
阿里发布一系列新模型,Qwen3-Omni强势对标Gemini
阿里巴巴发布多模态大模型Qwen3-Omni,对标谷歌Gemini,支持文本、图像、音频和视频的统一处理。同时推出升级版图像编辑模型Qwen-Image-Edit-2509,增强多图编辑和一致性;以及高效文本转语音模型Qwen3-TTS-Flash,支持多语言、多方言和丰富音色,在多项测试中达到SOTA性能。这些新模型彰显了阿里在AI领域加速技术迭代、争夺全球领导地位的决心。
近日,阿里巴巴旗下通义千问团队重磅发布了一系列新模型,覆盖多模态大模型、图像编辑和文本转语音等多个前沿领域。此次发布的核心亮点是原生多模态模型 Qwen3-Omni,标志着阿里在大模型技术竞赛中进入了新的阶段。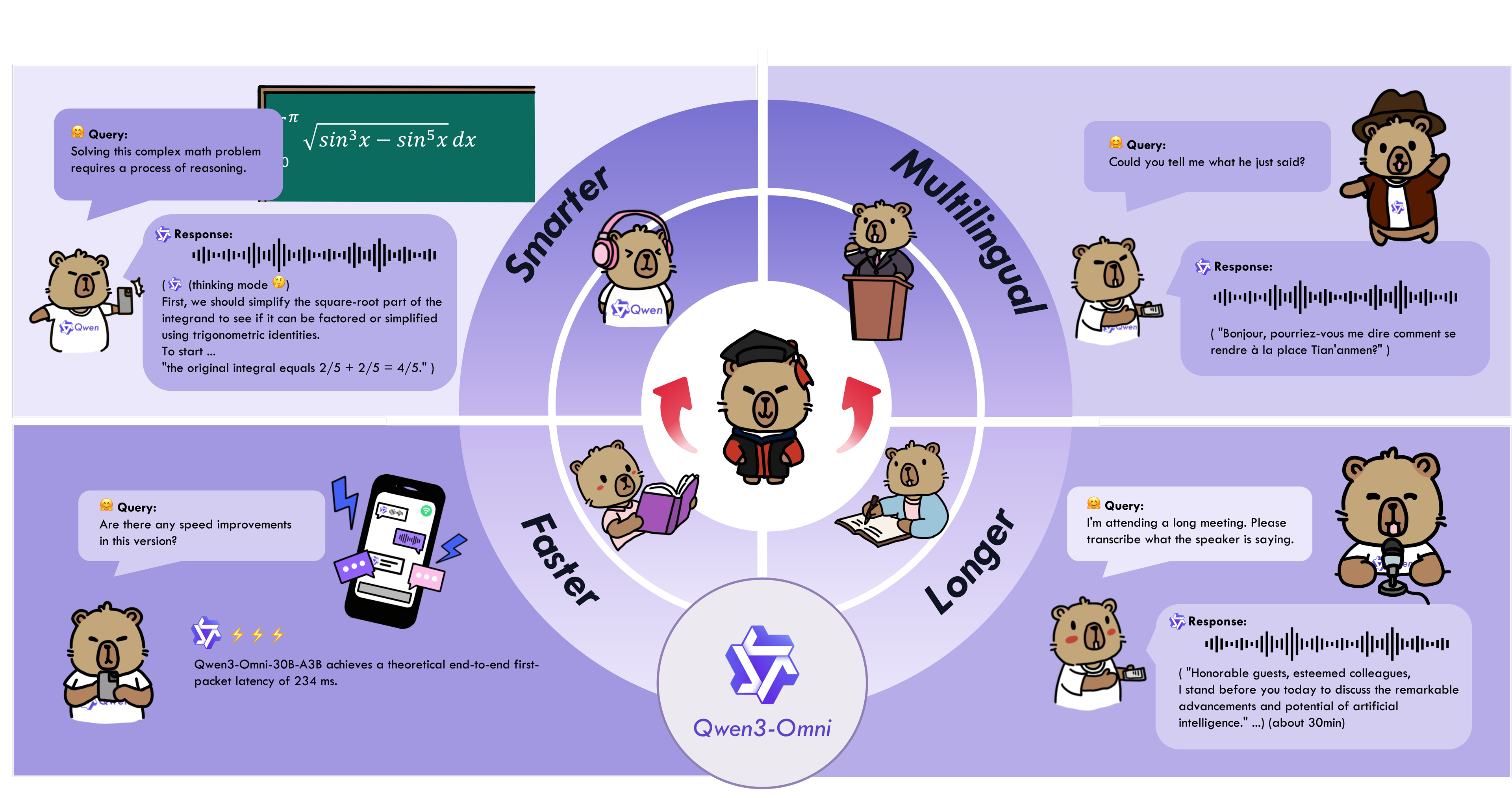
1. Qwen3-Omni:全能型多模态模型,对标国际顶尖水平
Qwen3-Omni 是本次发布的核心产品,被定位为与谷歌 Gemini 全面对标的全能型模型。其最大特点是“原生多模态”,意味着模型在设计之初就具备统一理解和生成文本、图像、音频、视频等多种信息的能力,而非将不同模态的模型简单拼接。
- 核心能力:能够无缝处理和理解文本、图片、音频和视频内容,并在此基础上进行推理、问答和创作。
