
GLM-4.6: 高级代理、推理与编码能力
智谱AI发布GLM-4.6大模型,主要升级包括:上下文窗口扩展至200K token,代码和推理能力显著提升,智能体任务表现更优。在八大基准测试中优于GLM-4.5,与Claude Sonnet 4性能接近,token效率提升15%。已开源模型权重,支持vLLM等框架本地部署,订阅用户可自动升级使用。评估细节和任务数据已在HuggingFace开源。
今天我们正式发布旗舰模型的最新版本:GLM-4.6。相比GLM-4.5,这一代带来多项关键提升:
- 更长上下文窗口:上下文窗口从128K扩展至200K token,使模型能处理更复杂的智能体任务
- 更强代码能力:在代码基准测试中获得更高分数,在Claude Code、Cline、Roo Code和Kilo Code等应用中展现出更优的实际表现,包括生成视觉效果更精致的前端页面
- 进阶推理能力:GLM-4.6在推理性能上有明显提升,支持推理过程中使用工具,带来更强的综合能力
- 更智能的智能体:在工具调用和基于搜索的智能体任务中表现更强劲,在智能体框架中的集成更高效
- 更细腻的写作:更符合人类对风格和可读性的偏好,在角色扮演场景中表现更为自然
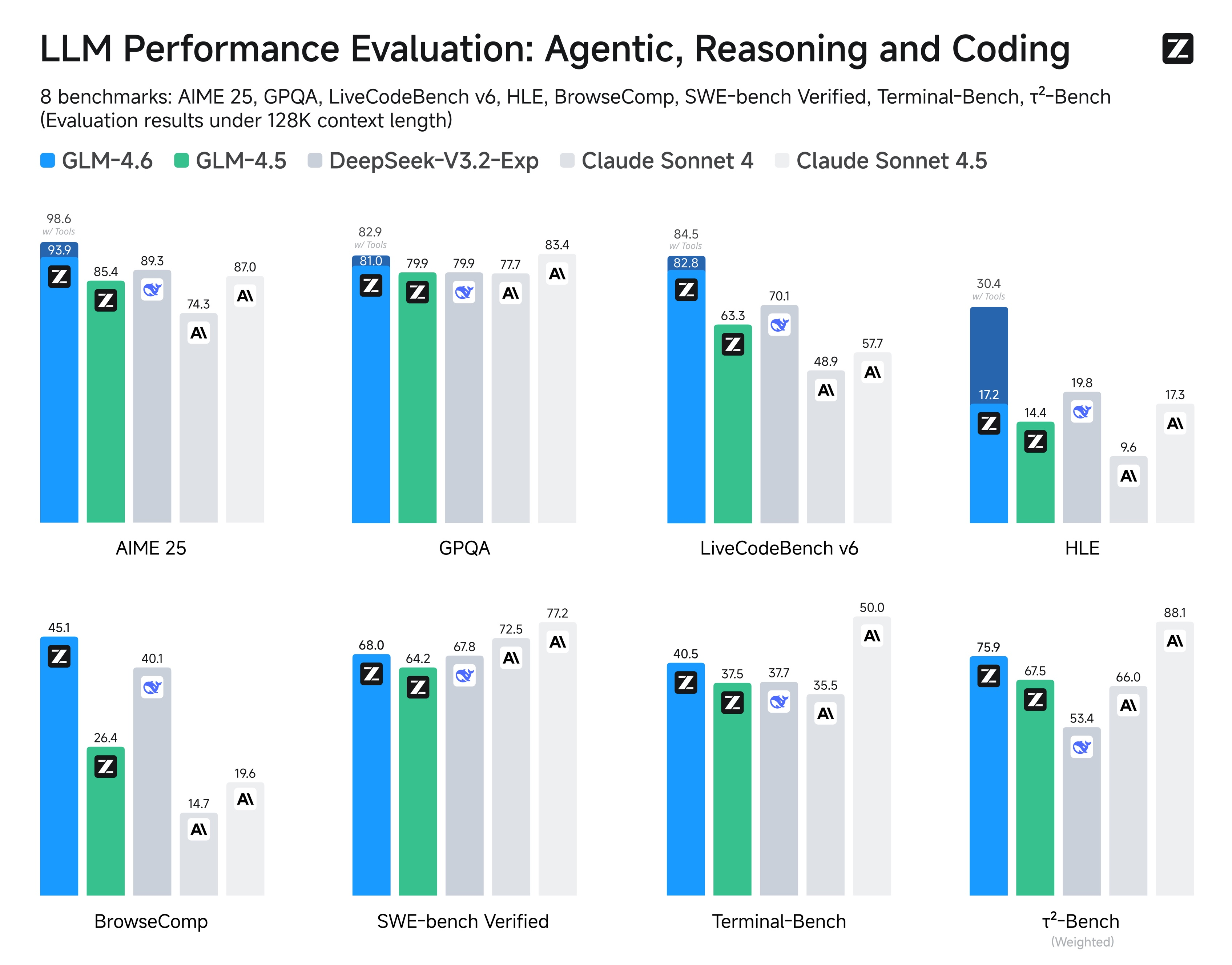
我们在涵盖智能体、推理和代码的八大公开基准上评估了GLM-4.6。结果显示其相对GLM-4.5有明显提升,对比DeepSeek-V3.2-Exp和Claude Sonnet 4等国内外领先模型也具备竞争优势,但在代码能力上仍落后于Claude Sonnet 4.5。
实际经验比排行榜更重要。我们在GLM-4.5基础上扩展了CC-Bench评估框架,新增更具挑战性的任务:人类评估员在隔离的Docker容器中与模型协作,完成跨前端开发、工具构建、数据分析、测试和算法的多轮现实任务。GLM-4.6相较GLM-4.5实现显著提升,达到与Claude Sonnet 4近乎持平水平(48.6%胜率),明显优于其他开源基线模型。从token效率维度看,GLM-4.6完成任务所需token数量比GLM-4.5减少约15%,展现出能力与效率的双重提升。所有评估细节和任务轨迹数据已开源供社区研究:https://huggingface.co/datasets/zai-org/CC-Bench-trajectories
使用GLM-4.6编码代理
GLM-4.6现已可在编码代理中使用(包括Claude Code、Kilo Code、Roo Code、Cline等)。
GLM编码计划订阅用户:您将自动升级至GLM-4.6。若您此前自定义过应用配置(如Claude Code中的~/.claude/settings.json文件),只需将模型名称更新为"glm-4.6"即可完成升级。
本地部署GLM-4.6
GLM-4.6模型权重已公开发布在HuggingFace和ModelScope平台。针对本地部署场景,GLM-4.6支持包括vLLM和SGLang在内的多种推理框架。完整的部署指南详见官方GitHub代码库。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)