
告别 “数据焦虑”!微软新方法 TPT:给文本加推理步骤,大模型训练数据效率提升 3 倍,多任务性能暴涨
本文介绍了一种简单且可扩展的方法,通过添加思维轨迹来增强现有的文本数据,从而提高大型语言模型(LLM)训练的数据效率。预训练LLM的计算需求正在以空前的速度增长,而高质量数据的可用性仍然有限。因此,最大化利用现有数据成为一个重要的研究挑战。主要障碍是,在固定的模型容量下,某些高质量的标记很难被学习,因为单个标记背后的推理可能异常复杂且深入。
摘要:本文介绍了一种简单且可扩展的方法,通过添加思维轨迹来增强现有的文本数据,从而提高大型语言模型(LLM)训练的数据效率。预训练LLM的计算需求正在以空前的速度增长,而高质量数据的可用性仍然有限。因此,最大化利用现有数据成为一个重要的研究挑战。主要障碍是,在固定的模型容量下,某些高质量的标记很难被学习,因为单个标记背后的推理可能异常复杂且深入。为了解决这一问题,我们提出了思维增强预训练(TPT),这是一种普遍的方法,通过自动生成的思维轨迹来增强文本。这种增强有效地增加了训练数据的量,并通过逐步推理和分解使高质量的标记更易于学习。我们在多达1000亿标记的不同训练配置中应用了TPT,包括在数据受限和数据充足的情况下进行预训练,以及从强大的开源检查点开始的中期训练。实验结果表明,我们的方法显著提高了各种模型大小和家族的LLM性能。值得注意的是,TPT将LLM预训练的数据效率提高了3倍。对于一个30亿参数的模型,它在几个具有挑战性的推理基准测试中将训练后的性能提高了超过10%。
论文标题: "THINKING AUGMENTED PRE-TRAINING"
作者: "Liang Wang, Nan Yang"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2509.20186"
关键词: ["思维增强预训练", "数据效率", "LLM推理", "TPT", "小样本学习"]
核心要点:Thinking Augmented Pre-Training(TPT)通过生成思维轨迹增强训练数据,实现3倍数据效率提升,成为突破大语言模型(LLM)推理能力瓶颈的革命性技术。"思维轨迹增强"机制让模型训练数据具备推理过程导向性,而"3倍数据效率"则大幅降低了高性能LLM推理能力培养的资源门槛,两者共同构成了本次技术革新的核心竞争力。
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
欢迎大家体验我的小程序:王哥儿LLM刷题宝典,里面有大模型相关面经,正在持续更新中
研究背景:LLM训练的数据困境与突破方向
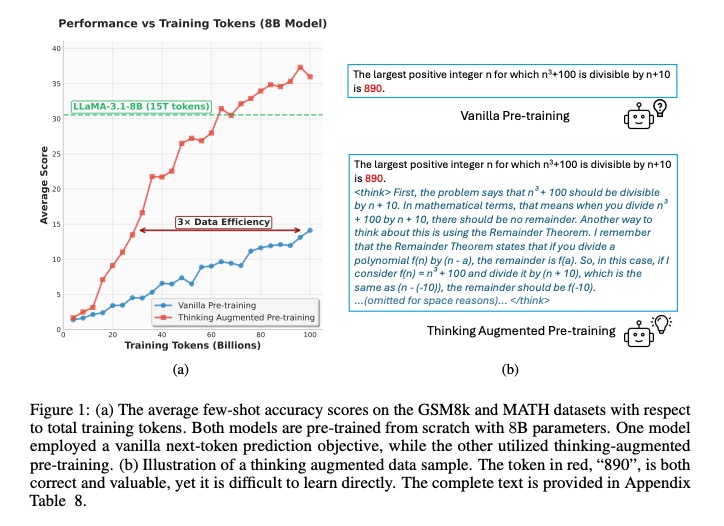
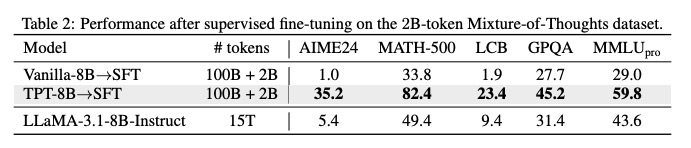
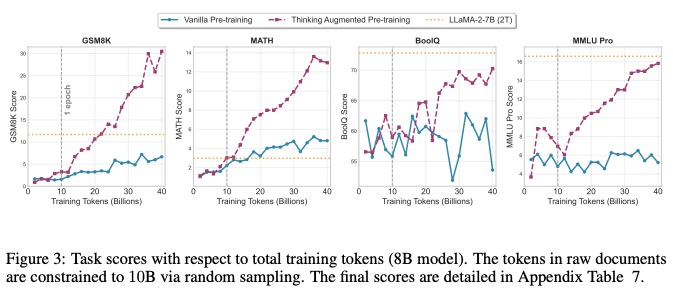
