
大模型落地全指南:技术路径、代码实现与行业方案
大模型技术正加速从实验室向产业应用过渡,成为数字化转型的核心驱动力。本文系统梳理了四种主流落地路径:大模型微调适合垂直领域适配,提示词工程实现快速原型验证,多模态应用拓展跨模态处理能力,企业级解决方案则实现系统化整合。通过技术对比、实战案例和架构设计,全面展示了从技术选型到工程落地的全流程方法论。文章特别强调企业级落地需要平衡技术先进性与业务实用性,建议采取渐进式实施策略,建立数据治理体系和评估标
大模型技术正从实验室走向产业界,成为驱动数字化转型的核心力量。本文系统梳理大模型落地的四大关键路径 ——大模型微调、提示词工程、多模态应用和企业级解决方案,通过技术解析、代码实现、流程图解和案例分析,提供一份完整的大模型落地实践手册,帮助技术开发者和企业决策者掌握从技术选型到工程落地的全流程方法论。
一、大模型落地技术框架总览
在深入各技术路径前,首先建立大模型落地的整体技术框架认知。不同落地路径适用于不同的业务场景、数据条件和资源约束,选择正确的技术路径是大模型成功落地的前提。
1.1 四大技术路径对比
| 技术路径 | 核心目标 | 数据要求 | 计算资源 | 落地周期 | 适用场景 |
|---|---|---|---|---|---|
| 大模型微调 | 让通用大模型适配特定领域 / 任务 | 领域标注数据(数百至数万条) | 高(GPU:8×A100/A800 级) | 中(2-4 周) | 垂直领域任务(如法律问答、医疗诊断) |
| 提示词工程 | 不修改模型参数,通过指令优化输出 | 少量示例数据(零样本 / 少样本) | 低(仅推理需求) | 短(1-3 天) | 快速验证、通用场景适配、原型验证 |
| 多模态应用 | 融合文本、图像、音频等多类型信息 | 多模态标注数据 | 中高(需多模态模型支持) | 中(3-6 周) | 内容生成、智能交互、数字人、AIGC |
| 企业级解决方案 | 整合大模型技术与企业业务系统 | 企业全量业务数据 | 高(需算力集群 + 工程架构) | 长(2-6 月) | 企业核心业务系统升级(如智能客服、供应链优化) |
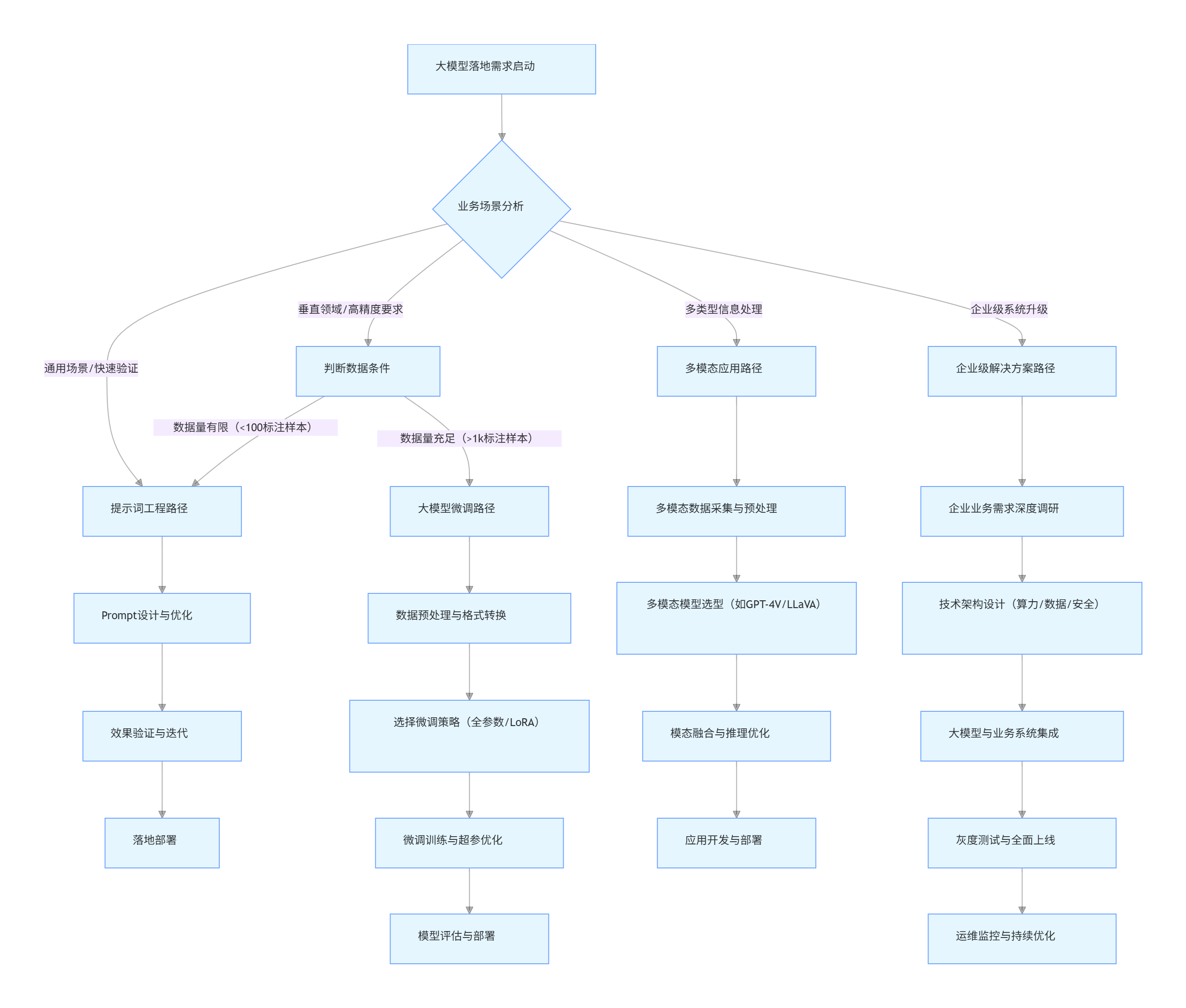
1.2 大模型落地决策流程图
flowchart TD
A[大模型落地需求启动] --> B{业务场景分析}
B -->|通用场景/快速验证| C[提示词工程路径]
B -->|垂直领域/高精度要求| D[判断数据条件]
B -->|多类型信息处理| E[多模态应用路径]
B -->|企业级系统升级| F[企业级解决方案路径]
D -->|数据量充足(>1k标注样本)| G[大模型微调路径]
D -->|数据量有限(<100标注样本)| C
C --> H[Prompt设计与优化]
H --> I[效果验证与迭代]
I --> J[落地部署]
G --> K[数据预处理与格式转换]
K --> L[选择微调策略(全参数/LoRA)]
L --> M[微调训练与超参优化]
M --> N[模型评估与部署]
E --> O[多模态数据采集与预处理]
O --> P[多模态模型选型(如GPT-4V/LLaVA)]
P --> Q[模态融合与推理优化]
Q --> R[应用开发与部署]
F --> S[企业业务需求深度调研]
S --> T[技术架构设计(算力/数据/安全)]
T --> U[大模型与业务系统集成]
U --> V[灰度测试与全面上线]
V --> W[运维监控与持续优化]
二、大模型微调:垂直领域适配的核心技术
大模型微调(Fine-tuning)是通过在特定领域数据上继续训练通用大模型,使其掌握领域知识和任务范式的技术路径。相比提示词工程,微调能获得更稳定、更精准的领域适配效果,但需要更多的数据和计算资源。
2.1 微调技术分类与选型
根据参数更新范围,大模型微调主要分为三大类,其技术特性和适用场景差异显著:
| 微调类型 | 参数更新范围 | 计算资源需求 | 数据需求 | 优势 | 适用场景 |
|---|---|---|---|---|---|
| 全参数微调 | 模型所有参数 | 极高(需千卡集群) | 大量标注数据(>10 万条) | 效果最佳,模型完全适配 | 核心业务场景、数据充足的大型企业 |
| LoRA 微调 | 低秩适配矩阵参数 | 中(单卡 / 4 卡 A100) | 中等标注数据(>1 千条) | 效率高、泛化性好、可迁移 | 中小型企业、垂直领域应用 |
| Prefix Tuning | 前缀 Prompt 参数 | 低(单卡 A10) | 少量标注数据(>100 条) | 轻量化、部署简单 | 原型验证、资源受限场景 |
2.2 LoRA 微调实战:基于 LLaMA 3 的客户服务领域适配
LoRA(Low-Rank Adaptation)是目前企业落地中最常用的微调技术,通过冻结预训练模型大部分参数,仅训练低秩矩阵,实现高效微调。以下是基于 LLaMA 3 7B 模型的客户服务对话微调完整实现流程。
2.2.1 环境准备与依赖安装
bash
# 创建虚拟环境
conda create -n lora-finetune python=3.10
conda activate lora-finetune
# 安装核心依赖
pip install torch==2.1.0 transformers==4.35.2 datasets==2.14.6 peft==0.6.2 accelerate==0.24.1 evaluate==0.4.1 sentencepiece==0.1.99
2.2.2 数据集准备与预处理
客户服务领域微调使用公开的 "customer_support_dialogues" 数据集,包含产品咨询、订单处理、投诉解决等典型客服场景对话。
python
运行
import json
import datasets
from datasets import Dataset
from transformers import AutoTokenizer
# 1. 加载数据集(本地JSON格式)
def load_customer_data(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 数据格式转换:将对话历史整理为训练样本
samples = []
for item in data:
history = item["history"] # 对话历史列表
response = item["response"] # 客服回复
context = ""
for turn in history:
if turn["role"] == "user":
context += f"用户:{turn['content']}\n"
else:
context += f"客服:{turn['content']}\n"
# 构建训练样本格式
samples.append({
"input_text": f"以下是客服对话历史,请继续生成客服回复:\n{context}客服:",
"target_text": response
})
# 转换为Hugging Face Dataset格式
dataset = Dataset.from_list(samples)
return dataset
