
大模型不难懂:从原理到实战,一篇读懂AI如何学习和生成
本文系统介绍了大型语言模型(LLM)的核心知识体系,包括三个关键环节:1)训练过程:从预训练(学习通用语言能力)、监督微调(适应特定任务)到RLHF(对齐人类偏好)的完整流程;2)推理机制:解析自回归生成、解码策略及KV缓存/量化等优化技术;3)应用实践:通过代码示例展示分词、训练和生成过程。文章还探讨了LLM发展历程、核心架构(Transformer)及未来趋势,为读者构建了从基础理论到工程实现

一、认识大型语言模型
1、什么是大语言模型(LLM)
当我们与ChatGPT对话、让Copilot编写代码、或用Midjourney生成图片描述时,背后都有一个共同的引擎——大型语言模型(LLM);LLM是一种基于海量文本数据训练的深度学习模型,能够理解、生成和处理自然语言。
核心特征:
-
规模巨大:参数从数十亿到数万亿
-
数据海量:训练数据涵盖互联网大部分公开文本
-
能力通用:通过预训练获得通用语言理解能力
2、LLM的发展史
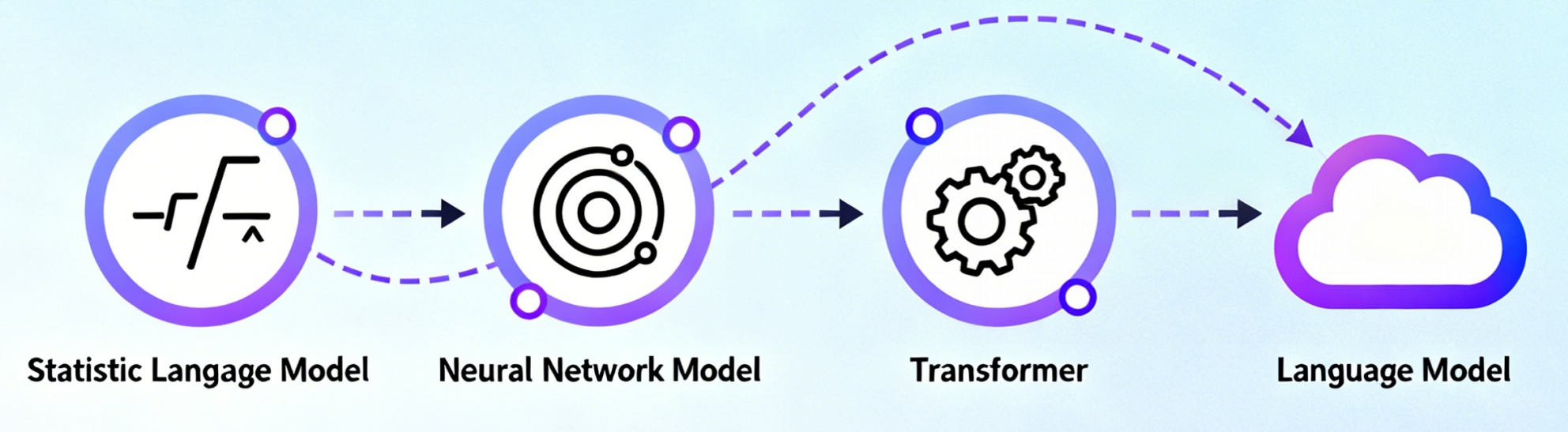
关键里程碑:
-
2017年:Google提出Transformer架构(革命的起点)
# Transformer的核心创新:自注意力机制
# 传统RNN必须顺序处理,Transformer可以并行处理整个序列
def transformer_attention(Q, K, V):
# 每个词都可以直接与序列中所有其他词交互
scores = torch.matmul(Q, K.transpose(-2, -1))
attention_weights = torch.softmax(scores, dim=-1)
return torch.matmul(attention_weights, V) # 并行输出-
2018年:GPT-1、BERT问世(预训练+微调范式确立)
-
2020年:GPT-3发布(1750亿参数,涌现能力出现)
# Scaling Laws:性能随规模增长可预测提升
def scaling_law(parameters, data, compute):
performance = a * log(parameters) + b * log(data) + c * log(compute)
return performance
# GPT-3验证了"更大确实更好"的假设
gpt3_performance = scaling_law(175e9, 300e9, 3.14e23) # 突破性表现-
2022年:ChatGPT横空出世(RLHF对齐技术成熟)
| 时间 | 里程碑 | 核心贡献 | 影响范围 |
|---|---|---|---|
| 2017 | Transformer | 注意力机制架构基础 | 技术底层革新 |
| 2018 | GPT/BERT | 预训练+微调范式 | 研究方法统一 |
| 2020 | GPT-3 | 规模效应验证 | 工程路径明确 |
| 2022 | ChatGPT | 人类对齐技术 | 产品化突破 |
3、理解LLM的原子单位:Token
在深入了解LLM工作原理前,我们需要先理解它如何处理文本。LLM并不直接认识汉字或单词,而是处理称为token的基本单元。
Token是什么?
