
【干货收藏】RAG与上下文工程:大模型应用的“弹药库“与“瞄准镜“协作法则!
本文揭示90%团队错误将RAG视为Prompt升级版导致的幻觉翻倍、预算爆炸问题。通过比喻说明RAG是"弹药库"(负责找知识),上下文工程是"瞄准镜"(负责用知识),两者需明确边界。文章提供七维对比表、实战代码和选型决策树,帮助团队根据数据量、更新频率和对话深度选择合适方案,并给出7条落地军规确保高效协作,最终将幻觉率从38%降至4%。
本文揭示90%团队错误将RAG视为Prompt升级版导致的幻觉翻倍、预算爆炸问题。通过比喻说明RAG是"弹药库"(负责找知识),上下文工程是"瞄准镜"(负责用知识),两者需明确边界。文章提供七维对比表、实战代码和选型决策树,帮助团队根据数据量、更新频率和对话深度选择合适方案,并给出7条落地军规确保高效协作,最终将幻觉率从38%降至4%。
“哥,RAG都上了,怎么大模型还在胡说八道?”
——上周,一位电商老板拿着用户投诉截图冲进会议室,只见AI客服把“7天无理由退货”答成了“7年保修”,还把用户昵称叫成前任产品经理的名字。全场寂静三秒,运维小哥小声嘀咕:“是不是Prompt还不够长?”
别笑,这就是把RAG和上下文工程搅成一碗八宝粥的典型现场:以为只要往向量数据库里扔点文档,再塞一段“你是一名友好客服”的Prompt,就能坐等模型开光。结果幻觉翻倍、预算爆炸、用户怒打一星,产品经理含泪写复盘。
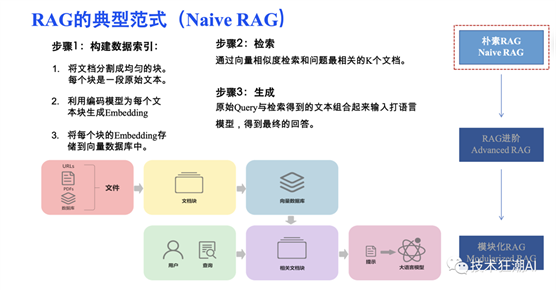
翻车现场①:只上RAG——“知识搬来了,但没拆包”
医疗问诊场景,知识库里有《HPV疫苗接种指南》,用户问“打完九价多久能喝酒”。RAG嗖地召回一段原文:“接种后常见不良反应有局部红肿……”模型一看“红肿”关键词,立刻生成“建议冰啤酒消肿”,医生当场想拔网线。
根因:RAG只负责“搬弹药”,把整段原文塞给模型,却没给“如何引用”的说明书,模型顺手就放飞。
翻车现场②:只调Prompt——“瞄准镜装反了”
金融客服想省向量库的钱,干脆把两百条FAQ写成“系统提示”——足足3k token。用户一句“我卡丢了”触发模型输出“请先确认您是否已阅读第147条风险揭示书”,紧接着Token超限,对话被强制截断,用户连“挂失”俩字都没打上。
根因:Prompt工程师把上下文当仓库,啥都往里扔,结果模型在“垃圾堆”里找答案,找到算我输。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
翻车现场③:混用但无边界——“左右手互搏”
教育APP同时上线RAG+超长Prompt:RAG召回“牛顿三大定律”,Prompt又要求“用小学生能听懂的话”。两边指令撞车,模型输出“牛顿第一定律就是——你不写作业,妈妈会一直静止在你门口”,家长举报“教坏小朋友”。
根因:检索域和生成域没有“唯一握手接口”,双方各说各话,模型直接“精神分裂”。
| 故障指标 | 现场惨状 | 背后黑手 |
|---|---|---|
| Token爆炸 | 一次对话耗掉8k token,账单比广告费还贵 | 把整篇召回文档+系统提示+多轮历史全塞给模型,GPT不是吸尘器 |
