
【Ai智能助手下篇】
本文主要介绍了AI应用开发的两个重要概念--工具调用和检索增强,并通过一个具体的例子,搭建一个智能助手结合进行讲解,旨在帮助小伙伴对AI在实际Java开发中的具体应用进行了解,帮助大家扩展大模型开发方面的知识。
摘要:
本文主要介绍了AI应用开发的两个重要概念--工具调用和检索增强,并通过一个具体的例子,搭建一个智能助手结合进行讲解,旨在帮助小伙伴对AI在实际Java开发中的具体应用进行了解,帮助大家扩展大模型开发方面的知识。
一,工具调用(Funtion-call)
1,基本介绍
工具调用(亦称函数调用)是 AI 应用的常见模式,允许模型通过与一组 API(即工具)交互来扩展其能力。简单来说,工具调用就是让大模型能够调用你定义好的各种工具,其中包括:信息检索、业务功能等等,使大模型变得更强大。
更多关于大模型“工具调用”的细节可以访问官网了解:工具(Tool)调用 :: Spring AI 中文文档
2,基本原理
本质就是用户提出“额外”需求,如常用的豆包的联网搜索等,也是通过网页搜索工具实现,而非大模型的功能;大模型获取工具结果然后包装返回给用户。
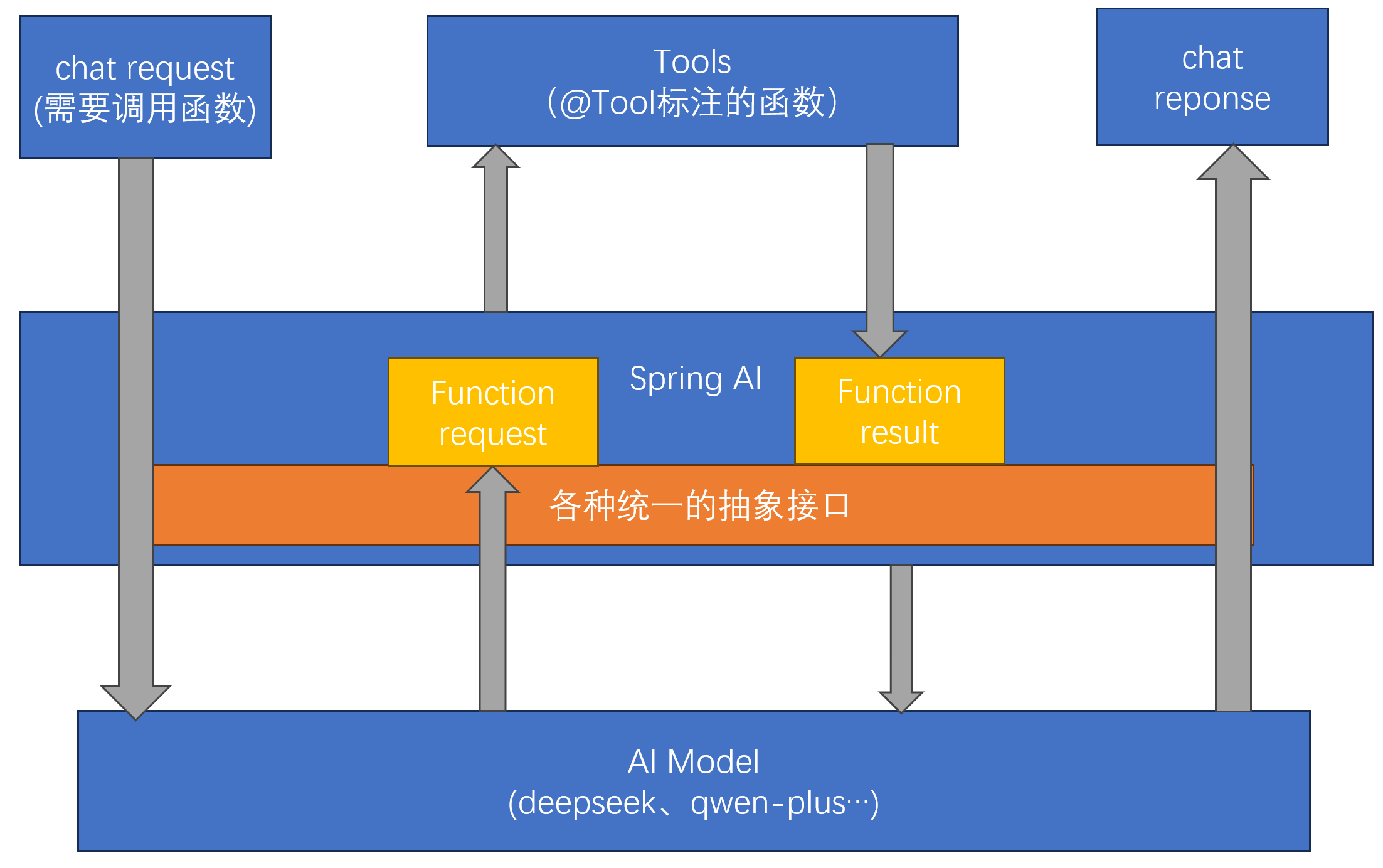
-
工具定义:当我们想让模型使用某个工具或业务方法时,我们会在聊天请求中包含该工具的定义。每个工具的定义都包括名称、描述和输入参数
-
工具调用请求:当模型决定调用工具时,它会发送包含工具名称及符合预定义模式的输入参数的响应
-
执行工具:应用程序负责根据工具名称识别对应工具,并使用提供的输入参数执行该工具
-
处理结果并返回:工具调用的结果由程序进行处理,应用程序将工具调用结果返回至模型
-
包装结果:模型最终利用工具调用结果作为附加上下文生成响应
3,具体实战
【1】@Tool注解
(1)name:工具名称。若不指定,默认使用方法名称。模型通过此名称识别调用工具,因此不允许在同一类中存在同名工具。模型处理单个聊天请求时,所有可用工具的名称必须保持全局唯一。
(2)description:工具描述,用于指导模型判断何时及如何调用该工具。若未指定,默认使用方法名称作为工具描述。但强烈建议提供详细描述,因为这对模型理解工具用途和使用方式至关重要。若描述不充分,可能导致模型在该调用工具时未调用,或错误调用工具。
(3)returnDirect:控制工具结果直接返回客户端(true)还是传回模型(false)。
【2】工具实现
(1)创建一个工具类,标注为“Component”,用于依赖注入。
(2)实现具体业务方法,也可以在该工具中调用已存在的业务方法,例如:保存用户预约看房信息并返回预约单号。
(3)通过description工具描述和参数描述让大模型了解这个函数的作用,同时函数名也应该更加规范清晰,如此一来能够使大模型对工具调用更加精准。
@Tool(description = "保存用户预约看房信息并返回预约单号")
public String setViewAppointment(
@ToolParam(description = "用户姓名") String name,
@ToolParam(description = "用户电话号码") String phone,
@ToolParam(description = "用户选择的公寓名称对应的公寓id") Long apartmentId,
