
实战:SQL统一访问200+数据源,构建企业级智能检索与RAG系统(下)
MindsDB是一款开源AI数据引擎,提供统一SQL接口访问200+数据源与AI模型。其知识库功能简化了向量索引创建和语义检索,支持向量+标量的混合检索,实现结构化与非结构化数据融合。通过SQL可快速构建RAG管道和数据智能体(Data Agent),支持自动数据同步和模型训练。适合作为复杂企业环境中的"虚拟AI数据底座",以"数据不出库,AI进库来"模式降低AI应用门槛,是传统企业技术栈引入AI
本篇内容:
- 知识库与混合检索的应用
- RAG与数据智能体(Agent)
- 总结与MindsDB应用建议
01 知识库与混合检索的应用
上篇我们已经体验到MindsDB的两大集成能力:数据源(RDBMS、文件、向量库等)的集成与AI模型(传统ML模型、语言模型、嵌入模型等)的集成。其独特之处在于:让你用一种统一的SQL接口方式来查询所有的数据源与模型,并能够巧妙的融合。
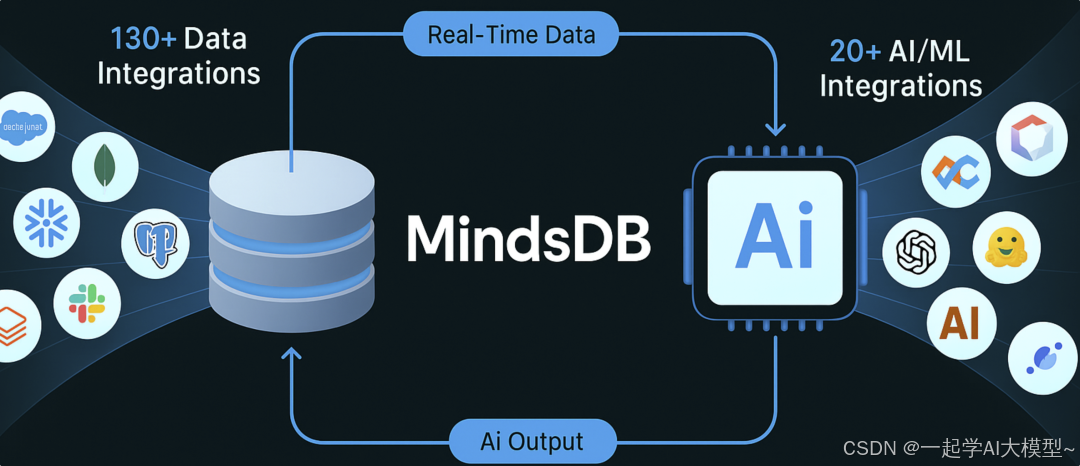
比如你可以:
-
把数据表与LLM连接,输出批量推理结果(如生成文本字段的摘要)
-
把数据表与嵌入模型连接,再与向量库连接,创建某字段的向量索引
这里的第二种场景中,如果把一个文件映射成“表”,然后通过一个SQL,就可以直接给这个文件创建向量索引。比如:
create table my_chromadb.collection_name(select m.embedding as embeddings,f.content,f.metadatafrom files.table1 f join my_emb_openai m )
现在你可以查询这个向量库中的“表”实现语义检索、拓展应用(如RAG)。
尽管这个过程已经非常直观与友好,但是你仍然需要如下步骤:
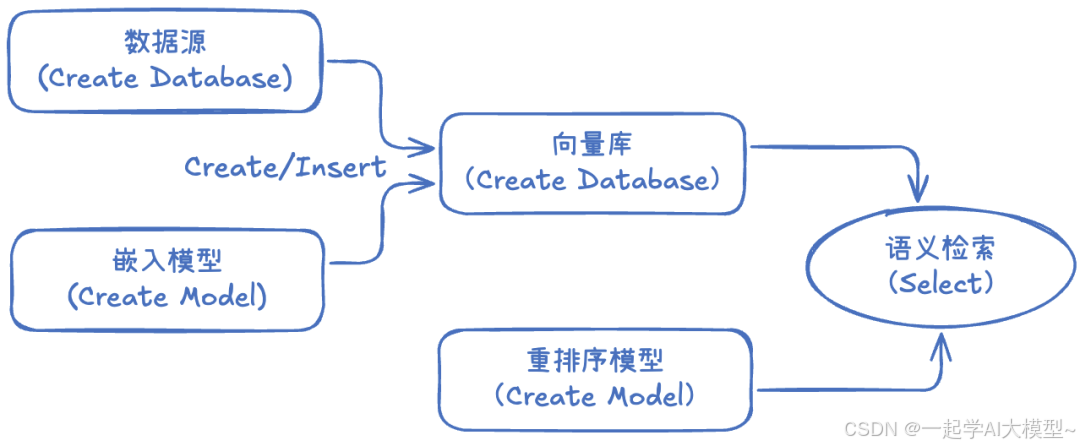
- 映射数据源(DB或者文件):用来读取需要向量化的数据
- 创建向量库:用来存储向量与索引,提供语义检索
- 创建嵌入模型:用来生成输入数据的向量
- 创建向量索引:将必要的源数据向量化
- 语义检索:对向量数据库执行语义检索
- 重排序(可选):对检索的内容通过Rerank模型重排序
为了简化这样的场景,MindsDB推出一种更高级的特性:知识库(Knowledge Base)。
【什么是MindsDB的知识库】
简单的总结:
