
如何为你的 RAG 应用选择合适的 Embedding 模型?大模型入门到精通,收藏这篇就足够了!
企业和组织特别喜欢它,因为它能让他们用自己的专有数据来回答用户问题。它让 LLM 给出准确、及时、和用户问题相关的答案。
Retrieval-Augmented Generation (RAG) 现在是最受欢迎的框架,用来构建 GenAI 应用。企业和组织特别喜欢它,因为它能让他们用自己的专有数据来回答用户问题。它让 LLM 给出准确、及时、和用户问题相关的答案。
从我这几年构建 RAG 应用的经验来看,你的响应质量很大程度上取决于检索到的上下文。 而提升 RAG 检索上下文的一个关键方式,就是把数据切分成合适的大小,选择合适的 embedding 模型,还有选一个有效的检索机制。
Embeddings 是 LLMs 的骨干。当你让 LLM 帮你调试代码时,你的词和 token 会被转化成高维向量空间,在那里语义关系变成数学关系,这靠的就是 embedding 模型。如果你用了错的 embedding 模型,你的 RAG 应用可能会拉来不相关或乱七八糟的数据。这会导致糟糕的答案、更高的成本,还有不开心的用户。
在这篇博客里,我会解释 embeddings 是什么,为什么它们重要,以及你在选择时该考虑什么。我们还会看看不同的 embedding 模型,以及哪些适合特定情况。到最后,你会清楚怎么挑对 embedding 模型,来提升准确性,让你的 RAG 应用跑得顺顺的。
Embeddings 是什么?
Embeddings 是捕捉语言含义和模式的数字表示。这些数字帮你的系统找到和问题或主题紧密相关的信息。
这些 embeddings 是用 embedding 模型创建的。Embedding 模型把词、图像、文档,甚至声音,转成一系列叫向量(vector)的数字。
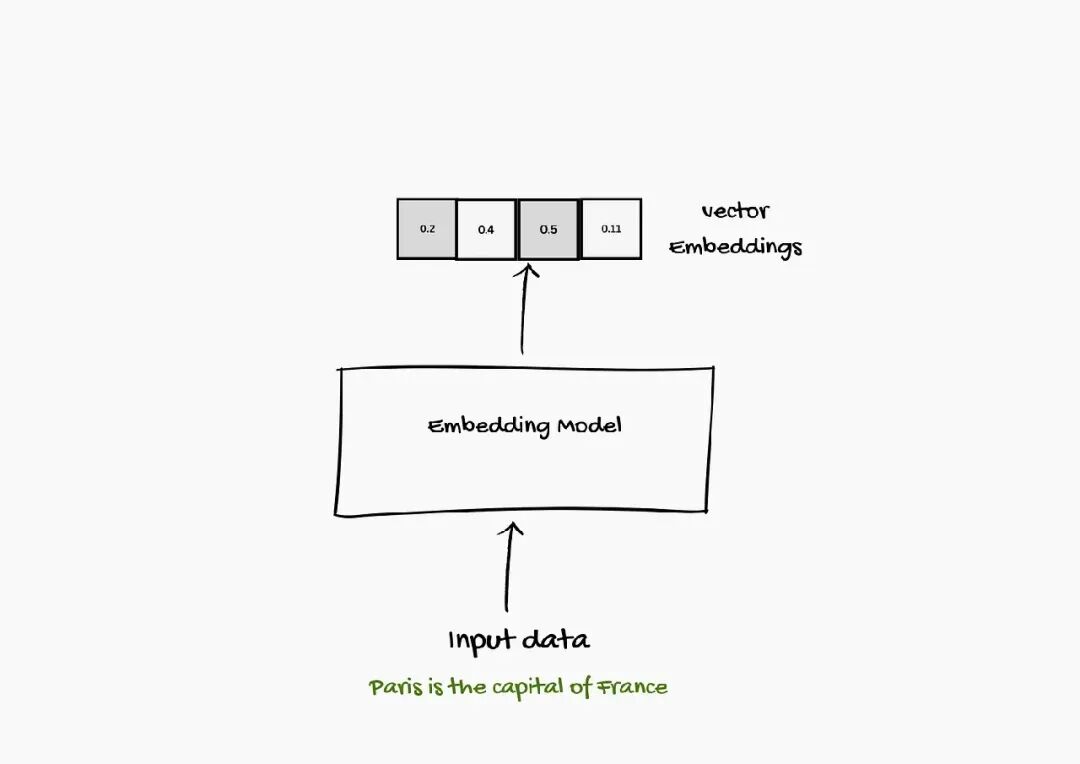
你可能是在 large language models 的语境下学到 embeddings 的,但 embeddings 其实历史更悠久。
这些 embeddings 是怎么计算的?
