
大模型原理与实践:第三章-预训练语言模型详解_第2部分-Encoder-Decoder-T5
T5模型是Google提出的Encoder-Decoder架构预训练语言模型,采用完整Transformer结构,将各类NLP任务统一为文本到文本转换。其关键创新包括:1)使用RMSNorm替代LayerNorm,计算更高效;2)引入相对位置编码;3)采用Encoder-Decoder架构,支持更灵活的生成任务。模型通过统一框架处理多种任务,实现NLP任务的大一统,为后续研究提供了重要参考。
预训练语言模型详解
总目录
目录
- Encoder-Decoder 预训练语言模型
- 3.1 T5模型
- 3.1.1 模型结构:Encoder-Decoder
- 3.1.2 预训练任务
- 3.1.3 大一统思想
- 3.1 T5模型
Encoder-Decoder 预训练语言模型
T5模型
T5(Text-To-Text Transfer Transformer)是Google提出的一种预训练语言模型,其核心创新在于将所有NLP任务统一表示为文本到文本的转换问题。T5基于完整的Transformer架构,包含Encoder和Decoder两部分,使用自注意力机制捕捉全局依赖关系。
模型结构:Encoder-Decoder
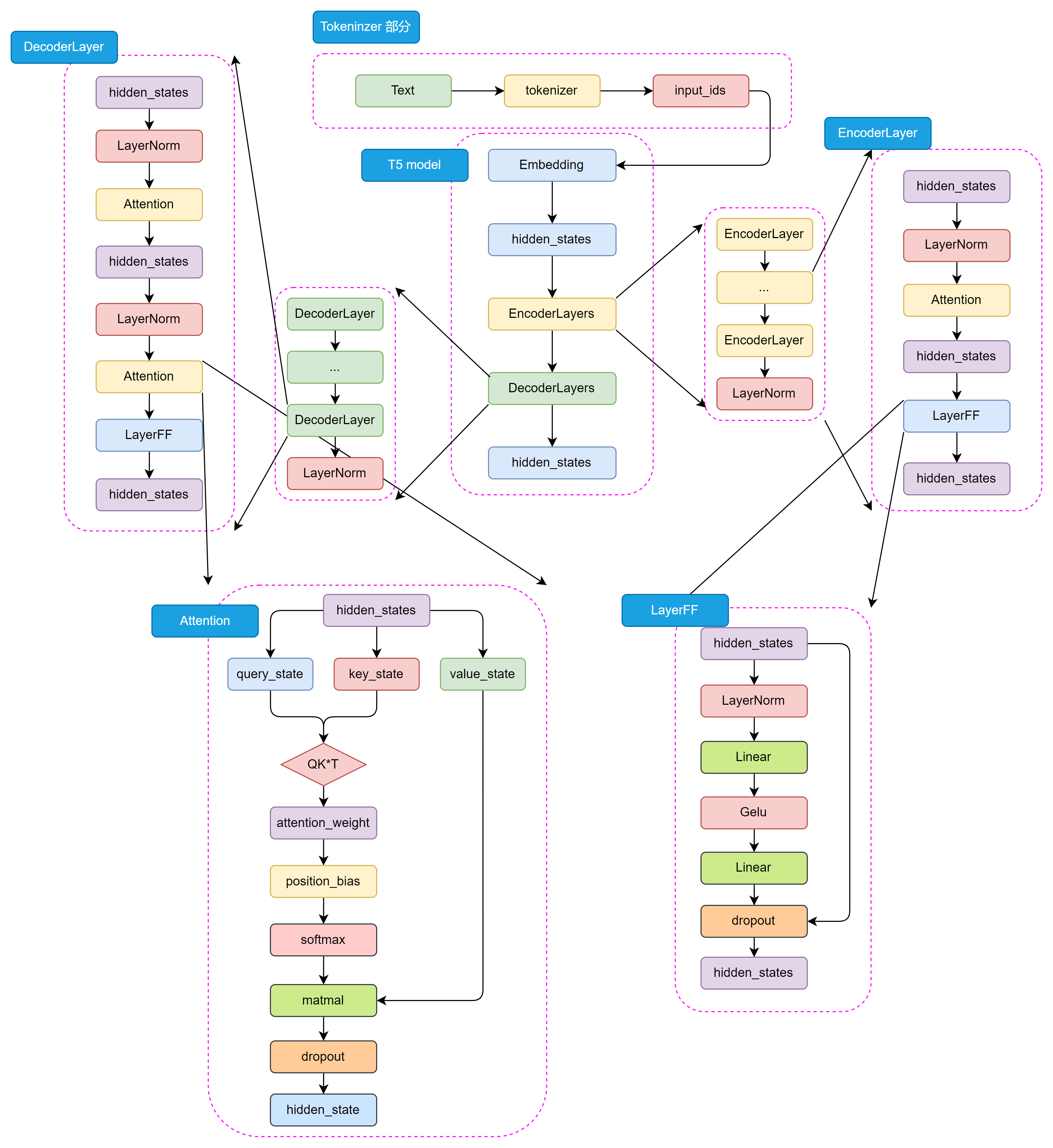
T5采用了Encoder-Decoder结构,不同于BERT的Encoder-Only和GPT的Decoder-Only。其整体架构可分为几个关键部分:
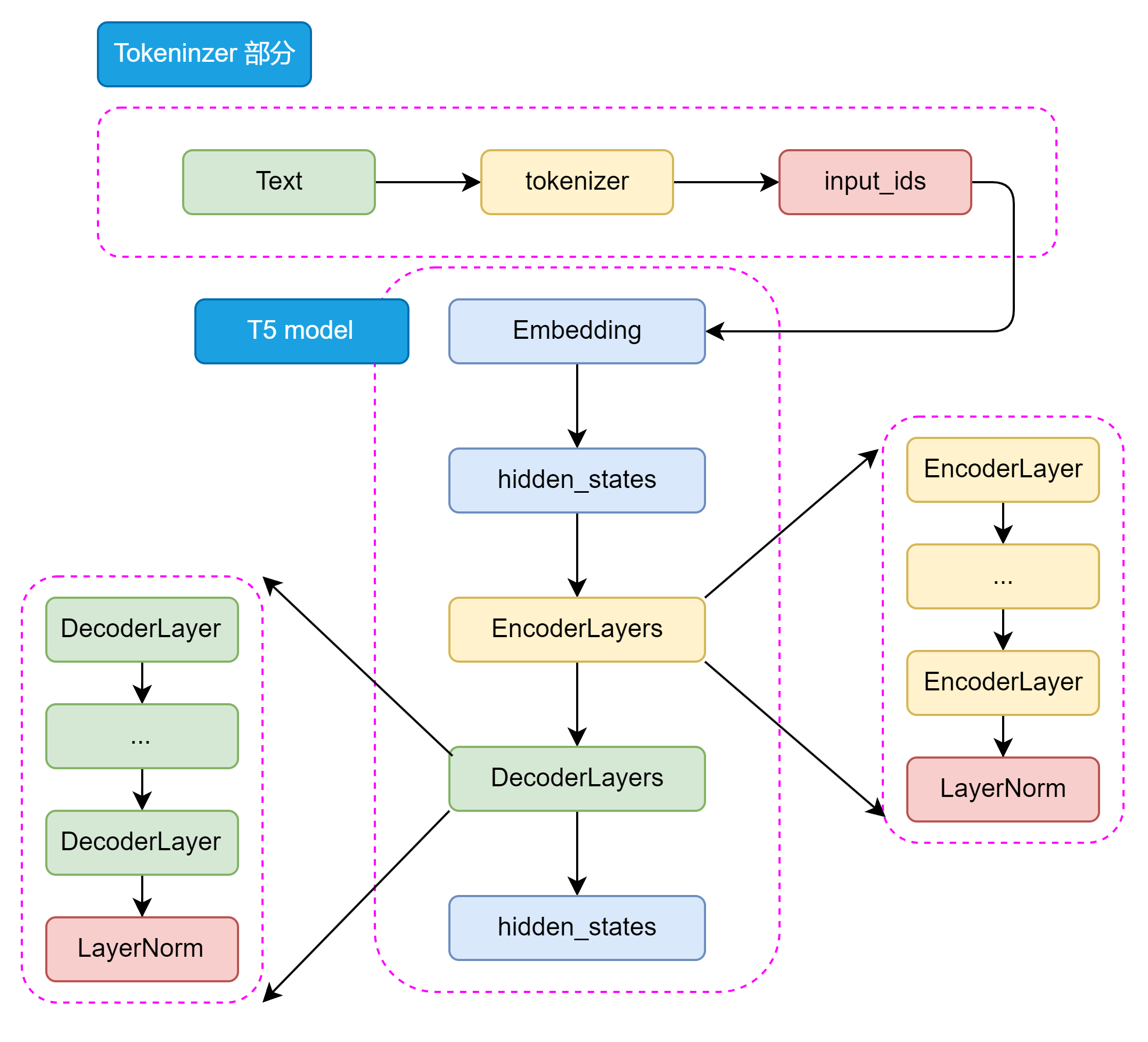
整体架构层次:
-
Tokenizer部分:将输入文本转换为模型可接受的格式
-
Transformer部分:
- EncoderLayers:由多个Encoder Block堆叠
- DecoderLayers:由多个Decoder Block堆叠
Encoder和Decoder的结构差异:
Decoder 和 Encoder 不一样的是,在 Decoder 中还包含了 Encoder-Decoder Attention 结构,用于捕捉输入和输出序列之间的依赖关系。这两种 Attention 结构几乎完全一致,只有在位置编码和 Mask 机制上有所不同。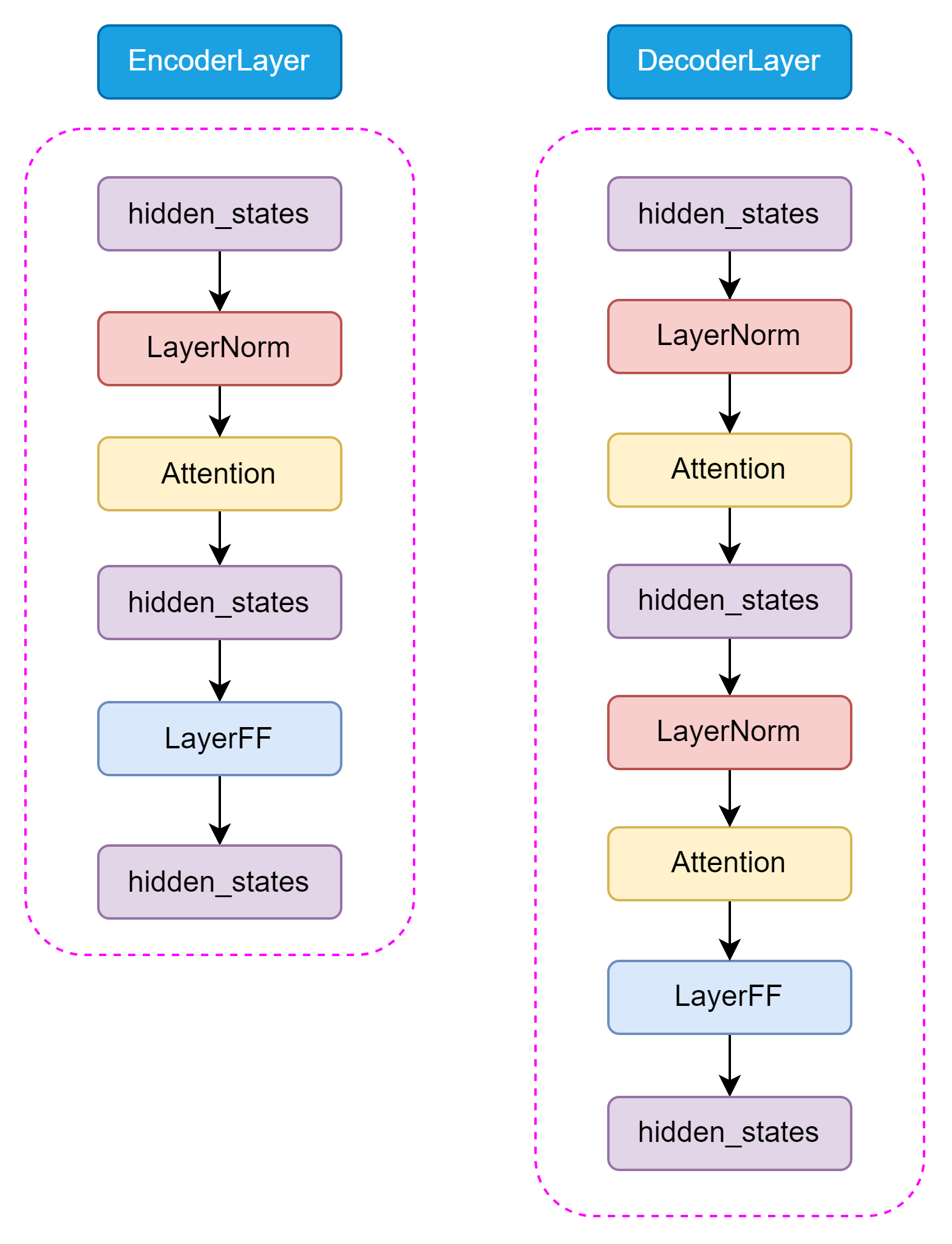
class T5EncoderBlock:
"""
T5的Encoder Block
"""
def forward(self, hidden_states):
# 1. Self-Attention
attn_output = self.self_attention(hidden_states)
hidden_states = self.layer_norm1(hidden_states + attn_output)
# 2. Feed-Forward
ff_output = self.feed_forward(hidden_states)
hidden_states = self.layer_norm2(hidden_states + ff_output)
return hidden_states
class T5DecoderBlock:
"""
T5的Decoder Block
"""
def forward(self, hidden_states, encoder_hidden_states):
# 1. Masked Self-Attention(带因果掩码)
self_attn_output = self.masked_self_attention(hidden_states)