- 战略意义:这一定位直接瞄准了当前全球多模态大模型的最前沿,展示了阿里在通用人工智能技术上的雄心。
- 模型获取:该模型已在 Hugging Face 平台上线,开发者可前往体验和研究。
技术报告: Qwen3-Omni Technical Report
模型地址: https://github.com/QwenLM/Qwen3-Omni
模型架构: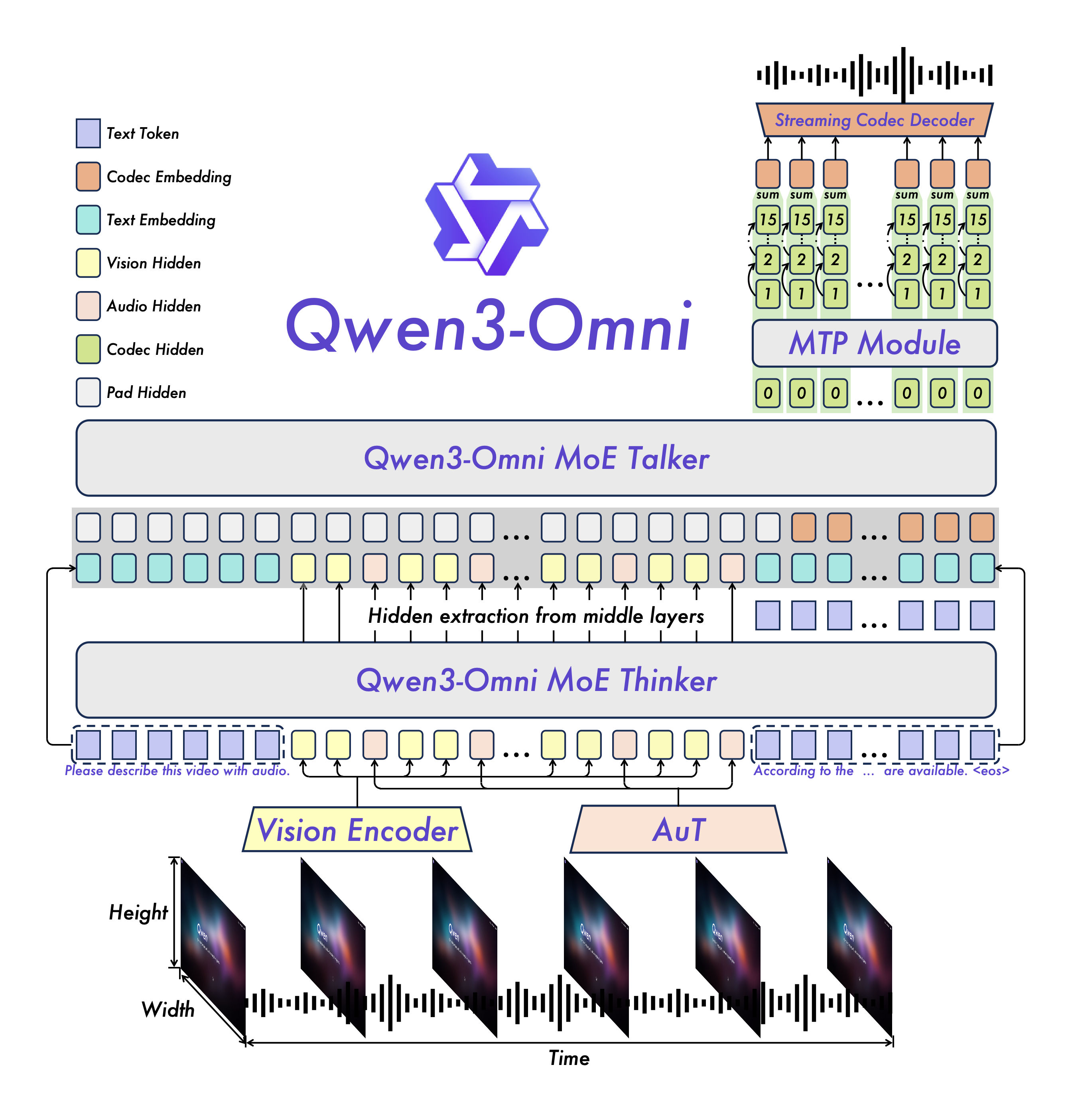

2. Qwen-Image-Edit-2509:升级版图像编辑模型,功能更强大
九月,Qwen推出 Qwen-Image-Edit-2509,这是 Qwen-Image-Edit 的月度迭代版本。要体验最新版本,请访问Qwen Chat 并选择“图像编辑”功能。与八月发布的 Qwen-Image-Edit 相比,Qwen-Image-Edit-2509 的主要改进包括:
- 多图像编辑支持:对于多图像输入,Qwen-Image-Edit-2509 基于 Qwen-Image-Edit 架构构建,并通过图像连接进一步训练,以实现多图像编辑。它支持各种组合,例如“人物 + 人物”、“人物 + 产品”和“人物 + 场景”。目前,1 至 3 张输入图像即可达到最佳性能。