-
相当于模型的"词汇表"或"字母表"
-
可能是子词、单个汉字、标点符号等
-
所有文本都需要先转换为token序列才能输入模型
# 分词过程示例
text = "我喜欢吃披萨!"
tokens = ["我", "喜欢", "吃", "披", "萨", "!"] # 中文分词
token_ids = [123, 456, 789, 101, 234, 999] # 对应的数字ID
text_en = "I love pizza!"
tokens_en = ["I", " love", " pizza", "!"] # 英文分词为什么需要分词?
-
解决词汇爆炸:直接使用单词会产生百万级词汇表
-
处理未知词:新词如"ChatGPT"可拆分为已知token
-
统一处理:不同语言都映射到同一token空间
Token的实用影响:
-
上下文长度:GPT-4的128K上下文是指128,000个token
-
API计费:大部分AI服务按token数量收费
-
生成速度:模型每次前向传播生成一个token
二、LLM的训练之旅
LLM的训练通常分为三个主要阶段,就像一个学生的成长过程。
1、预训练——"通读天下书籍"
预训练是 LLM 构建基础能力的核心环节,类比人类 “广泛阅读、积累常识” 的过程。此阶段不针对特定任务,而是让模型通过海量文本学习语言的底层逻辑、语法规则、语义关联,以及涵盖历史、科学、文化等领域的世界知识,最终具备 “理解语言、储备常识” 的通用能力。
目标:让模型学会语言的统计规律和世界知识。
技术核心:因果语言建模(Causal Language Modeling, CLM)
- 核心任务:下一个 token 预测(Next Token Prediction)
- 学习逻辑:模型只能看到当前位置之前的文本(因果掩码),无法获取后续信息,模拟人类 “逐句阅读、实时理解” 的过程
- 典型输入输出示例:
输入文本(token 序列):“今天天气很好,我决定去...”(对应 token:[今天,天气,很好,,, 我,决定,去])
模型预测输出(概率最高的 token):“公园”(或 “散步”“户外”,取决于训练数据中的语境分布)
import torch
import torch.nn as nn
from transformers import AutoModelForCausalLM # 引入 Hugging Face 因果语言模型(如 GPT 类)
def calculate_pretraining_loss(pretrained_model, input_ids, attention_mask=None):
"""
计算LLM预训练阶段的因果语言建模损失(下一个token预测损失)
参数说明:
- pretrained_model: 初始化后的因果语言模型(如 GPT2Model、LlamaForCausalLM)
- input_ids: 文本对应的token ID序列,形状为 [batch_size, sequence_length](批量处理的文本长度)
- attention_mask: 注意力掩码,形状同 input_ids,用于区分真实token(1)和填充token(0),避免模型学习无效填充
返回:
- avg_loss: 批量数据的平均交叉熵损失,值越小表示模型预测越接近真实文本
"""
# 1. 模型前向传播:输入token序列,输出每个位置的token预测概率(logits)
# logits 形状:[batch_size, sequence_length, vocab_size](vocab_size为模型词表大小)
outputs = pretrained_model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=input_ids # 直接传入labels,Hugging Face模型会自动处理偏移和掩码
)
# 2. 提取损失:Hugging Face模型会自动完成“输入右移1位作为标签”“忽略填充位置损失”的操作
# 无需手动处理 logits 和 labels 的偏移,简化代码且避免逻辑错误
total_loss = outputs.loss
# 3. 计算批量平均损失(除以有效token数量,而非批量大小,确保损失计算公平)
valid_token_count = attention_mask.sum() if attention_mask is not None else input_ids.numel()
avg_loss = total_loss / valid_token_count
return avg_loss
# 示例:初始化模型并计算损失
if __name__ == "__main__":
# 加载预训练模型(以小型GPT2为例,实际预训练用更大模型如 Llama、GPT-3)
model = AutoModelForCausalLM.from_pretrained("gpt2")