知识库就是融合嵌入模型、向量数据库、Rerank模型的能力,把上述多个数据组织步骤进一步简化的一种虚拟AI“表”。
原理示意如下:
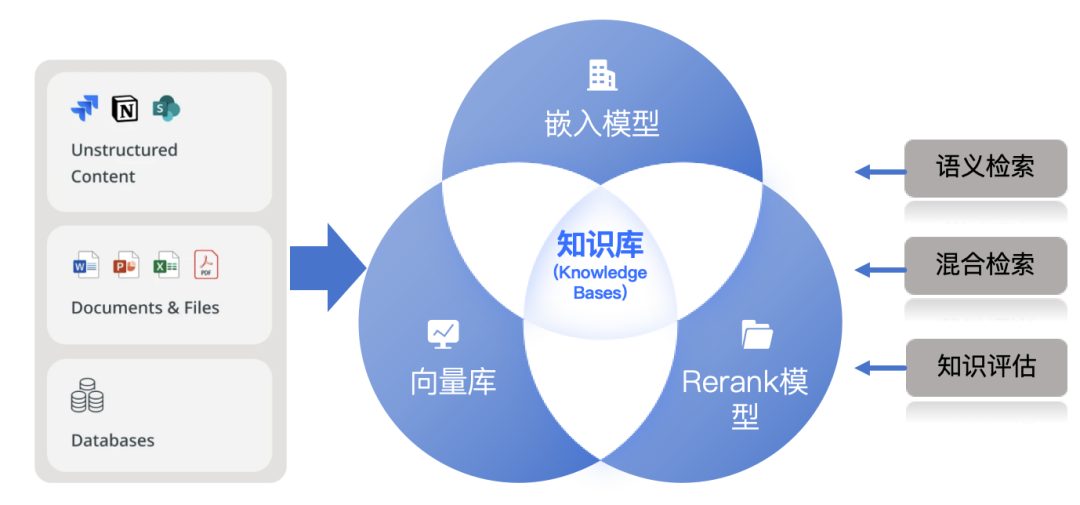
下面通过具体的例子来演示其工作方式,并了解其背后的工作原理。
【准备数据源】
以之前导入的一个包含若干FAQ问答的Word文档为例,这文档已经被映射成一个文件数据源,通过SQL可检索:
select * from files.sales_questions

【创建知识库】
现在如果你想针对content(其实是源文件内容分割后的chunk)创建向量索引,就可以借助知识库(Knowledge Base)模块,首先创建一个知识库:
create KNOWLEDGE_BASE my_sales_question_kbusing content_columns = ['content'], preprocessing = { "text_chunking_config" : { "chunk_size": 1000, "chunk_overlap": 100 } }
知识库可以指定的创建参数主要包括:
-
模型:包括嵌入和Rerank模型,这里使用config.json中的默认模型
-
向量库与数据源对应关系:这是用来指定向量数据库中的信息对应的数据源的列,包括id_*column(标识唯一的向量)、metadata_*columns(向量元数据的列,可以多列)、content_columns(需要生成向量的列,可以多列)
-
预处理参数:用来指定对content列预处理的参数,典型的如需要分割成的chunk大小(chunk_size,默认500)等
【向知识库插入数据】
现在就可以直接向知识库中插入数据,无需指定列信息,MindsDB会自动根据知识库创建的参数映射:
insertinto my_sales_question_kbselect * from files.sales_questions
MindsDB会自动完成创建嵌入模型、创建向量库、利用嵌入模型生成向量、将向量与Metadata等保存到向量库这一系列动作。
【利用知识库做语义检索】
在知识库创建完成后,你可以不带任何条件的查看其数据:
select * from my_sales_question_kb
注意MindsDB知识库的结构是固定的,包括ID、chunk_id、chunk_content、metadata等列,这些数据正是根据你在创建时的参数从数据源生成:

当然这样的检索并无实际意义。知识库最大的价值是可以进行语义检索,比如:
select * from my_sales_question_kbwhere content = '客户出一个超低价时怎么办?或者说:客户为什么会出"超低价"?'relevance >=0.7 limit5
注意语义检索的字段必须是content。这里用SQL的方式完成了语义检索,相比其他的方式更直观与简单。
检索时除了带自然语言文本的条件外,还可以:
-
使用limit来限制返回的数量(默认为10)
-
使用relevance来限制语义相关度(或者distance)
-
使用metadata中的列来做元数据过滤
以下是典型的检索结果:

【交叉连接实现多源混合检索】
这也是我认为知识库最重要的价值。
由于MindsDB把知识库也当做了一种“表”,因此你也可以把它与其他数据源的做JOIN,从而实现更加复杂的向量+标量、结构化+非结构化的多条件混合检索场景。以之前在介绍OceanBase文章中提到的一个查询为例:
推荐几款操作流畅的受女生喜欢的手机,苹果或者华为的,价格低于1万。
如何在数据不离开RDBMS,而RDBMS自身又不支持向量的环境下做这个检索呢?或许借助MindsDB可以轻松实现。
首先你需要参考上面的过程,针对产品(假设存放在Postgres数据源中,表名为products)创建一个可用来语义检索的知识库,比如名称为my_kb,ID列为product_id,Content列为手机的文本介绍。
现在你可以执行这样的SQL来完成混合检索:
SELECT p.product_id,p.product_name,p.descriptionFROM my_kb as k join my_postgres.products as p on k.id = p.product_idWHERE k.content = '操作要流畅,受女生欢迎的手机'and relevance >= 0.5andp.brand in ('苹果','华为') and p.price < 10000limit5
这里首先利用知识库my_kb在content上做语义匹配找到相关产品,然后通过k.id = p.productid关联回原始产品表p,进一步在SQL层面按品牌和价格进行了过滤。最终结果返回的就是同时满足语义条件和结构化条件的产品列表。
你甚至可以把两个知识库做JOIN,同时加入两个不同的语义检索条件。
