
下一代AI应用引擎:多模态处理架构的核心组件与数据流
本文系统介绍了多模态数据向量化处理的工作流程,包括三个关键阶段:1)数据预处理与模态转换,将图像、视频和音频等非文本数据转换为文本描述;2)统一向量嵌入与语义对齐,利用文本嵌入模型实现跨模态语义映射;3)向量数据库存储与高效检索,采用ANN算法实现快速语义搜索。文章强调这是一个系统工程,需要优化每个技术环节,并指出多模态数据处理是构建下一代AI应用的核心能力。最后附带了AI大模型学习资料推荐,包含
在当今的AI领域,我们早已跨越了单一模态数据处理的阶段。如何高效、系统化地处理和利用海量的多模态数据,已经成为构建下一代智能应用的关键。今天,我将与大家深入探讨一个典型的多模态数据向量化工作流,从其背后的技术选型、架构设计到具体实现,进行一次全方位的解构。
这个工作流的核心思想是,通过一系列的模态转换(Modality Translation)和嵌入(Embedding),将异构数据(文本、图像、视频、音频)统一映射到同一个高维向量空间,从而实现基于语义的跨模态检索和分析。
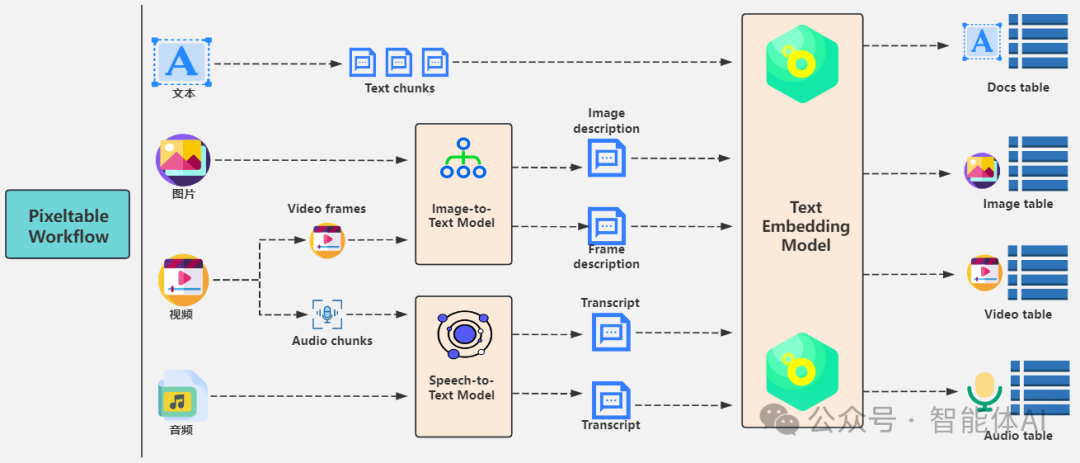
一、多模态数据预处理与模态转换
这一阶段的目标是将所有非文本数据转换为结构化或非结构化的文本描述,为后续的向量化做准备。这是整个工作流的基石,其准确性和效率直接影响最终的检索效果。
-
文本:
作为原生文本数据,其处理相对直接。通常需要进行分块(Chunking)操作,以适应大型语言模型(LLM)的上下文窗口限制,并确保每个数据块都具有完整的语义信息。常用的分块策略包括:按固定字符数或句子数分块,以及更智能的基于 Markdown 语法或语义边界的分块。
-
图像与视频:
核心是利用多模态大模型(Multimodal Large Models, MLLMs)进行图像标注(Image Captioning)和视频帧描述。
-
- 技术选型: 典型模型如 Vision-Language Models (VLMs),例如 BLIP-2、CoCa 或 GPT-4V。这些模型通常采用编码器-解码器架构,其中视觉编码器(如 ViT)提取图像特征,语言模型解码器(如 T5 或 LLaMA)根据这些特征生成描述性文本。
- 视频处理的挑战: 对于视频,我们需要决定采样策略。是按固定时间间隔(如每秒一帧)采样,还是基于关键帧提取(Keyframe Extraction)。后者更具挑战性,需要利用算法识别视频中内容变化最大的帧,以最小化计算量并最大化信息覆盖。生成的每一帧描述都可以看作是视频在特定时间点的“快照”。

