
【干货收藏】AI应用开发实战:从0到0.8,AI Agent架构演进与实战经验
本文分享了参加讯飞AI大赛的实战经验,虽然只获得0.8分,但详细记录了从零构建AI Agent系统的完整历程。文章重点讲述了架构演进过程:从Simple RAG到自定义工具+ReAct,再到状态管理和模板机制,解决了Token超限等关键问题。同时分享了处理LLM"偷懒"和"想当然"的技巧,以及针对Jaccard评分标准的答案优化策略。最终总结出架构设计、不完全信任模型、为失败设计等核心经验,为AI
前段时间参加了讯飞的一个比赛,最终的成绩是0.8左右。这个分数,离“完美”相去甚远,但它背后,却是一次从零开始构建AI Agent系统的完整征途——充满了深夜的Bug、推倒重来的架构和“白花花”的Token消耗。这不完美的胜利,恰好是真实世界AI应用开发的缩影。
所以,我决定把这个项目复盘出来,用一场真实的战斗,带你走一遍AI Agent的构建之路,看看我是如何从最初的“天真”想法,一步步被现实“毒打”,最终搭建出一个能解决复杂问题的系统的。
这篇文章,无关炫技,全是干货。我会聚焦于架构的演进和问题的攻防。
01 系统的起点:数据先行
任何AI系统,数据都是原点。大赛给的数据是JSON格式的企业私有数据,第一步,就是把它摸透。
1.1 数据读取
首先我们来看问题:大赛要求我们搭建一套基于企业私有数据的问答系统。给出的数据是JSON存储的。我们首先要对数据做一个了解,知道数据的结构是什么样子。
import json
def read_json_file(file_path):
try:
with open(file_path,'r') as file:
data = json.load(file)
return data
except FileNotFoundError:
print(f"错误:文件 '{file_path}' 未找到")
return None
except json.JSONDecodeError as e:
print(f"错误:JSON解析失败 - {e}")
return None
except Exception as e:
print(f"错误:读取文件时发生意外错误 - {e}")
return None
# json_data = read_json_file('graph_data.json')
# entities_dic = json_data['entities']
# attributes_dic = json_data['attributes']
# relations_list = json_data['relations']
# 以实体 "EFM8664" 为例
print(entities_dic['EFM8664'])
# 输出: {'关联服务/APP ID': 'EcoLifeApp-100', '所属产品线': '智能家居系列'}
print(attributes_dic['EFM8664'])
# 输出: {'生产年份': 2012.0, '成本(RMB)': 756.71, ...}
print(relations_list[0])
# 输出: {'source': 'EFM8664', 'type': '兼容设备', 'target': 'KLT6358-Plus'}
1.2 数据梳理
有了这个初步的了解以后,我们接下来要做的就是梳理和清洗数据,对于这类结构的数据三水总结了一个结构化数据梳理七步走,按照走这个基本不会有什么遗漏。
(1)字段盘点: 列出所有数据字段,一个不漏。
(2)关联确认: 若有多个数据源,明确关联键(Foreign Key),并注意一对多关系。
(3)主键探查: 确定核心主键(Primary Key),检查是否存在重复?重复是脏数据还是业务逻辑?
(4)类型定义: 为每个字段强制定义数据类型(int, string, date, float),特别留意列表、嵌套JSON、逗号分隔值等“伪装者”。
(5)逻辑校验: 检查数据间的逻辑冲突。比如“生产年份是2025,销售日期却是2015”,这种“时空穿越”的坑必须填平。
(6)结构化建模: 将梳理后的数据,设计成规范的结构化表(如数据库表或CSV)。
(7)数据清洗与迁移: 将数据导入新结构。对 null, None, “”, “无” 等空值进行标准化处理,赋予其统一的“空”状态。
到此我们完成了数据梳理,别急着开始,数据梳理远未结束,最关键的一步是建立你对数据的“体感”:
(1)数值类: 最大/小值、中位数、均值是多少?有没有离谱的异常值?