@ToolParam(description = "用户给定的预约时间") Date appointmentTime,
@ToolParam(description = "用户的备注信息") String additionalInfo
){
Long userId = LoginUserHolder.getLoginUser().getUserId();
ViewAppointment viewAppointment = new ViewAppointment();
viewAppointment.setUserId(userId);
viewAppointment.setName(name);
viewAppointment.setPhone(phone);
viewAppointment.setApartmentId(apartmentId);
viewAppointment.setAppointmentTime(appointmentTime);
viewAppointment.setAdditionalInfo(additionalInfo);
viewAppointment.setAppointmentStatus(AppointmentStatus.WAITING);
boolean save = viewAppointmentService.save(viewAppointment);
if (save) {
return UUID.randomUUID().toString()+viewAppointment.getId();
}else {
return "预约失败";
}
}【3】装载工具
我们定义了许多工具(函数)等,那如何让大模型知道有哪些工具(函数)供其使用呢?放心,Spring Ai框架早就为我们考虑好了这个问题:
在构造chatClient实例中有一个defaultTools()方法,该方法接收Object参数,我们通过传入工具(函数)所在类的实例(注入或者new皆可)即可,这些工具的基本信息会自动和prompt发送给大模型,这样大模型就能够根据用户请求决定是否调用工具/哪个工具。
二,搭建RAG知识库
1,基本介绍
【1】向量模型
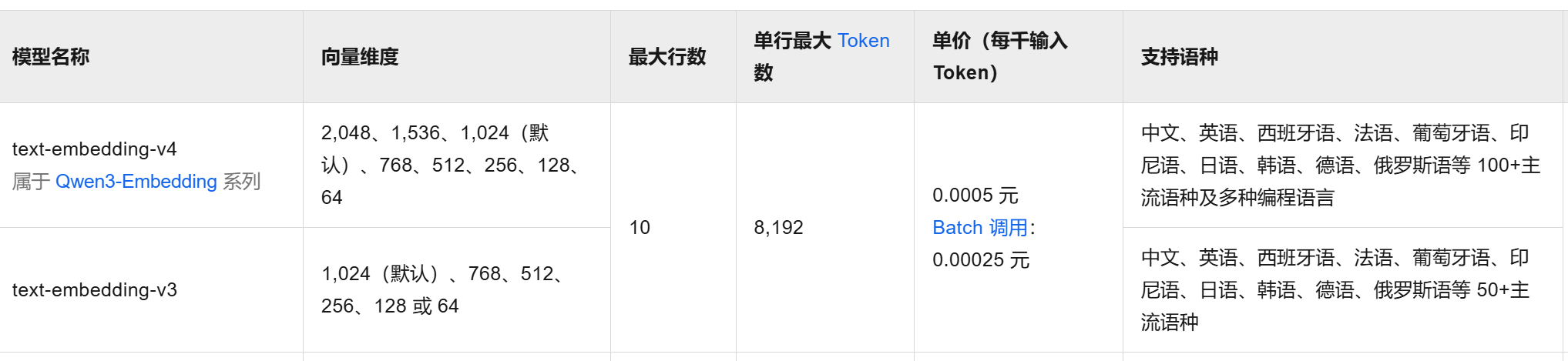
顾名思义,这种模型的主要作用就是将文本转化为设定好维数的向量,以阿里的通用向量模型text-embedding-v4、v3等为例,具体参数如下:
【2】向量数据库
向量数据库中的数据都会被向量模型(或特定算法)解析为固定维度(可以更改,一般需要与向量转化模型生成的向量维数一致)的向量[0.36732,0.74398......]
同时在向量数据库中,查询与传统关系型数据库不同,它们执行的是相似性搜索而非精确匹配,当给定一个向量作为查询时,向量数据库会返回与查询向量 “相似” 的向量
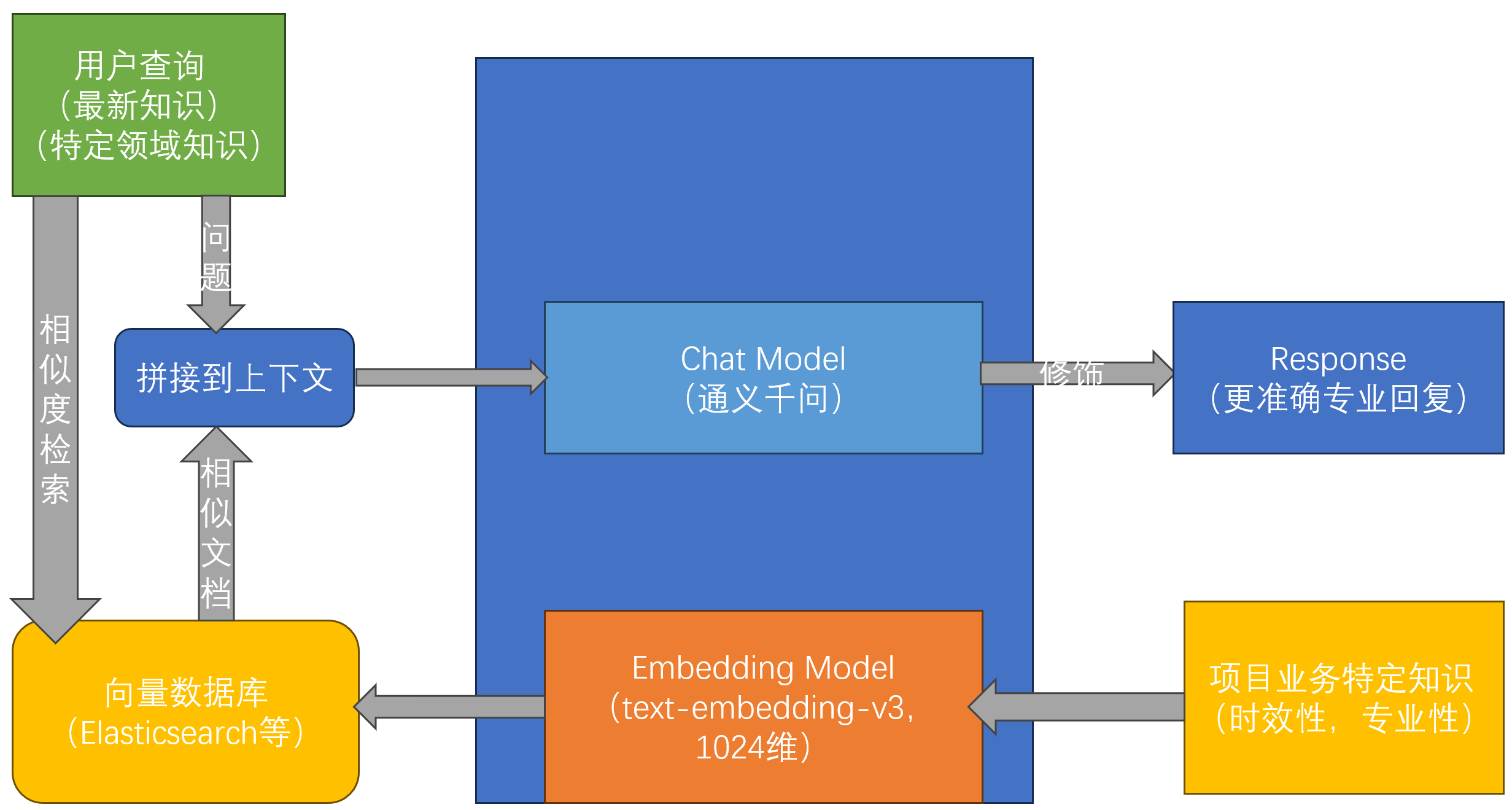
【3】RAG检索增强生成
当用户需要向 AI 模型发送查询时,首先在向量数据库中检索一组相似文档。这些文档随后作为用户问题的上下文,与用户查询整合一起发送给大模型。这种技术被称为检索增强生成。
大模型的训练需要时间,因此,大模型的回答会有滞后性,而且会捏造对专业领域问题的回答,所以通过额外的知识库可以使大模型更加真实专业。
2,基本配置
【1】引入依赖