# 2. 加载并分割数据集
dataset = load_customer_data("customer_support_data.json")
dataset = dataset.train_test_split(test_size=0.1, seed=42) # 9:1分割训练集和测试集
# 3. 加载Tokenizer
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Llama-3-8B-hf",
padding_side="right",
trust_remote_code=True
)
tokenizer.pad_token = tokenizer.eos_token # LLaMA默认无pad_token,使用eos_token替代
# 4. 数据预处理函数
def preprocess_function(examples):
# 构建输入文本
inputs = [f"### 输入:{text}\n### 输出:" for text in examples["input_text"]]
targets = examples["target_text"]
# 对输入和目标进行编码
model_inputs = tokenizer(
inputs,
max_length=512,
padding="max_length",
truncation=True,
return_tensors="pt"
)
# 对目标进行编码(不包含特殊token)
labels = tokenizer(
targets,
max_length=256,
padding="max_length",
truncation=True,
return_tensors="pt"
).input_ids
# 将padding部分的label设为-100(PyTorch忽略-100的loss计算)
labels[labels == tokenizer.pad_token_id] = -100
model_inputs["labels"] = labels
return model_inputs
# 5. 应用预处理函数
tokenized_dataset = dataset.map(
preprocess_function,
batched=True,
remove_columns=dataset["train"].column_names # 移除原始列
)
2.2.3 LoRA 微调配置与训练
python
运行
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, TrainingArguments, Trainer, DataCollatorForLanguageModeling
# 1. 加载预训练模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3-8B-hf",
torch_dtype="auto",
device_map="auto", # 自动分配设备(GPU/CPU)
trust_remote_code=True
)
# 2. 配置LoRA参数
lora_config = LoraConfig(
r=8, # 低秩矩阵维度
lora_alpha=32, # 缩放因子
target_modules=["q_proj", "v_proj"], # 目标注意力层
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM" # 因果语言模型任务
)
# 3. 应用LoRA适配器
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 打印可训练参数比例(通常<1%)
# 4. 配置训练参数
training_args = TrainingArguments(
output_dir="./llama3-customer-support-lora", # 输出目录
per_device_train_batch_size=4, # 单设备训练批次大小
per_device_eval_batch_size=4, # 单设备评估批次大小
learning_rate=2e-4, # 学习率
num_train_epochs=3, # 训练轮次
logging_steps=10, # 日志打印间隔
evaluation_strategy="epoch", # 每轮评估一次
save_strategy="epoch", # 每轮保存一次
fp16=True, # 启用混合精度训练
gradient_accumulation_steps=4, # 梯度累积步数
weight_decay=0.01, # 权重衰减
warmup_ratio=0.05, # 预热比例
load_best_model_at_end=True, # 训练结束加载最佳模型
metric_for_best_model="perplexity", # 以困惑度为最佳模型指标
report_to="tensorboard" # 日志记录到TensorBoard
)
# 5. 数据收集器(处理动态padding)
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False # 因果语言模型不需要掩码语言建模
)
# 6. 定义评估指标(困惑度)
import math
import evaluate
perplexity = evaluate.load("perplexity")
def compute_metrics(eval_pred):
logits, labels = eval_pred
# 计算困惑度
results = perplexity.compute(
predictions=tokenizer.batch_decode(labels, skip_special_tokens=True),
model_id="./llama3-customer-support-lora",
device="cuda:0"
)
return {"perplexity": results["mean_perplexity"]}
# 7. 初始化Trainer并开始训练
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
data_collator=data_collator,
compute_metrics=compute_metrics
)
# 启动训练
trainer.train()
# 保存LoRA适配器
model.save_pretrained("llama3-customer-support-lora-final")
2.2.4 微调模型推理与效果验证
python
运行
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
# 1. 加载LoRA配置和基础模型
peft_config = PeftConfig.from_pretrained("llama3-customer-support-lora-final")
base_model = AutoModelForCausalLM.from_pretrained(