现在,大多 embeddings 是用 language models 创建的。 不是用静态向量表示每个 token 或词,language models 创建上下文化的词 embeddings,根据上下文用不同的 token 表示词/句子/块。这些向量然后可以被其他系统用于各种任务。
有多种方式产生 text embedding vector。最常见的方式之一,是平均模型产生的所有 token embeddings 的值。但高质量的 text embedding 模型通常是专门为 text embedding 任务训练的。
我们可以用 sentence-transformers 这个流行包,来用预训练 embedding 模型产生 text embeddings。
from sentence_transformers import SentenceTransformer# 加载模型model = SentenceTransformer("sentence-transformers/all-mpnet-base-v2")# 把文本转成 text embeddingsvector = model.encode("Best movie ever!")
embedding vector 的值数量,或者说维度,取决于底层的 embedding 模型。可以用 vector.shape 方法找到 embedding vector 的维度。
为什么 Embeddings 在 RAG 中重要?
Embeddings 在 Retrieval-Augmented Generation (RAG) 系统里扮演关键角色。来看看为什么:
语义理解:Embeddings 把词、句子或文档转成向量(数字列表),让相似含义的靠近在一起。这帮系统理解上下文和含义,不只是匹配确切的词。
高效检索:RAG 需要快速找到最相关的段落或文档。Embeddings 让搜索更快更容易,通常用像 k-nearest neighbors (k-NN) 这样的算法。
更好准确性:用 embeddings,模型能找出和问题相关的信息,哪怕没用一样的词。这意味着你得到更准确、更相关的答案。
Embeddings 的类型
Embeddings 有几种形式,取决于你的系统需要处理什么信息。
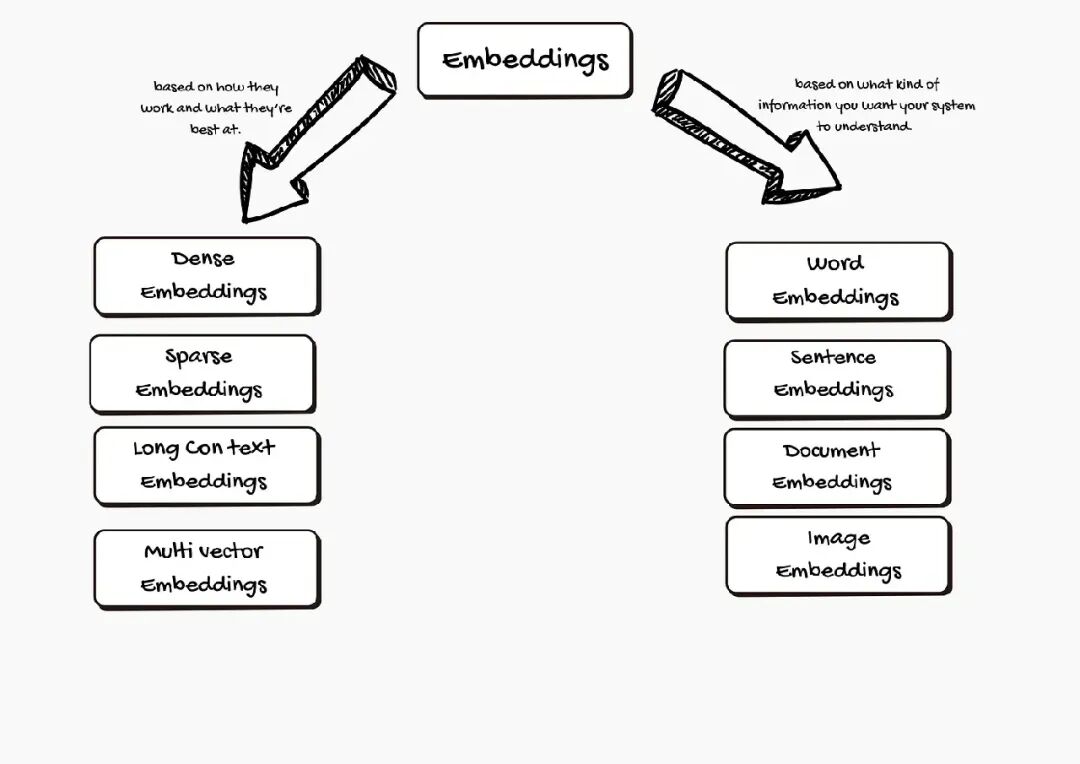
- 根据你想让系统理解的信息种类:
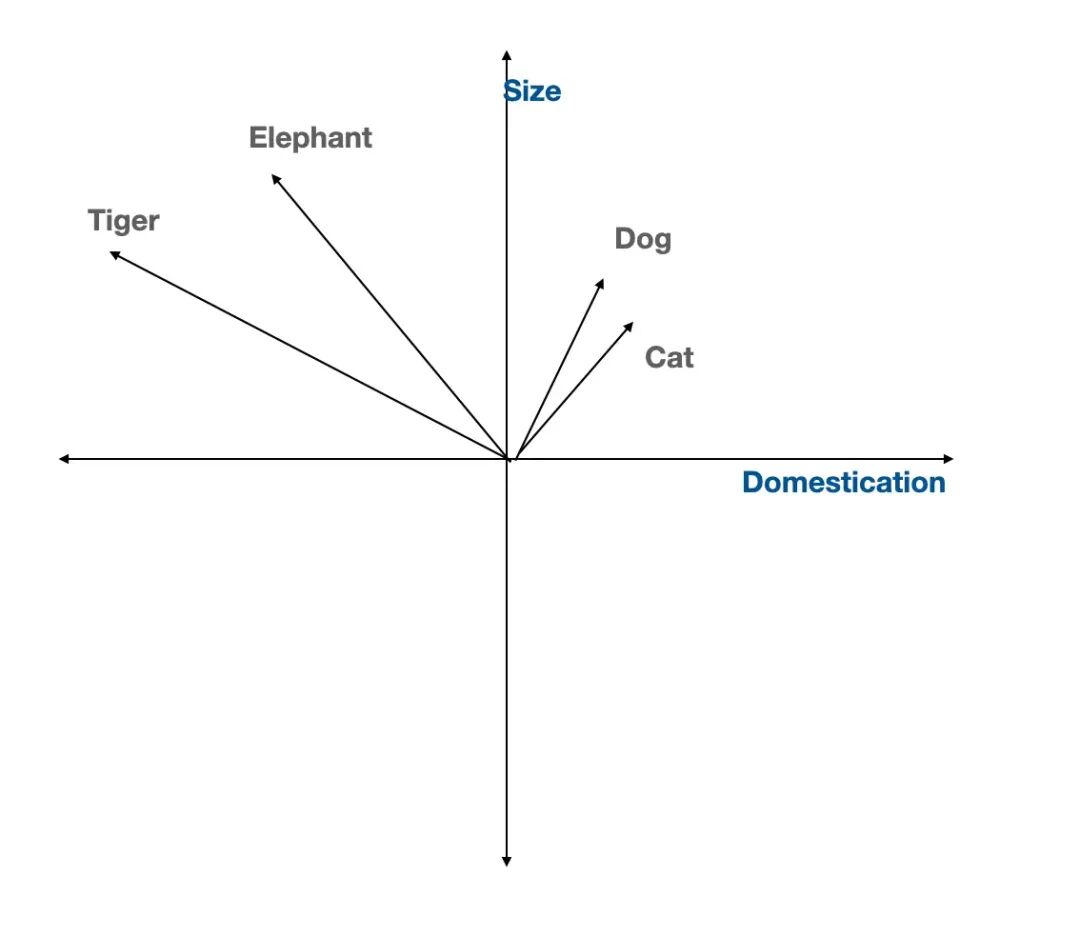
1.1 Word Embeddings
Word embeddings 把每个词表示成多维空间里的一个点。含义相似的词,比如 “dog” 和 “cat”,最后会靠近在一起。这帮电脑理解词之间的关系,不只是拼写。
热门 word embedding 模型包括:
Word2Vec:从大量文本学习词关系。
GloVe:关注词一起出现的频率。
FastText:把词拆成更小部分,让它更好处理稀有或拼错的词。
1.2 Sentence Embeddings
有时,含义只能从整个句子学到,不是单个词。Sentence embeddings 把句子的整体含义捕捉成一个向量。
知名 sentence embedding 模型有:
Universal Sentence Encoder (USE):对各种句子都行,包括问题和陈述。
