
大模型系列四:使用向量库进行相关性检索,大模型入门到精通,收藏这篇就足够了!
向量数据库是一种专为存储和高效检索高维向量数据设计的数据库系统,其核心优势在于支持基于向量相似性的快速查询,而非类似传统数据库的精确匹配。
一、什么是向量库
向量数据库是一种专为存储和高效检索高维向量数据设计的数据库系统,其核心优势在于支持基于向量相似性的快速查询,而非类似传统数据库的精确匹配。
其核心是以数学向量的形式存储数据,每个向量代表多维空间中的一个点或特征。它专为处理非结构化数据(如图像、文本、语音)设计,可通过大模型的相关底层库将数据转换为向量后再进行存储,并支持基于向量相似度的检索(如查找最接近的向量)。
二、核心应用场景
存储和搜索非结构化数据最常见的方法之一是对其进行嵌入处理并存储生成的嵌入向量,然后在查询时,对非结构化查询进行嵌入处理,并检索与嵌入后的查询“最相似”的嵌入向量。
向量数据库是传统数据库在AI时代的扩展,其核心价值在于高效处理非结构化数据的相似性查询。随着生成式AI(如ChatGPT)和大规模多模态模型的普及,向量数据库已成为推荐系统、图像检索、NLP等场景的底层基础设施,未来将在工业物联网、元宇宙等更多领域发挥关键作用。
三、使用的主体流程
在仅谈向量数据库的向量查询场景,其主体查询流程如下图所示:
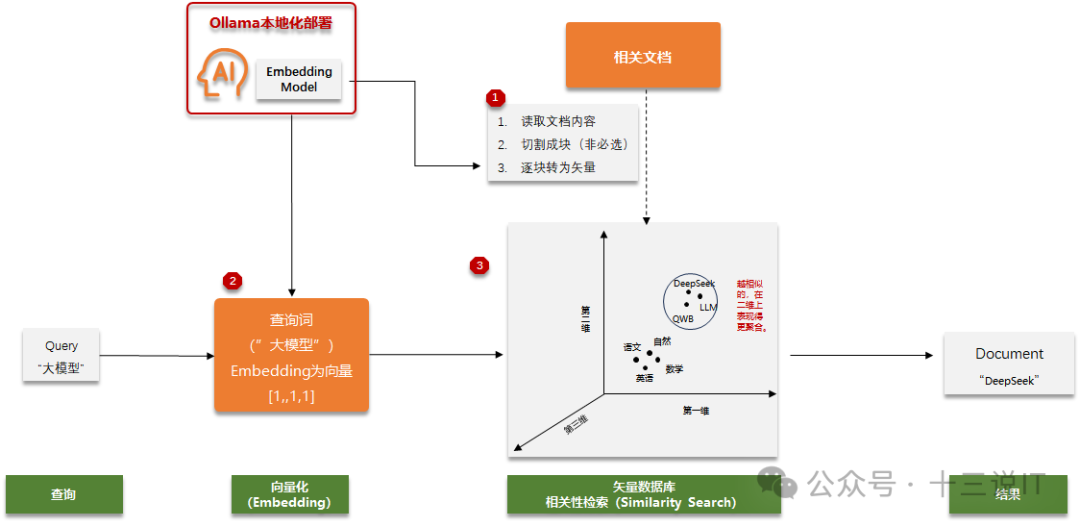
1、读取相关文档内容,采用EmbeddingModel(后面代码示例选用的nomic-embed-text)相关的代码库将其转化为向量数据后存入向量数据库(一个文档通常要切割为Chunk块后才能存入,无法将大文档一次性全部转化为向量,当前只能是逐块)。
2、用户在查询的时候,采用存储时一致的LLM相关代码库,将查询词转化为向量数据。
3、将查询向量数据在向量库中进行相关性查询(Similarity Search),并讲过返回客户端。
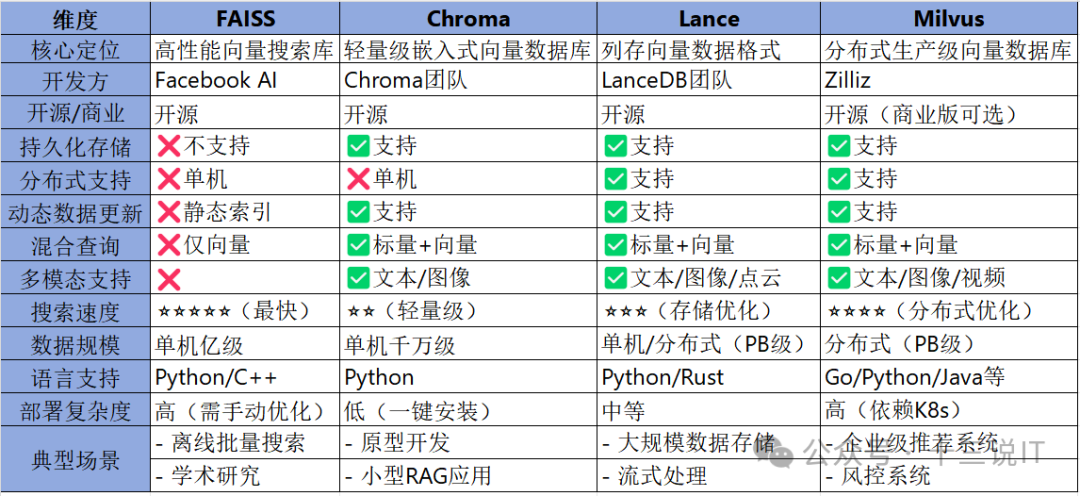
四、常见向量库横向对比
目前市面上比较常用的向量库,其关键对比的适用场景如下:
- FAISS:适合性能优先的离线场景,但需自行处理持久化和分布式。
- Chroma:轻量级首选,适合开发者快速验证想法。
- Lance:平衡存储效率与查询性能,适合大数据场景。
- Milvus:全功能企业级方案,但部署和维护成本较高。
明细对比如下:
五、代码示例
这段代码实现了读取本地的PDF等文件内容,使用Ollama本地化部署的向量模型转换为向量存储到轻量级向量库Chroma中,并做了相关性检索。最终检索的结果不精确,有待后续查证。
from unstructured.partition.auto import partition
from pathlib import Path
import os
from unstructured.chunking.title import chunk_by_title
from langchain_core.documents import Document
from uuid import uuid4
from concurrent.futures import ThreadPoolExecutor
from langchain_community.document_loaders import PyPDFLoader
import time
#一些依赖的包
#pip install "unstructured[docx,pptx,xlsx,pdf]"
#pip install poppler-utils
#执行文档的向量化转换和存储任务
def task(file_path,vector_store):
print("doing==============:"+file_path)
isSuccess = "成功"
try:
#文档识别,提取文档内容,同时识别文档的metadata,例如语言,encoding等。
elements = partition(file_path)
#执行切块任务,每块最大1000个字符
chunks = chunk_by_title(elements, max_characters=1000)
documents= []
for chunk in chunks:
#不适用chunk的metadata,经常识别错误
# metadata = chunk.metadata.to_dict()
#只设定的文档来源
new_metadata= dict()
new_metadata["source"] = file_path
#创建langchain的Document,核心属性就是page_content和metadata
document = Document(page_content=chunk.text, metadata=new_metadata)
documents.append(document)
