
护理 + 人工智能研究热点数据分析项目(二)
本文介绍了一个基于Selenium和MongoDB的知网论文爬取系统,用于护理与人工智能研究热点分析。系统包含6个核心模块:1)浏览器初始化与配置;2)MongoDB数据库连接;3)搜索功能实现;4)页面解析与数据提取;5)数据存储;6)自动翻页控制。系统创新性地采用动态判断翻页机制,并针对知网数据特点进行了标题清洗处理。文章还详细分析了常见问题解决方案,包括元素定位失败、驱动版本匹配、反爬虫应对
护理 + 人工智能研究热点数据分析项目


文章目录
本文了也参考了很多开源小伙伴的代码,大同小异,也不知道谁是原创作者了,所以特别感谢他们为开源代码做出的贡献!
三、代码解析:从浏览器启动到数据存储
我们将代码按功能拆分为 6 个核心模块,逐个讲解其原理与细节。
模块 1:初始化浏览器与基础配置
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# ChromeDriver路径(替换为你的实际路径)
chromedriver_path = r"C:\Users\zfj\AppData\Local\Google\Chrome\Application\chromedriver.exe"
# 创建Service对象(Selenium 4.x推荐用法,管理驱动服务)
service = Service(chromedriver_path)
# 初始化Chrome浏览器
browser = webdriver.Chrome(service=service)
# 设置显式等待(最长等待10秒,用于等待页面元素加载)
wait = WebDriverWait(browser, 10)
关键知识点:
-
Selenium 4.x 后推荐使用
Service类管理驱动,替代旧版的executable_path参数,更稳定 -
WebDriverWait是 “显式等待”,比time.sleep()更智能:仅在元素出现时继续执行,避免无效等待
模块 2:连接 MongoDB 数据库
import pymongo
# 连接本地MongoDB服务(默认端口27017)
client = pymongo.MongoClient('localhost', 27017)
# 选择/创建数据库(如果不存在,插入数据时会自动创建)
mongo = client.cnki
# 选择/创建集合(类似关系型数据库的“表”)
collection = mongo.papers
为什么用 MongoDB?
学术数据字段可能不固定(例如部分论文可能没有 “数据库” 信息),MongoDB 的文档型结构支持灵活存储,无需预先定义表结构,比 MySQL 更适合此类场景。
模块 3:搜索功能实现(核心交互逻辑)
def searcher(keyword):
# 打开知网首页
browser.get('https://www.cnki.net/')
browser.maximize_window() # 最大化窗口(避免元素因窗口大小被隐藏)
time.sleep(2) # 短暂等待,确保页面加载基础元素
# 定位搜索框并输入关键词
input = wait.until(EC.presence_of_element_located((By.ID, 'txt_SearchText')))
input.send_keys(keyword)