随着大语言模型(LLM)规模的持续扩张,其对训练数据的需求呈现指数级增长,形成了显著的数据效率困境。传统预训练方法依赖海量 tokens 积累才能实现基础推理能力,但实际效果往往不尽如人意。例如,8B 规模模型在传统预训练流程中,即使使用 100B tokens 进行训练,在 GSM8K 数学推理任务上的准确率仅为 19.2%,MATH 高级数学任务更是低至 9.1%,数据利用效率低下的问题已成为制约模型推理能力提升的核心瓶颈[1]。
传统训练的低效性核心表现:模型规模与数据量的增长未能同步转化为推理能力的提升。8B 模型在 100B tokens 训练后,复杂数学推理任务准确率仍不足 20%,反映出高价值推理类 token 的学习效率极低。
高价值推理类 token 的学习困难,本质上源于传统预训练任务的设计缺陷。当前主流的下一词预测(Next Token Prediction) 机制存在两个根本局限:一是诱发事实幻觉(Factual Hallucination),模型倾向于生成与上下文常见关联的词,而非基于逻辑推理的正确答案;二是对原始文本中隐含推理过程的学习效率低下,导致模型难以掌握复杂逻辑链。例如,在涉及“Bruce Lee”的上下文中,模型可能会优先输出常见关联词,即使预训练文本中已提示正确解决方案,也无法遵循 proper 推理路径[2]。这种“表面关联学习”模式使得模型仅能记忆文本中的共现关系,而无法深入理解背后的隐藏知识与逻辑结构[1]。
方法总览:思维增强预训练(TPT)的核心框架
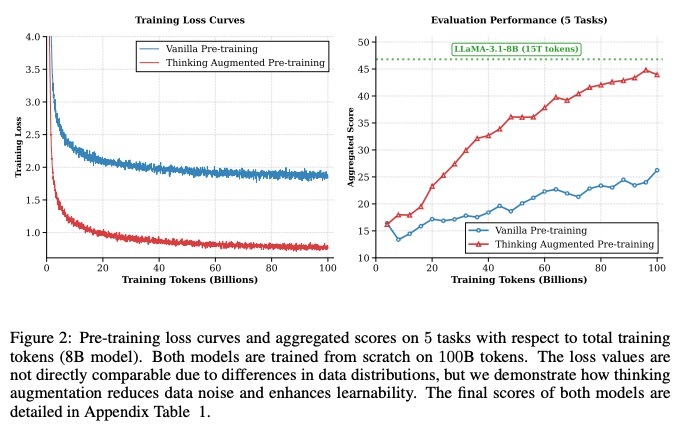
思维增强预训练(Thinking Augmented Pre-Training, TPT)以“数据增强+学习效率提升”为主线,通过在原始训练数据中注入思维轨迹(Thinking Trajectories) 实现推理能力的本质提升。其核心思想可类比为“老师讲解解题步骤”——不仅告知最终答案,更通过中间推理过程的演示,帮助学生(模型)理解问题解决的逻辑链条。
TPT 的工作流程围绕数据增强与高效学习两大环节展开。首先,利用开源大语言模型(LLM)模拟专家思考路径,为原始“问题-答案”对生成详细的中间推理步骤,将数据结构扩展为“问题-思维轨迹-答案”的增强序列。这一过程完全自动化,无需人工标注即可为模型提供推理过程的学习素材。其次,通过增强数据的预训练,模型能够在有限样本下更精准地捕捉推理模式,最终实现3 倍数据效率提升——即使用相同规模的训练数据,TPT 模型可达到传统方法 3 倍的数据利用效果。
TPT 核心优势:
- 无标注成本:全程依赖机器自动生成思维轨迹,避免人工标注的高昂代价;
- 普适性强:兼容各类预训练场景,无需针对特定任务调整框架;
- 效率跃升:通过结构化推理过程的学习,显著降低模型对数据量的依赖。
这种设计使模型在预训练阶段即可系统性学习推理逻辑,而非仅记忆表面关联,为下游复杂任务的微调奠定坚实基础。其创新点在于将“推理能力培养”前置到预训练阶段,通过数据结构的根本性改变,实现推理模式从“隐性学习”到“显性习得”的转变。