这种混合查询相信在很多企业应用场景非常有用,因为传统应用的高价值信息大多在RDBMS,需要结合AI时代的非结构化文本处理,借助MindsDB这种数据“中间件”,实现既简单又直观。
【知识库自动更新】
由于知识库的背后有一个基于数据源创建的向量库,那么这个向量库与数据源之间如何同步呢?这也是很多新的“AI数据孤岛”常面临的麻烦。
在MindsDB中你可以借助JOB这个机制(CREATE JOB)来实现定期、自动化的同步处理。这种同步可以是:
- 不同数据源之间的同步
- 数据源与知识库的同步
- 数据源与模型的同步(重新训练ML模型)
这种同步机制非常类似于Oracle的JOB或MySQL的Event Scheduler机制,借助于ID列,可以轻松让知识库根据数据源定期同步:
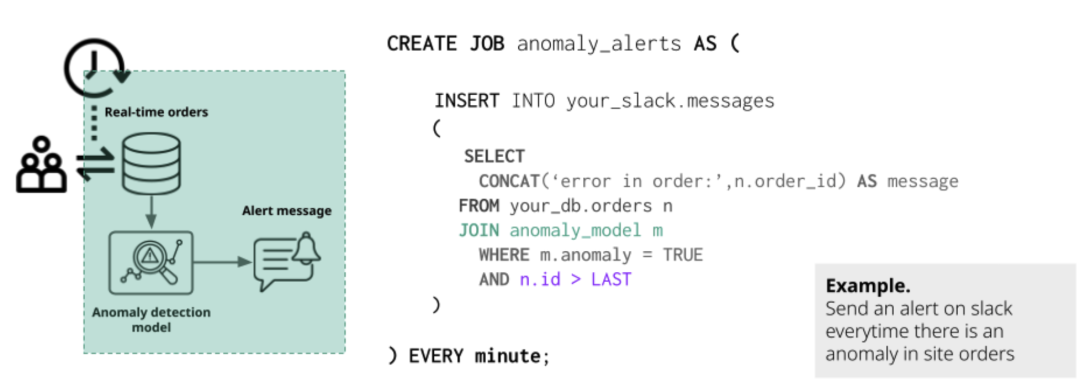
当然,如果你有更实时的同步需求,也可以考虑MindsDB的Trigger(触发器)机制,不过该机制存在数据库限制。
02 RAG与数据智能体(Data Agent)
知识库可以用来语义检索,那么就可以在此基础上快速构建一个RAG(Retrieval-Augmented Generation,检索增强生成)管道:
无非是把检索出的内容输入给LLM,由于LLM在MindsDB中也是一种可以查询的“表”,所以你可以用“表”连接来查询RAG答案:
select answer from (SELECT '你是一个销售管理的专家。请参考以下的上下文,适当的组织,回答销售提出的问题。如果上下文无法解答,请表示歉意,不要编造。直接给出答案,不要多余解释。使用Markdown格式。'+group_concat(chunk_content)+'------------销售的问题是:' + '客户出一个"超低"价时怎么办?或者说:客户为什么会出"超低价"??'as questionFROM `my_sales_question_kb`WHERE content = '客户出一个"超低"价时怎么办?或者说:客户为什么会出"超低价"?'limit 3) as prompt join my_llm_openai_answer
这是一个有趣的SQL RAG管道!执行后可以直接得到答案:

它包含了基础的语义检索、重新排序、相关性过滤、记录数限制,在召回若干chunk后,用group_concat函数合并;然后把它们组装成提示词,用“JOIN”的方式输入给LLM模型(把模型看做包含question和anser两列的“表”)。