(2)离散类: 值的分布是怎样的?有没有“长尾效应”?
(3)业务理解: EFM8664 兼容 KLT6358-Plus,那么反过来,KLT6358-Plus 的数据里是否也体现了这种兼容关系?
有了这些基于业务的了解你才能更好的构建出能正确回答问题的智能体。
到此我们完成系统最重要的一部分———数据的构建,这是我们一切的基础,一定要重视。
在这个项目中,我最终将数据整理为两张核心表:entity (实体属性表) 和 relation (实体关系表)。
02 架构演进之路:由失败驱动的重构之路
前菜吃完,上正餐。这条路,我走了四次,每一次重构,都是一次惨痛但深刻的领悟。
2.1 艰难的起点:Simple RAG
我的第一个想法简单粗暴:题目给了所有问题,那我为每个产品型号写个查询接口,至于聚合、计算?我先手动算出来,毕竟“有多少人工,就有多少智能”。
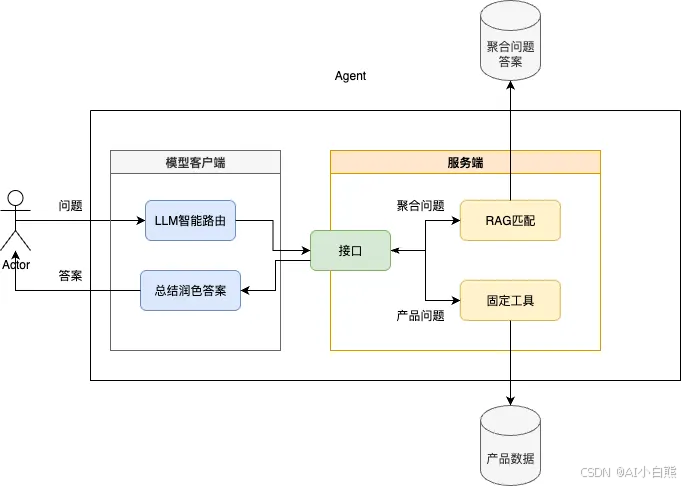
整体流程为:
(1)接受到用户提问后我们先将问题送入智能路由,确定该问题是RAG匹配还是固定工具查询问题。
(2)模型返回答案后我们调用服务端接口,将问题送入服务端进行答案的获取。
(3)服务端根据智能路由的分配调用RAG匹配或固定工具获得答案,通过接口返回到模型客户端。
(4)客户端使用模型总结润色答案,给出输出。
结果: 但很快啊,很快,我这个老同志就顶不住了,聚合问题太多了,我一个一个搞得搞到啥时候,万一官方后来整个测试集我这“人工智障”不就没了?蒜鸟,蒜鸟,推翻重构吧。
2.2 胎死腹中的第二步: Text-to-SQL
既然是结构化数据,最优雅的方案莫过于 Text-to-SQL。让 LLM 自己写 SQL 查询数据库,多酷!
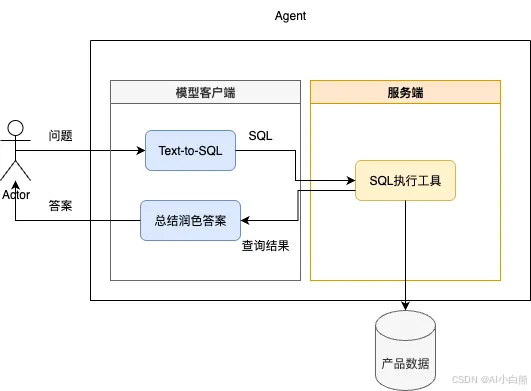
整体流程为:
(1)接受用户问题送入文本转SQL模型,生成SQL语句。
(2)送入服务端SQL执行工具进行查询。
(2)将查询结果送入模型总结润色答案,给出输出。
然而,我还没来得及建库,就想到了两个致命问题:
(1)不可控:LLM 写出的 SQL 一旦出错,我无法有效纠正,只能不断为错误打补丁,治标不治本。
(2)能力不足:通用小模型写 SQL 的能力本就有限,在没有专门数据集进行微调的情况下,这无异于一场豪赌。
调研发现,Text-to-SQL 是个专门的研究领域,水深坑多。
果断放弃,继续重构!
