
读技术之外:社会联结中的人工智能05数据神话
读技术之外:社会联结中的人工智能05数据神话
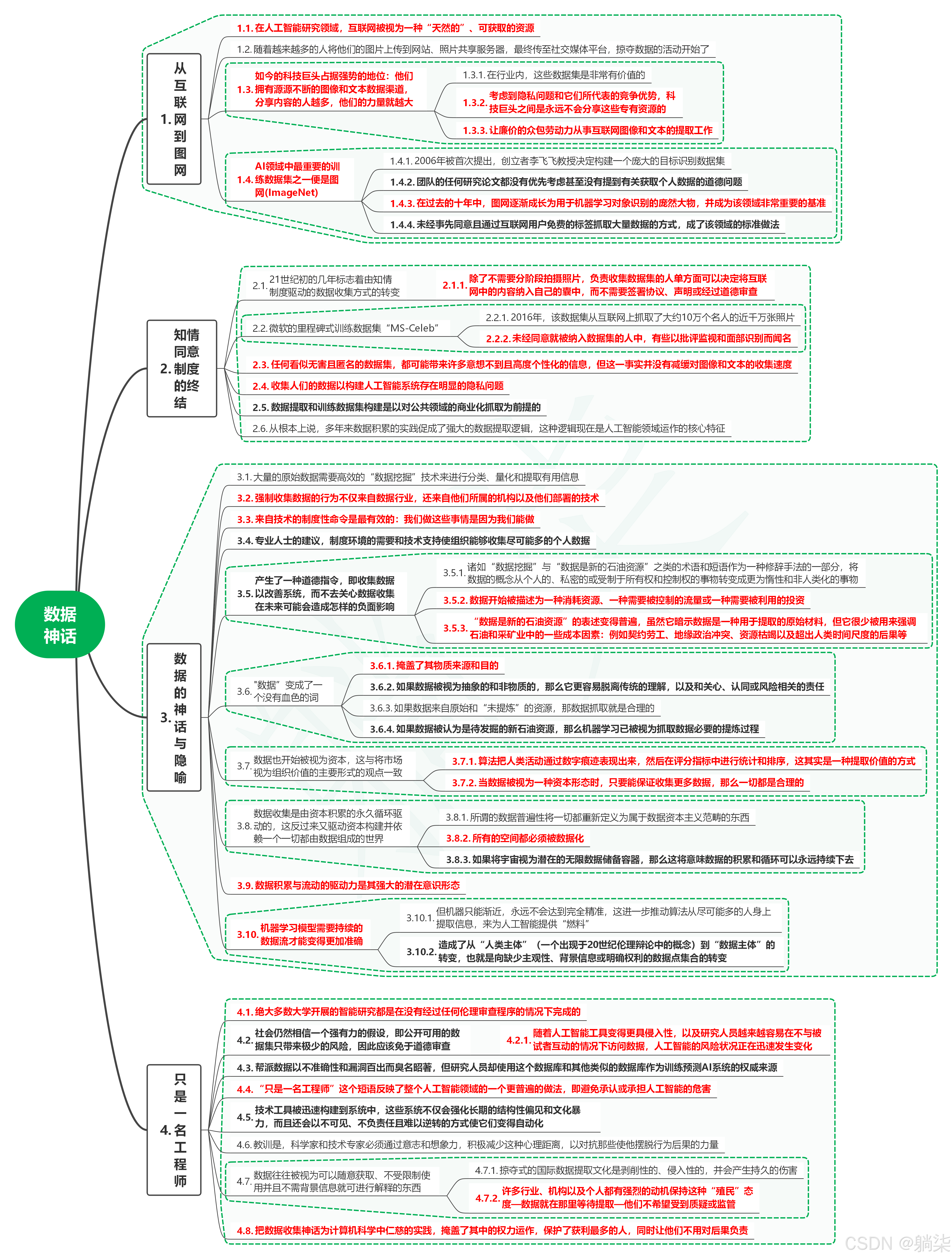
1. 从互联网到图网
1.1. 在人工智能研究领域,互联网被视为一种“天然的”、可获取的资源
1.2. 随着越来越多的人将他们的图片上传到网站、照片共享服务器,最终传至社交媒体平台,掠夺数据的活动开始了
1.3. 如今的科技巨头占据强势的地位:他们拥有源源不断的图像和文本数据渠道,分享内容的人越多,他们的力量就越大
-
1.3.1. 在行业内,这些数据集是非常有价值的
-
1.3.2. 考虑到隐私问题和它们所代表的竞争优势,科技巨头之间是永远不会分享这些专有资源的
-
1.3.3. 让廉价的众包劳动力从事互联网图像和文本的提取工作
1.4. AI领域中最重要的训练数据集之一便是图网(ImageNet)
-
1.4.1. 2006年被首次提出,创立者李飞飞教授决定构建一个庞大的目标识别数据集
-
1.4.2. 团队的任何研究论文都没有优先考虑甚至没有提到有关获取个人数据的道德问题
-
1.4.3. 在过去的十年中,图网逐渐成长为用于机器学习对象识别的庞然大物,并成为该领域非常重要的基准
-
1.4.4. 未经事先同意且通过互联网用户免费的标签抓取大量数据的方式,成了该领域的标准做法
2. 知情同意制度的终结
2.1. 21世纪初的几年标志着由知情制度驱动的数据收集方式的转变
- 2.1.1. 除了不需要分阶段拍摄照片,负责收集数据集的人单方面可以决定将互联网中的内容纳入自己的囊中,而不需要签署协议、声明或经过道德审查
2.2. 微软的里程碑式训练数据集“MS-Celeb”
-
2.2.1. 2016年,该数据集从互联网上抓取了大约10万个名人的近千万张照片
-
2.2.2. 未经同意就被纳入数据集的人中,有些以批评监视和面部识别而闻名
2.3. 任何看似无害且匿名的数据集,都可能带来许多意想不到且高度个性化的信息,但这一事实并没有减缓对图像和文本的收集速度
2.4. 收集人们的数据以构建人工智能系统存在明显的隐私问题
2.5. 数据提取和训练数据集构建是以对公共领域的商业化抓取为前提的
2.6. 从根本上说,多年来数据积累的实践促成了强大的数据提取逻辑,这种逻辑现在是人工智能领域运作的核心特征
3. 数据的神话与隐喻
3.1. 大量的原始数据需要高效的“数据挖掘”技术来进行分类、量化和提取有用信息
3.2. 强制收集数据的行为不仅来自数据行业,还来自他们所属的机构以及他们部署的技术
3.3. 来自技术的制度性命令是最有效的:我们做这些事情是因为我们能做
3.4. 专业人士的建议,制度环境的需要和技术支持使组织能够收集尽可能多的个人数据
3.5. 产生了一种道德指令,即收集数据以改善系统,而不去关心数据收集在未来可能会造成怎样的负面影响
-
3.5.1. 诸如“数据挖掘”与“数据是新的石油资源”之类的术语和短语作为一种修辞手法的一部分,将数据的概念从个人的、私密的或受制于所有权和控制权的事物转变成更为惰性和非人类化的事物
-
3.5.2. 数据开始被描述为一种消耗资源、一种需要被控制的流量或一种需要被利用的投资
-
3.5.3. “数据是新的石油资源”的表述变得普遍,虽然它暗示数据是一种用于提取的原始材料,但它很少被用来强调石油和采矿业中的一些成本因素:例如契约劳工、地缘政治冲突、资源枯竭以及超出人类时间尺度的后果等