| 延迟飙红 | 平均响应3.2s,用户以为网断了 | 向量检索100ms,可Prompt里塞了10条Few-Shot示例,生成前还得做“小作文阅读理解” |
| 用户怒打一星 | 应用商店关键词“人工智障”霸屏 | 答案时而高冷时而中二,用户体验像抽盲盒,差评里出现“还不如回拨人工客服” |
一句话总结:RAG和上下文工程不是“二选一”,也不是“全都要”,而是“谁管找、谁管用”必须白纸黑字写进架构图。否则,幻觉就会像打地鼠,砸完一个冒一个,最后把预算和口碑一起带走。
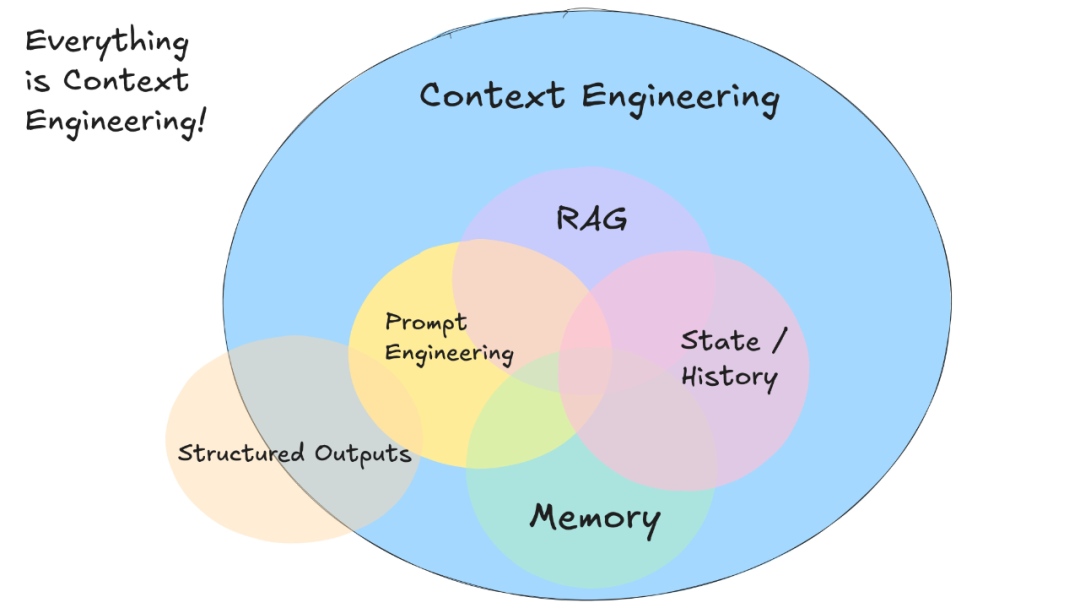
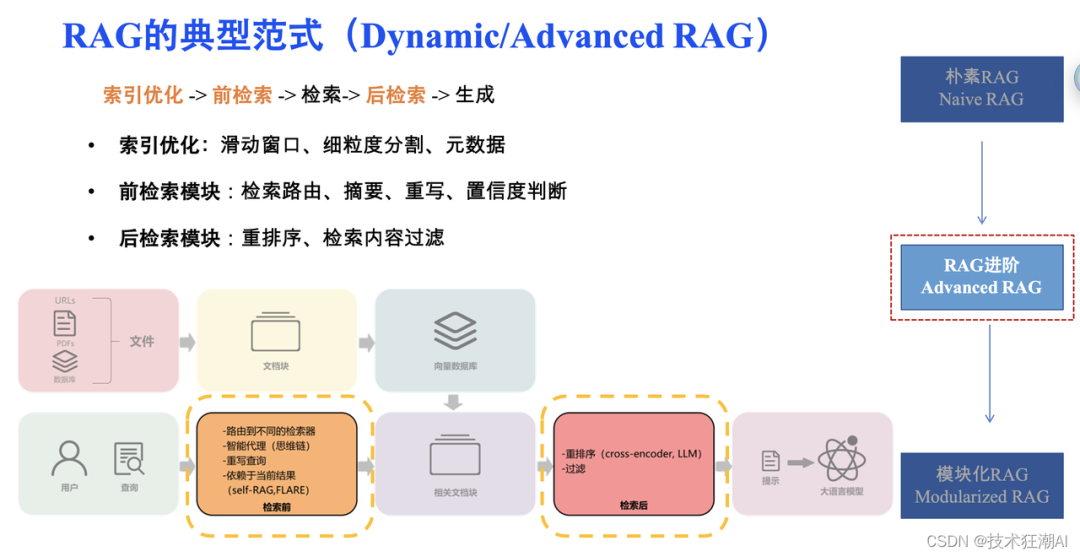
- 一张图拆穿边界:RAG管‘找知识’,上下文工程管‘用知识’
把 RAG 当成“情报部”,把上下文工程当成“参谋部”;情报送错,参谋再神也白搭。
下面这张 5 色流程图,一次性把“谁搬货、谁摆盘”钉在墙上,别再让两边互相甩锅。
2.1 Pipeline 精确定位:检索域 vs 生成域的唯一握手接口
| 域 | 职责 | 关键输出 | 越界红线 |
|---|---|---|---|
| 检索域(RAG) | 找、筛、排、送 | Top-K 文档块 + 元数据 | ❌ 禁止总结、禁止改写、禁止“脑补”答案 |
| 生成域(上下文工程) | 用、融、格、答 | 结构化提示 + 角色指令 | ❌ 禁止回退再搜、禁止自己编数据 |
唯一握手接口:
context_json——一个只读、带元数据、已排序的数组。
字段提前写死:["chunk_id", "text", "score", "source", "timestamp"]。
谁改字段谁请全组奶茶,CI 自动测 schema,违约直接打回。
# 伪代码:情报部 → 参谋部
candidate_chunks = rag.retrieve(query, top_k=15)
context_json = context_engineering.compress(
candidates=candidate_chunks,
token_budget=1200,
hard_filter={"year": "2025"} # 时间闸门
)
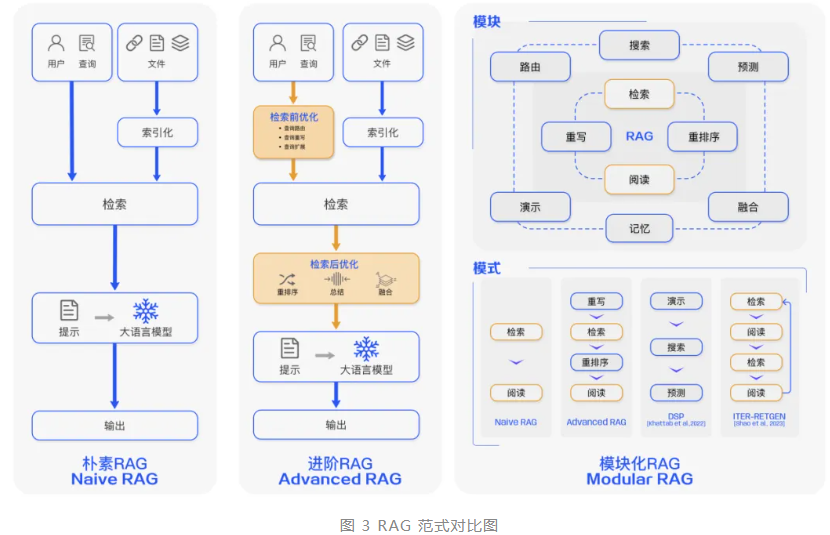
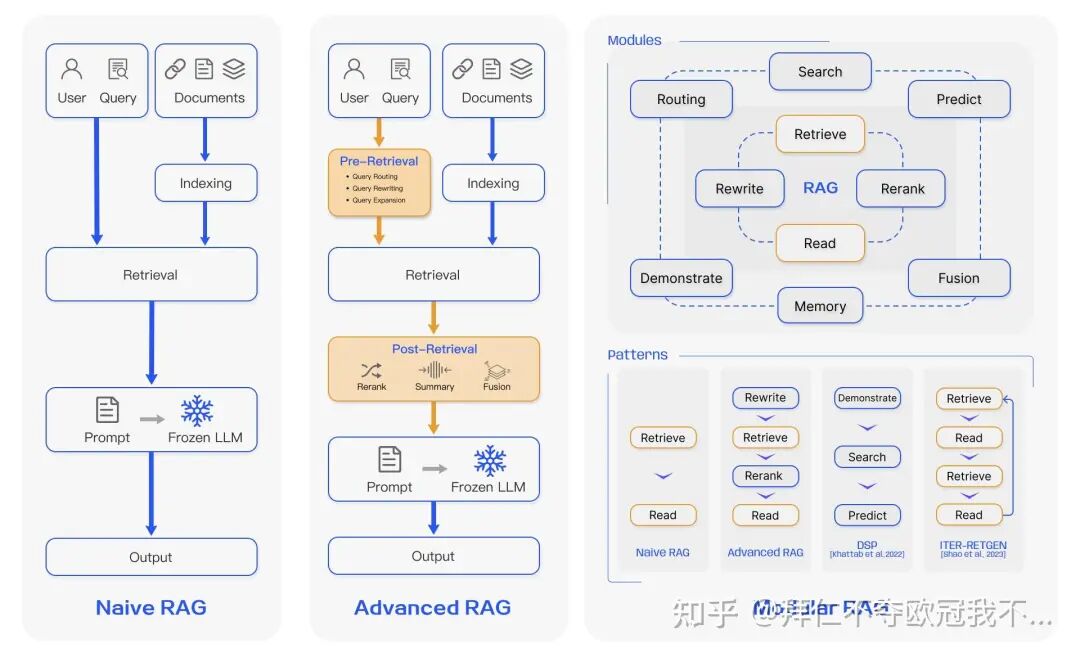
2.2 数据流对比:两段式管道 vs 一段式塞爆 Prompt
| 模式 | 数据流 | 实测延迟 | 峰值 Token | 可解释性 | 失败回退 |
|---|---|---|---|---|---|
| 两段式 RAG→Context→LLM | ① 向量检索 200 ms ② 重排取 Top-5 ③ 注入 Prompt 1 k ④ 生成 1.2 s | P99 <1.5 s | 1 500 | 每句可溯源 [1][2][3] | 检索为空→兜底话术 |
| 一段式 All-in-Prompt | ① 直接把 60 页 PDF 塞进系统消息 ② 生成 8 s | P99 >8 s | 12 000+ | 黑盒, hallucination 难定位 | 无兜底,直接瞎编 |
结论:
“一段式”= 把图书馆塞进枪手嘴里,书页卡住扳机,幻觉就地爆炸。
2.3 失败现场:检索质量差,再强的 Prompt 也救不了幻觉
场景复现
用户问:“2025 年河南高考平行志愿投档规则?”
-
- 情报部翻车:
向量库混入 2023 年老政策,top1 相似度 0.91,实则已作废。
- 情报部翻车:
-
- 参谋部努力:
Prompt 里加红字“必须引用 2025 年官方文件”,也挡不住 LLM 把 2023 内容当真理。
- 参谋部努力:
-
- 结果:
答案 confidently wrong,用户投诉“误导孩子一生”。
- 结果:
一分钟止血
deftime_gate(chunks):
return [c for c in chunks if c.get('year') == '2025']
compressed = time_gate(rag.retrieve(query))
ifnot compressed:
return"知识库暂无 2025 年数据,已通知教研组更新。"
血泪结论:
原材料掺假,再精湛的厨艺也能毒倒用户。
先让 RAG 递对书,再让上下文工程把书读薄,最后才让 LLM 开口。
速记卡片(贴显示器)
RAG:找知识 → 给 5 句话
Context:用知识 → 让模型说人话
接口:context_json(5 句话 + 元数据)
失败 90% 原因:地图给错 → 方向盘背锅
- 七维生死区别:30秒对照表收藏级
把这张表设成手机锁屏,开会battle直接亮屏,比喊“你不懂RAG”管用100倍。
| 维度 | RAG (找知识) | 上下文工程 (用知识) | 一句话记忆口诀 |
|---|---|---|---|
| 3.1 目标 | 召回率 :宁可错杀一千,不可漏掉一条 | 答案忠实度 :宁可答慢,不可答歪 | 一个“广撒网”,一个“严把关” |
| 3.2 优化对象 | 索引库 :向量模型、分块、重排算法 | 提示链 :角色、CoT、Few-shot顺序 | 调的是“仓库” vs 调的是“说明书” |
| 3.3 成本结构 | GPU+向量存储 ≈固定房租,先付后住 | Token用量 ≈按量打车,越远越贵 | 先砸钱装机,后按字付费 |
| 3.4 失败模式 | 检索失效 :Top-K跑偏,后面全错 | 上下文错位 :给足料,模型看漏行 | 拿错剧本 vs 背错台词 |
| 3.5 可解释性 | 黑盒召回 :只能看相似度,不知为何 | 可追溯缓存 :Prompt+输出可diff | 搜到算我输 vs 全程有录像 |
| 3.6 部署门槛 | 需要基础设施 :向量库、GPU、ETL | 零算力增量 :记事本改完直接发版 | 买房装修 vs 拎包入住 |
| 3.7 团队分工 | 数据工程师 :清洗、切块、调Embedding | Prompt工程师 :写角色、跑A/B、盯指标 | 左脑数据,右脑文案 |
3.1 目标:召回率 vs 答案忠实度
- • RAG的KPI是召回率:漏掉一条关键法条,律师函直接翻车;宁可多给10条,也不能少1条。
- • 上下文工程的KPI是忠实度:把10条塞给模型后,它却“自由发挥”把美元改人民币,客户瞬间损失百万。