# 模拟输入:批量大小=2,序列长度=8(随机生成token ID,范围0-模型词表大小)
input_ids = torch.randint(0, model.config.vocab_size, (2, 8))
# 模拟注意力掩码:全部为1(无填充token)
attention_mask = torch.ones_like(input_ids)
# 计算损失
loss = calculate_pretraining_loss(model, input_ids, attention_mask)
print(f"预训练批量平均损失:{loss.item():.4f}")预训练的挑战:
预训练是 LLM 训练中成本最高、难度最大的阶段,核心挑战集中在 “计算资源”“数据质量” 和 “效率平衡” 三大维度:
|
挑战类别 |
具体表现 |
行业应对思路 |
|
计算成本高昂 |
训练 GPT-3(1750 亿参数)需数千张 A100 GPU 连续运行数月,电费 + 硬件成本超千万美元;小模型(如 7B 参数)也需数十张 GPU 运行数周。 |
1. 模型并行:将模型参数拆分到多 GPU / 多节点(如 Megatron-LM 的张量并行、流水线并行); 2. 混合精度训练:用 FP16/FP8 精度替代 FP32,减少显存占用和计算量; 3. 云厂商优化:AWS、阿里云推出专用 LLM 训练集群(如 AWS Trainium)降低成本。 |
|
数据质量关键 |
需处理万亿级别的 token 数据(约相当于数百万本图书的文本量),且数据中存在噪声(如错误信息、重复内容、偏见内容),直接影响模型性能。 |
1. 多源数据筛选:优先选择高质量文本(如维基百科、学术论文、权威出版物),过滤低质量论坛、广告文本; 2. 数据清洗流程:去重(基于文本哈希去重)、纠错(用规则或小模型修正语法错误)、去偏见(检测并平衡性别、地域相关表述); 3. 数据多样性:覆盖多语言、多领域(科技、人文、生活),避免模型 “偏科”。 |
|
训练效率瓶颈 |
长序列(如 1024/2048 token)训练时,注意力计算复杂度随序列长度平方增长;训练过程中易出现梯度消失、模型过拟合。 |
1. 注意力优化:采用稀疏注意力(如 Longformer 的滑动窗口注意力)、线性注意力(如 Performer)降低计算复杂度; 2. 训练策略:使用学习率预热(Warm-up)+ 余弦退火,稳定梯度;加入 Dropout 层、权重衰减(Weight Decay)防止过拟合; 3. checkpoint 机制:定期保存训练进度,避免因硬件故障导致训练中断、数据丢失。 |
2、有监督微调——"入职培训"
如果说预训练是让模型 “饱读诗书”,那么有监督微调(Supervised Fine-Tuning,SFT)就是为模型做 “入职培训”:通过人工标注的高质量指令 - 回答数据,将 “知识渊博但不懂如何服务人类” 的基座模型(Base Model),改造为 “能理解人类需求、按指令输出有用结果” 的实用助手(如聊天机器人、代码助手)。此阶段的核心是让模型学习 “人类交互逻辑”,而非单纯积累知识。
目标:将"知识渊博但不会交流"的基座模型,变成"有用的助手"。
核心数据格式:指令 - 回答对(Instruction-Response Pairs)
|
数据组成 |
作用说明 |
示例 |
|
Instruction |
明确任务目标,告诉模型 “要做什么” |
“解释量子计算的基本概念”“将以下英文翻译成中文” |
|
Input(可选) |
补充任务所需的具体信息,避免模型歧义 |
翻译任务中的 “Hello, how are you?”、摘要任务中的原文文本 |
|
Output |
人工标注的标准回答,作为模型学习的 “正确答案”,确保输出质量和格式规范 |
“量子计算是一种利用量子力学原理(如叠加态、纠缠态)处理信息的计算方式...”“你好,最近怎么样?” |
# 涵盖不同任务类型的SFT数据集(解释类、翻译类、创作类)
sft_data = [
{
"instruction": "解释量子计算的基本概念",
"input": "", # 无补充信息,指令已明确任务
"output": "量子计算是一种利用量子力学核心原理(如量子叠加、量子纠缠)处理信息的计算范式。与传统计算机用'0'和'1'二进制比特存储信息不同,量子计算使用量子比特(Qubit),可同时处于多个状态的叠加态,因此在处理大数分解、量子模拟等特定问题时,效率远超传统计算机。"
},
{
"instruction": "将以下英文翻译成中文,保持口语化风格",
"input": "Hey buddy, do you wanna grab a cup of coffee after work?",
"output": "嘿兄弟,下班后要不要一起去喝杯咖啡呀?" # 符合“口语化”指令要求
},
{