构造rag检索增强的核心依赖“spring-ai-rag”;读取pdf文件的依赖不是必须的,这里是增加的一个额外功能--“方便管理端通过pdf导入业务知识”;连接数据库需要具体看大家选择什么数据库作为向量数据库,如果不知道自己的数据库需要引入哪个可以参考向量数据库 :: Spring AI 中文文档记载了目前各种支持的向量数据库
<!--构建RAG库的依赖-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
<version>1.0.0</version>
</dependency>
<!--读取pdf文件的依赖-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
<version>1.0.0</version>
</dependency>
<!--连接向量库的依赖-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-elasticsearch</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.18.1</version>
</dependency>【2】yaml文件配置
(1)首先是es的连接配置,IP、端口默认9200和用户名(默认)、密码
(2)下面是关于ai的es配置,初始化索引(类似表)、索引名、向量维数(这里的维数一定要和选择的向量模型一致,如:v3默认转化1024维所以这里我填写1024)和相似算法
spring:
elasticsearch:
uris: https://<host-ip>:9200<默认>
password:xxxx
username: elastic
ai:
vectors tore:
elasticsearch:
initialize-schema: true
index-name: springai-index #索引名相当于MySQL表名
dimensions: 1024
similarity: cosine【3】温馨提示(es版本>8.10)
(1)es的下载和一些配置有些麻烦,如果第一次接触es的小伙伴可以参考这个大佬的文章:
Linux环境下安装Elasticsearch,史上最详细的教程来啦~_linux elasticsearch-CSDN博客
大佬的文章非常详细,包括各种突发情况等,小伙伴自行参阅。
(2)在连接es时可能会出现SSL证书的连接问题,两种解决方案:1,在es的配置文件中关闭SSL验证机制;2,将es的SSL证书加入到jdk的信任文件中
3,代码实现
【1】构造检索增强的chatClient实例
(1)自动注入DashScope模型、VectorStore接口实现类实例ElasticsearchVectorStore和聊天记忆ChatMemory
(2)添加Rag流程的拦截器RetrievalAugmentationAdvisor,这是实现Rag的核心,下面的方法都是其增强组件,如:queryExpander、documentRetriever...等等
(3)这里的增强检索流程是:扩充问题(扩充用户问题) -> 对生成的问题进行上下文增强 -> 向量库检索 -> 拼接检索到的文件
@Bean
public ChatClient ragChatClient(
DashScopeChatModel model,
ElasticsearchVectorStore vectorStore,
ChatMemory chatMemory