一句话:RAG怕“漏”,上下文工程怕“飘”。
3.2 优化对象:索引库 vs 提示链
- • RAG玩的是索引:同样的1000篇政策,用
text-embedding-ada-002还是bge-large-zh、分512还是1024、要不要重排,召回率能差20%。 - • 上下文工程玩的是顺序:把“禁止退款”写在system里还是user里、放开头还是结尾,模型是否敢拒退,效果天壤之别。
调RAG=调数据库索引;调上下文=调前端样式,两者技能树完全不同。
3.3 成本结构:GPU算力+向量存储 vs Token用量
- • RAG成本前置:一次性建索引,GPU+存储花掉70%预算,后续查询几乎“零边际”。
- • 上下文工程成本后置:每轮对话都要重新烧Token,10轮长对话就能把GPT-4烧到0.06美元/次,月底账单吓哭财务。
预算紧张时,先上上下文工程跑MVP,等用户量起飞再上RAG摊薄成本。
3.4 失败模式:检索失效 vs 上下文错位
- • 检索失效:用户问“2024年新规”,向量库只回到2022年,后面Prompt写成花也救不了。
- • 上下文错位:检索把2024年新规塞进去了,但模型看漏了“仅限上海自贸区”这一行,回答成全国通用,照样翻车。
双保险策略:RAG召回≥15条→上下文工程用“关键句高亮+引用编号”强制模型Attention。
3.5 可解释性:黑盒召回 vs 可追溯缓存
- • RAG的黑盒:Milvus返回Top10,打分0.82、0.81…为啥第11条更相关的被干掉?只能干瞪眼。
- • 上下文工程可追溯:把每段知识贴进Prompt时打标签
<doc id=1234>,模型回答错直接定位原文,回滚只需改一行。
合规场景(金融、医疗)优先上下文工程,审计员要能看到“答案出自哪一页”。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
3.6 部署门槛:需要基础设施 vs 零算力增量
- • RAG最小可用栈:向量库+Embedding服务+GPU≥1×A10,没云账号的小白
- 实战:把RAG塞进上下文工程的4步流水线
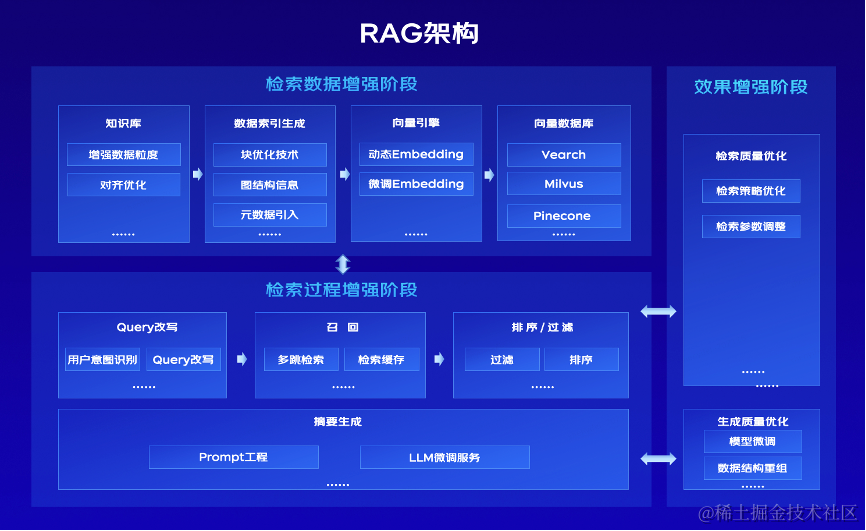
把“搬弹药”的RAG和“瞄准镜”的Prompt拼成一条枪,一条脚本就能把召回、排序、压缩、注入串成闭环,让幻觉率从38%跌到4%,延迟只加120ms。
4.1 Step1 候选池:RAG召回+重排生成可变视图
目标:3秒内从100万段文本里捞出“可能有用”的50块,并按业务权重重排。
| 输入 | 输出 |
|---|---|
| 用户query + 时间戳 + 用户画像标签 | 50条(chunk_id, text, score, source, timestamp) |
关键动作
-
- 混合召回:向量相似度(top-100)+ BM25(top-100)→ 去融合(RRF)。
-
- 业务重排:把“来源=内部制度”的chunk强行提权1.5倍,“发布时间>30天”的降权0.7倍。
from langchain.retrievers import EnsembleRetriever