hidden_states = self.layer_norm1(hidden_states + self_attn_output)
# 2. Encoder-Decoder Cross-Attention
cross_attn_output = self.cross_attention(
query=hidden_states,
key=encoder_hidden_states,
value=encoder_hidden_states
)
hidden_states = self.layer_norm2(hidden_states + cross_attn_output)
# 3. Feed-Forward
ff_output = self.feed_forward(hidden_states)
hidden_states = self.layer_norm3(hidden_states + ff_output)
return hidden_states
关键技术创新:
- RMSNorm替代LayerNorm:
T5使用RMSNorm(Root Mean Square Normalization)来归一化激活值,其数学公式为:
RMSNorm ( x ) = x 1 n ∑ i = 1 n x i 2 + ϵ ⋅ γ \text{RMSNorm}(x) = \frac{x}{\sqrt{\frac{1}{n}\sum_{i=1}^{n}x_i^2 + \epsilon}} \cdot \gamma RMSNorm(x)=n1∑i=1nxi2+ϵx⋅γ
其中:
- x i x_i xi 是输入向量的第 i i i 个元素
- γ \gamma γ 是可学习的缩放参数
- n n n 是输入向量的维度数量
- ϵ \epsilon ϵ 是一个小常数,用于数值稳定性(避免除零)
RMSNorm相比LayerNorm参数更少,只有一个可学习参数γ\gamma γ,计算更高效,且能更好地适应不同任务和数据集。
class RMSNorm:
"""
RMSNorm实现
"""
def __init__(self, hidden_size, eps=1e-6):
self.weight = nn.Parameter(torch.ones(hidden_size)) # 可学习的缩放参数γ
self.eps = eps
def forward(self, hidden_states):
# 计算均方根
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.eps)
# 应用可学习的缩放
return self.weight * hidden_states
# 对比LayerNorm和RMSNorm
class LayerNorm:
"""
传统LayerNorm实现(用于对比)
"""
def __init__(self, hidden_size, eps=1e-6):
self.weight = nn.Parameter(torch.ones(hidden_size)) # 缩放参数
self.bias = nn.Parameter(torch.zeros(hidden_size)) # 偏移参数
self.eps = eps
def forward(self, hidden_states):
# 计算均值和方差
mean = hidden_states.mean(-1, keepdim=True)
variance = (hidden_states - mean).pow(2).mean(-1, keepdim=True)
# 归一化
hidden_states = (hidden_states - mean) / torch.sqrt(variance + self.eps)