2.3 第一次过招:自定义工具 + ReAct
既然 SQL 这条路不通,那我就自己造一个“数据库”——封装一套自定义的查询工具(Function Calling),让 LLM 通过 ReAct 的范式来调用。这样,工具的行为完全由我定义,可控性大大增强。
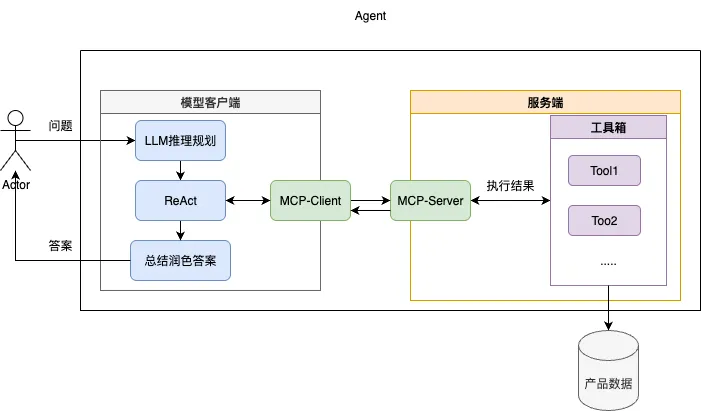
整体流程为:
(1)接受用户问题先送入LLM根据当前Prompt中提供的工具进行推理并初步规划出相应的执行计划。
(2)送入ReAct循环中依次通过MCP调用服务端提供的工具,并根据工具反馈的内容决定下一步应该如何进行。
(3)当ReAct认为当前数据已可以回答问题或者超过最大执行次数后,将当前的结果内容送入LLM总结润色答案,给出最终输出。
这里我们使用ReAct范式实现智能体,使用MCP协议+Function calling提供工具箱的使用能力,提示词规范模型的行为。
这里简单展示下客户端交互的伪代码
while not done:
thought = llm.think(prompt, history)
action, params = llm.plan(thought)
observation = execute_tool(action, params)
history.append((thought, action, observation))
bug来的太快,就像龙卷风
BUG
我搭好整个流程,测试了几个问题发现没问题,就挂到后台去跑全部问题了。等再看的时候就是满屏的报错了。分析了一下除了缺少工具的报错,最主要的就是两类:
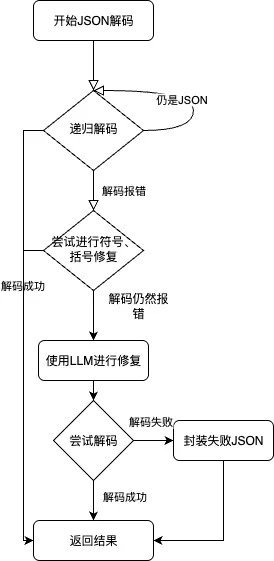
(1)json解析报错,主要的报错分为几类
- 递归编码
- 存在一些特殊符号,或者括号无法匹配
- 整个JSON格式完全不对
这个问题还是很好解决的我们用一个多段修复的程序,基本解决所有的JSON问题,具体流程如下图所示:
(2)429请求超限
这个问题就更好解决了,429是LLM模型的平台做的限制策略,用个简单的装饰器,用几乎无侵入的方式,完成了暂停重试策略的添加。
def retry_on_rate_limit(logger:Logger,max_retries: int = 3, delay: int = 90):
"""
一个装饰器工厂,用于在遇到API速率限制(RateLimitError)时自动重试一个异步函数。
Args:
max_retries (int): 允许的最大重试次数。
delay (int): 每次重试前等待的秒数。
Returns:
Callable: 一个可以应用到异步函数上的装饰器。
"""
def decorator(func):
@functools.wraps(func)
async def wrapper(*args, **kwargs):
"""
这是包装函数,它包含了重试的核心逻辑。
它会替代原始的函数被调用。
"""
last_exception = None
for attempt in range(max_retries):
try:
# 尝试像平常一样调用原始的异步函数
return await func(*args, **kwargs)
except RateLimitError as e:
# 如果捕获到速率限制错误 (HTTP 429)
last_exception = e
logger.warning(
f"API速率限制已超出。函数 '{func.__name__}' 将在 {delay} 秒后重试... "
f"(尝试 {attempt + 1}/{max_retries})"
)
# 如果这是最后一次尝试,就不再等待,直接准备抛出异常
if attempt + 1 == max_retries:
break
# 等待指定的秒数
await asyncio.sleep(delay)
except Exception as e:
# 如果是其他类型的错误,则不进行重试,直接抛出
logger.error(f"执行函数 '{func.__name__}' 时发生未知错误: {e}", exc_info=True)
raise e
# 如果循环结束(意味着所有重试都失败了),则抛出最后一次捕获到的异常
logger.error(f"函数 '{func.__name__}' 在 {max_retries} 次尝试后最终失败。")
raise last_exception
return wrapper
return decorator
解决了这些小问题,一个更大的坑在等着我。
2.4 我踩过最大的坑就是太相信LLM:AI也需要记笔记
再次全量运行,问题没解决几个,钱包先空了30块。日志里满屏的 “Token a超长”。
病因
某个查询步骤返回了一个巨大的中间结果(比如几千条记录),Agent 把它一股脑全塞进了下一步的 Prompt 里,瞬间爆炸。
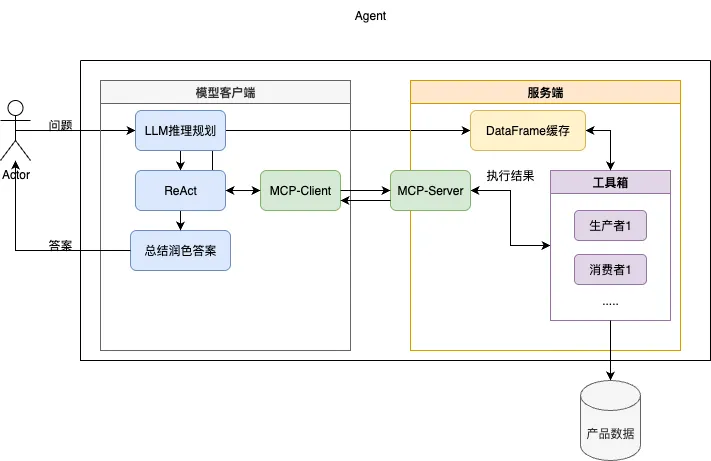
痛定思痛,架构再进化!这次,我借鉴了 Java 的流式操作(Stream),引入了状态管理。
- 生产者:在接受数据的时候除了查询参数还会接受一个存储数据的DataFrame对象作为查询的数据源,返回数据中则会封装一个对象,这里包含了处理过后的数据句柄(即新DataFrame的Id)以及这批数据的元信息(字段名称,3条样例数据,列表长度)。
- 消费者:只负责把数据转换成json格式,然后送给LLM生成最终答案。
- 同时提供一个DataFrame(后缩写为DF)的缓存和一个缓存清理方法。
整体流程为:
(1)接受用户问题先送入LLM根据当前Prompt中提供的工具进行推理并初步规划出相应的执行计划。
(2)送入ReAct循环中依次通过MCP调用服务端提供的工具并通过DataFrame缓存对生产者或消费者注入对应的Data Handler,并根据工具反馈的元数据内容决定下一步应该如何进行。
(3)当ReAct认为当前数据已可以回答问题或者超过最大执行次数后,调用消费者将当前的结果内容送入LLM总结润色答案,给出最终输出。
这样,无论中间结果多大,在 Prompt 里流转的只是轻量的元信息。我以为胜券在握,但意外还是发生了。
不出意外的话,又要出bug了!

