
PyTorch + CUDA 让你的本地大模型推理飞起来
本文介绍了在Windows/Linux系统上安装PyTorch和CUDA以加速本地大模型推理的完整教程。主要内容包括:1)通过nvidia-smi确认显卡支持CUDA;2)推荐使用pip直接安装自带CUDA运行时的PyTorch(方案一),或从NVIDIA官网安装完整CUDA Toolkit(方案二);3)验证PyTorch与CUDA的兼容性;4)实战演示如何在PyTorch环境中配置Huggin
适用于 Windows / Linux 系统(macOS 无 NVIDIA GPU 不适用),目标加速本地大模型推理!
🧠 PyTorch + CUDA 安装与加速推理完整教程
✅ 食用人群:想在本地 GPU 上部署 LLM(如 LLaMA、Qwen、ChatGLM、Mistral)并实现高性能推理的开发者
✅ 目标:正确安装驱动、PyTorch、CUDA Toolkit,并验证加速推理效果
📋 1 准备工作
1.1 确认你的显卡支持CUDA
# Windows/Linux 终端运行:
nvidia-smi
⚠️ cmd 运行nvidia-smi会看到如下提示:

✅ 切换到bash如果看到类似输出:
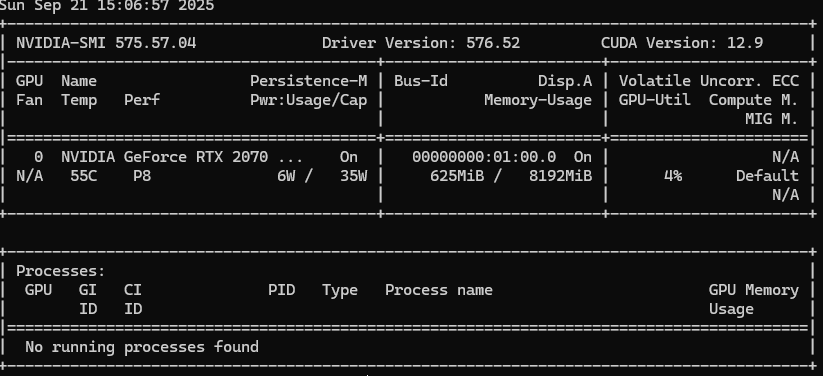
→ 说明你有 NVIDIA 显卡,且驱动已安装。
💡 注意:CUDA Version 显示的是驱动支持的最高 CUDA 版本,不是你当前安装的 Toolkit 版本
1.2 安装 CUDA 运行时
⚠️ 重要概念澄清:
- 你不需要完整安装 CUDA Toolkit 来运行 PyTorch 推理!
- PyTorch 的 pip 包已经内置了所有必需的 CUDA 运行时库(如
libcudart,libcublas)- 只有在你需要
nvcc编译器(如装flash-attn,vLLM)时,才需安装完整 CUDA Toolkit
方案一(推荐):跳过 conda 安装 cudatoolkit,直接用 pip 装 PyTorch
conda 安装见我另一篇博客5202年用Conda 管理 Python 环境
# 创建并激活环境
conda activate py3_10
# 直接安装 PyTorch(自带 CUDA 12.1 运行时)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
✅ 这是目前 95% 用户的最佳实践 —— 简单、稳定、无需折腾
cudatoolkit
方案二:从 NVIDIA 官网安装完整 Toolkit(含 nvcc)