尽管在一些高级RAG特性上可能还不够强大(比如多模态、融合检索),但在一些简单的需要“嵌入式RAG”管道的场景中,却是一种技能要求最低的方式。
不过这种方式仍然不够直观,在MindsDB的新版本中,提供了更加强大的 Data Agent(或者SQL Agent)模块。
【什么是MindsDB的Agent】
简单总结就是:
一个围绕特定数据集和模型、配置好技能的智能数据问答智能体。
通过指定Agent可以访问哪些表和知识库、使用哪个LLM模型来生成回答,以及一个提示模板来指导LLM回答,就可以完成一个Data Agent的创建。
定义好后,Agent就能接受自然语言问题输入,自动在授权的数据源中检索信息,然后由LLM综合给出答案 。
举个例子,假设想构建一个面向客服或销售的“产品咨询助手”。它可以访问产品库、客户和订单数据库,还能从产品描述知识库中获取语义信息,最终通过一个LLM生成答案。你可以这样配置 Agent:
CREATE AGENT my_agentCONFIGURE engine = 'openai', model = 'gpt-4o', openai_api_key = '<OpenAI密钥>'USING knowledge_bases = ['my_kb'], tables = [ 'my_postgres.products', 'my_postgres.customers', 'my_postgres.orders', 'my_postgres.order_items' ], prompt_template = ' - 知识库 my_kb:包含产品描述的语义向量索引,可用于理解产品特性; - 表 my_postgres.products:产品的结构化信息(名称、品牌、价格等); - 表 my_postgres.customers:客户详细信息; - 表 my_postgres.orders 与 order_items:历史订单及明细。';
以上的SQL配置了一个Agent:
-
使用OpenAI的gpt-4o作为语言模型
-
用知识库my_kb以及四张Postgres表作为数据源
-
提示模板用来告诉LLM数据源的作用
现在你可以通过SQL语句提出问题:
SELECT answerFROM my_sales_question_agent WHERE question = '<你的问题>';
此外还可以在客户端通过SDK来调用;甚至通过A2A协议调用这个Agent。
【Agent原理】