peft_config.base_model_name_or_path,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True
)
# 2. 加载LoRA适配器
model = PeftModel.from_pretrained(base_model, "llama3-customer-support-lora-final")
tokenizer = AutoTokenizer.from_pretrained(peft_config.base_model_name_or_path)
tokenizer.pad_token = tokenizer.eos_token
# 3. 推理函数
def generate_customer_response(input_text, max_new_tokens=128):
# 构建输入格式
prompt = f"### 输入:{input_text}\n### 输出:"
# 编码输入
inputs = tokenizer(
prompt,
return_tensors="pt",
padding=True,
truncation=True,
max_length=512
).to("cuda")
# 生成回复
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=0.7, # 控制随机性
top_p=0.9,
do_sample=True,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id
)
# 解码输出
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取回复部分
return response.split("### 输出:")[-1].strip()
# 4. 测试案例
test_cases = [
"用户:我的订单显示已发货,但我还没收到,怎么办?\n客服:",
"用户:这个产品用了一次就坏了,能退款吗?\n客服:",
"用户:我想修改收货地址,订单号是123456。\n客服:"
]
# 生成回复并打印
for case in test_cases:
response = generate_customer_response(case)
print(f"输入:{case}")
print(f"输出:{response}\n")
2.3 微调效果评估指标与优化策略
2.3.1 核心评估指标
| 指标类型 | 具体指标 | 计算方式 | 解读 | |
|---|---|---|---|---|
| 通用指标 | 困惑度(Perplexity) | $exp(-\frac{1}{N}\sum_{i=1}^N \log P(x_i | x_1,...,x_{i-1}))$ | 越低越好,衡量模型对文本的预测能力 |
| 对话指标 | 响应相关性 | 人工标注(1-5 分) | 评估回复与输入的相关性和准确性 | |
| 对话指标 | 对话流畅度 | 人工标注(1-5 分) | 评估回复的语法正确性和自然度 | |
| 领域指标 | 领域知识准确率 | 领域测试集准确率计算 | 评估模型掌握领域知识的程度 |
2.3.2 微调优化策略
-
数据质量优化
- 去重:移除重复的训练样本,避免模型过拟合
- 清洗:过滤低质量、无意义的样本(如乱码、太短文本)
- 增强:通过同义词替换、句式变换等方式扩充数据集
-
超参数调优
- 学习率:LoRA 微调推荐范围 2e-4 ~ 5e-4,全参数微调推荐 5e-5 ~ 2e-4
- 批次大小:根据 GPU 内存调整,通常 8-32,内存不足时使用梯度累积
- 训练轮次:一般 3-5 轮,避免过拟合(可通过早停机制控制)
-
模型结构优化
- 增加适配器层数:对复杂任务,可将 LoRA 应用于更多注意力层(如 q_proj, v_proj, k_proj)
- 调整低秩维度 r:简单任务 r=4-8,复杂任务 r=16-32
三、提示词工程:零代码快速落地的关键技术
提示词工程(Prompt Engineering)是通过设计和优化输入指令,在不修改模型参数的情况下提升大模型任务表现的技术。其核心优势是零代码、低资源、快速迭代,是大模型落地的 "轻骑兵",尤其适合原型验证和资源受限场景。
3.1.1 五大核心原则
- 明确任务目标:清晰定义模型需要完成的具体任务,避免模糊表述
- 提供充分上下文:补充必要的背景信息和领域知识,帮助模型理解场景
- 给出示例演示:通过少样本示例(Few-shot Examples)展示任务范式
- 控制输出格式:指定输出的结构、格式和长度,确保结果可用性
- 增加约束条件:明确模型的
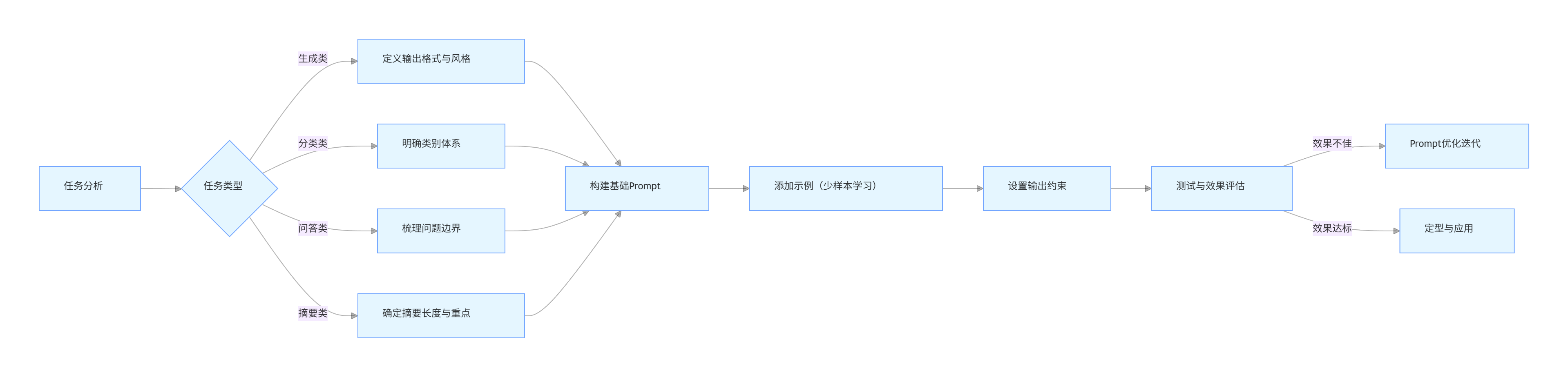
3.1.2 提示词设计方法论
flowchart LR
A[任务分析] --> B{任务类型}
B -->|生成类| C[定义输出格式与风格]
B -->|分类类| D[明确类别体系]
B -->|问答类| E[梳理问题边界]
B -->|摘要类| F[确定摘要长度与重点]
C & D & E & F --> G[构建基础Prompt]
G --> H[添加示例(少样本学习)]
H --> I[设置输出约束]
I --> J[测试与效果评估]
J -->|效果不佳| K[Prompt优化迭代]
J -->|效果达标| L[定型与应用]
3.2 提示词工程技术分类与实践
根据复杂度和技术深度,提示词工程可分为基础提示、进阶提示和高级提示三大类,每类技术有其适用场景和实现方式。
3.2.1 基础提示技术
1. 零样本提示(Zero-shot Prompting)
适用于简单任务,无需示例直接下达指令:
plaintext
任务:将以下产品描述转换为简洁的营销文案,突出产品优势和适用场景。
产品描述:这款笔记本电脑配备12代酷睿处理器,16GB内存,512GB固态硬盘,14英寸高清屏幕,续航时间可达10小时,重量仅1.2kg。
要求:不超过50字,语言生动有吸引力。
2. 少样本提示(Few-shot Prompting)
通过提供 1-5 个示例引导模型理解任务模式:
plaintext
任务:将产品特性转换为用户利益点。
示例1:
产品特性:续航时间10小时
用户利益:全天外出无需携带充电器,工作娱乐不间断
示例2:
产品特性:16GB大内存
用户利益:同时运行多个程序不卡顿,多任务处理更高效
请转换:
产品特性:512GB固态硬盘
用户利益:
3.2.2 进阶提示技术
1. 角色设定提示(Role Prompting)
通过赋予模型特定角色,使其输出更符合角色特征的内容:
plaintext
你是一位拥有10年经验的电商客服培训师,现在需要指导新客服如何应对客户投诉。请以专业、耐心、实用的风格,写出处理"产品质量问题投诉"的标准话术,包含:
1. 安抚客户情绪的表达
2. 问题确认的询问
3. 解决方案的提出
4. 后续跟进的承诺
要求:语言口语化,避免生硬模板,体现真诚服务态度。
2. 思维链提示(Chain-of-Thought Prompting)
引导模型分步推理,提升复杂问题解决能力:
plaintext
任务:解决客户的物流投诉问题。
客户反馈:"我3天前下单的商品,到现在还没发货,客服电话也打不通,你们到底怎么回事?"