👉 前往:https://developer.nvidia.com/cuda-downloads
⚠️ 官网主页提供的是最新版本CUDA Toolkit,根据自己电脑配置请下载合适版本,其他版本CUDA Toolkit前往:https://developer.nvidia.com/cuda-toolkit-archive
选择你的系统 → 下载 .run(Linux)或 .exe(Windows)文件
Linux 示例(以 Ubuntu 22.04 + CUDA 12.4 为例)
wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run
sudo sh cuda_12.4.0_550.54.14_linux.run
✅ 安装时取消勾选“Driver”(如果你已装好最新驱动),只勾选
CUDA Toolkit
安装后配置环境变量(Linux/macOS):
echo 'export PATH=/usr/local/cuda-12.4/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
验证:
nvcc --version
# 应输出:Cuda compilation tools, release 12.4, V12.4.xxx
windows 示例(以 Windows 11 + CUDA 12.1 为例)
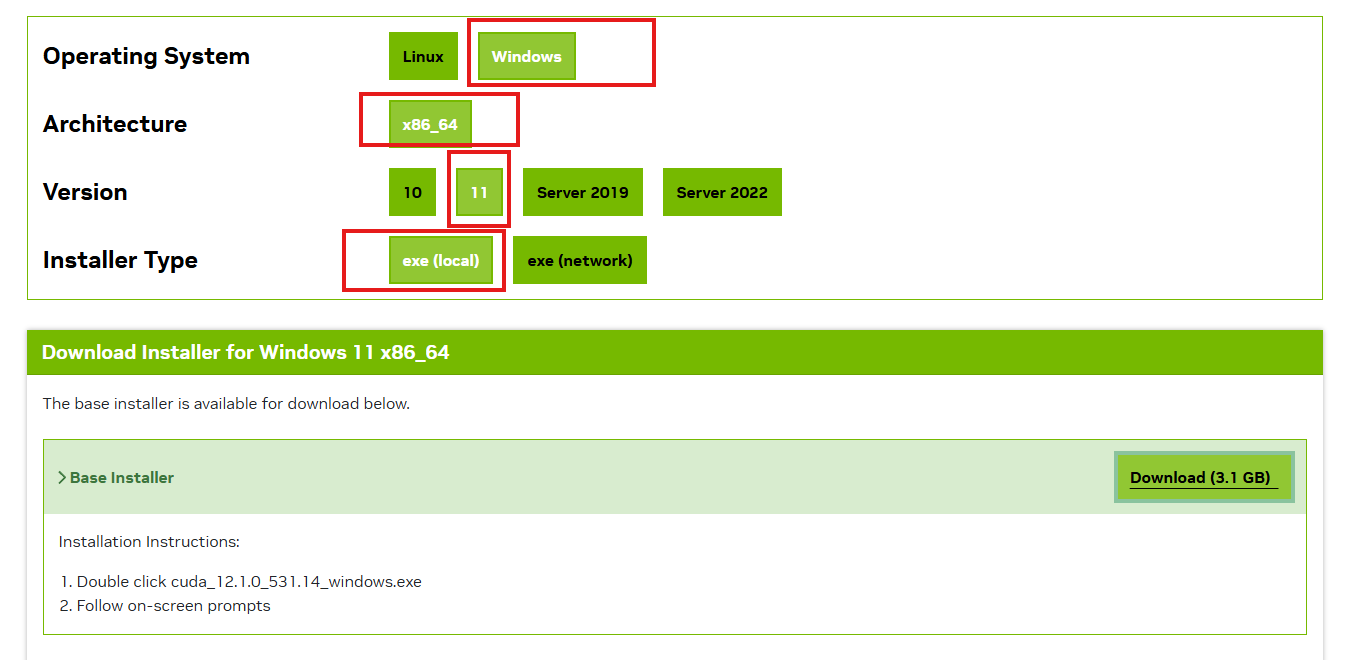
📌 选项选择:
- 操作系统:Windows
- 架构:x86_64(99% 的电脑都是这个)
- 版本:你用 Win10 就选 10,Win11 就选 11
- 需要联网 → exe (network): 在线/快速安装快速适合普通用户
- 不联网→ exe (local) ** :离线/批量部署适合服务器、科研人员、IT 管理员
- 双击运行: 快速安装即可
验证 PyTorch + CUDA 是否正常工作
- 测试代码
# test_cuda.py
import torch
print("PyTorch版本:", torch.__version__)
print("CUDA可用:", torch.cuda.is_available())
print("CUDA版本:", torch.version.cuda)
print("cuDNN版本:", torch.backends.cudnn.version() if torch.backends.cudnn.is_available() else "N/A")
print("GPU数量:", torch.cuda.device_count())
