联”时,我最初的想法是用 FAISS 配合大模型的 Embedding 接口算余弦相似度。做这个应用时我觉得近义词匹配和大模型词向量映射逻辑刚好契合,因为大模型本身会通过 Embedding 将词语编码为高维语义向量,构建语义向量库,天然适合利用向量余弦相似度,实现近义词的自动关联与检索。
但在测试时发现了一个现象:当我点击 amend(修改)时,系统匹配出最相似的词居然是defend(防御)和 offend(冒犯)。 排查后发现,大模型的 BPE 分词在处理缺乏上下文的单个英文单词时,容易受字母组成的干扰(它们都带有 end 结尾),导致算出来的向量距离有偏差。
改进方法:我调整了策略,不再直接比对单词向量。而是先让大模型进行“查询扩展(Query Expansion)”,提炼出该词的 3 个核心同义词(比如 amend -> revise, modify),然后再拿这些词去和用户的词典库进行 O(1) 的精确碰撞查找。这样出来的关联词就非常准确了。
2. 长文本生成的延迟处理
大模型生成一个词根组下所有单词的解析和例句,往往需要十几秒。在 Web 页面上等待这么长时间体验很不顺畅。
改进方法:我没有选择让用户干等,而是在前端加了简单的并发控制和预加载机制。当用户在阅读第一组单词的图谱时,程序会在后台静默请求并缓存后续几个词根组的数据。这样只要过了最初的加载期,后续切换词根组基本可以实现无缝秒开。
📝 写在最后
这算是我第一次完整走完 Vue3 + FastAPI + 大模型应用 + 云服务部署的全流程。虽然功能还比较基础,但确实解决了我自己背单词时缺乏关联的痛点。
作为一个刚入门的新人,代码里肯定还有很多可以优化的地方,欢迎社区的前辈们多提意见。
最后,我目前正在寻找暑期研发实习机会(全栈开发 / 大模型应用开发均可) 。如果您团队有合适的实习机会,非常期待能和您聊聊!可以通过站内信或 GitHub 上的方式联系我。
的实习机会,非常期待能和您聊聊!可以通过站内信或 GitHub 上的方式联系我。
感谢阅读!
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)