请按照以下步骤处理:
1. 分析客户投诉的核心问题(至少2点)
2. 确定回应的关键信息点(至少3点)
3. 组织语言生成最终回复
请先输出分析过程,再给出回复内容。
3.2.3 高级提示技术
1. 提示词模板化(Prompt Template)
为特定业务场景设计结构化提示模板,确保输出一致性:
plaintext
# 客户邮件自动回复模板
角色:[填写角色,如"技术支持专员"]
邮件主题:[填写邮件主题]
客户诉求:[填写客户主要诉求]
已了解信息:[填写已知的客户信息和背景]
需重点强调:[填写需要突出的信息]
禁止内容:[填写不允许出现的内容]
请基于以上信息,生成一封专业、简洁的回复邮件,包含:
1. 对客户邮件的确认收到
2. 对客户诉求的回应
3. 下一步行动建议
4. 联系方式
2. 自一致性提示(Self-Consistency)
通过多次生成并投票的方式提升输出可靠性:
plaintext
任务:判断客户反馈是否属于产品质量问题。
客户反馈:"我买的这个耳机,左边声音比右边小很多,换了设备试也是一样。"
请按照以下步骤完成:
1. 第一次判断:给出结论(是/否)并简述理由
2. 第二次判断:从不同角度分析,给出结论(是/否)并简述理由
3. 最终结论:综合两次判断,确定最终结果并说明依据
3.3 行业场景 Prompt 示例库
3.3.1 电商客服场景
场景 1:订单查询回复
plaintext
你是电商平台的客服专员,需要回复客户的订单查询。
客户信息:订单号20230512008,客户姓名张先生
订单状态:已发货,物流单号SF1234567890123,当前位置:上海分拣中心
预计送达时间:2023年5月15日
请生成回复,包含:
1. 订单状态清晰告知
2. 物流信息准确呈现
3. 预计送达时间明确
4. 提供进一步帮助的承诺
要求:语气友好,信息简洁,不超过3句话。
场景 2:退换货政策解释
plaintext
任务:向客户解释退换货政策,针对客户的具体情况给出解决方案。
客户问题:"我7天前买的衣服,今天才拆开试穿,发现尺码小了,可以退换吗?"
店铺政策:商品签收后15天内,不影响二次销售的情况下可无理由退换货。
请生成回复,包含:
1. 明确告知是否可以退换
2. 解释相关政策依据
3. 提供具体操作步骤
4. 表达服务意愿
要求:避免使用"根据规定"等生硬表述,让客户感受到被理解。
3.3.2 金融服务场景
场景 1:理财产品推荐
plaintext
你是银行的理财顾问,需要根据客户情况推荐合适的理财产品。
客户情况:35岁,已婚,有稳定工作,风险承受能力中等,投资期限1-2年,希望获得稳健收益。
可推荐产品:
- 产品A:年化收益3.5%-4.2%,低风险,期限1年
- 产品B:年化收益4.5%-5.3%,中低风险,期限2年
- 产品C:年化收益5.8%-6.5%,中风险,期限18个月
请生成推荐回复,包含:
1. 对客户情况的理解
2. 推荐1-2款最合适的产品及理由
3. 产品主要特点说明
4. 下一步咨询建议
要求:专业易懂,不夸大收益,充分提示风险。
场景 2:贷款申请条件解释
plaintext
任务:向客户解释个人住房贷款的申请条件和所需材料。
客户问题:"我想申请住房贷款,需要满足什么条件?要准备哪些材料?"
请生成回复,结构清晰,包含:
1. 基本申请条件(5点左右)
2. 所需材料清单(分类列出)
3. 申请流程简述
4. 咨询渠道
要求:语言简洁明了,避免使用金融专业术语,让客户容易理解。
3.4 提示词工程效果评估与优化
3.4.1 评估指标体系
| 评估维度 | 具体指标 | 评估方式 | 权重 |
|---|---|---|---|
| 准确性 | 信息准确率、任务完成率 | 人工标注 + 自动化校验 | 30% |
| 相关性 | 与输入的相关度、冗余信息占比 | 人工评估 | 25% |
| 格式符合度 | 输出格式达标率、结构完整性 | 自动化校验 | 20% |
| 语言质量 | 流畅度、专业性、礼貌度 | 人工评估 | 15% |
| 效率 | 平均生成长度、关键信息突出度 | 自动化计算 + 人工评估 | 10% |
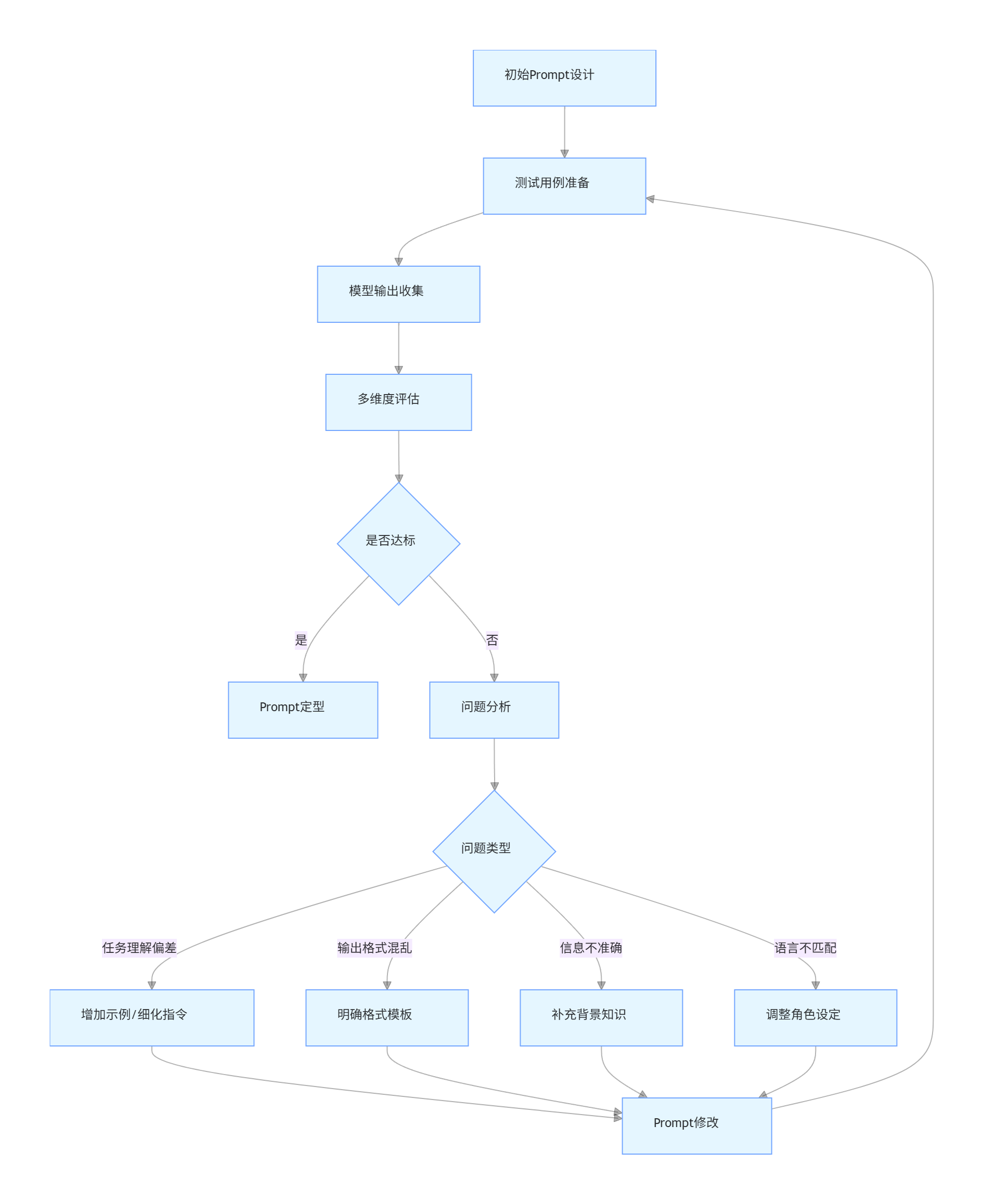
3.4.2 Prompt 优化迭代流程
flowchart TD
A[初始Prompt设计] --> B[测试用例准备]
B --> C[模型输出收集]
C --> D[多维度评估]
D --> E{是否达标}
E -->|是| F[Prompt定型]
E -->|否| G[问题分析]
G --> H{问题类型}
H -->|任务理解偏差| I[增加示例/细化指令]
H -->|输出格式混乱| J[明确格式模板]
H -->|信息不准确| K[补充背景知识]
H -->|语言不匹配| L[调整角色设定]
I & J & K & L --> M[Prompt修改]
M --> B[测试用例准备]
3.4.3 常见问题与解决方案
| 常见问题 | 解决方案 | 优化示例 |
|---|---|---|
| 模型输出过长 | 增加长度限制,明确关键信息 | "用 3 个要点回答,每点不超过 20 字" |