记不记得我之前文章中提过的事情:大模型本质是个下个词元预测模型,他在生成答案的时候对我的句柄名做预测了,生成了一个完全不存在的句柄名。导致执行器直接报错。
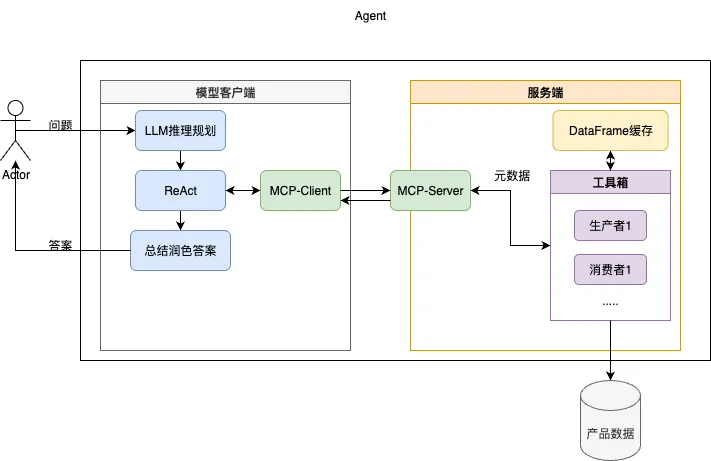
这次我将责任划分的更清晰了,LLM作为无状态的规划师,只负责规划怎么搞,以及填什么参数。Server作为有状态的执行器,自动缓存当前的句柄并在执行后更新。client作为有状态的大脑,获取server的句柄,直接注入正确的句柄。这次彻底根治了状态问题,模型可以开始正常的思考然后回答问题了。
整体流程为:
(1)接受用户问题先送入LLM根据当前Prompt中提供的工具进行推理并初步规划出相应的执行计划。
(2)入ReAct循环中依次通过MCP调用服务端提供的工具,服务端根据DataFrame缓存对生产者或消费者注入对应的Data Handler,模型客户端根据服务端反馈的元数据内容决定下一步应该如何进行。
(3)当ReAct认为当前数据已可以回答问题或者超过最大执行次数后,调用消费者将当前的结果内容送入LLM总结润色答案,给出最终输出。
2.5 最后的鸿沟:怎么又在最后爆炸了呢?
终于回答出了大部分问题,但日志里还存在着几个Token超限,一看问题,原来是要返回查询出来的全部数据。那就再修改架构吧
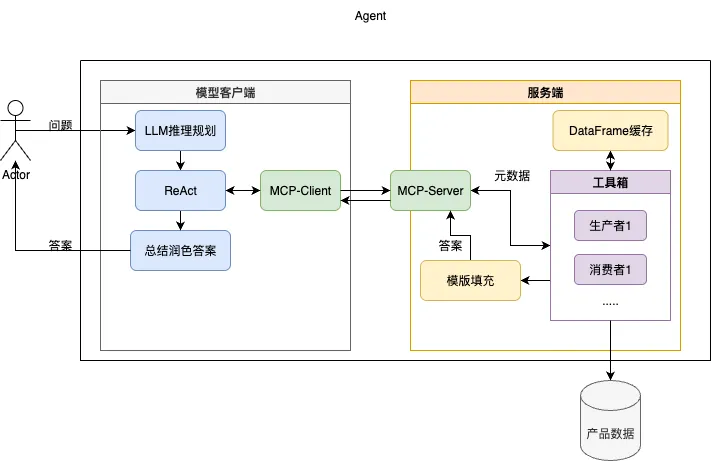
这次我们直接引入模版机制,当LLM看到元信息中的 length 超出限制时,它不再要求返回完整数据,而是生成一个带占位符的答案模板。
模板示例:“查询结果共有XX条,具体如下:\n{DATA_PLACEHOLDER}”
最终由客户端负责获取完整数据,并完成模板的填充。
整体流程为:
(1)接受用户问题先送入LLM根据当前Prompt中提供的工具进行推理并初步规划出相应的执行计划。
(2)送入ReAct循环中依次通过MCP调用服务端提供的工具,服务端根据DataFrame缓存对生产者或消费者注入对应的Data Handler,模型客户端根据服务端反馈的元数据内容决定下一步应该如何进行。
(3)当ReAct认为当前数据已可以回答问题或者超过最大执行次数后,根据最终返回的元数据信息调用消费者将当前的结果内容送入LLM总结润色答案,若元数据长度过长则调用模版填充,给出最终输出。
至此,架构终于稳定。这条由失败驱动的重构之路,每一步都代价不菲,但也收获满满。
03 千难万险:模型你怎么老坑我?