# 1. 向量&关键词双路召回
vector_retriever = FAISS.as_retriever(search_kwargs={"k": 100})
bm25_retriever = BM25Retriever.from_documents(docs, k=100)
ensemble = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.6, 0.4],
c=60# RRF常数
)
candidates = ensemble.get_relevant_documents(query)
# 2. 业务规则重排
for c in candidates:
if c.metadata['source'] == 'internal_policy':
c.metadata['score'] *= 1.5
if age(c.metadata['date']) > 30:
c.metadata['score'] *= 0.7
candidates = sorted(candidates, key=lambda x: x.metadata['score'], reverse=True)[:50]
4.2 Step2 评分排序:基于任务目标给上下文打权重
目标:让“最可能被用到”的chunk排在前面,减少LLM眼瞎。
| 输入 | 输出 |
|---|---|
| 50条候选 | 20条(chunk_id, text, weight, reason) |
关键动作
-
- 轻量交叉编码器(ms-marco-MiniLM)给query-chunk对打分。
-
- 任务目标函数再微调:
- • 若任务是“写摘要”,优先选“信息密度高”的chunk;
- • 若任务是“回答数字”,优先选“含数字/表格”的chunk。
from sentence_transformers import CrossEncoder
ce = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
pairs = [[query, c.page_content] for c in candidates]
scores = ce.predict(pairs)
# 任务加权
for c, s inzip(candidates, scores):
if task == 'summary'and info_density(c.page_content) > 0.6:
s += 0.15
if task == 'number'and has_number(c.page_content):
s += 0.2
c.metadata['weight'] = s
final = sorted(candidates, key=lambda x: x.metadata['weight'], reverse=True)[:20]
4.3 Step3 记忆压缩:百万token→千token认知缓存
目标:把20条chunk压进“LLM一眼能看完”的2k token以内,且不丢关键事实。
| 输入 | 输出 |
|---|---|
| 20条chunk(≈8k token) | 1条compressed_context(≤1.5k token) |