"instruction": "根据以下场景写一段50字以内的温馨提示",
"input": "小区电梯维修,预计3天内恢复使用",
"output": "各位邻居:小区电梯正维修,3天内恢复,不便之处请谅解,出行可走楼梯~"
}
]监督微调核心挑战:
SFT 虽成本低于预训练,但仍面临 “数据质量”“过拟合”“泛化能力” 三大核心挑战,直接影响模型的实用效果
|
挑战类别 |
具体表现 |
应对策略 |
|
数据质量依赖 |
SFT 模型性能完全依赖标注数据:若数据存在错误(如翻译错误)、偏见(如性别歧视表述),模型会 “学错”;若数据量过少(不足千条),模型无法覆盖多样场景。 |
1. 数据筛选:人工审核标注数据,剔除错误、偏见内容; 2. 数据增强:对同类任务数据进行改写(如同义句替换),扩大数据量; 3. 领域覆盖:确保数据包含目标场景(如代码生成、医疗咨询),避免 “偏科”。 |
|
易发生过拟合 |
SFT 数据量远小于预训练数据(通常万级 vs 万亿级),模型易 “死记硬背” 标注数据,面对未见过的新指令时无法灵活应对(如只学过 “翻译英文”,不会 “翻译日文”)。 |
1. 正则化策略:加入 Dropout 层(概率 0.1~0.2)、权重衰减(Weight Decay=1e-4),抑制过拟合; 2. 数据多样性:增加任务类型(如解释、翻译、创作)和输入风格(正式 / 口语); 3. 早停机制(Early Stopping):监控验证集损失,损失上升时停止训练。 |
|
指令理解偏差 |
模型可能误解模糊指令(如 “处理一下这份文件” 未说明 “处理方式”),或无法处理复杂指令(如多步骤任务 “先总结文本,再提取关键词”)。 |
1. 指令精细化:标注数据中明确指令的 “任务类型” 和 “输出要求”(如 “处理文件:需提取姓名和电话,输出表格格式”); 2. 复杂任务拆解:将多步骤指令拆分为单步骤数据(如先标注 “总结文本”,再标注 “提取关键词”); 3. 加入指令描述示例:在数据中增加 “指令说明”(如 “解释概念:需包含定义、原理、应用场景”)。 |
3、RLHF——学习人类的偏好
经过有监督微调(SFT)的模型虽能 “按指令做事”,却未必能 “做人类喜欢的事”—— 这就是 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)存在的核心价值:解决 “有用的回答 ≠ 人类喜欢的回答” 的矛盾,让模型输出更贴合人类偏好(如自然、礼貌、有帮助)。
目标:解决 “有用的回答 ≠ 人类喜欢的回答” 的矛盾。
RLHF 三步核心流程:
- 收集人类偏好数据
- 让标注者对 SFT 模型的 3-5 个回答排序(如 A>B>C),标注 “更优 / 较差”,把隐性偏好变成可量化的标签。
- 训练奖励模型(RM)
- 用排序数据训练模型,让它能给 “指令 + 回答” 打分(分数越高越符合人类偏好)。核心逻辑:确保 “优回答分数>差回答分数”。
- 强化学习优化(PRO算法)
- 以奖励模型为 “裁判”,让 SFT 模型调整输出 —— 分数高就强化该模式,分数低就调整,同时避免模型忘记 SFT 的基础能力。
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import AutoModel, AutoTokenizer
# 1. 定义奖励模型
class RewardModel(nn.Module):
def __init__(self, base_model):
super().__init__()
self.base = AutoModel.from_pretrained(base_model)
self.head = nn.Linear(self.base.config.hidden_size, 1)
def forward(self, input_ids, attention_mask):
# 取最后有效token的隐藏状态算分数
out = self.base(input_ids=input_ids, attention_mask=attention_mask)
last_idx = attention_mask.sum(1)-1
seq_repr = out.last_hidden_state[range(len(input_ids)), last_idx]
return self.head(seq_repr).squeeze()
# 2. 训练函数
def train_rm(model, tokenizer, data, opt, device):
model.train()
total_loss = 0.0
for batch in data:
# 处理优/差回答
a = tokenizer(batch["ins"]+batch["good"], return_tensors="pt", truncation=True, max_length=512).to(device)