3.6. "数据”变成了一个没有血色的词
-
3.6.1. 掩盖了其物质来源和目的
-
3.6.2. 如果数据被视为抽象的和非物质的,那么它更容易脱离传统的理解,以及和关心、认同或风险相关的责任
-
3.6.3. 如果数据来自原始和“未提炼”的资源,那数据抓取就是合理的
-
3.6.4. 如果数据被认为是待发掘的新石油资源,那么机器学习已被视为抓取数据必要的提炼过程
3.7. 数据也开始被视为资本,这与将市场视为组织价值的主要形式的观点一致
-
3.7.1. 算法把人类活动通过数字痕迹表现出来,然后在评分指标中进行统计和排序,这其实是一种提取价值的方式
-
3.7.2. 当数据被视为一种资本形态时,只要能保证收集更多数据,那么一切都是合理的
3.8. 数据收集是由资本积累的永久循环驱动的,这反过来又驱动资本构建并依赖一个一切都由数据组成的世界
-
3.8.1. 所谓的数据普遍性将一切都重新定义为属于数据资本主义范畴的东西
-
3.8.2. 所有的空间都必须被数据化
-
3.8.3. 如果将宇宙视为潜在的无限数据储备容器,那么这将意味数据的积累和循环可以永远持续下去
3.9. 数据积累与流动的驱动力是其强大的潜在意识形态
3.10. 机器学习模型需要持续的数据流才能变得更加准确
-
3.10.1. 但机器只能渐近,永远不会达到完全精准,这进一步推动算法从尽可能多的人身上提取信息,来为人工智能提供“燃料”
-
3.10.2. 造成了从“人类主体”(一个出现于20世纪伦理辩论中的概念)到“数据主体”的转变,也就是向缺少主观性、背景信息或明确权利的数据点集合的转变
4. 只是一名工程师
4.1. 绝大多数大学开展的智能研究都是在没有经过任何伦理审查程序的情况下完成的
4.2. 社会仍然相信一个强有力的假设,即公开可用的数据集只带来极少的风险,因此应该免于道德审查
- 4.2.1. 随着人工智能工具变得更具侵入性,以及研究人员越来越容易在不与被试者互动的情况下访问数据,人工智能的风险状况正在迅速发生变化
4.3. 帮派数据以不准确性和漏洞百出而臭名昭著,但研究人员却使用这个数据库和其他类似的数据库作为训练预测AI系统的权威来源
4.4. “只是一名工程师”这个短语反映了整个人工智能领域的一个更普遍的做法,即避免承认或承担人工智能的危害
4.5. 技术工具被迅速构建到系统中,这些系统不仅会强化长期的结构性偏见和文化暴力,而且还会以不可见、不负责任且难以逆转的方式使它们变得自动化
4.6. 教训是,科学家和技术专家必须通过意志和想象力,积极减少这种心理距离,以对抗那些使他摆脱行为后果的力量
4.7. 数据往往被视为可以随意获取、不受限制使用并且不需背景信息就可进行解释的东西
-
4.7.1. 掠夺式的国际数据提取文化是剥削性的、侵入性的,并会产生持久的伤害
-
4.7.2. 许多行业、机构以及个人都有强烈的动机保持这种“殖民”态度—数据就在那里等待提取—他们不希望受到质疑或监管
4.8. 把数据收集神话为计算机科学中仁慈的实践,掩盖了其中的权力运作,保护了获利最多的人,同时让他们不用对后果负责
更多推荐

 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)