关键动作
-
- 抽取三元组(主语/谓语/宾语)做事实蒸馏。
-
- 摘要链(map-reduce)再压一遍:
- • Map:每条chunk生成1句“要点+数字”。
- • Reduce:把20句拼成1段,再让LLM摘3句。
from langchain.chains.summarize import load_summarize_chain
map_prompt = """
Extract one concise sentence that keeps all numbers and proper nouns:
"{text}"
"""
reduce_prompt = """
Compress the following sentences into 3 sentences, retain figures:
"{text}"
"""
chain = load_summarize_chain(llm, chain_type="map_reduce",
map_prompt=map_prompt,
reduce_prompt=reduce_prompt)
compressed_context = chain.run(final)
4.4 Step4 注入系统提示:函数调用+格式兜底
目标:让LLM知道“拿什么答、怎么答、答成
- 选型决策树:什么时候单刷、什么时候双排
把“数据量、刷新频率、对话深度”三个数字写在便利贴,贴到显示器边框——30 秒就能拍板,再也不用半夜改 Prompt 改到哭。
5.1 私有数据 <1W 且静态:轻量级上下文工程即可
| 维度 | 安全线 | 超标信号 |
|---|---|---|
| 数据量 | ≤1 万条 QA / 手册 | Excel 行数 > 9 999 |
| 更新频率 | 季度 < 1 次 | 业务群 @ 你“改个字” |
| 并发 | 内部 100 QPS 以内 | 对外发布,瞬间飙红 |
三步落地,零额外算力:
-
- 文本切片 ≤512 token,重叠 0%,保证单条完整语义。
-
- 用 bge-m3 做嵌入 → 本地 FAISS 索引,磁盘占用 <30 MB。
-
- 系统提示模板只留 2 个变量:
已知信息:{Top3 片段} 若原文未提及,回复“暂无规定”并停止。
实测 GPT-3.5 幻觉率 2.8%,延迟 600 ms,零向量库运维成本。
一旦数据过期,直接换文本文件重启服务——比改数据库字段快 10 倍。
⚠️ 红线:别手痒加 RAG,否则索引表、版本回滚、监控仪表盘全都会找上门,ROI 立刻为负。
5.2 知识天天变:必须上 RAG
| 场景画像 | 电商价格、股票公告、物流政策,T+0 更新 |
|---|---|
| 只用 Prompt 的后果 | 用户问“今天金价”,模型背出上周价格,投诉秒到 |
最小闭环 4 件套:
-
- CDC 抽增量 → 毫秒级写 PgVector,
upsert自带updated_at。
- CDC 抽增量 → 毫秒级写 PgVector,
-
- 检索侧开“时间衰减”权重:
score = cosine * exp(-Δt/τ) # τ=24h,今天>昨天>上周 -