# 应用可学习的缩放和偏移
return self.weight * hidden_states + self.bias
- 相对位置编码:
T5使用相对位置编码,在注意力机制中直接编码位置信息,而不是像原始Transformer那样使用绝对位置编码。
class T5Attention:
"""
T5的注意力机制(包含相对位置编码)
"""
def __init__(self, hidden_size, num_heads):
self.num_heads = num_heads
self.head_dim = hidden_size // num_heads
# Q, K, V投影层
self.q_proj = nn.Linear(hidden_size, hidden_size)
self.k_proj = nn.Linear(hidden_size, hidden_size)
self.v_proj = nn.Linear(hidden_size, hidden_size)
# 相对位置编码的bias
self.relative_position_bias = nn.Embedding(32, num_heads) # 可学习的相对位置bias
def forward(self, hidden_states, attention_mask=None):
batch_size, seq_len, _ = hidden_states.shape
# 计算Q, K, V
q = self.q_proj(hidden_states).view(batch_size, seq_len, self.num_heads, self.head_dim)
k = self.k_proj(hidden_states).view(batch_size, seq_len, self.num_heads, self.head_dim)
v = self.v_proj(hidden_states).view(batch_size, seq_len, self.num_heads, self.head_dim)
# 计算注意力分数
attention_scores = torch.matmul(q, k.transpose(-1, -2)) / math.sqrt(self.head_dim)
# 添加相对位置bias
position_bias = self.compute_position_bias(seq_len)
attention_scores = attention_scores + position_bias
# 应用attention mask
if attention_mask is not None:
attention_scores = attention_scores.masked_fill(
attention_mask == 0, float('-inf')
)
# Softmax和加权求和
attention_probs = F.softmax(attention_scores, dim=-1)
context = torch.matmul(attention_probs, v)
return context
def compute_position_bias(self, seq_len):
"""
计算相对位置bias
"""
# 创建相对位置矩阵
position_ids = torch.arange(seq_len)
relative_position = position_ids[None, :] - position_ids[:, None]
# 限制相对位置范围(例如-16到16)
relative_position = torch.clamp(relative_position, -16, 16) + 16