b = tokenizer(batch["ins"]+batch["bad"], return_tensors="pt", truncation=True, max_length=512).to(device)
# 打分+算损失
score_a, score_b = model(**a), model(**b)
losRLHF核心挑战:
|
挑战 |
应对方法 |
|
标注者偏好有偏差 |
统一标注标准,覆盖多场景数据 |
|
奖励模型过拟合 |
数据增强(改写指令),加 Dropout 层 |
|
RL 阶段训练不稳定 |
用 PPO 的 “剪辑损失” 限制调整幅度,加 KL 散度约束(避免胡言乱语) |
三、LLM的推理过程
1、自回归生成:一个 token 一个 token 地 "思考"
自回归生成是 LLM 推理的核心逻辑 —— 像猜词游戏一样,基于历史语境逐 token 生成,最终拼凑出完整回答。
工作原理:模型仅依赖当前已生成的 token 序列(语境),计算所有可能下一个 token 的概率,选概率最高的 token 追加到序列中,重复该过程直到生成结束符。
输入:"法国的首都是" → tokens: [法,国,的,首,都,是]
- 语境:[法,国,的,首,都,是] → 算得 "巴" 的概率最高 → 追加
- 语境:[法,国,的,首,都,是,巴] → 算得 "黎" 的概率最高 → 追加
- 语境:[法,国,的,首,都,是,巴,黎] → 算得 "< 结束 >" 概率最高 → 停止
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def generate_text(model, tokenizer, prompt, max_len=50):
# 1. 文本转token(推理输入预处理)
input_ids = tokenizer.encode(prompt, return_tensors="pt")
generated = input_ids.clone()
for _ in range(max_len):
# 2. 模型预测:输出所有token的概率(logits)
outputs = model(generated, return_dict=True)
# 取最后一个token的概率分布(只关注下一个token)
next_logits = outputs.logits[:, -1, :]
# 3. 选概率最高的token(贪心搜索策略)
next_token = torch.argmax(next_logits, dim=-1, keepdim=True)
# 4. 追加token并检查终止
generated = torch.cat([generated, next_token], dim=-1)
if next_token.item() == tokenizer.eos_token_id:
break
# 5. token转回文本(过滤特殊符号)
return tokenizer.decode(generated[0], skip_special_tokens=True)
# 运行示例
if __name__ == "__main__":
# 加载因果语言模型(如Llama、GPT类)
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
tokenizer = AutoTokenizer.from_pretrained("distilgpt2")
# 补充结束符(部分模型默认无,需手动设置)
tokenizer.pad_token = tokenizer.eos_token
result = generate_text(model, tokenizer, prompt="法国的首都是", max_len=50)
print(result) # 输出:法国的首都是巴黎关健特点和局限
| 特点 / 局限 | 说明 |
|---|---|
| 逐 token 生成 | 每次仅依赖历史语境,无全局规划能力,可能出现 "局部合理但整体跑偏" |
| 贪心搜索缺陷 | 只选当前最优 token,可能错过更优长序列(如 "今天天气"→选 "不错" 而非 "很好,适合出游") |
| 终止机制 | 依赖结束符(eos_token),若无对应训练数据可能生成过长或过短文本 |
2、解码策略:控制生成的"创造性"
自回归生成时,“选哪个下一个 token” 由解码策略决定 —— 不同策略会让输出呈现 “确定” 或 “多样” 的特点,核心是平衡 “准确性” 和 “创造性”。
两种核心对比:
|
策略 |
逻辑 |
特点 |
适用场景 |
|
贪婪搜索 |
每次选概率最高的 token |
输出确定但可能单调、局限 |
问答、摘要(需准确) |
|
随机采样 |
从概率分布中随机选 token |
输出多样但可能偏离主题 |