SkipThought:学习预测周围句子,帮模型理解上下文和意图。
1.3 Document Embeddings
文档可以是从一段到整本书。Document embeddings 把所有文本转成单个向量。这让搜索大集合文档更容易,帮找到和查询相关的内容。
领先 document embedding 模型包括:
Doc2Vec:基于 Word2Vec,但设计用于更长文本。
Paragraph Vectors:类似 Doc2Vec,但专注更短文本部分,比如段落。
1.4 Image Embeddings:
文本不是 RAG 系统唯一能处理的,系统还能处理图像。Image embeddings 把图片转成描述颜色、形状和模式的数字列表。
热门 image embedding 模型是 Convolutional Neural Networks (CNNs)。它特别擅长识别图像模式。
2.根据 embedding 的特性:
Embeddings 可以有不同品质,影响它们怎么工作和最适合什么。咱们用简单解释和例子分解这些特性:
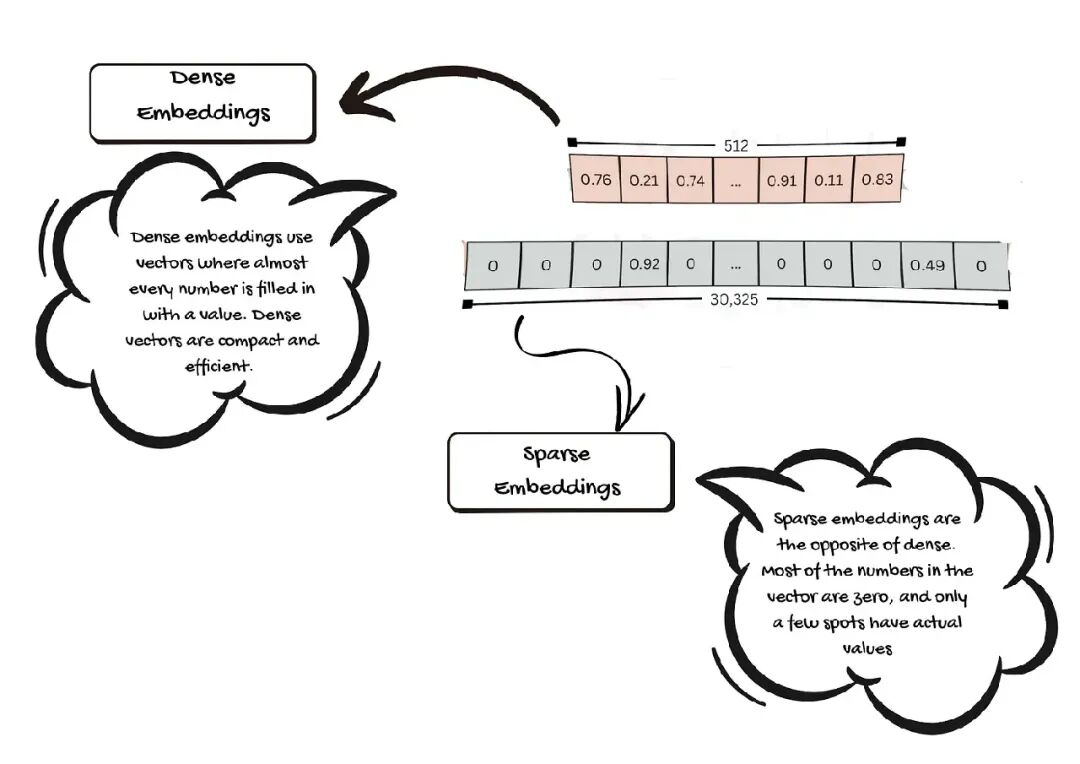
2.1. Dense Embeddings
Dense embeddings 用向量,几乎每个数字都有值。每个值都存一点关于词、句子、图像或文档的信息。Dense vectors 紧凑高效。在小空间存很多细节。这让电脑更容易比较东西,快速找到相似点。
2.2. Sparse Embeddings