- 增强单图一致性:对于单图输入,Qwen-Image-Edit-2509 显著提高了编辑一致性,具体表现在以下几个方面:
- 改进人物编辑一致性:更好地保留面部特征,支持各种肖像风格和姿势变换;
- 提升产品编辑一致性:更好地保留产品身份,支持产品海报编辑;
- 提升文本编辑一致性:除了修改文本内容外,还支持编辑文本字体、颜色、材质;
ControlNet 的原生支持:包括深度图、边缘图、关键点图等。
模型地址: https://huggingface.co/Qwen/Qwen-Image-Edit-2509
3. Qwen3-TTS-Flash:高效的文本转语音模型
Qwen3-TTS-Flash 是支持多音色、多语言和多方言的旗舰语音合成模型,旨在生成自然且具有表现力的语音,目前可通过Qwen API访问。
主要特点:
- 卓越的中英稳定性:Qwen3-TTS-Flash的中英稳定性在seed-tts-eval test set上,取得了SOTA的表现,超越SeedTTS、MiniMax、GPT-4o-Audio-Preview。
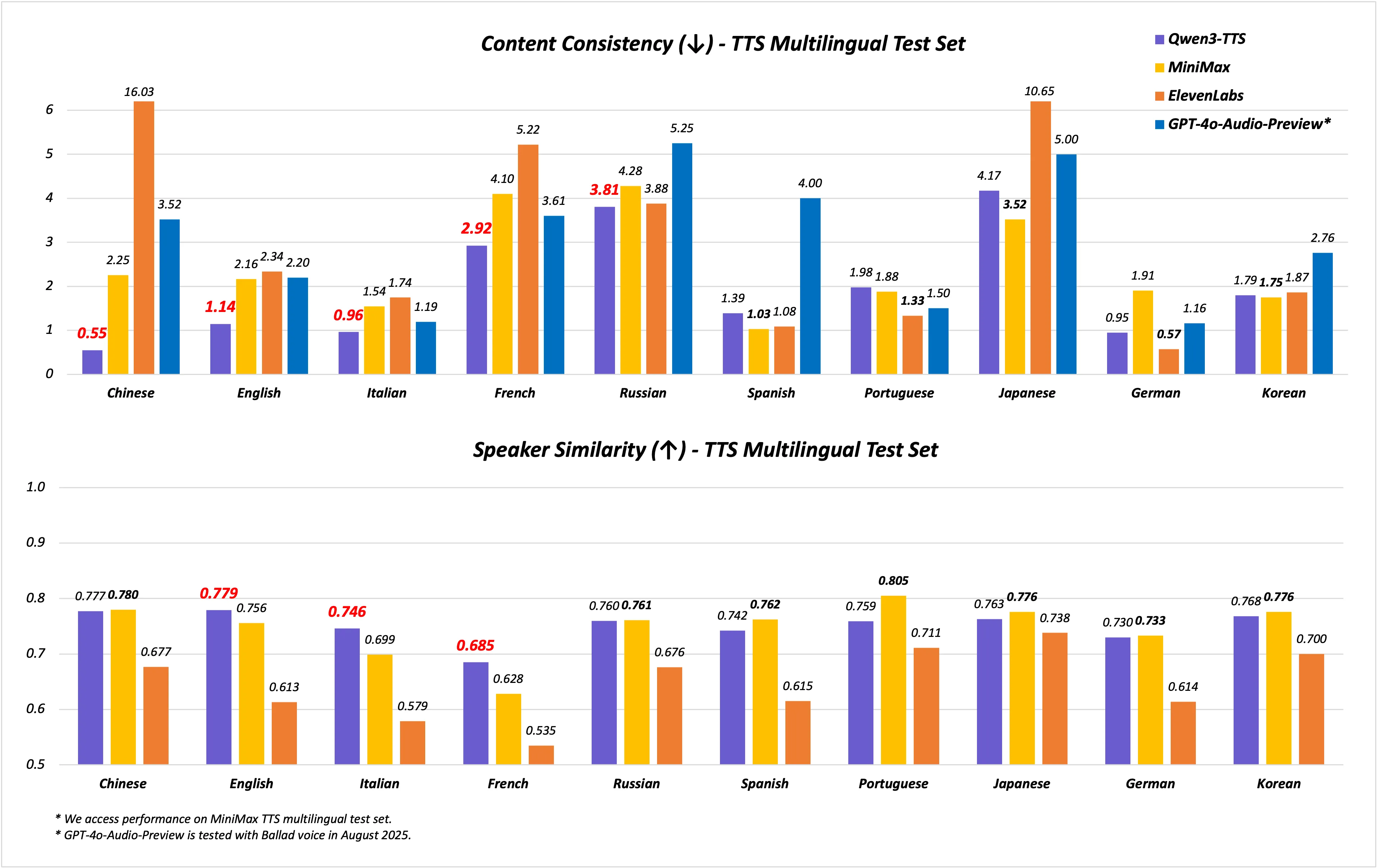