#目前用的随机ID,会导致更新重复,后续可用hash改进
uuids = [str(uuid4()) for _ in range(len(documents))]
#存储文档,自动向量化
vector_store.add_documents(documents=documents, ids=uuids)
except Exception as e:
isSuccess = "失败"
print(isSuccess+"==============:"+file_path)
return isSuccess+"==============:"+file_path
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
#使用Ollama的本地模型,这里用的nomic-embed-text
#EmbeddingModel还是得用这种专门的模型,之前选用了QWB和DeekSeek的慢死了...
embeddings_model = OllamaEmbeddings(model="nomic-embed-text")
#创建向量库。这里是测试使用,使用Chroma
vector_store = Chroma(
collection_name="nomic_test_collection",
#关联LLM的embeddings_model(嵌入模型)
embedding_function=embeddings_model,
persist_directory="C:/develop/test/chroma_nomic_test_db", # Where to save data locally, remove if not necessary
)
# extensions = ['.csv', '.txt', '.doc', '.docx', '.xls', '.xlsx', '.ppt', '.pptx', '.pdf']
#需要进行建立向量索引的文件类型。
extensions = ['.csv', '.txt', '.doc', '.docx','.ppt', '.pptx', '.pdf']
#向量转化实在太慢,不得不开启高并发(IO密集型)
#另外一种是DirectoryLoader,示例代码:irectoryLoader("../", glob="**/*.md", use_multithreading=True) 。支持文档过滤和执行并发。
#但是个人没看底层原理,担心文档过多的时候会内存崩,所以不用这个示例。详细可参考:https://python.langchain.com/docs/how_to/document_loader_directory/
with ThreadPoolExecutor(max_workers=200) as executor:
# for root, dirs, files in os.walk("C:/Users/34481/WPSDrive/317939480/WPS云盘/cloud_dir/书籍"):
for root, dirs, files in os.walk("C:/develop/test/其他书籍"):
for file in files:
file_path=os.path.join(root, file)
if any(file_path.endswith(ext) for ext in extensions):
executor.submit(task,file_path,vector_store)
print("All tasks completed")
#相关性检索
results = vector_store.similarity_search(
"测试",
k=1,
# filter={"source": "tweet"},
)
#输出查询的结果,结果很不准确。相当的不准。。。这个相似性真的是太不准了。。也许是我的程序问题吧。
print("========分隔符=============")
for res in results:
print(f"* {res.page_content} [{res.metadata}]")
六、后记
向量库的读取和存储时相当简单的,麻烦的只是环境安装,这个跟着官方指南多搞几次就可以了。Ollama很简单,那个Chroma的安装就使用干净的Python环境就可以了。
最后就是这个向量数据搜索出来的内容实在是太差了,不知道是不是代码问题还是Embedding模型的问题。看来在一些精确查询的场景下(例如我想做的文件内容精确检索的时候)换用ElasticSearch是不是更好,具体什么原因有待考证。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!
更多推荐

 8
8 0
0- 0



 已为社区贡献117条内容
已为社区贡献117条内容

所有评论(0)