宏观上的演进路线讲完了,但魔鬼隐藏在细节中,让我们来看一下我在这次构建的细节中踩过的坑有哪些?
LLM的“偷懒”——只选择第一个的并列处理失败
(1)问题场景
问题:哪个生产批次号出现的次数最多?并且该批次号对应的累计销量平均值是多少?
Agent的处理逻辑:为了回答这个问题,我将执行以下步骤:
- 使用 get_most_common_attributes 找出出现次数最多的生产批次号。
- 使用 execute_query 筛选出该生产批次号的所有记录。
- 使用 get_scalar_aggregation 计算这些记录的累计销量平均值。
问题分析:
在这个问题中第一次聚合后,存在多个并列的结果,但模型会忽略掉这个多个并列,只选择一个最终导致答案的错误。同时当存在多个并列时,我当时的工具并不能提供查询,只能让模型一步一步的去查询,这样也会引入更多的错误。
(2)解决方案
我们要纠正他的这种想法,就要通过提示词结合工具简化的方式,让他跳过Top这种逻辑的判断,于是我编写了这样一个提示词以及代码。
配方 12:复杂分组分析 (关键配方)
用途: 当一个问题需要基于一个聚合指标(如计数、总和)找到最佳分组,然后再查询这些分组的【另一个】聚合指标时。
核心理念: 使用【多维度聚合】一步到位,而不是繁琐地分步操作。这从根本上解决了处理“并列第一”结果的难题。
计划:
1. 识别出问题中的分组依据(例如 '生产批次号')。
2. 识别出问题需要计算的所有聚合指标(例如 '产品ID' 的 'count' 和 '累计销量' 的 'mean')。
3. 调用【一次】升级版的 `get_grouped_aggregation`,将所有聚合任务放入 `aggregations` 字典中。
4. 使用 `sort_by_col` 和 `top_n` 参数直接筛选出最终结果。
5. 调用 `consume_data_to_text` 展示这个小而精的最终结果表格。
错误范例: 先用 `get_most_common_attributes` 找出现次数最多的批次号,然后只选择第一个进行后续计算。
正确示例:
问题: "哪个生产批次号出现的次数最多?并且该批次号对应的累计销量平均值是多少?"