# 点击搜索按钮
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'search-btn'))).click()
time.sleep(3) # 等待搜索结果加载
# 设置每页显示50条(默认可能是10条,减少翻页次数)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[class="icon icon-sort"]'))).click()
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '#id_grid_display_num ul li')))[2].click()
time.sleep(3)
# 解析当前页数据
parse_page()
创新解析:
-
主动设置 “每页 50 条”:通过模拟点击下拉框选择条目数,减少翻页次数,提升爬取效率
-
元素定位策略:混合使用
ID、CLASS_NAME、CSS_SELECTOR,应对不同元素的定位需求(ID 唯一最可靠,CSS 适合复杂选择)
模块 4:页面解析(提取论文信息)
from bs4 import BeautifulSoup
def parse_page():
# 等待所有论文条目加载完成(关键!避免因加载不全漏数据)
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.result-table-list tbody tr')))
# 获取当前页面HTML
html = browser.page_source
# 用BeautifulSoup解析(lxml解析器速度快)
soup = BeautifulSoup(html, 'lxml')
# 提取所有论文行(每个<tr>对应一篇论文)
items = soup.select('.result-table-list tbody tr')
for item in items:
# 提取每行的单元格(<td>)
detail = item.select('td')
# 处理标题:去除“免费”干扰词(实际爬取中常见的脏数据处理)
title = detail[1].text.strip()
title = title.replace(' 免费', '').replace('免费', '')
# 组装论文数据字典
paper = {
'index': detail[0].text.strip(), # 索引号
'title': title, # 标题(清洗后)
'author': detail[2].text.strip(), # 作者
'resource': detail[3].text.strip(),# 来源期刊
'time': detail[4].text.strip(), # 发表时间
'database': detail[5].text.strip()# 所属数据库
}
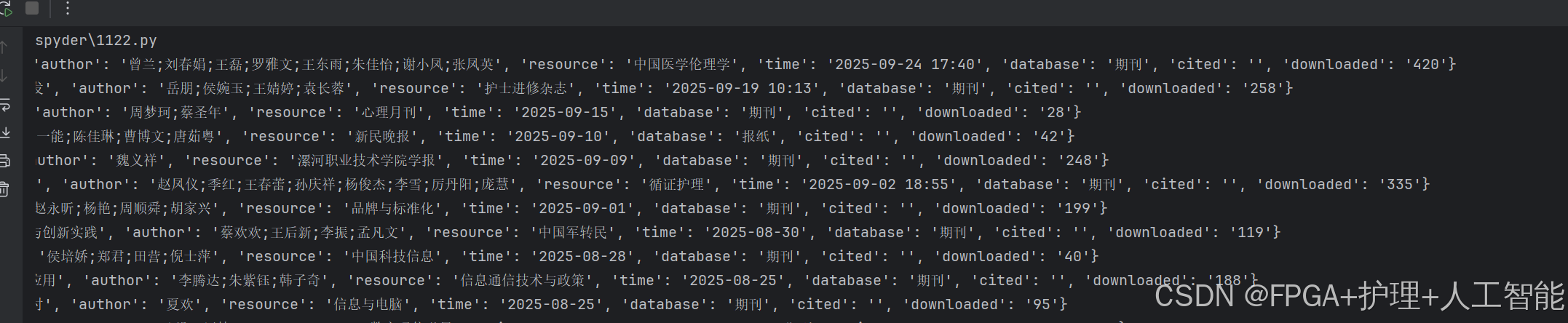
print(paper)
data_storage(paper) # 调用存储函数
数据清洗技巧:
标题中可能包含 “免费” 等广告字样,通过replace方法提前处理,避免脏数据进入数据库。实际爬取中,还可添加去除特殊字符、空格标准化等操作。
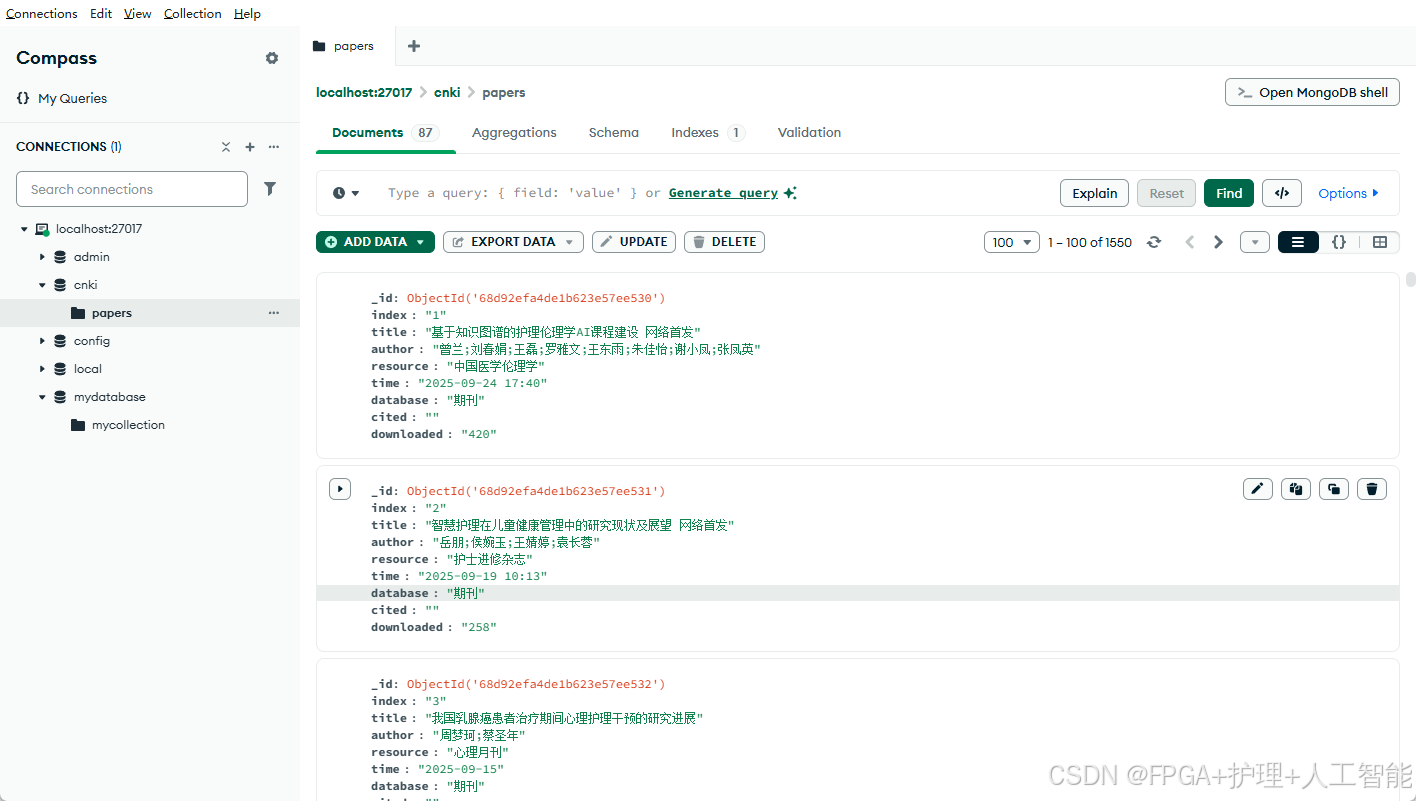
模块 5:数据存储到 MongoDB