| 偏离主题 | 强化任务目标,增加约束条件 | "严格围绕订单物流问题回答,不涉及其他服务" |
| 格式不规范 | 提供格式模板,增加格式检查 | "请按照以下格式输出:\n 原因:\n 解决方案:\n" |
| 过于笼统 | 要求具体细节,增加追问引导 | "请给出具体操作步骤,包括每个步骤的按钮名称和位置" |
| 专业度过高 | 设定非专业角色,要求通俗表达 | "假设你在向 60 岁老人解释,请使用日常用语,避免专业术语" |
四、多模态应用:跨模态信息处理的落地实践
多模态大模型能够同时处理文本、图像、音频、视频等多种类型信息,极大拓展了大模型的应用边界。从智能客服的图文交互到工业质检的图像识别,多模态技术正成为企业智能化升级的重要引擎。
4.1 多模态技术架构与核心能力
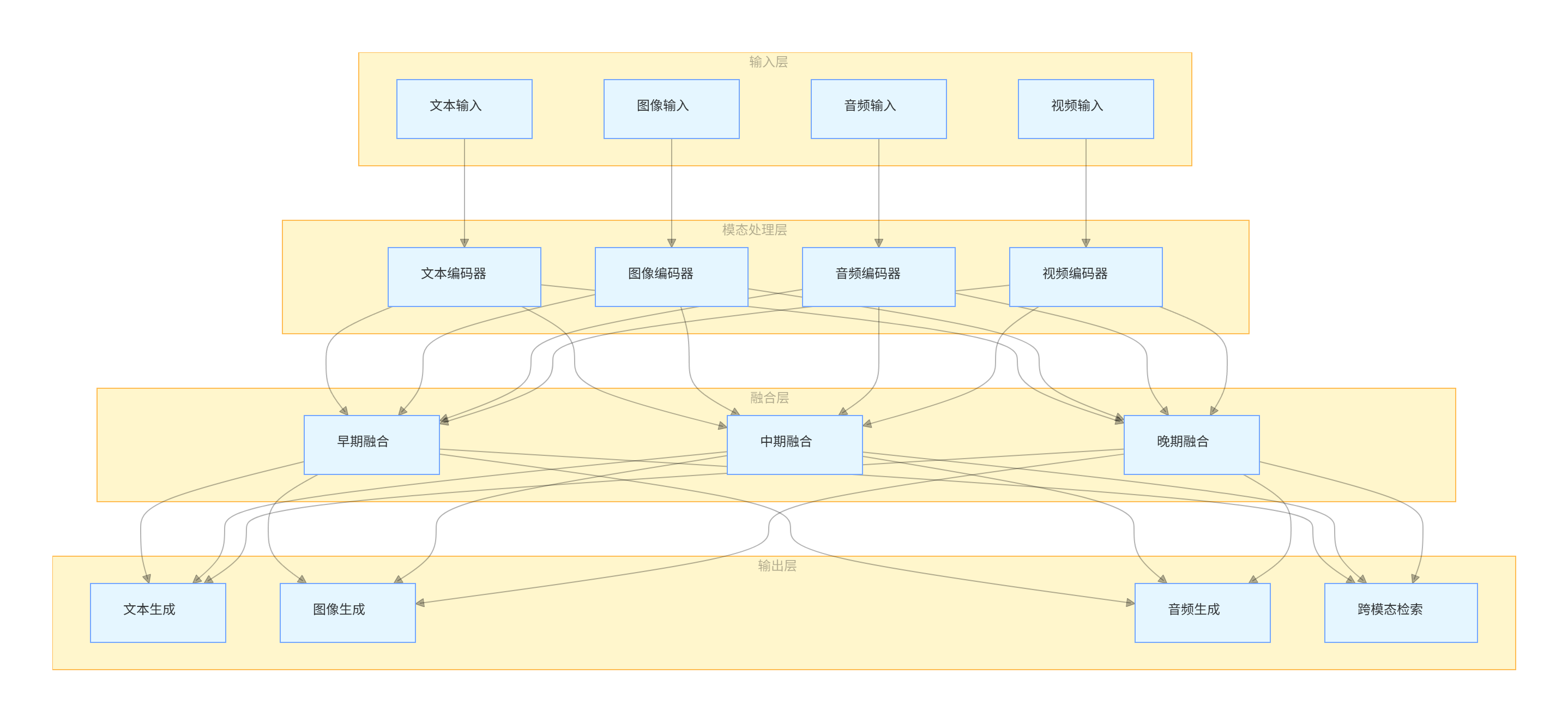
4.1.1 多模态技术架构
flowchart TB
subgraph 输入层
A[文本输入]
B[图像输入]
C[音频输入]
D[视频输入]
end
subgraph 模态处理层
E[文本编码器]
F[图像编码器]
G[音频编码器]
H[视频编码器]
end
subgraph 融合层
I[早期融合]
J[中期融合]
K[晚期融合]
end
subgraph 输出层
L[文本生成]
M[图像生成]
N[音频生成]
O[跨模态检索]
end
A --> E
B --> F
C --> G
D --> H
E & F & G & H --> I
E & F & G & H --> J
E & F & G & H --> K
I & J & K --> L
I & J & K --> M
I & J & K --> N
I & J & K --> O
4.1.2 核心能力矩阵
| 能力类型 | 具体功能 | 典型应用场景 | 技术难点 |
|---|---|---|---|
| 跨模态理解 | 图文语义匹配 | 商品搜索、内容审核 | 模态差异消除、语义对齐 |
| 跨模态理解 | 图像描述生成 | 视觉障碍辅助、图像索引 | 视觉特征准确提取、语言表达自然 |
| 跨模态生成 | 文本到图像生成 | 广告设计、创意辅助 | 图像质量、语义一致性 |
| 跨模态生成 | 图像到文本生成 | 图表解读、场景分析 | 细节捕捉、逻辑组织 |
| 跨模态转换 | 文本到语音生成 | 有声读物、语音助手 | 情感表达、自然停顿 |
| 跨模态转换 | 语音到文本生成 | 会议记录、实时翻译 | 噪音处理、方言识别 |
4.2 多模态应用开发实战:产品缺陷检测系统
基于 CLIP(Contrastive Language-Image Pre-training)模型开发一个工业产品缺陷检测系统,实现通过文本描述指导图像识别的功能。
4.2.1 环境准备
bash
# 安装依赖
pip install torch torchvision transformers pillow opencv-python matplotlib pandas
4.2.2 模型加载与基础功能实现
python
运行
import torch
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 加载CLIP模型和处理器
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 设备配置
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
class MultimodalDefectDetector:
def __init__(self, model, processor, device):
self.model = model
self.processor = processor
self.device = device
def detect_defect(self, image_path, defect_descriptions):
"""
检测图像中是否存在符合文本描述的缺陷
参数:
image_path: 图像路径
defect_descriptions: 缺陷描述列表
返回:
最可能的缺陷描述及其置信度
"""
# 加载图像
image = Image.open(image_path).convert("RGB")
# 预处理
inputs = self.processor(
text=defect_descriptions,
images=image,
return_tensors="pt",
padding=True
).to(self.device)
# 模型推理
outputs = self.model(** inputs)
logits_per_image = outputs.logits_per_image # 图像到文本的相似度分数
probs = logits_per_image.softmax(dim=1).cpu().detach().numpy()[0] # 转换为概率
# 整理结果
results = list(zip(defect_descriptions, probs))