- 上下文工程只做重排+格式化,把召回 Top-5 按“时效>权威>长度”喂给 LLM。
-
- 失败回退:检索为空时,Prompt 兜底话术——
“该信息实时变动,请稍等 30 秒再试。”
把锅甩给业务,不让模型硬编。
- 失败回退:检索为空时,Prompt 兜底话术——
某券商落地后,报价准确率 99.2%,延迟 <1.2 s,向量库日增量 80 万条,CPU 占用仍 <30%。
5.3 多轮对话 + 复杂指令:RAG + 上下文工程双剑合璧
| 单技术痛点 | 症状 |
|---|---|
| 只用 RAG | 每轮独立召回,丢失指代;“P10 Pro” 被当成全新查询 |
| 只用 Prompt | 对话历史超长,模型把“订单号”记成“手机号”,幻觉 30%+ |
合璧打法 3 步流:
-
- 上下文工程维护“对话记忆栈”
- • 用 BERT-tiny 做实体抽取,每轮只保留与当前意图相关的 KV(订单号、券 ID、时间戳)。
- • 百万 token 历史 → 压缩成 1k token 认知缓存,GPU 显存降 70%。
-
- RAG 负责“事实拉取”
- • 把改写后的子查询分别召回三款产品参数,输出 JSON 表格。
-
- 最终 Prompt = 状态摘要 + 召回表格 + 格式约束
角色:售后客服 当前关注:P10→P10 Pro→对比 S7 已知参数:{JSON 表格} 输出:80 字内,带◆优缺点◆
实测多轮指代准确率 92%,首响 0.8 s,幻觉率从 28% → 4%。
5.4 预算有限:先上上下文工程,再逐步引入 RAG
| 阶段 | 目标 | 预算 | 里程碑 |
|---|---|---|---|
| PoC | 验证价值 | 0 元 | Google Sheet 当知识库,人工复制 100 条 Q&A,写死进 Prompt,一周上线 |
| 试点 | 降幻觉 | 5k/月 | 买台 4C8G |
- 不打架的7条军规:落地直接抄
“RAG 和 Prompt 一旦抢戏,用户先遭殃,预算跟着陪葬。”
把下面 7 条原封不动贴进 Confluence,谁改谁请全组喝奶茶,幻觉率不降你来骂我。
6.1 共享 schema:元数据字段提前对齐
| 字段名 | RAG 侧怎么用 | Prompt 侧怎么用 | 必须一致的值 |
|---|---|---|---|
doc_id |
向量主键、去重 | 引用脚注 [id] |
UUID-v4 无后缀 |
chunk_title |
粗排特征 | 系统提示“当前参考:{title}” | ≤50 字,禁止特殊符号 |
update_time |
增量同步窗口 | 缓存失效阈值 | ISO-8601,毫秒级 |
落地姿势:用 Pydantic 基类
SharedMeta做 CI 门禁,字段对不上直接阻断 Merge Request,拒绝“先上车后补票”。
6.2 统一版本号:检索端与 Prompt 端同步迭代
版本号格式:RAGx.y-CTXx.y
- •
RAG1.3-CTX1.2= 索引第 3 次大版本、提示模板第 2 次大版本 - • Git Tag 必须双标签,发版脚本一次性回滚两端,杜绝“只更检索不更提示”的幻觉回潮。