计划:
1. (思考): 我需要按“生产批次号”分组。我需要两个指标:设备数量(即 产品ID 的 count)和平均销量(即 累计销量的 mean)。我要按设备数量降序排序,并找出最高的那组。
2. (行动): 调用 `get_grouped_aggregation(
group_by_col='生产批次号',
aggregations={'产品ID': 'count', '累计销量': 'mean'},
sort_by_col='产品ID_count',
ascending=false,
top_n=1
)`
3. (观察): (得到一个句柄,其指向一个包含所有并列第一的批次号,及其对应设备数和平均销量的 DataFrame)
4. (行动): 调用 `consume_data_to_text(...)` 将结果呈现给用户。
LLM的“想当然”——关系理不清与思维僵化
(1)问题场景
『 案例A(关系混淆)』
问题:查询型号为"EFM8664"的设备所兼容的设备信息。
智能体在处理这个问题的时候的逻辑是:为了查询型号为 “EFM8664” 的设备所兼容的设备信息,我将首先使用 find_products_by_relation 工具来查找与 “EFM8664” 兼容的所有设备,然后使用 get_full_entity_details 工具来获取这些设备的详细信息。
兼容设备是一种双向关系,他包含着A兼容B,B也兼容A,即在我们的表里“EFM8664”即是target也是source。但模型只用了source这个关系导致了最终答案的错误。
『 案例B(思维僵化)』
问题:哪个具体销售区域的建议零售价(RMB)平均值最高?并计算每个销售区域的平均建议零售价
智能体在处理这个问题的时候的逻辑是:为了回答这个问题,我将按照以下步骤操作:
- 使用 get_grouped_aggregation 按具体销售区域分组,计算每个销售区域的建议零售价(RMB)平均值。
- 使用 get_grouped_aggregation 的结果,找到平均值最高的具体销售区域。
- 使用 consume_data_to_text 将每个销售区域的平均建议零售价输出为文本。
首先,我将执行第一步,计算每个销售区域的建议零售价(RMB)平均值。
这个问题是两问,同时第二问实际上是包含第一问的。在我们的这个架构中,模型的规划是没有问题的,但在实际的执行中,模型在执行完第一步骤后直接调用了consume_data_to_text获取了最终输出文本,然后打算开始总结陈词了。在我们的架构中,为了防止Token过长,我们限制了最终文本的长度,导致模型最终输出的结果是:
体销售区域的建议零售价(RMB)平均值最高的区域是山西省-太原市,平均值为 6893.13 RMB。以下是每个具体销售区域的建议零售价(RMB)平均值:
具体销售区域,建议零售价(RMB)
山西省-太原市,6893.13
四川省-成都市,6737.35
福建省-福州市,6683.19
…
总共有 28 个具体销售区域。
模型把中间的内容全都省略了……

(2)解决方案
对于这两类问题,我们从分析中可以发现,我们已经把工具提供给他了,但模型自身思维的固定导致了他无法正确使用工具,对于这样的问题,我们就要使用提示词来规范他的行为,告诉他在面对到什么样子的情况的时候,应该怎么处理。
配方 13:两段式回答
用途: 当一个问题同时要求一个“摘要式答案”(例如“哪个最高?”、“总数是多少?”)和一份“完整数据列表”时。
核心理念: 你必须将回答分解为两个独立的部分:首先通过工具链找到摘要答案,然后在最后一步才输出完整列表。
计划:
1. 执行必要的工具调用来生成一个包含所有信息的【已排序】数据流(例如,使用 `get_grouped_aggregation` 并设置 `sort_direction`)。
2. 【关键步骤】: 观察第一步返回的 `metadata` 中的 `sample_data` 字段。由于数据已经排序,`sample_data` 中的第一行就是你的“摘要式答案”。
3. 在你的思考区 (`content` 字段) 中,先明确陈述这个“摘要式答案”。如果问题还有后续计算,则继续调用【流式工具】进行处理。
4. 直到所有计算和分析都完成后,在最后一个步骤,才调用 `consume_data_to_text(max_rows_to_show=-1)` 来获取用于展示的“完整数据列表”。
5. 在拿到完整列表后,结合你之前的思考,生成最终的、包含两部分内容的答案。
正确示例:
问题: "哪个销售区域平均价格最高?并列出所有区域的平均价格。"
步骤1 (行动): 调用 `get_grouped_aggregation(group_by_col='具体销售区域', agg_col='建议零售价(RMB)', agg_func='mean', sort_direction='descending')` -> 得到 `handle_A`
步骤2 (思考与行动):
(观察 `handle_A` 的 `metadata`,看到 `sample_data` 的第一行是“山西省-太原市,6893.13”)
在 `content` 中思考:“我已经找到了平均价格最高的区域是山西省-太原市。现在,我将获取并展示所有区域的完整列表。”
在 `tool_calls` 中调用 `consume_data_to_text(input_handle='handle_A', max_rows_to_show=-1)`。
步骤3 (最终回答):
(观察 `consume_data_to_text` 返回的文本列表)
生成最终答案:“根据计算结果,平均建议零售价最高的区域是山西省-太原市。完整的各区域平均价格列表如下:...[粘贴列表]...”