创作、对话(需灵活) |
import torch
def sampling_decode(logits, temp=1.0, top_k=50, top_p=0.9):
"""
带温度、Top-k、Top-p的采样解码(平衡创造性与准确性)
参数:
- temp: 温度(>1更随机,<1更确定,=1无调节)
- top_k: 只保留前k个高概率token(过滤低概率噪声)
- top_p: 保留累积概率≥p的token(动态筛选,更灵活)
"""
# 1. 温度调节:缩放概率分布
logits = logits / temp # temp=0.5时,高概率token更突出
# 2. Top-k筛选:只留前k个高概率token
top_k_val = torch.topk(logits, top_k)[0][..., -1, None]
logits[logits < top_k_val] = -float('inf') # 低概率token设为负无穷(不参与采样)
# 3. Top-p(核采样):保留累积概率≥top_p的token
sorted_logits, sorted_idx = torch.sort(logits, descending=True)
cum_probs = torch.cumsum(torch.softmax(sorted_logits, dim=-1), dim=-1)
# 移除累积概率超top_p的token(首token必保留,避免空集)
to_remove = cum_probs > top_p
to_remove[..., 1:] = to_remove[..., :-1].clone()
to_remove[..., 0] = False
# 映射回原token索引,过滤低概率
logits[to_remove.scatter(dim=-1, index=sorted_idx, src=to_remove)] = -float('inf')
# 4. 从筛选后的分布中采样
probs = torch.softmax(logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1) # 随机选1个token
return next_token关键参数调优建议:
- 温度(temperature):
- 追求准确(如代码生成):设 0.3-0.7;
- 追求多样(如故事创作):设 1.0-1.5;
- Top-k:通常设 20-100,过小易局限,过大易杂乱;
- Top-p:一般设 0.8-0.95,避免极端值(如 <0.7 太局限,>0.99 太随机)。
3、推理优化技术:让大模型"飞起来"
LLM 推理时面临 “速度慢、内存占用高” 的问题,KV 缓存和量化技术是解决这两个痛点的核心方案 —— 前者减少重复计算,后者压缩模型体积,让大模型能在普通硬件上高效运行。
KV 缓存:避免 “重复算”,提升速度
- 速度提升:生成第 N 个 token 时,计算量从 O (N²) 降至 O (N),长文本生成速度提升 3-10 倍;
- 内存代价:需额外存储 KV 缓存,内存占用增加约 20%-30%(但远小于计算收益)。
import torch
class KVCache:
def __init__(self):
# 缓存结构:{层索引: (Key缓存, Value缓存)},Key/Value形状均为[batch, head, seq_len, dim]
self.cache = {}
def update(self, layer_idx, new_k, new_v):
"""更新缓存:新token的KV拼接到历史缓存后"""
if layer_idx not in self.cache:
# 首次计算:直接存入当前层的KV
self.cache[layer_idx] = (new_k, new_v)
else:
# 非首次:拼接历史KV与新KV(只扩展序列长度维度,dim=-2对应seq_len)
old_k, old_v = self.cache[layer_idx]
self.cache[layer_idx] = (
torch.cat([old_k, new_k], dim=-2),
torch.cat([old_v, new_v], dim=-2)
)
def get(self, layer_idx):
"""获取某一层的缓存KV,无缓存则返回(None, None)"""
return self.cache.get(layer_idx, (None, None))
def clear(self):
"""清空缓存(新对话开始时使用)"""
self.cache = {}
# 使用示例:在注意力层中集成KV缓存
def attention_layer(query, key, value, layer_idx, kv_cache):