# 获取相对位置embedding
position_bias = self.relative_position_bias(relative_position)
return position_bias.permute(2, 0, 1).unsqueeze(0) # [1, num_heads, seq_len, seq_len]
完整的T5前向传播流程:
class T5Model:
"""
T5模型完整实现
"""
def __init__(self, config):
self.encoder = T5Encoder(config)
self.decoder = T5Decoder(config)
def forward(self, input_ids, decoder_input_ids):
# 1. Encoder处理输入
encoder_outputs = self.encoder(input_ids)
# 2. Decoder生成输出(带cross-attention)
decoder_outputs = self.decoder(
decoder_input_ids,
encoder_hidden_states=encoder_outputs
)
return decoder_outputs
class T5Encoder:
"""
T5 Encoder
"""
def __init__(self, config):
self.embed_tokens = nn.Embedding(config.vocab_size, config.d_model)
self.blocks = nn.ModuleList([
T5EncoderBlock(config) for _ in range(config.num_layers)
])
self.final_layer_norm = RMSNorm(config.d_model)
def forward(self, input_ids):
# Embedding
hidden_states = self.embed_tokens(input_ids)
# 通过所有Encoder blocks
for block in self.blocks:
hidden_states = block(hidden_states)
# 最终LayerNorm
hidden_states = self.final_layer_norm(hidden_states)
return hidden_states
class T5Decoder:
"""
T5 Decoder
"""
def __init__(self, config):
self.embed_tokens = nn.Embedding(config.vocab_size, config.d_model)
self.blocks = nn.ModuleList([
T5DecoderBlock(config) for _ in range(config.num_layers)
])
self.final_layer_norm = RMSNorm(config.d_model)
self.lm_head = nn.Linear(config.d_model, config.vocab_size, bias=False)
def forward(self, decoder_input_ids, encoder_hidden_states):
# Embedding
hidden_states = self.embed_tokens(decoder_input_ids)
# 通过所有Decoder blocks
for block in self.blocks:
hidden_states = block(hidden_states, encoder_hidden_states)
# 最终LayerNorm
hidden_states = self.final_layer_norm(hidden_states)
# 映射到词表
logits = self.lm_head(hidden_states)
return logits
预训练任务
T5的预训练任务基于MLM,但有一些独特的设计:
预训练任务特点:
- MLM(BERT-style目标):在输入文本中随机遮蔽15%的token,让模型预测这些被遮蔽的token
- 文本到文本格式:预训练时将输入转换为"文本到文本"格式
def create_t5_training_sample(text):
"""
创建T5的预训练样本
"""
tokens = tokenize(text)
# 随机选择15%的token进行遮蔽
mask_indices = random.sample(range(len(tokens)), k=int(len(tokens) * 0.15))
# 创建输入序列(用特殊token替换被遮蔽的部分)
input_tokens = tokens.copy()
masked_spans = []
for idx in sorted(mask_indices):
input_tokens[idx] = '<extra_id_0>' # T5使用特殊的sentinel token
masked_spans.append(tokens[idx])
# 创建目标序列(只包含被遮蔽的token)
target_tokens = ['<extra_id_0>'] + masked_spans + ['</s>']
return {
'input': input_tokens,
'target': target_tokens
}
# 示例
text = "The quick brown fox jumps over the lazy dog"
sample = create_t5_training_sample(text)
print("Input:", sample['input'])
# Output: ['The', 'quick', '<extra_id_0>', 'fox', 'jumps', '<extra_id_0>', 'the', 'lazy', 'dog']
print("Target:", sample['target'])
# Output: ['<extra_id_0>', 'brown', 'over', '</s>']
- C4数据集:T5使用自己创建的大规模数据集"Colossal Clean Crawled Corpus"(C4),从Common Crawl中提取了750GB的干净英语文本。
# C4数据集处理示例
class C4DatasetProcessor:
"""
C4数据集处理器
"""
def __init__(self):
self.min_text_length = 100 # 最小文本长度
self.max_text_length = 10000 # 最大文本长度
def clean_text(self, text):
"""
清洗文本:去除无意义文本、重复文本等
"""
# 1. 去除太短或太长的文本
if len(text) < self.min_text_length or len(text) > self.max_text_length:
return None
# 2. 去除包含过多特殊字符的文本
special_char_ratio = sum(not c.isalnum() for c in text) / len(text)