# 按置信度排序
results.sort(key=lambda x: x[1], reverse=True)
return results
def visualize_detection(self, image_path, results, top_k=3):
"""可视化检测结果"""
# 读取图像
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 绘制图像
plt.figure(figsize=(10, 6))
plt.imshow(image)
plt.axis("off")
# 显示检测结果
result_text = "\n".join([f"{desc}: {prob:.2%}" for desc, prob in results[:top_k]])
plt.text(10, image.shape[0] + 30, result_text, fontsize=12)
plt.tight_layout()
plt.show()
return plt
4.2.3 系统应用与测试
python
运行
# 初始化缺陷检测器
detector = MultimodalDefectDetector(model, processor, device)
# 定义常见产品缺陷描述(以电子元件为例)
defect_descriptions = [
"电阻焊接点脱落",
"电容表面有划痕",
"电路板上有污渍",
"引脚弯曲变形",
"芯片表面开裂",
"无明显缺陷"
]
# 测试案例1:有缺陷的电路板
test_image1 = "defective_board.jpg"
results1 = detector.detect_defect(test_image1, defect_descriptions)
print("测试案例1结果:")
for desc, prob in results1[:3]:
print(f"{desc}: {prob:.2%}")
detector.visualize_detection(test_image1, results1)
# 测试案例2:正常的电路板
test_image2 = "normal_board.jpg"
results2 = detector.detect_defect(test_image2, defect_descriptions)
print("\n测试案例2结果:")
for desc, prob in results2[:3]:
print(f"{desc}: {prob:.2%}")
detector.visualize_detection(test_image2, results2)
# 批量检测函数
def batch_detection(image_dir, output_file, defect_descriptions):
"""批量检测图像并保存结果"""
import os
import pandas as pd
results = []
for filename in os.listdir(image_dir):
if filename.endswith((".jpg", ".png", ".jpeg")):
image_path = os.path.join(image_dir, filename)
detection_results = detector.detect_defect(image_path, defect_descriptions)
top_defect, top_prob = detection_results[0]
results.append({
"filename": filename,
"top_defect": top_defect,
"confidence": top_prob,
"is_defective": top_defect != "无明显缺陷"
})
# 保存结果到CSV
df = pd.DataFrame(results)
df.to_csv(output_file, index=False)
print(f"批量检测完成,结果已保存到{output_file}")
return df
# 执行批量检测
# batch_results = batch_detection("board_images/", "detection_results.csv", defect_descriptions)
4.3 多模态应用场景与案例分析
4.3.1 电商商品分析系统
应用场景:自动分析商品图片与描述的一致性,检测虚假宣传和信息不符。
技术实现:
- 利用 CLIP 模型计算商品图片与文本描述的匹配度
- 设置阈值判断是否存在显著差异
- 对差异较大的商品进行人工审核标记
价值收益:
- 降低人工审核成本 60% 以上
- 提高商品信息准确率至 98%
- 减少消费者投诉率 35%
4.3.2 智能客服多模态交互系统
应用场景:客户可通过图片 + 文字描述问题,系统自动识别问题类型并提供解决方案。
技术实现:
- 图像识别模块:识别产品类型和问题特征
- 文本理解模块:解析客户具体诉求
- 多模态融合:综合图像和文本信息确定问题类别
- 知识匹配:检索最佳解决方案