Sparse embeddings 和 dense 相反。向量里大多数数字是零,只有少数地方有实际值。零不带信息。Sparse embeddings 帮突出最重要的特征。它们让突出什么让东西独特或不同更容易。
2.3 Long Context Embeddings
有时,你需要理解整个文档或长对话,不是短句子。Long context embeddings 设计用来一次处理大量文本。
老模型只能看短文本。如果你给它们大文章,它们得拆成小部分。这可能让它们错过重要连接或丢掉主思路。新模型,像 BGE-M3,能一次处理成千上万词(高达 8,192 tokens)。这帮电脑保持完整故事。
2.4 Multi-Vector Embeddings
通常,一个项目(像词或文档)只得一个向量。Multi-vector embeddings 为每个项目用几个向量。每个向量能捕捉不同特征或方面。
用不止一个向量,电脑能注意到更多细节和关系。这带来更丰富、更准确的结果。
选择最佳 Text Embedding 模型的参数
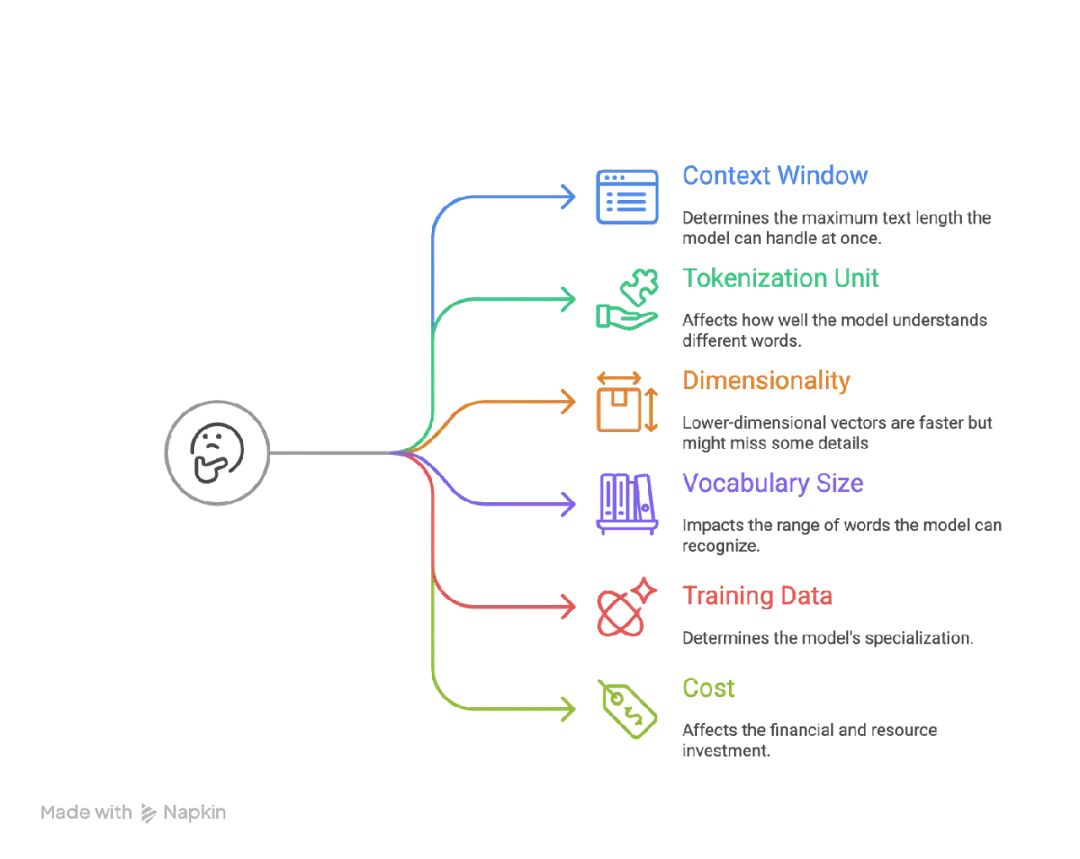
在挑模型前,你该知道看什么。有几个关键因素要考虑:
-
Context Window
Context window 是模型一次能处理的最大文本量。比如,如果模型 context window 是 512 tokens,它一次只能读 512 个词或词片。更长文本必须拆分。有些模型,像 OpenAI 的 text-embedding-ada-002 (8192 tokens) 和 Cohere 的 embedding 模型 (4096 tokens),能处理更长文本。为什么重要?