if special_char_ratio > 0.3:
return None
# 3. 去除重复文本
if self.is_duplicate(text):
return None
return text
def process_corpus(self, raw_corpus):
"""
处理整个语料库
"""
cleaned_corpus = []
for text in raw_corpus:
cleaned_text = self.clean_text(text)
if cleaned_text:
cleaned_corpus.append(cleaned_text)
return cleaned_corpus
- 多任务预训练:T5尝试将多个任务混合在一起进行预训练,而不仅仅是单独的MLM任务。
def create_multitask_sample(data_type, text):
"""
创建多任务预训练样本
"""
if data_type == 'mlm':
# MLM任务
return create_mlm_sample(text)
elif data_type == 'translation':
# 翻译任务
source, target = split_parallel_text(text)
return {
'input': f"translate English to French: {source}",
'target': target
}
elif data_type == 'summarization':
# 摘要任务
article, summary = split_article_summary(text)
return {
'input': f"summarize: {article}",
'target': summary
}
# ... 其他任务
大一统思想
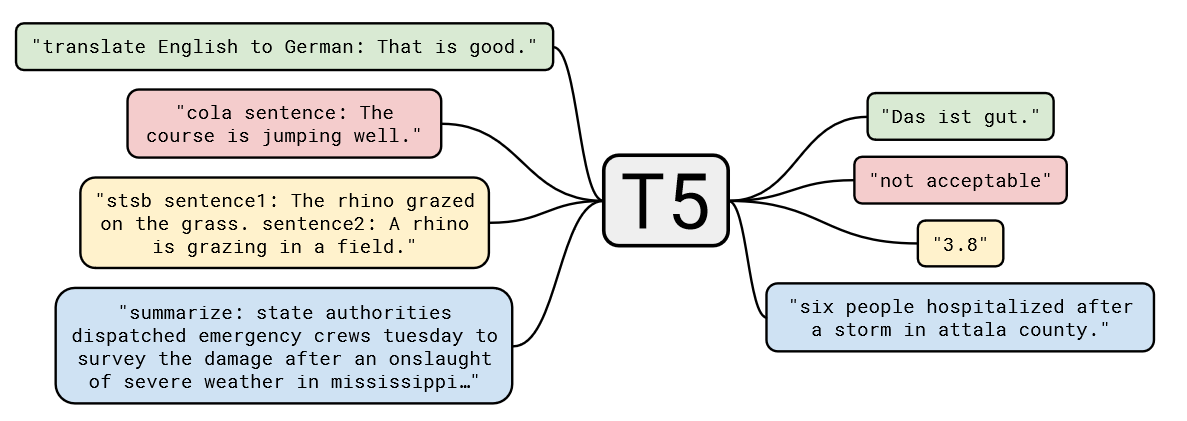
T5的核心理念是"大一统思想"——将所有NLP任务统一为文本到文本的任务。这一思想通过任务前缀来实现:
不同任务的统一表示:
class T5UnifiedFramework:
"""
T5大一统框架
"""
def __init__(self, model):
self.model = model
self.task_prefixes = {
'translation': 'translate {source_lang} to {target_lang}:',
'summarization': 'summarize:',
'classification': 'classify:',
'qa': 'question: {question} context:',
'sentiment': 'sentiment:',
}
def process_task(self, task_type, input_text, **kwargs):
"""
统一处理不同类型的任务
"""
# 1. 添加任务前缀
if task_type == 'translation':
prefix = self.task_prefixes['translation'].format(
source_lang=kwargs['source_lang'],
target_lang=kwargs['target_lang']
)
else:
prefix = self.task_prefixes[task_type]
# 2. 构建完整输入
full_input = f"{prefix} {input_text}"
# 3. 模型推理
output = self.model.generate(full_input)