- 出色的多语言性能:多语言稳定性和音色相似度上,Qwen3-TTS-Flash在MiniMax TTS multilingual test set上,WER在中文、英文、意大利语、法语达到SOTA,显著低于MiniMax、ElevenLabs、GPT-4o-Audio-Preview,英文、意大利语、法语的说话人相似度显著超越MiniMax、ElevenLabs、GPT-4o-Audio-Preview。
- 高表现力:Qwen3-TTS-Flash具备高表现力的拟人音色,能够稳定、可靠地输出高度遵循输入文本的音频。
- 丰富的音色和语种:Qwen3-TTS-Flash 提供17种音色选择,每一种音色均支持10种语言。
- 多方言支持:Qwen3-TTS-Flash支持方言生成,包括普通话、闽南语、吴语、粤语、四川话、北京话、南京话、天津话和陕西话。
- 语气适应:经过海量数据训练,Qwen3-TTS-Flash能够根据输入文本自动调节语气。
- 高鲁棒性:Qwen3-TTS-Flash能够自动处理复杂文本,抽取关键信息,对复杂和多样化的文本格式具有很强的鲁棒性。
- 快速生成:Qwen3-TTS-Flash具有极低首包延迟,单并发首包模型延迟低至97ms。
模型性能
对Qwen3-TTS-Flash在语音稳定性和音色相似度方面进行了全面评估,结果显示其在多项指标上都达到了SOTA性能。