# 先从缓存取历史KV,无则用当前KV
cached_k, cached_v = kv_cache.get(layer_idx)
if cached_k is not None and cached_v is not None:
key = cached_k # 复用历史Key,无需重新计算
value = cached_v # 复用历史Value,无需重新计算
else:
# 首次计算:更新缓存(后续生成时可复用)
kv_cache.update(layer_idx, key, value)
# 注意力计算(简化版)
attn_score = torch.matmul(query, key.transpose(-2, -1))
attn_weight = torch.softmax(attn_score, dim=-1)
return torch.matmul(attn_weight, value)量化技术:把 “大模型” 变 “小”,节省内存
- 内存节省:INT8 量化减少 75% 内存(FP32→INT8),INT4 量化减少 87.5% 内存;
- 性能影响:INT8 量化性能损失 < 5%,适合大多数场景;INT4 量化需结合校准技术(如 GPTQ),避免性能下降过多。
import torch
def quantize_model_weights(model, dtype=torch.int8):
"""批量量化模型权重:FP32→INT8/INT4,返回量化权重和缩放因子"""
quant_params = {} # 存储{层名: (量化权重, 缩放因子)}
for name, param in model.named_parameters():
if param.dtype == torch.float32: # 只量化浮点数权重
# 计算缩放因子:将权重映射到目标 dtype 的范围(如INT8为[-128, 127])
max_val = torch.max(torch.abs(param))
scale = max_val / (torch.iinfo(dtype).max) # 避免溢出
# 量化:缩放→四舍五入→截断到目标 dtype 范围
quantized = torch.clamp(torch.round(param / scale),
torch.iinfo(dtype).min,
torch.iinfo(dtype).max).to(dtype)
quant_params[name] = (quantized, scale)
# 替换模型权重为量化权重(减少内存占用)
param.data = quantized
return quant_params
def dequantize_weight(quantized, scale, dtype=torch.float32):
"""推理时反量化:INT8/INT4→FP32,用于计算"""
return quantized.float() * scale # 缩放回原数值范围
# 使用示例:量化模型+推理
if __name__ == "__main__":
from transformers import AutoModelForCausalLM
# 加载模型(以小型模型为例)
model = AutoModelForCausalLM.from_pretrained("distilgpt2")
print(f"量化前内存占用:{sum(p.numel()*p.element_size() for p in model.parameters())/1024**2:.2f}MB")
# 量化权重(FP32→INT8)
quant_params = quantize_model_weights(model, dtype=torch.int8)
print(f"量化后内存占用:{sum(p.numel()*p.element_size() for p in model.parameters())/1024**2:.2f}MB")
# 推理时反量化(某一层权重)
layer_name = "transformer.h.0.attn.c_attn.weight"
quant_weight, scale = quant_params[layer_name]
dequant_weight = dequantize_weight(quant_weight, scale) # 用于注意力计算两种技术适用场景
|
技术 |
核心优势 |
适用场景 |
注意事项 |
|
KV 缓存 |
提升生成速度 |
长文本生成(如小说、报告)、对话 |
新对话需清空缓存,避免历史干扰 |
|
量化技术 |
减少内存占用 |
普通 GPU/CPU 推理、多模型并行部署 |
INT4 量化需用专用框架(如 AutoGPTQ) |
四、完整实战示例
以下是一段迷你LLM的示例代码
import torch
import torch.nn as nn