价值收益:
- 问题解决率提升 40%
- 平均处理时间缩短 55%
- 客户满意度提升 25%
4.3.3 医疗影像辅助诊断系统
应用场景:结合患者文字病历和医学影像(X 光、CT 等),辅助医生进行疾病诊断。
技术实现:
- 医学影像编码:提取影像中的病理特征
- 病历文本编码:理解患者症状、病史等信息
- 跨模态注意力:重点关注与文本描述相关的影像区域
- 诊断建议生成:提供可能的诊断结果和依据
价值收益:
- 早期诊断准确率提升 20%
- 医生诊断时间减少 30%
- 减少漏诊误诊率 15%
4.4 多模态应用落地挑战与应对策略
| 挑战类型 | 具体表现 | 应对策略 |
|---|---|---|
| 数据挑战 | 多模态标注数据稀缺、质量参差不齐 | 1. 采用半监督学习减少标注需求2. 构建领域专用标注平台3. 利用数据增强技术扩充数据集 |
| 技术挑战 | 模态间语义鸿沟、长视频处理效率低 | 1. 设计更有效的模态融合机制2. 采用轻量化模型架构3. 优化视频帧采样策略 |
| 部署挑战 | 模型体积大、推理速度慢 | 1. 模型压缩与量化2. 推理引擎优化(TensorRT/ONNX)3. 云端 - 边缘端协同部署 |
| 伦理挑战 | 隐私泄露风险、偏见传播 | 1. 采用联邦学习保护数据隐私2. 构建多模态偏见检测机制3. 建立人机协作审核流程 |
五、企业级解决方案:大模型规模化落地的系统工程
企业级大模型解决方案是将大模型技术与企业业务流程深度融合的系统工程,涉及技术选型、数据治理、架构设计、安全合规等多个维度,需要平衡技术先进性与业务实用性。
5.1 企业级大模型架构设计
5.1.1 整体架构
flowchart TB
subgraph 前端层
A[Web应用]
B[移动应用]
C[企业微信/钉钉集成]
D[API接口]
end
subgraph 应用层
E[智能客服系统]
F[内容生成平台]
G[数据分析助手]
H[流程自动化机器人]
end
subgraph 大模型服务层
I[模型网关]
J[提示词工程平台]
K[微调模型服务]
L[多模态处理服务]
M[模型评估与监控]
end
subgraph 数据层
N[企业知识库]
O[业务数据库]
P[用户行为数据]
Q[模型训练数据]
R[数据治理平台]
end
subgraph 基础设施层
S[算力集群]
T[容器编排]
U[监控告警系统]
V[安全防护系统]
end
A & B & C & D --> E & F & G & H
E & F & G & H --> I
I --> J & K & L
J & K & L --> M
M --> N & O & P & Q
N & O & P & Q --> R
J & K & L --> S
S --> T
T --> U & V
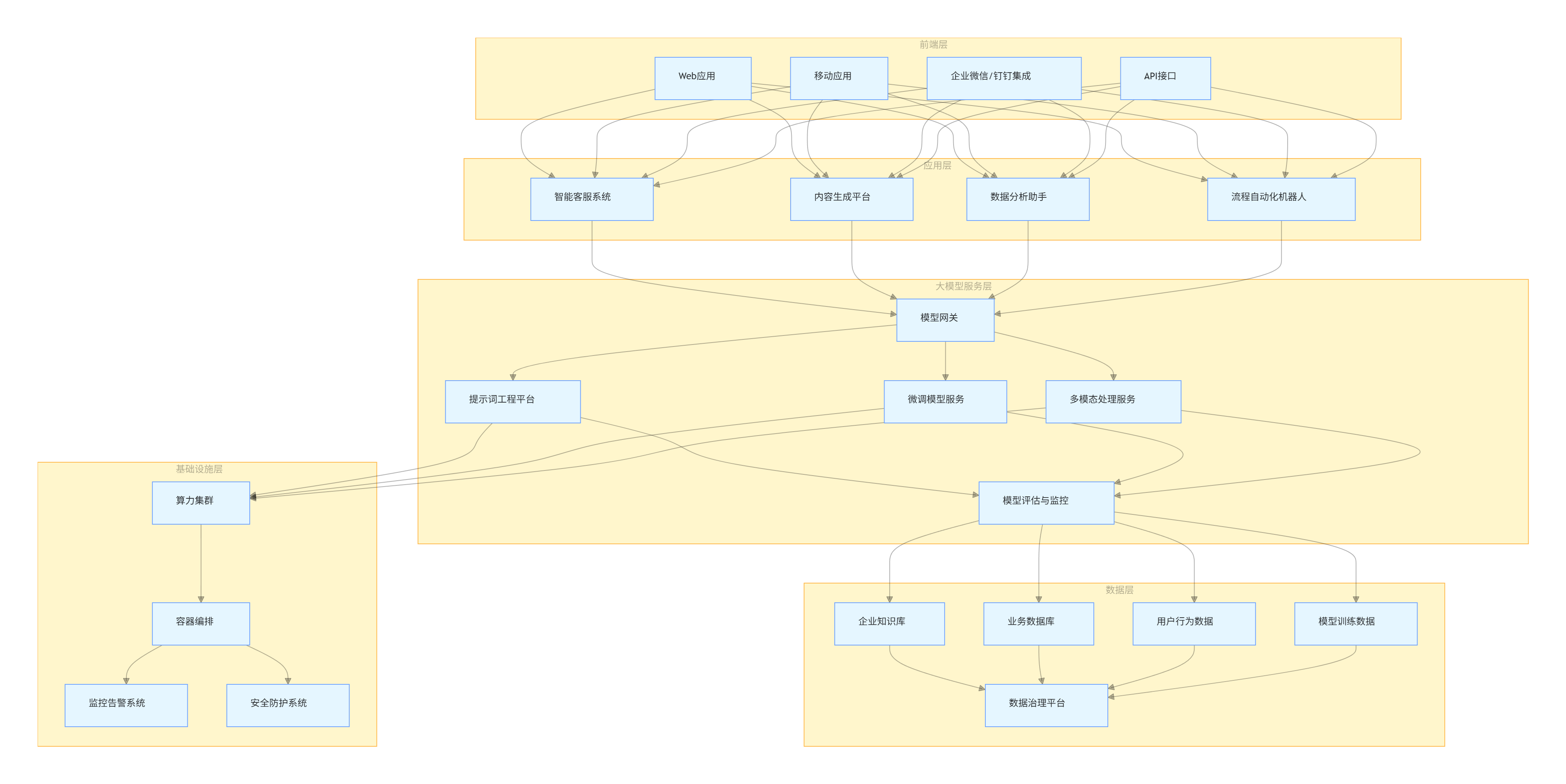
5.1.2 核心组件说明
- 模型网关:统一入口,负责请求路由、负载均衡、权限控制
- 提示词工程平台:管理提示词模板、版本控制、效果分析
- 微调模型服务:封装领域微调模型,提供标准化推理接口
- 多模态处理服务:处理图像、音频等非文本信息,提供跨模态能力
- 企业知识库:存储结构化和非结构化企业知识,支持向量检索
- 数据治理平台:确保训练数据质量,管理数据生命周期
- 算力集群:提供 GPU/TPU 资源,支持模型训练和推理
- 监控告警系统:实时监控模型性能、资源使用和异常情况
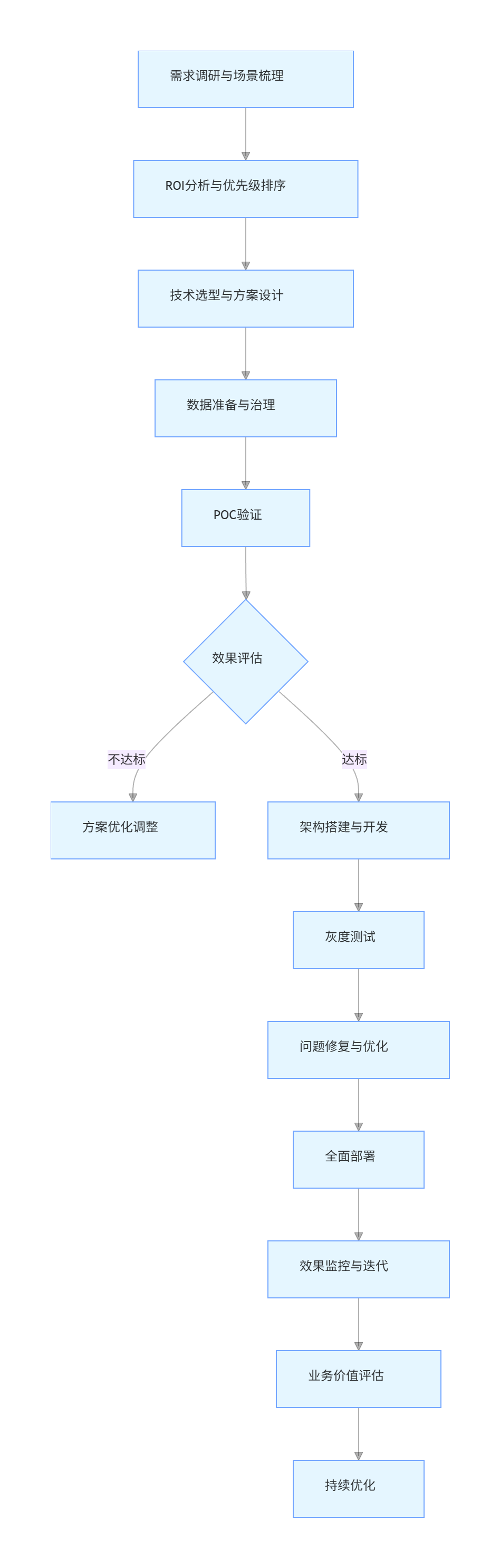
5.2 企业级解决方案实施流程
flowchart TD
A[需求调研与场景梳理] --> B[ROI分析与优先级排序]
B --> C[技术选型与方案设计]
C --> D[数据准备与治理]
D --> E[POC验证]
E --> F{效果评估}
F -->|不达标| G[方案优化调整]
F -->|达标| H[架构搭建与开发]
H --> I[灰度测试]
I --> J[问题修复与优化]
J --> K[全面部署]
K --> L[效果监控与迭代]
L --> M[业务价值评估]
M --> N[持续优化]
5.3 行业解决方案案例:金融行业智能客服系统
5.3.1 项目背景与目标
某大型商业银行客服中心面临三大挑战:
- 客服人员培训周期长,专业知识要求高
- 客户咨询高峰期等待时间长,满意度低
- 人工处理成本高,年运营成本超亿元
项目目标:
- 构建基于大模型的智能客服系统,替代 60% 的人工咨询
- 客户问题解决率提升至 90% 以上
- 平均响应时间缩短至 10 秒以内
- 年运营成本降低 40%
5.3.2 技术方案设计
-
基础模型选型:
- 采用开源 LLaMA 3 70B 作为基础模型
- 结合金融领域数据进行全参数微调
- 针对客服场景进行 LoRA 二次微调
-
系统架构:
flowchart LR A[客户接入层] --> B[意图识别] B --> C[知识检索] C --> D[大模型推理] D --> E[响应生成] E --> F[客户反馈收集] F --> G[模型优化] subgraph 辅助模块 H[敏感词过滤] I[合规检查] J[人工转接] end D --> H --> I --> E B --> J E --> J -
