
自动驾驶大模型---BEVDriver
本文介绍了一种新型自动驾驶模型BEVDriver,该模型结合大型语言模型(LLM)的推理能力和鸟瞰图(BEV)特征的空间表示,实现端到端闭环驾驶。BEVDriver通过BEV编码器融合多视角图像和激光雷达点云,并利用LLM生成未来轨迹点。实验结果表明,BEVDriver在LangAuto基准测试中表现优异,驾驶分数比现有最优方法高出35.1%。该模型在开环评估和泛化能力方面也优于其他方法,但在处理
1 前言
关于大模型的博客,笔者分为了两个系列:车企量产 + 科研论文。希望有兴趣的朋友能够从笔者的大模型博客系列当中收获一些知识或者idea。
车企量产:
科研论文:
《自动驾驶大模型---小米&华科之DriveMonkey大模型》
《自动驾驶大模型---上海交通大学之DriveTransformer》
本篇博客介绍一篇论文,由慕尼黑应用科学大学提出了一种新型自动驾驶模型 BEVDriver,通过结合大型语言模型(LLM)的推理能力和鸟瞰图(BEV)特征的高效空间表示,实现端到端的闭环驾驶。
2 BEVDriver
自动驾驶需要安全、可靠且透明的驾驶能力,LLM 具备推理和自然语言理解能力,有望作为通用的运动规划决策者,但在绝对空间理解方面存在不足。BEV 特征图能够提供环境的顶视图表示,增强对周围环境的理解,适用于轨迹规划等任务,但现有方法在将三维空间感知与 LLM 的推理和语言能力结合方面存在挑战。因此论文作者结合了两者的能力,下面笔者介绍给各位朋友。
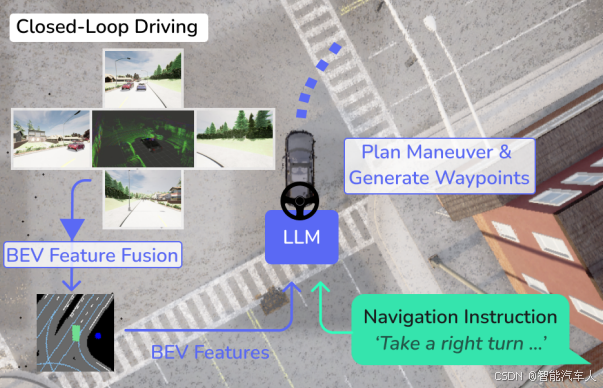
2.1 模型设计
熟悉VLA大模型的朋友,看着BEVDriver的架构,会非常眼熟,除了轨迹解码部分区别比较大之外,前面的结构是比较相似的。但LLM输出的轨迹质量显然是不高的。
- 编码模块:使用 BEV 编码器将多视角图像和激光雷达点云融合为 BEV 特征嵌入,通过 Transformer 编码器映射到 256 维嵌入空间,并通过预训练的解码器头进行交通检测、交通灯状态预测和语义分割。
- 端到端驾驶流程:BEV 特征通过 Q-Former 与自然语言指令对齐,并输入 LLM 生成未来轨迹点。
- PIDController:使用经典的 PID 控制器直接对LLM输出的轨迹点进行跟踪。LLM 的输出通过 PID 控制器转换为驾驶指令,实现轨迹跟踪。
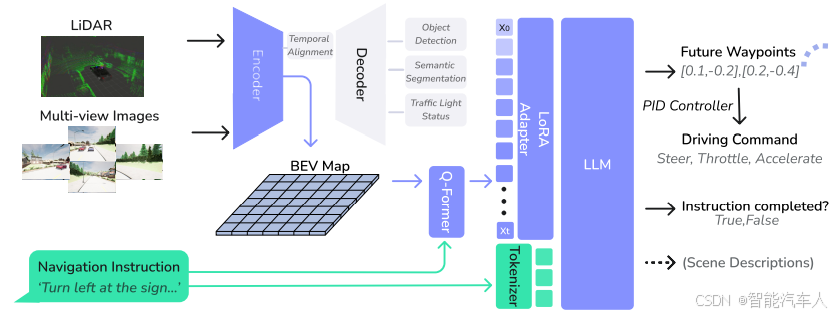
2.2 训练评估
使用 Llama - 7b 和 Llama3.1 - 8B - Instruct 模型进行训练,采用 AdamW 优化器和余弦学习率调度器。BEV 编码器单独预训练,整个管道训练了 15 个周期。
(1)数据集和基准测试
使用 LMDrive 数据集和 BEVDriver 语义数据集,包含 CARLA 仿真环境中的导航指令、控制信号和多视角图像等数据。LangAuto 基准测试评估模型在不同天气和光照条件下的驾驶能力。
(2)评估指标
闭环规划使用驾驶分数(DS)、路线完成率(RC)和违规分数(IS)进行评估。开环规划使用平均位移误差(ADE)和最终位移误差(FDE)评估轨迹预测精度。
2.3 实验结果
如下图所示,基于前视 RGB 图像、真值语义分割图、语义预测图、真值检测结果和检测预测结果,对两个场景进行语义分割与鸟瞰图(BEV)目标检测。

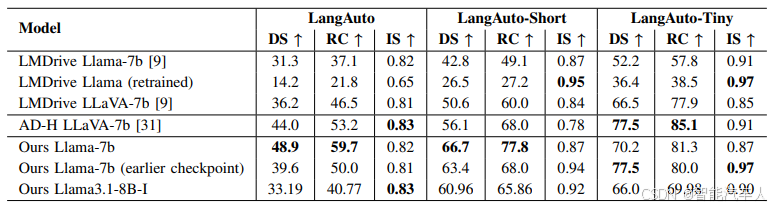
- 定量结果:BEVDriver 在 LangAuto 基准测试中表现优于现有最佳方法,驾驶分数比 LMDrive 高出 35.1%,比 AD - H 高出 18.9%。在开环评估中,BEVDriver 的 ADE 和 FDE 指标也优于 LMDrive。
- 消融研究:在 CARLA Town 5 基准测试中,BEVDriver 表现优于其他模型,表明其更好的泛化能力。端到端训练提升了路线完成率,但降低了违规分数。此外,误导性指令的移除降低了模型性能,表明指令频率与驾驶分数呈正相关。
3 结论
BEVDriver 通过结合 BEV 特征和自然语言指令,实现了高精度的轨迹预测和上下文驱动的决策,但在处理基于距离的指令时存在不足。未来工作将集中在提升 BEVDriver 的鲁棒性、时间感知能力和可解释性,并探索端到端训练的潜力。
参考文献:《BEVDriver: Leveraging BEV Maps in LLMs for Robust Closed - Loop Driving》
更多推荐

 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)