
大模型基础补全计划(三)---RNN实例与测试
那么我们就可以简单定义模型结构是:St=U∗Xt+W∗St−1+bi��=�∗��+�∗��−1+��和 Ot=V∗St+bo��=�∗��+��。注意,这里的核心就是St��,前面的输入Xt��对应一个St��,那么在计算Ot+1��+1的时候,会用到St��。这样对于这个模型来说,Xt��对Ot+1��+1是有影响的,也就意味着,模型可能可以学习到Xt��和Xt+1��+1的关系。前者是手搓r
(Recurrent Neural Network)
RNN的意义
在提到rnn之前,我们还是有必要先提一下cnn,cnn的应用目标是指定一个输入,获得一个模型输出,多次输入之间是没有必然联系。然而,在日常生活中,我们还有许多其他的任务是多个输入之间是有前后关系的。例如:机翻、对话模型等等,这些任务都有明显的特征,那就是输入数据是一个序列,前面输入的数据会对后面的输出产生了影响,因此有了rnn模型结构。
RNN的结构
如图(注意,此图找不到来源出处,看到网络大部分文章都引用了此图,若有侵权,联系删除)rnn的基础结构就三层:输入层、隐藏层、输出层,:
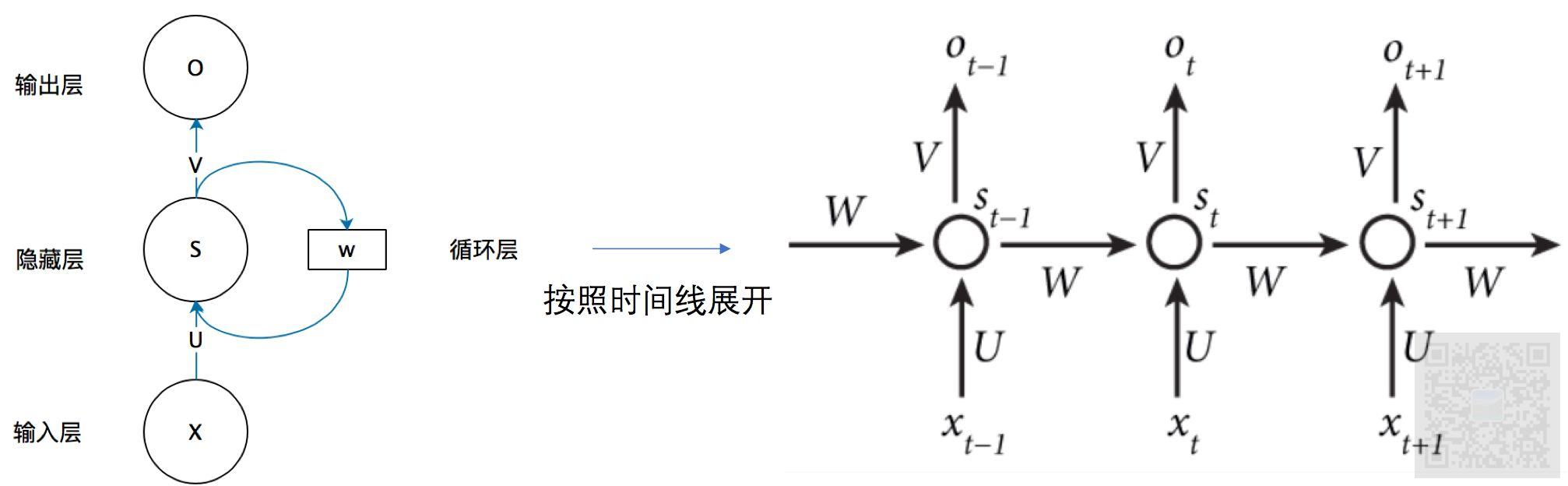
从图中可以知道,W是一个隐藏参数,是作为来至于上一次模型计算值St−1��−1的参数。V是输出的参数,U是输入的参数。那么我们就可以简单定义模型结构是:St=U∗Xt+W∗St−1+bi��=�∗��+�∗��−1+��和 Ot=V∗St+bo��=�∗��+��
对于输入层来说,其是一个输入序列,我们输出的内容也是一个序列。
注意,这里的核心就是St��,前面的输入Xt��对应一个St��,那么在计算Ot+1��+1的时候,会用到St��。这样对于这个模型来说,Xt��对Ot+1��+1是有影响的,也就意味着,模型可能可以学习到Xt��和Xt+1��+1的关系。