更大 context window 让你处理更大文档而不丢信息。这对像搜索长文章、研究论文或报告的任务有帮助。
-
Tokenization Unit
Tokenization 是模型把文本拆成更小部分,叫 tokens。不同模型用不同方法:Subword Tokenization (Byte Pair Encoding, BPE):把词拆成更小片。比如,“unhappiness” 变成 “un” 和 “happiness。” 这帮处理稀有或新词。WordPiece:类似 BPE,但常用于像 BERT 的模型。
Word-Level Tokenization:把文本拆成整词。不太适合稀有词。
为什么重要?
模型 tokenization 的方式影响它怎么理解不同词,尤其是 unusual 的。大多现代模型用 subword tokenization 来更好灵活。
-
Dimensionality
Dimensionality 是模型为每块文本创建的数字列表(vector)大小。比如,有些模型产生 768 个数字的向量,其他是 1024 甚至 3072。为什么重要?
更高维向量能存更多细节信息,但需要更多电脑功率。更低维向量更快,但可能错过一些细节。
-
Vocabulary Size
这是模型知道的独特 tokens 数量。更大词汇库处理更多词和语言,但用更多内存。更小词汇库更快,但可能不懂稀有或专业词。
比如:大多现代模型有 30,000 到 50,000 tokens 的词汇库。 -
Training Data
Training data 是模型学的东西。训练于 General-Purpose:当训练于很多类型文本,像网页或书,模型变得适用于一般用途。适合广任务。
Domain-Specific:当训练于专业文本,像医疗或法律文档,模型变得特定领域专家。这些适合 niche 任务。
为什么重要?
训练于特定数据的模型在那些领域做得更好。但可能不适合一般任务。
-
Cost
Cost 包括用模型需要的钱和电脑资源。根据你计划怎么访问 LLM 模型,cost 结构会变。API-Based Models:按使用付费,像 OpenAI 或 Cohere。
Open-Source Models:免费用,但你需要硬件(像 GPUs)和技术技能自己跑它们。
为什么重要?
API 模型容易用,但如果你数据多,可能贵。Open-source 模型省钱,但需要更多设置和知识。
选择 Embedding 时关键因素
- 了解你的数据领域
从我的经验,当设计 RAG 应用时,我第一个问的是,“我的 RAG 系统要处理什么数据?”
如果我们处理一般知识或客户 FAQs,一般用途 embeddings 像 OpenAI 的 text-embedding-3-small 通常够。但对专业领域像医学、法律或金融,domain-specific 模型如 BioBERT、SciBERT 或 Legal-BERT 是最佳。这些模型训练来理解那些领域的独特语言和上下文。
如果 RAG 工具需要处理产品图像或语音查询,去用 multimodal embeddings。CLIP 是处理文本和图像的可靠选择。
- Embedding 大小和模型复杂度
接下来我会评估我的查询和文档是短还是长,结构化还是非结构化。有些模型更适合简短片段,其他擅长处理更长、自由形式文本。
Embedding dimensionality 很重要。高维向量 (1536 或 4096 维度) 捕捉更多细微差异和上下文。它们一般提升检索准确性,但需要更多计算资源和存储。
低维向量 (384 或 768 维度) 更快更轻,如果你扩展到百万文档,这很关键。权衡简单:更多维度意味更好准确但更高成本;更少维度意味速度和效率但可能牺牲精度。
实践中,最好从 384–768 范围的向量开始。这给你性能和资源用的好平衡。
现代 vector databases 像 Pinecone、Weaviate 或 FAISS 能用 quantization 或 dimensionality reduction 压缩 embeddings。这些 vector DBs 让你用更大 embeddings 而不付全内存成本。
- 计算效率
速度关键,尤其是实时应用。
如果响应时间对你的应用超级重要,去用低 inference times 的模型。轻模型像 DistilBERT 或 MiniLM 快,还对大多任务够准确。 - 上下文理解