) {
ChatClient.Builder expanderBuilder = ChatClient.builder(model);
ContextualQueryAugmenter contextualQueryAugmenter = ContextualQueryAugmenter.builder().allowEmptyContext(true).build();
VectorStoreDocumentRetriever vectorStoreDocumentRetriever = VectorStoreDocumentRetriever.builder().topK(3).vectorStore(vectorStore).build();
MultiQueryExpander multiQueryExpander = MultiQueryExpander.builder().chatClientBuilder(expanderBuilder).build();
return ChatClient.builder(model)
.defaultSystem(new ClassPathResource("system_prompt.txt"))
.defaultSystem("请根据上下文回答问题,遇到上下文没有的问题,不要自己随意编造")
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(chatMemory).build(),
new SimpleLoggerAdvisor(),
RetrievalAugmentationAdvisor.builder()
//扩充问题,默认3个+原来那1个
.queryExpander(multiQueryExpander)
//向量库中检索
.documentRetriever(vectorStoreDocumentRetriever)
//拼接检索到的文档
.documentJoiner(new ConcatenationDocumentJoiner())
//对生成的问题进行上下文增强:
.queryAugmenter(contextualQueryAugmenter).build()
)
.defaultTools(new AgreementTools(), new AppointmentTools())
.build();
}【2】定义RAG问答接口
接口定义基本无需改动,基本的用户prompt和聊天记忆ID,rag的具体实现和增强组件基本都包装到ragChatClient实例中,接口直接调用会自动实现检索增强
@GetMapping(value = "/chat/rag", produces = "text/html;charset=UTF-8")
public Flux<String> chatByRag(String prompt) {
return ragChatClient.prompt()
.user(prompt)
.advisors(a -> a.param(
ChatMemory.CONVERSATION_ID,
LoginUserHolder.getLoginUser().getUserId())
)
.stream()
.content();