基于RNN训练一个简单的文字序列输出模型
文本预处理
import collections
# [
# [line0],
# [line1],
# .....
# ]
def read_data_from_txt():
with open('诛仙 (萧鼎).txt', 'r', encoding='utf-8') as f:
lines = f.readlines()
return [line.strip() for line in lines]
# 下面的tokenize函数将文本行列表(lines)作为输入, 列表中的每个元素是一个文本序列(如一条文本行)。
# 每个文本序列又被拆分成一个词元列表,词元(token)是文本的基本单位。 最后,返回一个由词元列表组成的列表,
# 其中的每个词元都是一个字符串(string)。
# [
# [line0-char0, line0-char1, line0-char2, ....],
# [line1-char0, line1-char1, line1-char2, ....],
# .....
# ]
def tokenize(lines, token='char'): #@save
"""将文本行拆分为单词或字符词元"""
if token == 'word':
return [line.split() for line in lines]
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:' + token)
# 词元的类型是字符串,而模型需要的输入是数字,因此这种类型不方便模型使用。 现在,让我们构建一个字典,
# 通常也叫做词表(vocabulary), 用来将字符串类型的词元映射到从开始的数字索引中。
def count_corpus(tokens): #@save
"""统计词元的频率"""
# 这里的tokens是1D列表或2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
# 将词元列表展平成一个列表
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
# 返回类似{'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1}的一个字典
class Vocab:
"""文本词表"""
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
# 按出现频率排序
# 对于Counter("hello world"),结果如下
# Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1],
reverse=True)
# 未知词元的索引为0
self.idx_to_token = ['<unk>'] + reserved_tokens
self.token_to_idx = {token: idx
for idx, token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self): # 未知词元的索引为0
return 0
@property
def token_freqs(self):
return self._token_freqs
# 将传入的数据集映射为一个索引表
# 返回传入文本的索引、词表
def load_dataset(max_tokens=-1):
lines = read_data_from_txt()
print(f'# 文本总行数: {len(lines)}')
# print(lines[0])
# print(lines[10])
tokens = tokenize(lines)
# for i in range(11):
# print(tokens[i])
vocab = Vocab(tokens, reserved_tokens=['<pad>', '<bos>', '<eos>'])
# print(list(vocab.token_to_idx.items())[:10])
# for i in [0, 10]:
# print('文本:', tokens[i])
# print('索引:', vocab[tokens[i]])
corpus = [vocab[token] for line in tokens for token in line]
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus, vocab
上面代码做了如下事情:
- 首先我们随便找了一部中文小说,然后读取其所有的行,然后得到一个包含所有行的二维列表。
- 然后我们对每一行进行文字切割,得到了一个二维列表,列表中的每一行又被分割为一个个中文文字,也就得到了一个个token。(特别注意,站在当前的时刻,这里的token和现在主流的大语言模型的token概念是一样的,但是不是一样的实现。)
- 由于模型不能直接处理文字,我们需要将文字转换为数字,那么直接的做法就是将一个个token编号即可,这个时候我们得到了词表(vocabulary)。
- 然后我们根据我们得到的词表,对原始数据集进行数字化,得到一个列表,列表中每个元素就是一个个token对应的索引。
构造数据集及加载器
# 以num_steps为步长,从随机的起始位置开始,返回
# x1=[ [random_offset1:random_offset1 + num_steps], ... , [random_offset_batchsize:random_offset_batchsize + num_steps] ]
# y1=[ [random_offset1 + 1:random_offset1 + num_steps + 1], ... , [random_offset_batchsize + 1:random_offset_batchsize + num_steps + 1] ]
def seq_data_iter_random(corpus, batch_size, num_steps): #@save
"""使用随机抽样生成一个小批量子序列"""
# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1
corpus = corpus[random.randint(0, num_steps - 1):]