接下来,我们该评估 RAG 系统该回答的查询。知识内容/文档的结构和长度。这些内容该基于应用切成合适最佳大小。得到用户问题正确答案的一个关键因素是模型的 context window,就是它一次考虑的文本量。
更大 context windows 在处理长或复杂文档时有帮助。能一次处理更多文本的模型倾向于为长查询给出更准确答案。 - 集成和兼容性
最好选和现有基础设施无缝集成的模型。
来自 TensorFlow、PyTorch 或 Hugging Face 的预训练模型通常更容易部署,有强文档和社区支持。 - Cost
最后,要估项目总权衡训练和部署成本,如果你计划 fine tune 模型并 host 你的模型。但大多 RAG 应用能用现成的好好工作。
更大模型训练和跑更贵。Open-source 模型通常更预算友好,但可能需要额外设置和维护。Proprietary 模型提供更好支持和性能,但价格更高。
场景:为医疗研究论文选择 Embedding 模型
假设你需要建一个 semantic search 系统,为医疗研究论文。你想让用户快速准确找到相关研究。你的数据集大,每个文档长,介于 2,000 到 8,000 词。你需要一个能处理这些长文本、提供有意义结果、并保持每月预算 300$ - 500$ 的模型。
你怎么为这个工作挑对 embedding 模型?咱们一步步走过程。
步骤 1: 专注领域相关性
医疗研究论文用复杂医疗术语和技术语言。你选的模型该训练于科学或学术文本,不是只法律或一般内容。
所以,主要设计用于法律或生物医学文档的模型不会是更广科学研究的合适。
步骤 2: 检查 Context Window 大小
研究论文长。要完整处理它们,你需要大 context window 的模型。大多研究论文有 2,000 到 8,000 词。大约 2,660 到 10,640 tokens (假设 1.33 tokens 每词)。
8,192-token context window 的模型能一次盖约 6,156 词。
如果模型只能处理 512 tokens,它没法处理整论文。
要跳过的模型:
Stella 400M v5
Stella 1.5B v5
ModernBERT Embed Base
ModernBERT Embed Large
BAAI/bge-base-en-v1.5
allenai/specter
m3e-base
步骤 3: 考虑 Cost 和 Hosting
你有预算。按 token 付费会快速加起来,尤其是大文档和频繁搜索。
来看些模型:
OpenAI text-embedding-3-large: $0.00013 每 1,000 tokens
OpenAI text-embedding-3-small: $0.00002 每 1,000 tokens
Jina Embeddings v3: Open-source 和 self-hosted,无 per-token 成本
算算数。如果你每月处理 10,000 文档 (每个 8,000 tokens):
OpenAI text-embedding-3-large: $10.4/月 (预算内)
OpenAI text-embedding-3-small: $1.6/月 (远低于预算)
Jina Embeddings v3: 无 per-token 成本。但你付 hosting/server 成本 (取决于服务器大小和你是否和另一个模型 host)
要跳过的模型:
Jina Embeddings v3
步骤 4: 比较性能 (MTEB Score)
现在,看剩下模型的实际性能。Massive Text Embedding Benchmark (MTEB) 提供分数帮比较。
OpenAI text-embedding-3-large: 强性能,好 MTEB 分 (~71.6),能处理高达 8191 tokens,且成本有效。
OpenAI text-embedding-3-small: 好性能,好 MTEB 分 (~69.42),能处理高达 8191 tokens,且成本有效。
Voyage-3-large: 好 MTEB 分 (~60.5),能处理高达 32,000 tokens,且成本有效。