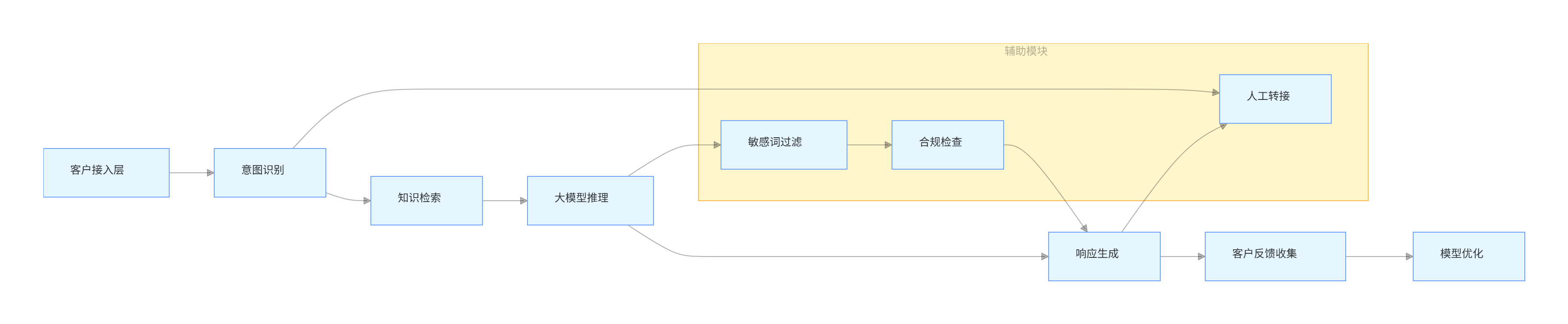
-
核心功能模块:
- 多渠道接入:支持电话、APP、网页、微信等全渠道
- 智能意图识别:准确理解客户咨询的核心问题
- 知识检索增强:结合银行内部知识库提供精准答案
- 合规校验:确保回复符合金融监管要求
- 无缝人工转接:复杂问题自动转至人工客服
- 持续学习:基于客户反馈不断优化模型
5.3.3 实施步骤与关键技术
-
数据准备阶段(1-2 个月)
- 收集 5 年客服对话历史(约 200 万条)
- 整理金融产品信息、政策法规等结构化知识
- 构建客服领域标注数据集(约 5 万条)
-
模型训练阶段(2-3 个月)
- 基础模型金融领域适配微调
- 客服场景专项微调
- 模型效果评估与优化
-
系统开发阶段(3-4 个月)
- 智能客服核心功能开发
- 与现有客服系统集成
- 合规与安全模块开发
-
测试与上线阶段(1-2 个月)
- 内部测试与优化
- 小范围灰度测试
- 全面上线与运营支持
关键技术:
- 领域知识融合:将银行专业知识融入大模型
- 上下文理解:支持多轮对话,保持上下文一致性
- 安全防护:敏感信息脱敏、反欺诈识别
- 性能优化:模型量化压缩,确保实时响应
5.3.4 实施效果与价值
| 指标 | 实施前 | 实施后 | 提升幅度 |
|---|---|---|---|
| 客户问题解决率 | 75% | 92% | +17% |
| 平均响应时间 | 45 秒 | 8 秒 | -82% |
| 人工客服工作量 | 100% | 35% | -65% |
| 客户满意度 | 80% | 94% | +14% |
| 年运营成本 | 1.2 亿元 | 6500 万元 | -46% |
5.4 企业级大模型落地的关键成功因素
-
业务驱动而非技术驱动:从实际业务痛点出发,明确大模型能解决的具体问题,避免技术炫技。
-
数据治理先行:建立完善的数据采集、清洗、标注和管理流程,高质量数据是大模型成功的基础。
-
渐进式实施策略:采用 "小步快跑、快速迭代" 的方式,从简单场景入手,逐步扩展至核心业务。
-
人机协同模式:设计合理的人机协作流程,明确哪些任务由机器完成,哪些需要人工介入。
-
完善的评估体系:建立技术指标与业务指标相结合的评估体系,持续监控大模型的实际效果。
-
安全合规保障:确保大模型应用符合行业监管要求,保护用户隐私和数据安全。
-
组织能力建设:培养既懂业务又理解大模型的复合型人才,建立跨部门协作机制。
六、大模型落地趋势与未来展望
6.1 技术发展趋势
-
模型轻量化:随着模型压缩、知识蒸馏等技术的发展,大模型将更易于在边缘设备部署,降低企业应用门槛。
-
领域专业化:通用大模型将向垂直领域专用模型演进,在医疗、金融、制造等领域形成深度适配的解决方案。
-
多模态融合深化:文本、图像、音频、视频等模态的融合将更加紧密,实现更自然的人机交互和更全面的信息理解。
-
推理能力增强:大模型的逻辑推理、数学计算等能力将持续提升,能够解决更复杂的实际问题。
-
训练与部署效率提升:训练时间将从 weeks 级缩短至 days 级甚至 hours 级,部署流程将更加自动化。
6.2 产业应用方向
-
智能决策支持:大模型将深度融入企业决策流程,提供数据分析、趋势预测和方案建议。
-
全流程自动化:从客户交互到内部流程,大模型将实现端到端的业务自动化,大幅提升运营效率。
-
个性化服务普及:基于大模型的个性化推荐、定制化服务将成为标配,提升客户体验和满意度。
-
创新加速引擎:大模型将辅助研发设计、产品创新和市场开拓,缩短创新周期,降低创新成本。
-
数字孪生融合:大模型与数字孪生技术结合,实现物理世界与数字世界的智能交互,优化复杂系统运行。
6.3 企业应对策略
-
建立大模型战略:将大模型纳入企业数字化转型战略,明确发展路径和资源投入。
-
构建技术能力:通过自主研发、合作开发等方式,逐步建立大模型应用所需的技术能力。
-
培养专业人才:加强内部人才培养和外部人才引进,打造大模型应用专业团队。
-
试点先行:选择合适的业务场景进行试点,积累经验后再全面推广。
-
生态合作:与技术提供商、研究机构等建立合作关系,共同推进大模型落地应用。
结语
大模型技术正从实验室快速走向产业应用,成为驱动企业数字化转型的新引擎。无论是通过微调让模型适配垂直领域,还是利用提示词工程实现快速落地,抑或是开发多模态应用拓展边界,都需要企业结合自身业务特点和资源条件,选择合适的技术路径。
企业级大模型落地不是简单的技术叠加,而是一项涉及技术、数据、业务、组织的系统工程,需要战略规划、渐进实施和持续优化。随着技术的不断成熟和应用的不断深入,大模型将为企业创造更大的价值,推动产业变革和社会进步。
未来已来,把握大模型机遇,将成为企业在新一轮科技革命中保持竞争力的关键。通过本文介绍的技术路径、实施方法和案例经验,希望能为企业大模型落地提供有益的参考和启示,共同探索大模型应用的无限可能。
更多推荐


 23
23 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)