# 减去1,是因为我们需要考虑标签
num_subseqs = (len(corpus) - 1) // num_steps
# 长度为num_steps的子序列的起始索引
# [0, num_steps*1, num_steps*2, num_steps*3, ...]
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
# 在随机抽样的迭代过程中,
# 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻
random.shuffle(initial_indices)
def data(pos):
# 返回从pos位置开始的长度为num_steps的序列
return corpus[pos: pos + num_steps]
num_batches = num_subseqs // batch_size
for i in range(0, batch_size * num_batches, batch_size):
# 在这里,initial_indices包含子序列的随机起始索引
initial_indices_per_batch = initial_indices[i: i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
yield torch.tensor(X), torch.tensor(Y)
# 以num_steps为步长,从随机的起始位置开始,返回
# x1=[:, random_offset1:random_offset1 + num_steps]
# y1=[:, random_offset1 + 1:random_offset1 + num_steps + 1]
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save
"""使用顺序分区生成一个小批量子序列"""
# 从随机偏移量开始划分序列
offset = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
# 重新根据corpus建立X_corpus, Y_corpus,两者之间差一位。注意X_corpus, Y_corpus的长度是batch_size的整数倍
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
# 直接根据batchsize划分X_corpus, Y_corpus
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
# 计算出需要多少次才能取完数据
num_batches = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batches, num_steps):
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
yield X, Y
class SeqDataLoader: #@save
"""加载序列数据的迭代器"""
def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):
if use_random_iter:
self.data_iter_fn = seq_data_iter_random
else:
self.data_iter_fn = seq_data_iter_sequential
self.corpus, self.vocab = dateset.load_dataset(max_tokens)
self.batch_size, self.num_steps = batch_size, num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
def load_data_epoch(batch_size, num_steps, #@save
use_random_iter=False, max_tokens=10000):
"""返回时光机器数据集的迭代器和词表"""
data_iter = SeqDataLoader(
batch_size, num_steps, use_random_iter, max_tokens)
return data_iter, data_iter.vocab
上面的代码主要作用是:在训练的时候,从我们在文本预处理数据中,以随机顺序或者相邻顺序抽取其中的部分数据作为随机批量数据。每次抽取的数据维度是:(batch_size, num_steps)
搭建RNN训练框架
按照原来的经验,我们要设计一个训练框架,第一步就要搭建网络,此网络用于接收一个输入,输出一个输出。
def rnn(inputs, state, params):
# inputs的形状:(时间步数量,批量大小,词表大小)
# inputs的形状:(num_steps,batch_size,词表大小)
# W_xh的形状: (词表大小, num_hiddens)
# W_hh的形状:(num_hiddens, num_hiddens)
# b_h 的形状:(num_hiddens)
# W_hq的形状:(num_hiddens, 词表大小)
# b_q 的形状:(词表大小)
W_xh, W_hh, b_h, W_hq, b_q = params
# H的形状:(batch_size, num_hiddens)
H, = state
outputs = []
# X的形状:(批量大小,词表大小)
# X的形状:(batch_size,词表大小)
for X in inputs:
# H是上一次预测的一个参数,每次计算隐藏层值后,更新H的值
# H = tanh(X*W_xh + H*W_hh + b_h)
H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)
# Y是输出值,每次rnn输出的时候,都会输出从开始到当前的所有值,因此我们需要保存所有的输出值
# Y = H * W_hq + b_q
# Y的形状:(batch_size,词表大小)
Y = torch.mm(H, W_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
class RNNModelScratch: #@save
"""从零开始实现的循环神经网络模型"""
def __init__(self, vocab_size, num_hiddens, device,
get_params, init_state, forward_fn):
self.vocab_size, self.num_hiddens = vocab_size, num_hiddens
# 初始化了隐藏参数 W_xh, W_hh, b_h, W_hq, b_q
self.params = get_params(vocab_size, num_hiddens, device)