总结:善用Prompt和工具,给模型“减负”
我们的核心原则是给模型**“减负”**。让模型做它最擅长的规划、编排和总结。把所有运算、比较、状态管理等“脏活累活”交给确定性的代码工具。 明确边界,各司其职。大家可以详细的看我的代码提示词,里面详细整理了多个模型的回答配方,帮助模型进行“减负”。
04 架构好不是真的好:怎么搞出符合要求的答案
这是比赛,不仅要答对,还要答得“标准”。评分标准是 Jaccard 相似系数,即“答案交集 / 答案并集”。
这意味着,答案里多一个“的”,少一个“是”,都可能导致失分。
4.1 Jaccard 指标下的答案组织原则
直击核心,废话少说:问“哪一年?”,就只回答“2023年”,而不是“生产设备数量最多的是2023年”。
猜测标签,用词精准:思考标准答案会是什么样的词语集合。尽量使用问题和数据原文中的词,避免同义词替换。
保留单位,注意格式:数字、单位、格式都可能是评分点。
多答案处理:若有多个答案,用逗号或空格隔开,避免使用“分别是A、B和C”这样的句子。
4.2 问题本身也可能是“脏数据”
官方提供的问题列表中,也埋着坑:重复问题、空问题、问题后夹带私货等。
(1)预处理: 先清洗问题列表,生成一份干净的调试版本。
(2)提交时还原: 最终提交时,必须严格按照原始问题的顺序和格式,空问题就留空,重复问题就回答多次。
4.3 如何生成稳定的答案?
要稳定提分,必须保证模型输出的一致性。两个关键设置:
(1)temperature = 0: 将模型的“温度”设为0,关闭其创造性和随机性,让输出更具确定性。
(2)Prompt 强约束: 在最终生成答案的 Prompt 中,明确指令:“请直接给出最终答案,不要包含任何解释、分析或额外的客套话。”
05 总结与反思:如何从0.8走向1.0
这次比赛,虽然结果不完美,但过程中的收获远超预期。我总结了几条核心经验,希望能帮你少走弯路:
架构决定上限
动手编码前,花足够的时间分析问题,设计一个健壮、可扩展的架构。好的架构能帮你规避掉80%的后期问题。
永远别完全相信模型
理解LLM的本质(概率模型),利用它的长处(语言理解、规划),规避它的短处(精确计算、逻辑一致性)。为它设计“护栏”。
为失败而设计
错误是常态。重试机制、错误捕获、状态回滚……这些都是系统稳定性的生命线。尤其涉及到昂贵的Token消耗时,一个健壮的熔断和重试机制能救你的钱包。
构建黄金测试集
把你踩过的每一个坑,都变成一个测试用例。每次修改后,跑一遍黄金测试集,确保“旧病未复发,新病未引入”。
先有人工答案,再有智能系统
这是我这次最大的教训。我应该在项目初期,就手动为所有问题找到标准答案。这样,整个开发过程就从“探索未知”变成了“逼近目标”,调试和优化的方向会清晰百倍。
未来的方向——让Agent监督Agent
如果再来一次,我会引入一个“评审Agent”。它不负责解答问题,只负责审查主Agent的思维链和工具调用过程,提前拦截那些不合理的规划,实现“左脚踩右脚”式的自我进化!
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
更多推荐

 10
10 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)