-
音频:
音频转录依赖于先进的语音识别(Automatic Speech Recognition, ASR)模型。
-
- 技术选型:OpenAI Whisper 是目前行业内公认的标杆模型之一。其优势在于其强大的多语言能力和对口音、噪音的鲁棒性。Whisper 采用了编码器-解码器Transformer架构,通过在大规模多语种、多任务数据上进行训练,实现了卓越的泛化能力。
- 视频中的音频: 对于视频数据流中的音频,通常需要先进行音频流分离,然后进行转录。这对于处理包含对话、背景音乐和环境音的复杂场景至关重要。
二、统一的向量嵌入与语义对齐
经过上一阶段的处理,所有数据都已转化为文本形式。接下来的关键是利用文本嵌入模型(Text Embedding Model)将这些异构文本映射到同一个高维向量空间,实现语义上的对齐。
-
核心模型:
这里的模型通常是基于 Transformer 架构的,如 Sentence-BERT (SBERT)、E5 或 OpenAI Embedding API。这些模型的核心能力在于,它们能够生成语义向量,即向量的距离能够有效反映文本内容的语义相似度。例如,embedding("一只猫")≈embedding("一只小猫咪")embedding("一只猫") \approx embedding("一只小猫咪")embedding("一只猫")≈embedding("一只小猫咪")。
-
多模态对齐的本质:
我们之所以能用一段文字搜索到一张图片或一段视频,其根本原因在于跨模态语义对齐。当“日落下的海滩”的图像描述与“夕阳、海、沙滩”的搜索文本通过同一个强大的文本嵌入模型进行编码时,它们的向量会在高维空间中非常接近。这得益于这些模型在训练过程中通过对比学习(Contrastive Learning),使相似语义的跨模态数据对(如图像-描述对)在向量空间中更靠近。
三、向量数据库与高效检索
将所有嵌入向量存储到专门的数据库中是实现高效检索和应用的关键一步。
-
技术选型:
传统的关系型数据库并不擅长处理高维向量的相似性搜索。因此,我们需要使用向量数据库(Vector Database)。主流的开源或商业向量数据库包括 Milvus、Weaviate、Pinecone 或 Qdrant。
-
核心机制:
向量数据库的核心是支持 近似最近邻(Approximate Nearest Neighbor, ANN) 搜索算法。不同于精确搜索,ANN 通过牺牲微小的精度换取巨大的性能提升。常见的 ANN 算法包括 HNSW (Hierarchical Navigable Small World)、IVF (Inverted File Index) 和 LSH (Locality-Sensitive Hashing)。这些算法将高维空间进行结构化,使得在海量向量数据中进行快速检索成为可能。
-
数据存储架构:
在实践中,每个数据表(Docs table, Image table等)通常会存储两类信息:
-
- 原始数据或元数据: 包括原始文本、图像/视频的 URL、音频文件的路径、以及其他结构化信息。
- 向量嵌入: 存储由第二阶段生成的嵌入向量。
当用户进行检索时,查询文本首先被向量化,然后向量数据库通过 ANN 算法找到最相似的向量,最后返回这些向量对应的原始数据或元数据。
四、总结
这个多模态向量化工作流不仅仅是一系列技术的简单堆砌,它是一个系统化的工程实践,贯穿了从数据获取、预处理、模型推理到数据存储与检索的完整链条。其成功依赖于对每个环节技术细节的深刻理解和优化。随着多模态模型的不断演进和向量数据库生态的日益成熟,我们有理由相信,未来所有的非结构化数据都将以这种方式被“索引”和“理解”,为构建更加智能、高效的AI应用开辟新天地。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
大模型学习之路,道阻且长,但只要你坚持下去,一定会有收获。本学习路线图为你提供了学习大模型的全面指南,从入门到进阶,涵盖理论到应用。
L1阶段:启航篇|大语言模型的基础认知与核心原理
L2阶段:攻坚篇|高频场景:RAG认知与项目实践
L3阶段:跃迀篇|Agent智能体架构设计
L4阶段:精进篇|模型微调与私有化部署
L5阶段:专题篇|特训集:A2A与MCP综合应用 追踪行业热点(全新升级板块)





AI大模型全套学习资料【获取方式】
更多推荐


 17
17 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)