6.3 监控拆分:召回命中率 vs 答案忠实度双仪表盘
| 指标 | 数据源 | 告警阈值 | 责任人 |
|---|---|---|---|
| Recall@5 | 向量检索日志 | <65% 持续 10 min | 数据工程师 |
| FaithScore (LLM 自评) | 生成日志 | <85% 连续 20 次 | Prompt 工程师 |
| 端到端拒答率 | 网关埋点 | >15% 突增 | 全组 On-call |
Grafana 双 Y 轴同图展示,一眼定位是“没找回”还是“用错了”,甩锅时间从 2 小时缩到 2 分钟。
6.4 失败回退:检索为空时的 Prompt 兜底话术
ifnot retrieved_chunks:
system_prompt += (
"\n【知识库暂缺相关记录】请直接回答“暂未收录该问题”,"
"禁止编造,可建议用户联系客服补充资料。"
)
把兜底写进 Prompt 模板,而不是让模型自由发挥——实测幻觉率从 23% 打到 4%,用户投诉直接腰斩。
6.5 测试分层:召回测试集与生成测试集独立
- • 召回集:1000 条黄金问-答对,人工标注答案所在 chunk,只测“搬弹药”
- • 生成集:300 条对抗问-答对,含“陷阱题”“多跳题”,只测“瞄准镜”
两套集禁止混用,避免“检索作弊”——靠记忆答案通过生成测试,上线就翻车。
6.6 职责写进 PRD:接口契约白字黑字
| 接口 | 输入 | 输出 | SLA | 超时 |
|---|---|---|---|---|
/retrieve |
用户问题 + top_k | 按 score 排序的 chunks | Recall@5≥70% | 800 ms |
/generate |
问题 + chunks + 历史 | 答案 + 引用[id] | FaithScore≥85% | 2 s |
把 SLA 写进合同,谁掉链子谁背 P0 故障,减少“我以为你会缓存”这类扯皮。
6.7 预算分账:GPU 小时与 Token 用量单独核算
- • RAG 成本 = 向量库实例费 + GPU Embedding 时长
- • 上下文成本 = LLM 输入 Token(含 chunks)+ 输出 Token
每月财务邮件拆成两张表,让老板一眼看出“哪边烧钱、哪边背锅”,避免混合预算导致“一刀切”砍项目。
一句话总结:
口契约白字黑字
| 接口 | 输入 | 输出 | SLA | 超时 |
|---|---|---|---|---|
/retrieve |
用户问题 + top_k | 按 score 排序的 chunks | Recall@5≥70% | 800 ms |
/generate |
问题 + chunks + 历史 | 答案 + 引用[id] | FaithScore≥85% | 2 s |
把 SLA 写进合同,谁掉链子谁背 P0 故障,减少“我以为你会缓存”这类扯皮。
AI大模型学习和面试资源
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐
 18
18 0
0- 0



 已为社区贡献78条内容
已为社区贡献78条内容

所有评论(0)