self.init_state, self.forward_fn = init_state, forward_fn
def __call__(self, X, state):
# X的形状:(batch_size, num_steps)
# X one_hot之后的形状:(num_steps,batch_size,词表大小)
X = F.one_hot(X.T, self.vocab_size).type(torch.float32)
return self.forward_fn(X, state, self.params)
def begin_state(self, batch_size, device):
return self.init_state(batch_size, self.num_hiddens, device)
# 用框架
#@save
class RNNModel(nn.Module):
"""循环神经网络模型"""
def __init__(self, rnn_layer, vocab_size, device, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size, device=device)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size, device=device)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state)
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
# 它的输出形状是(时间步数*批量大小,词表大小)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
# nn.GRU以张量作为隐状态
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),
device=device)
else:
# nn.LSTM以元组作为隐状态
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))
上面主要是设计了两个网络类:RNNModelScratch、RNNModel。前者是手搓rnn实现。后者是借用torch框架来实现一个简单的rnn网络。他们的主要做了如下几个事情:
- 接收(batch_size, num_steps)的输入,并将输入转换为one_hot向量模式,其shape是(num_steps,batch_size,词表大小)
- 通过rnn的计算,然后通过变换,将最终输出映射到(batch_size * num_steps, 词表大小)
其实我们观察输入和输出,就可以理解一个事情:输入的内容就是输入序列所有的字符对应的one_hot向量。输出的内容就是batch_size * num_steps个向量,代表输出的文字序列信息,每个向量里面的最大值就代表了网络预测的文字id。
有了网络,对于部署角度来说,我们只需要实现预测过程即可:
def predict_ch8(prefix, num_preds, net, vocab, device): #@save
"""在prefix后面生成新字符"""
state = net.begin_state(batch_size=1, device=device)
outputs = [vocab[prefix[0]]]
get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))
for y in prefix[1:]: # 预热期
_, state = net(get_input(), state)
outputs.append(vocab[y])
for _ in range(num_preds): # 预测num_preds步
# y 包含从开始到现在的所有输出
# state是当前计算出来的隐藏参数
y, state = net(get_input(), state)
outputs.append(int(y.argmax(dim=1).reshape(1)))
return ''.join([vocab.idx_to_token[i] for i in outputs])
由于输出的信息就是batch_size * num_steps个向量,那么只需要计算每一个向量的最大值id就得到了网络输出的tokenid,然后通过词表反向映射回词表,完成了预测文字输出的功能。
有了网络、预测过程,然后就可以搭建训练过程,训练过程最重要的一步就是通过网络得到输入对应的输出,然后根据输出计算loss信息,然后根据loss信息进行梯度下降(这就是通用流程)
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):
"""训练网络一个迭代周期(定义见第8章)"""
state, timer = None, Timer()
metric = Accumulator(2) # 训练损失之和,词元数量
# X的形状:(batch_size, num_steps)
# Y的形状:(batch_size, num_steps)
for X, Y in train_iter:
if state is None or use_random_iter:
# 在第一次迭代或使用随机抽样时初始化state
state = net.begin_state(batch_size=X.shape[0], device=device)
else:
if isinstance(net, nn.Module) and not isinstance(state, tuple):
# state对于nn.GRU是个张量
state.detach_()
else:
# state对于nn.LSTM或对于我们从零开始实现的模型是个张量
for s in state:
s.detach_()
y = Y.T.reshape(-1)
X, y = X.to(device), y.to(device)
# y_hat 包含从开始到现在的所有输出
# y_hat的形状:(batch_size * num_steps, 词表大小)
# state是当前计算出来的隐藏参数
y_hat, state = net(X, state)
# 交叉熵损失函数,传入预测值和标签值,并求平均值
l = loss(y_hat, y.long()).mean()
if isinstance(updater, torch.optim.Optimizer):
updater.zero_grad()
l.backward()
grad_clipping(net, 1)更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)