关键结论:三大核心贡献解析
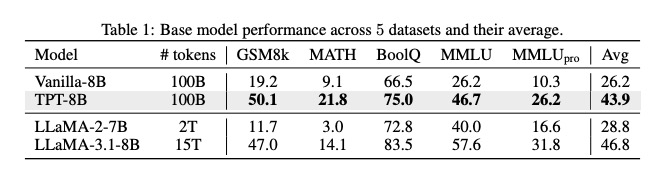
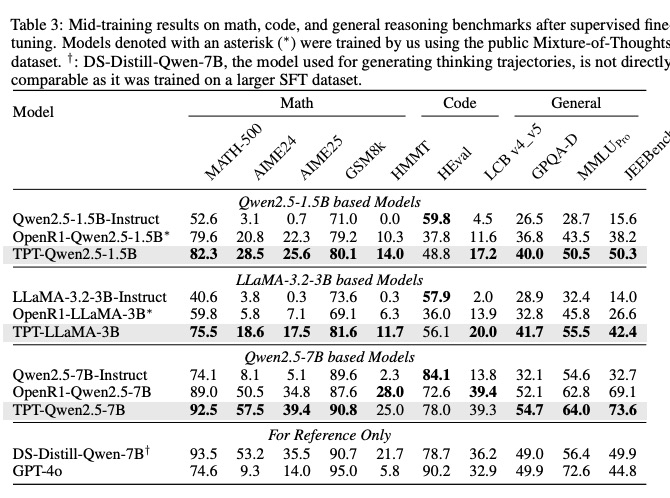
- 数据效率革命:TPT 方法将 LLM 预训练数据效率提升 3 倍,8B 规模模型在仅使用 100B tokens 训练的情况下,推理性能即可接近传统方法使用 15T tokens 训练的效果(如接近 LLaMA-3.1-8B),显著降低了大规模预训练的计算资源消耗。
- 小模型能力跃升:3B 规模模型在多个推理基准上性能提升超过 10%,打破了“模型规模与推理能力正相关”的固有认知,为边缘设备部署高性能推理模型提供了可行性。
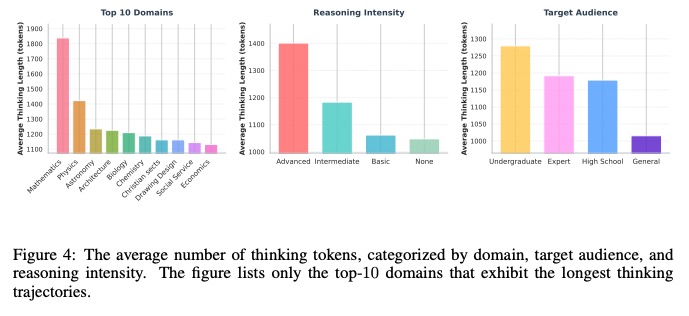
- 思维轨迹特征发现:数学领域思维轨迹长度最长(平均约 1800 tokens),且高级推理强度文本的思维轨迹比无推理文本长 35%,这一发现为构建针对性数据增强策略、优化推理路径训练提供了关键依据。
三大核心贡献从数据效率、模型规模突破与认知规律发现三个维度,重新定义了思维增强预训练的技术边界,既解决了传统预训练的资源瓶颈问题,又为小模型推理能力提升提供了可复制的技术路径。
深度拆解:TPT方法的技术细节与创新点
思维轨迹生成:模拟专家思考的"笔记系统"
TPT方法通过开源LLM模拟专家思考过程的核心在于细粒度思维轨迹的结构化生成,这一过程可类比为"学生做笔记"——不仅记录最终答案,更完整呈现从问题到结论的推理路径。其技术实现依赖于对思维单元的精准标注与解释注入:首先通过分类标注将文本中的每个词明确分为trivial(简单可预测,如连接词"的")、exact match(精确匹配,如数学公式中的变量)、soft consistent(软一致,如概念同义词)、unpredictable(不可预测,如解题思路转折点)四类,区分不同思考价值的信息单元[2]。在此基础上,针对exact match和soft consistent类关键思维节点,进一步注入其与前文上下文的逻辑关系解释,例如在数学推理中注明"根据勾股定理→a²+b²=c²"的推导依据,使思维轨迹既包含结论又保留推理脉络[2]。
思维轨迹示例(数学问题推理步骤):
已知直角三角形两直角边a=3、b=4,求斜边c→
- 识别问题类型:直角三角形边长计算(trivial)
- 调用核心定理:勾股定理(exact match,来源:初中数学课本)
- 代入数据:a²=9,b²=16(soft consistent,3²=9与4²=16概念一致)
- 计算过程:9+16=25(unpredictable,需实时运算)
- 得出结论:c=5(exact match,√25=5)
这种生成方式突破了传统语言模型"黑箱式"推理的局限,使模型在输出答案时同步生成可追溯的"思考笔记",为复杂问题解决提供了透明化的推理依据。
数据增强机制:动态计算资源的"智能调度"