NVIDIA NV-Embed-v2: 最高 MTEB 分 (72.31),处理高达 32,768 tokens,open-source 和 self-hosted。
我们的最终选择:
缩小列表后,你剩下 open-source 模型像 OpenAI text-embedding-3-small、OpenAI text-embedding-3-large、Voyage-3-large 和 NVIDIA NV-Embed-v2。
这些模型能处理长医疗研究论文,提供强准确性,并适合你的预算。
NVIDIA NV-Embed-v2 以其高 MTEB 分和大 context window 脱颖而出,让它成医疗 semantic search 的可靠选择。
选择对 embedding 模型需要仔细思考。看你的需要,比较选项,挑最适合你项目的那一个。
选择对 Embeddings 的基准
新和改进 embedding 模型一直出来。但你怎么跟踪它们?幸运,有大规模基准帮你保持信息。
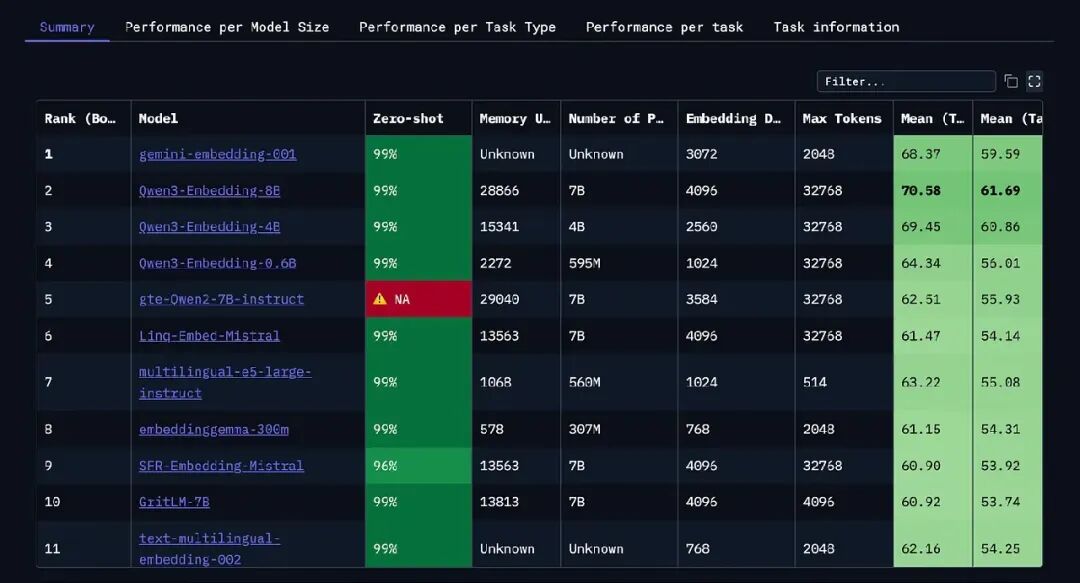
Massive Text Embedding Benchmark (MTEB)
MTEB 是个社区跑的 leaderboard。它比较超 100 个 text 和 image embedding 模型,跨超 1,000 语言。一切都在一处——评估指标、不同任务类型,和广泛领域。这让它成你决定用哪个模型的有用起点。
链接:MTEB Dashboard(https://huggingface.co/spaces/mteb/leaderboard)
Massive Multilingual Text Embedding Benchmark (MMTEB)
大多传统基准只盖几个语言或领域。MMTEB 走得更远。它是 MTEB 的扩展版,现在包括超 500 个评估任务,超 250 语言。MMTEB 还测试更难挑战,如指令跟随、从长文档检索信息,甚至代码检索。它目前是最彻底的多语言 embedding 基准。
链接:研究论文(https://arxiv.org/abs/2502.13595)
什么时候用 Massive Text Embedding Benchmark (MTEB)?怎么用?
MTEB 是挑 embedding 模型的有用工具。不同模型在不同任务闪光。MTEB leaderboard 显示每个模型跨广泛任务的表现。这能帮你为特定需要缩小选择。
但,别被 MTEB 分骗了。
MTEB 给你分,但不讲全故事。顶模型间差异常很小。这些分来自很多任务,但你看不到任务间结果变多少。有时,leaderboard 顶的模型只有轻微优势。统计上,几顶模型可能表现一样好。研究者发现平均分不总意味多,当模型这么近。
你该做什么?看模型在类似你用例的任务表现。这通常比只专注整体分更有帮助。你不用详细研究每个数据集。但知道用什么文本——像新闻文章、科学论文或社交媒体帖子——能帮。你能在数据集描述或瞥几例子找到这信息。
MTEB 是有帮助资源,但不完美。批判思考结果。别只挑最高分模型。深入找最适合你任务的。
考虑你应用的需要。没有单一模型对一切最好。那是为什么 MTEB 存在,帮你为情况选对。当你浏览 leaderboard 时,记住这些问题:
你需要什么语言?模型支持吗?
你用专业词汇吗,像金融或法律术语?
模型多大?它能在你硬件跑吗,像笔记本?
你电脑有多少内存?模型能 fit 吗?
最大输入长度是多少?你文本长还是短?
一旦你知道什么对你项目最重要,你能在 MTEB leaderboard 上按这些特征过滤模型。这帮你找不只表现好,还适合你实际需要的模型。
结语:
为你的 RAG 应用选对 embedding 模型不是只挑基准上最高分的那个。像 MTEB 的工具有帮助,但它们不能告诉你一切。重要是看数字之外,考虑对你项目真重要的,像语言支持、专业词汇、内存限,和文本长度。
花时间理解你用例。基于最相关任务比较模型。记住,对一个人应用好的模型可能不是你最好的。
最后,周到方法是平衡性能和实际需要。这会帮你找对模型。用点研究和仔细考虑,你会让 RAG 应用成功。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!
更多推荐

 7
7 0
0- 0



 已为社区贡献108条内容
已为社区贡献108条内容

所有评论(0)