MindsDB的Agent本质上是一个LangChain实现的服务端Agent,只是MindsDB自动完成了一些工作,包括工具的创建和提示词的设定等。内部架构如下:
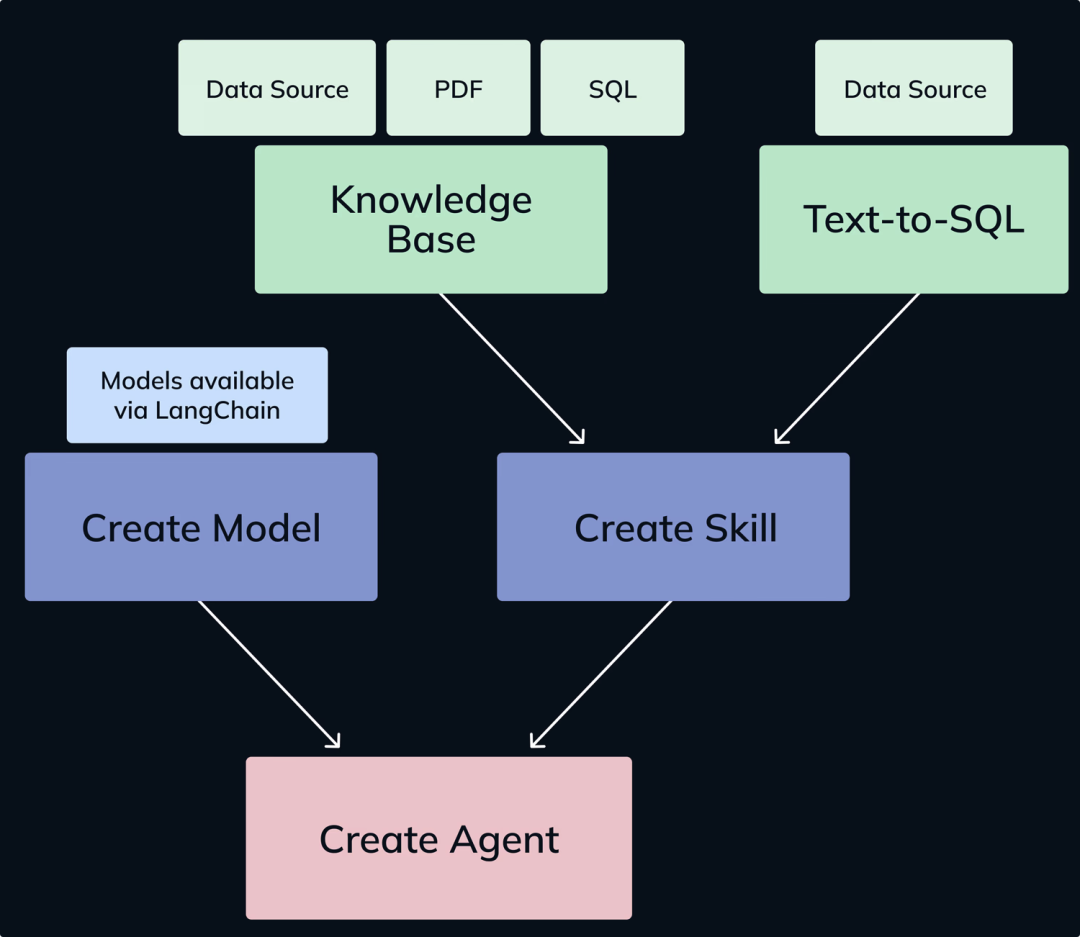
当用户提出问题时,Agent会借助它的两大技能完成数据检索,获得参考的上下文,最后组织答案并输出。
两类技能是:
-
知识库查询:对知识库执行语义检索,并返回相似的记录
-
文本到 SQL:自然语言转SQL查询,从数据源检索数据
Agent是MindsDB在其核心能力(数据源与模型的集成与统一访问)上层提供的应用侧模块。在一些特定场景下,比如客服自动化、即席数据查询、简单决策分析等,可以借助它来简化工作量。
个人测试结果看,MindsDB Agent目前还不够完善,不适合在严格商业环境下的使用,Text2SQL、知识库工具出错概率较大(也和模型有一定关系)。
03 总结与应用建议
至此我们已经把MindsDB的主要能力做了介绍。
MindsDB近期还支持了A2A以及MCP协议。这意味着可以将MindsDB中的融合数据查询、Agent等能力无缝集成到更大的智能体系统中,为企业构建复杂AI应用提供了极大的灵活性。
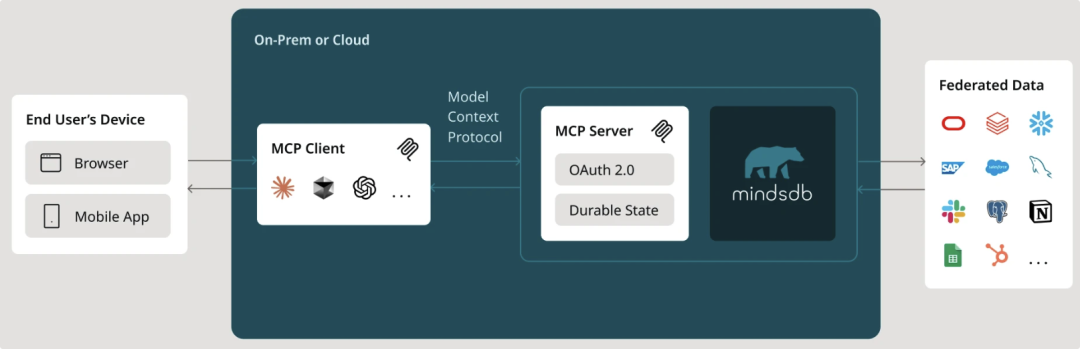
【应用建议】
作为一款开源产品,MindsDB是一个强大的企业数据层的智能“中间件”,它以“数据不出库,AI进库来”的模式,帮助解决企业AI应用落地中的数据环境复杂、遗留系统多、数据融合困难等难题。
你可以:
-
无需搬移数据就能跨源的数据访问,避免重复存储和时滞
-
无需复杂开发就能使用各种AI模型,用SQL降低了AI门槛
-
一种基于SQL扩展的融合数据访问方式,学习成本非常低
-
知识库帮助简化非结构化知识的自动组织、索引与检索
-
JOB、触发器等机制帮助实现自动数据同步与模型训练
-
丰富的客户端开发接口,支持SDK、REST、MCP/A2A等
整体上,对于MindsDB的应用建议为:
适合作为复杂企业环境中(比如多异构数据源或遗留系统)的“虚拟AI数据底座”,对上层应用提供融合与智能的统一数据访问接口。特别是希望以最低的学习成本,在传统企业技术栈的基础上引入与集成AI能力,可以考虑灵活应用。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
更多推荐

 21
21 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)