from transformers import GPT2Config, GPT2LMHeadModel, AutoTokenizer
class MiniLLM:
def __init__(self, model_name="gpt2"):
self.config = GPT2Config(
vocab_size=50257,
n_embd=768,
n_layer=12,
n_head=12,
)
self.model = GPT2LMHeadModel(self.config)
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
def tokenize_text(self, text):
"""演示分词过程"""
tokens = self.tokenizer.tokenize(text)
token_ids = self.tokenizer.encode(text)
print(f"文本: {text}")
print(f"Tokens: {tokens}")
print(f"Token IDs: {token_ids}")
return token_ids
def train(self, texts, epochs=3):
"""简化版训练过程"""
optimizer = torch.optim.AdamW(self.model.parameters(), lr=5e-5)
for epoch in range(epochs):
total_loss = 0
for text in texts:
# 文本转换为token IDs
inputs = self.tokenizer.encode(text, return_tensors="pt")
# 下一个token预测损失
outputs = self.model(inputs, labels=inputs)
loss = outputs.loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch {epoch}, Loss: {total_loss/len(texts):.4f}')
def generate(self, prompt, max_new_tokens=50, temperature=0.8):
"""文本生成"""
self.model.eval()
with torch.no_grad():
input_ids = self.tokenizer.encode(prompt, return_tensors="pt")
for i in range(max_new_tokens):
outputs = self.model(input_ids)
next_token_logits = outputs.logits[:, -1, :]
# 应用采样策略
next_token = sampling_decode(next_token_logits, temperature)
input_ids = torch.cat([input_ids, next_token], dim=-1)
# 实时显示生成过程
current_text = self.tokenizer.decode(input_ids[0], skip_special_tokens=True)
print(f"Step {i}: {current_text}")
if next_token.item() == self.tokenizer.eos_token_id:
break
return self.tokenizer.decode(input_ids[0], skip_special_tokens=True)
# 使用示例
llm = MiniLLM()
llm.tokenize_text("你好,人工智能!")
training_texts = ["机器学习很有趣", "深度学习改变世界"]
llm.train(training_texts)
result = llm.generate("人工智能的未来")
print("最终结果:", result)五、总结与展望
1、完整流程回顾
-
文本处理:原始文本 → token序列 → 模型理解
-
训练阶段:预训练(学知识)→ 微调(学交流)→ 对齐(学偏好)
-
推理生成:自回归生成 → 解码策略 → 优化加速
2、未来展望
-
更长上下文:处理更多token的模型正在出现
-
更智能推理:从token级生成到思维链推理
-
多模态扩展:从文本token到图像、音频的统一表示
通过这篇文章,您应该对LLM的完整生命周期有了深入理解——从最基础的token处理,到复杂的训练流程,再到高效的推理生成。这正是现代人工智能能够如此强大的技术基础。
更多推荐


 42
42 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)