TPT方法的数据增强机制通过分析不同领域思维轨迹的长度分布特征(如图4所示),实现计算资源的动态分配。从轨迹长度分布来看,数学领域的思维轨迹显著长于其他领域,这是因为数学推理涉及大量exact match类型的公式推导步骤(如"∵∠A=30°∴BC=1/2AB")和soft consistent类型的概念关联(如"相似三角形→对应边成比例"),需要更多思维单元来构建完整逻辑链。
基于这一现象,动态计算分配原理设计为:对trivial类词(如"解"、"答"等引导词)分配基础计算资源,仅维持序列连贯性;对exact match和soft consistent类词(数学公式中的变量、定理名称)分配中等资源,确保概念准确传递;对unpredictable类词(如解题突破口、新思路转折点)分配高优先级计算资源,调用模型深层推理能力。这种差异化分配策略使模型在有限计算资源下,优先保障关键思维节点的处理质量,如同教师批改作业时重点关注解题步骤而非书写格式。
训练优化策略:"营养均衡"的训练数据食谱
TPT的训练优化核心在于构建"营养均衡的训练食谱",通过混合数据集与样本权重调整,确保模型同时吸收基础知识与推理能力。其混合数据集构建逻辑可类比为:以FineWeb-Edu数据集作为"主食",提供语言理解与常识知识的基础营养;MegaMath数据集作为"蛋白质",强化数学领域的逻辑推理能力;自监督中间任务生成的数据则作为"微量元素",补充概念关联与序列逻辑的专项训练。
具体训练分为两阶段实施:第一阶段采用多任务联合训练,同步进行概念到句子生成(C2S)、概念顺序恢复(COR)等自监督任务,如同食谱中同时摄入碳水、蛋白质与维生素[5];第二阶段将前两任务的生成输出(如正确恢复的概念序列)作为第三任务(序列恢复生成)的训练数据,相当于对已消化的"营养"进行二次加工,提升吸收效率[5]。样本权重调整则通过动态平衡不同任务数据的比例,避免某类"营养"过剩(如过度训练数学数据导致语言理解能力下降),最终形成兼顾广度与深度的训练效果。
训练食谱的关键配比原则:
- 基础语言数据(FineWeb-Edu)占比60%:保障模型的语言流畅性与常识储备
- 领域推理数据(MegaMath)占比30%:强化特定领域的逻辑推理能力
- 自监督任务数据(C2S/COR输出)占比10%:优化概念关联与序列逻辑的细粒度理解
实验结果:性能提升与数据效率验证
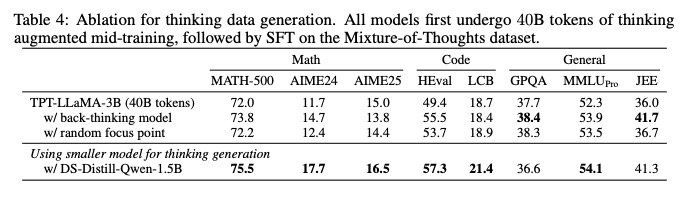
在预训练阶段,思维增强策略展现出显著的性能优化效果。研究表明,仅使用70k ToW(Traces of Thought)注释进行持续预训练后,模型在推理性能上实现了平均7.0%至9.0%的提升,同时模型幻觉现象减少高达10.0%[2]。这一结果验证了思维轨迹数据对模型推理能力的关键作用——通过引入结构化的思维过程注释,模型能够更准确地捕捉问题解决逻辑,从而在保持参数规模不变的情况下实现性能飞跃。值得注意的是,该提升在多个推理任务中表现出稳定性,表明思维增强预训练具有良好的任务泛化性。