if torch.cuda.is_available():
print("当前GPU:", torch.cuda.get_device_name(0))
# 创建一个张量测试计算
x = torch.randn(1000, 1000).cuda()
y = torch.randn(1000, 1000).cuda()
z = torch.matmul(x, y)
print("矩阵乘法测试成功!结果形状:", z.shape)
- 运行
python D:\test_cuda.py
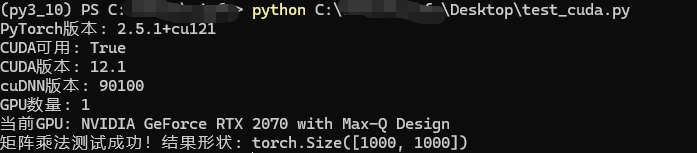
- 输出
🚀 五、实战:用 HuggingFace Transformers + GPU 加速推理
1 pyCharm 配置Conda 环境’
-
打开你的项目后,进入:
File ➜ Settings(Windows/Linux)
或 PyCharm ➜ Preferences(macOS)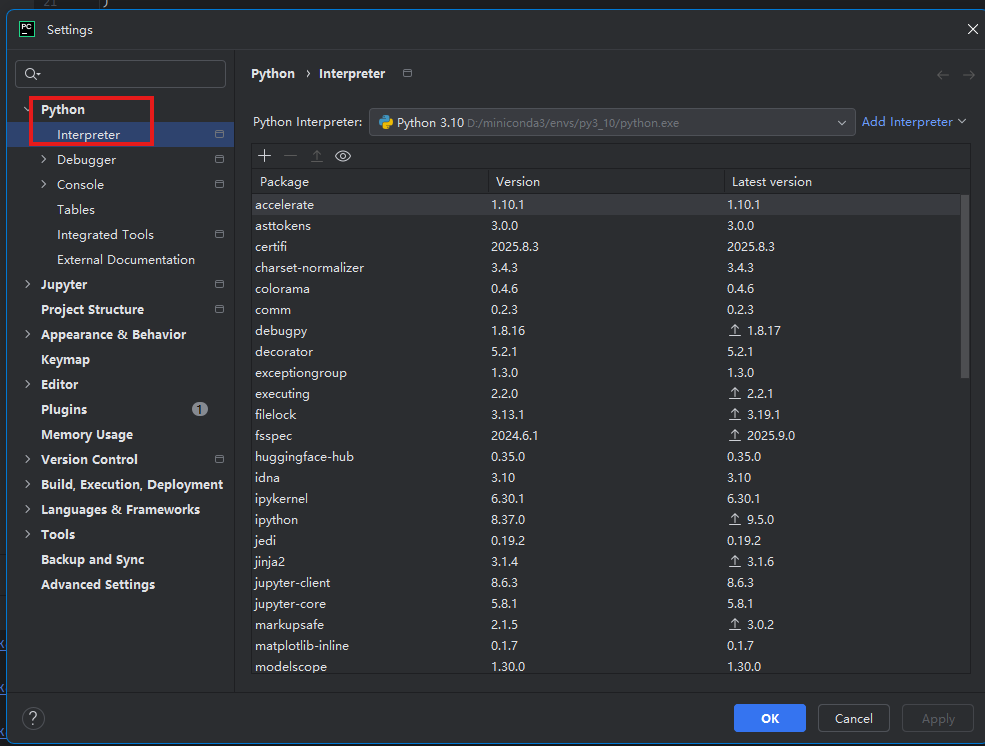
-
导航到:
Project: <项目名> ➜ Python Interpreter
点击右上角的 ⚙️ 齿轮图标 ➜ 选择 “Add…”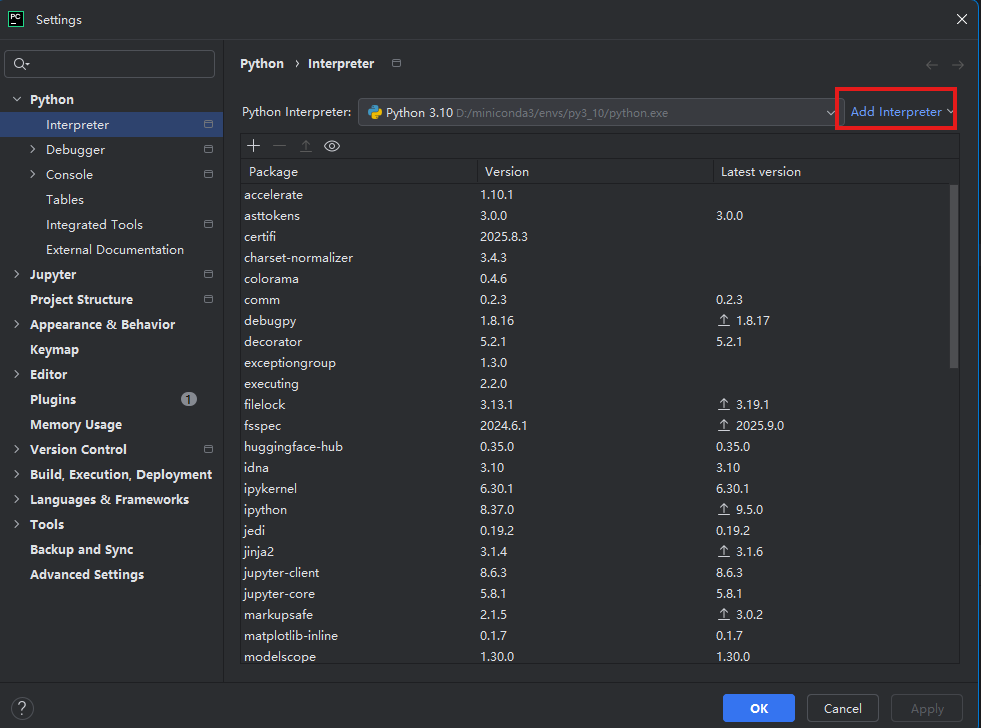
-
同样选择:
- Conda Environment
- Existing environment
- 手动浏览并选择
py3_10环境中的python可执行文件(路径同上)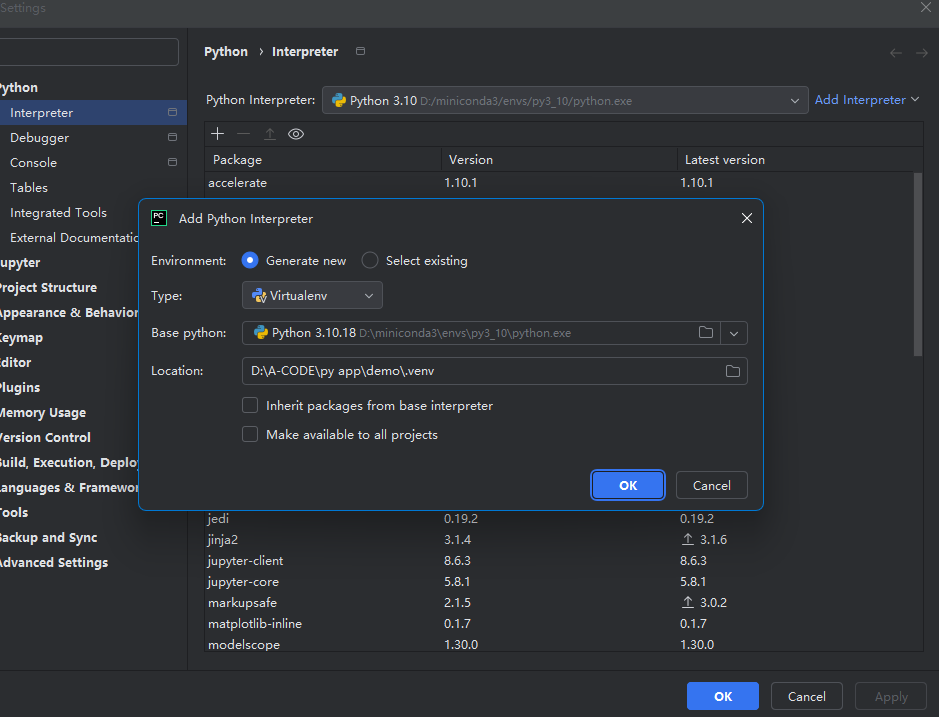
-
点击 “OK”,PyCharm 会自动加载该环境的包列表。
-
用一个小模型(如 Qwen2.5-0.5B-Instruct)测试加速效果:
- 先下载模型,不然模型太大,下载容易超时
from modelscope import snapshot_download # 模型下载到本地
# 先下载模型
model_dir = snapshot_download(
'Qwen/Qwen2.5-0.5B-Instruct',
cache_dir='D:\A-CODE\Models' # 下载到当前目录的 models 文件夹,
)
print(f"✅ 模型已下载到本地: {model_dir}")
- 运行测试代码
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import time
# ⬇️ 改为加载本地路径
model_dir = "D:\A-CODE\Models\Qwen\Qwen2.5-0.5B-Instruct"
prompt = "请用一句话解释量子力学"
messages = [{"role": "user", "content": prompt}]
def test_inference(device="cuda", dtype=torch.float16):
print(f"\n=== 测试设备: {device} ({dtype}) ===")
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_dir,
dtype=dtype,
device_map=device,
trust_remote_code=True
)
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(text, return_tensors="pt").to(model.device)
start_time = time.time()
outputs = model.generate(
**inputs,
max_new_tokens=100,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
end_time = time.time()
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
if "<|im_start|>assistant" in response:
response = response.split("<|im_start|>assistant")[-1].strip()
print("回复:", response)
print(f"⏱️ 耗时: {end_time - start_time:.2f} 秒")
print(f"使用设备: {model.device}")
# 清理内存
del model
torch.cuda.empty_cache() if device == "cuda" else None
# ===== GPU 测试 =====
test_inference(device="cuda", dtype=torch.float16)
# ===== CPU 测试 =====
test_inference(device="cpu", dtype=torch.float32)
运行:
python accelerate_inference.py
✅ 可见GPU的推理速度是CPU的四倍
更多推荐
 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)