}通过ChatClient配置这些组件,检索到的相关文档数量提升 30%~50%(尤其针对模糊查询或专业领域术语),减少的重复代码,新业务接口接入 RAG 只需一行代码,模型 “幻觉”(编造未在文档中出现的信息)概率降低,使增强检索流程更加“好用”。
【3】测试结果展示
(1)测试为了节约时间,采用的是基于内存实现的VectorStore->inMemoryVectorStore
@Bean
public VectorStore inMemoryVectorStore(DashScopeEmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}(2)测试类中注入ragChatClient,定义测试类testRAG手动向向量数据库(内存)添加数据,因为修改内存存储,原来ragChatClient实例的es暂时修改为inMemoryVectorStore即可
@Test
public void testRAG() {
List<Document> documents = List.of(
new Document("李冲,原名李思冲,字思顺。"),
new Document("李冲,陇西狄道(今甘肃临洮县)人。"),
new Document("李冲,南北朝时期北魏名臣,镇北将军李宝的幼子。")
);
inMemoryVectorStore.add(documents);
String content = ragChatClient.prompt("李冲是谁?").call().content();
System.out.println(content);(3)测试结果展示
2025-09-28T17:05:37.271+08:00 INFO 21768 --- [spring-ai] [ main] o.s.ai.vectorstore.SimpleVectorStore : Calling EmbeddingModel for document id = aa34001f-9a57-4f15-8948-1ce6db95209a
2025-09-28T17:05:37.454+08:00 INFO 21768 --- [spring-ai] [ main] o.s.ai.vectorstore.SimpleVectorStore : Calling EmbeddingModel for document id = f6b0d34b-b25b-406e-864a-5fe69d035d54
2025-09-28T17:05:37.634+08:00 INFO 21768 --- [spring-ai] [ main] o.s.ai.vectorstore.SimpleVectorStore : Calling EmbeddingModel for document id = 28e8584a-f291-4a07-838b-25851e0f4a77
李冲,原名李思冲,字思顺,陇西狄道(今甘肃临洮县)人,是南北朝时期北魏的名臣,镇北将军李宝的幼子。总结:
通过上述流程,一个完完整整的与业务紧密相连的AI智能助手已经开发完成,从基本交互-->工具调用-->最后到检索增强RAG,智能助手功能更加强大完善,重要的是各位小伙伴也从搭建的过程中加深了对AI应用开发的具体了解,这也是本文的重点,也希望大家能够根据这个例子,发挥奇思妙想开发属于自己的AI应用,提升自己的AI应用开发能力。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)