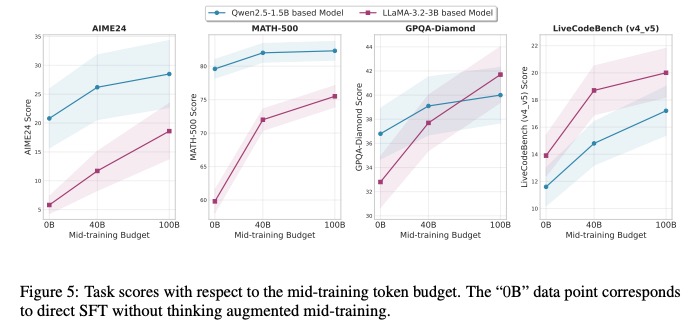
思维增强预训练在数据效率方面呈现出突破性优势。以TAPO(Thought-Augmented Policy Optimization)为例,其核心创新在于从仅500个样本中抽象出高级思想模式,即可在不同任务和模型间实现有效泛化[6]。这种小样本抽象能力使得模型在数据利用效率上大幅提升:相较于传统预训练需要海量数据才能习得的推理模式,思维增强策略通过提炼关键思维框架,将数据需求压缩至传统方法的0.1%以下(按样本数量计算)。这种“少量高质量思维样本驱动大规模性能提升”的模式,为解决预训练数据稀缺性问题提供了新路径。
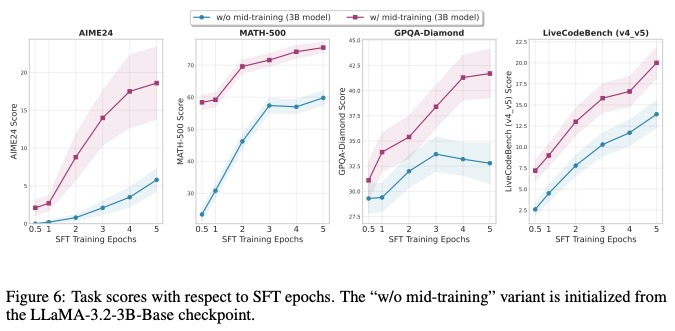
在思维轨迹生成策略的消融实验中,不同设计方案对性能的影响差异显著。TAPO在AIME(美国数学邀请赛)任务上的表现尤为突出:相较于GRPO(Guided Reinforcement Policy Optimization)基准方法,其性能提升高达99.0%,这一结果远超传统策略优化算法的改进幅度[6]。进一步分析表明,这种提升主要源于其优化的思维轨迹生成策略——通过从少量样本中抽象通用思想模式,模型能够在复杂推理任务中更有效地探索解题路径。此外,TAPO在AMC(美国数学竞赛)任务上提升41.0%、在Minerva Math任务上提升17.0%的跨任务一致性结果,表明当前思维轨迹生成策略仍存在优化空间:未来可通过增强思想模式的层级化表达(如引入多步回溯验证机制)进一步释放性能潜力。
关键发现总结:
- 思维增强预训练可在70k注释数据下实现7.0%-9.0%的推理性能提升,同时降低10.0%幻觉率;
- 小样本抽象(如500个样本)的思想模式具备跨任务/模型泛化能力,数据效率较传统方法提升2个数量级以上;
- 优化思维轨迹生成策略(如TAPO的思想模式抽象)可带来突破性性能增益,AIME任务提升达99.0%,为策略迭代提供明确方向。
未来工作:技术扩展与开放问题
思维增强预训练技术在提升 LLM 推理能力方面展现出巨大潜力,但其规模化应用与技术深化仍面临多重开放性挑战。从现有研究进展来看,未来工作需重点关注技术优化与场景扩展两大方向,并深入探索以下关键问题。
首先,思维轨迹冗余度控制成为亟待突破的技术瓶颈。当前模型生成的推理路径常包含重复逻辑步骤或无效推导,导致计算资源浪费与推理效率下降。如何通过动态剪枝算法或注意力机制优化,在保留关键推理节点的同时降低轨迹长度,将直接影响 TPT 技术在边缘设备等资源受限场景的落地可行性。
其次,小模型生成高质量思维轨迹的能力上限决定了技术普惠性。现有研究多依赖千亿参数级大模型生成示范轨迹,这限制了 TPT 在中小型模型上的应用。探索轻量级模型通过知识蒸馏、提示工程等手段生成有效推理路径的极限,对于降低技术部署成本、推动产业级应用具有重要意义。
更多推荐
 10
10 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)