具体来说,在seed-tts-eval test set上,Qwen3-TTS-Flash在中英文的语音稳定性表现上均取得了SOTA成绩,超越了SeedTTS、MiniMax和GPT-4o-Audio-Preview。此外,在MiniMax TTS multilingual test set上,Qwen3-TTS-Flash在中文、英文、意大利语和法语的WER均达到了SOTA,显著低于MiniMax、ElevenLabs和GPT-4o-Audio-Preview。
在说话人相似度方面,Qwen3-TTS-Flash在英文、意大利语和法语均超过了上述模型,在多语言的语音稳定性和音色相似度上展现出了卓越的表现。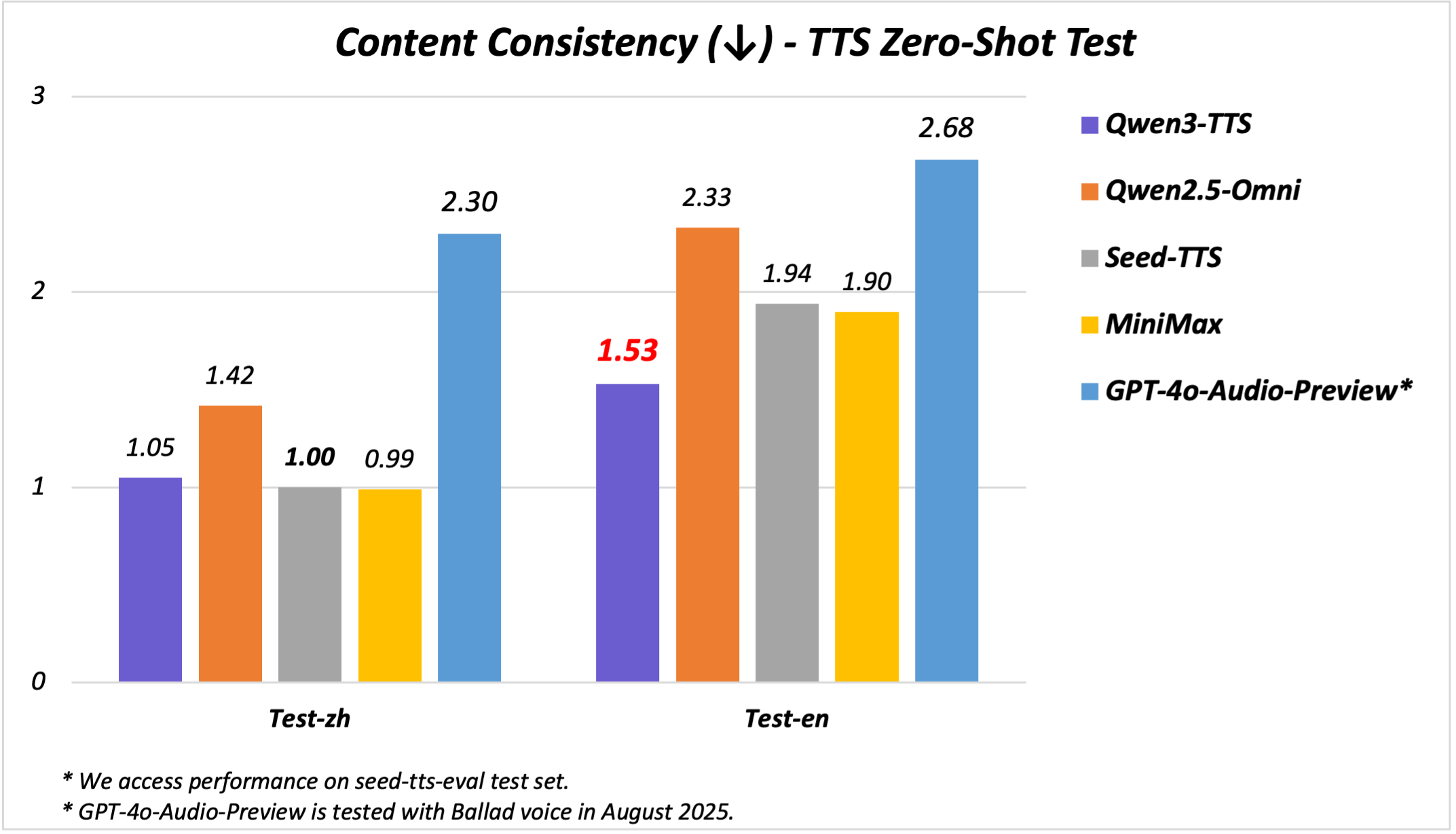
总结
此次阿里密集发布新模型,尤其是在核心的多模态赛道推出对标 Gemini 的 Qwen3-Omni,清晰地传递出其加速技术迭代、争夺全球AI领导地位的信号。通过将强大的原生多模态模型与垂直领域的专业工具相结合,阿里正试图构建一个更具竞争力和实用性的AI生态系统。
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)