def data_storage(paper):
try:
# 插入单条数据到集合
collection.insert_one(paper)
except Exception as e:
# 捕获异常并打印(方便调试存储失败的原因)
print('存储失败!', e, paper)
可靠性优化:
-
使用
try-except捕获存储异常(如网络中断、数据格式错误),避免程序崩溃 -
如需批量存储,可改用
insert_many,但注意单次插入数据量不宜过大(避免超时)
模块 6:自动翻页控制
from selenium.common.exceptions import TimeoutException
def next_page():
try:
# 等待“下一页”按钮可见(不可见则说明到最后一页)
page_next = wait.until(EC.visibility_of_element_located((By.CSS_SELECTOR, '#Page_next_top')))
page_next.click() # 点击下一页
return True
except TimeoutException:
# 超时说明没有下一页,返回False
return False
# 主程序入口
if __name__ == '__main__':
keyword = '护理 AI'
searcher(keyword)
# 循环翻页爬取
while True:
flag = next_page()
time.sleep(5) # 翻页后等待页面加载(时间可根据网络调整)
if flag:
parse_page() # 解析新页面
else:
break # 无下一页则退出
browser.quit() # 关闭浏览器
翻页逻辑设计:
通过next_page函数的返回值控制循环:成功翻页则继续解析,失败则结束爬取。相比固定页数循环,这种 “动态判断” 更灵活,适用于页数不固定的场景。
四、常见问题与解决
- 元素定位失败
-
原因:知网页面可能更新,导致
ID或CLASS变化 -
解决:用 Chrome 开发者工具(F12)重新定位元素,替换代码中的选择器
- ChromeDriver 启动失败
-
检查驱动路径是否正确(绝对路径用
r"路径"避免转义问题) -
确认驱动版本与 Chrome 版本匹配(版本号前 3 位需一致)
- MongoDB 连接失败
-
检查 MongoDB 服务是否启动(
net start mongodb) -
确认端口是否被占用(默认 27017,可在
MongoClient中修改)
- 爬取速度过快被反爬
-
增加随机延时(替代固定
time.sleep):import random; time.sleep(random.uniform(3, 5)) -
添加请求头(模拟真实浏览器):
from selenium.webdriver.chrome.options import Options
options = Options()
options.add\_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36')
browser = webdriver.Chrome(service=service, options=options)
最终结果
更多推荐

 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)