return output
使用示例
# 使用示例
t5_framework = T5UnifiedFramework(t5_model)
# 1. 文本分类
result = t5_framework.process_task(
'classification',
'这是一个很好的产品'
)
# 输入: "classify: 这是一个很好的产品"
# 输出: "正面"
# 2. 翻译任务
result = t5_framework.process_task(
'translation',
'How are you?',
source_lang='English',
target_lang='French'
)
# 输入: "translate English to French: How are you?"
# 输出: "Comment ça va?"
# 3. 摘要任务
result = t5_framework.process_task(
'summarization',
'这是一篇很长的文章内容...'
)
# 输入: "summarize: 这是一篇很长的文章内容..."
# 输出: "文章摘要"
# 4. 问答任务
result = t5_framework.process_task(
'qa',
'Where is the Eiffel Tower?',
question='Where is the Eiffel Tower?'
)
# 输入: "question: Where is the Eiffel Tower? context: ..."
# 输出: "Paris, France"
大一统思想的优势:
- 简化模型设计:所有任务共享同一个模型架构
- 参数共享:不同任务之间可以共享知识
- 统一训练流程:使用相同的数据处理和训练框架
- 提高泛化能力:多任务学习提升模型的通用性
- 便捷应用:只需改变输入前缀即可切换任务
# 大一统训练流程
class T5Trainer:
"""
T5统一训练器
"""
def train_step(self, batch):
"""
统一的训练步骤,适用于所有任务
"""
# 1. 前向传播
outputs = self.model(
input_ids=batch['input_ids'],
decoder_input_ids=batch['decoder_input_ids']
)
# 2. 计算损失(所有任务使用相同的损失函数)
loss = F.cross_entropy(
outputs.view(-1, self.vocab_size),
batch['labels'].view(-1)
)
# 3. 反向传播
loss.backward()
# 4. 更新参数
self.optimizer.step()
return loss
def train_multitask(self, datasets):
"""
多任务联合训练
"""
for epoch in range(self.num_epochs):
for task, dataset in datasets.items():
for batch in dataset:
# 所有任务使用相同的训练流程
loss = self.train_step(batch)
print(f"Task: {task}, Loss: {loss:.4f}")
T5的大一统思想不仅推动了NLP技术的发展,也为实际应用提供了更便捷和高效的解决方案。通过将所有任务统一为文本到文本的形式,T5大大简化了模型的使用和部署流程。
更多推荐

 14
14 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)