
用AI读懂汉字:基于卷积神经网络的手写汉字识别系统
你有没有被人调侃过:“这字写得像外星文!”又或者在课堂上,看着老师龙飞凤舞的板书,一脸懵逼,只能靠上下文硬猜?其实,这个困扰人类已久的问题,也是人工智能的一大挑战。和英文、数字相比,汉字数量庞大、结构复杂、书写风格千变万化。想让计算机“读懂”汉字,难度可不小。这一次,我们要让卷积神经网络(CNN)出场,打造一个能“辨字如神”的手写汉字识别系统。
你有没有被人调侃过:“这字写得像外星文!”又或者在课堂上,看着老师龙飞凤舞的板书,一脸懵逼,只能靠上下文硬猜?其实,这个困扰人类已久的问题,也是人工智能的一大挑战。和英文、数字相比,汉字数量庞大、结构复杂、书写风格千变万化。想让计算机“读懂”汉字,难度可不小。这一次,我们要让卷积神经网络(CNN)出场,打造一个能“辨字如神”的手写汉字识别系统。
你是否有过这样的瞬间:
翻看同学潦草的课堂笔记,感觉像在破译“外星文字”;
又或是看到祖辈写的书信,笔画飘逸,却让人难以辨认?
这正是汉字的魅力:形体复杂、变化万千、因人而异。但这种魅力也让人工智能的脚步一度止步。相比英文和数字,汉字识别更像是一道难以破解的迷题。
如今,随着深度学习的兴起,卷积神经网络(CNN) 成为攻克这道难题的关键。它就像给计算机装上了一双“慧眼”,让 AI 能够逐渐学会从一横一竖中读懂汉字。
一、教机器认汉字
想让 AI 学会“识字”,第一步就是要准备好它的“练字本”。我们先从公开的手写汉字数据集中收集大量样本,再对这些图片进行处理:把它们统一大小,转成灰度图,做归一化,让机器看起来更“顺眼”。但有些常见字样本很多,冷门字却寥寥无几,于是我们就用旋转、平移等方法制造更多样本,避免 AI 出现“偏科”。最后,把数据分成训练集、验证集和测试集,教材就齐了。
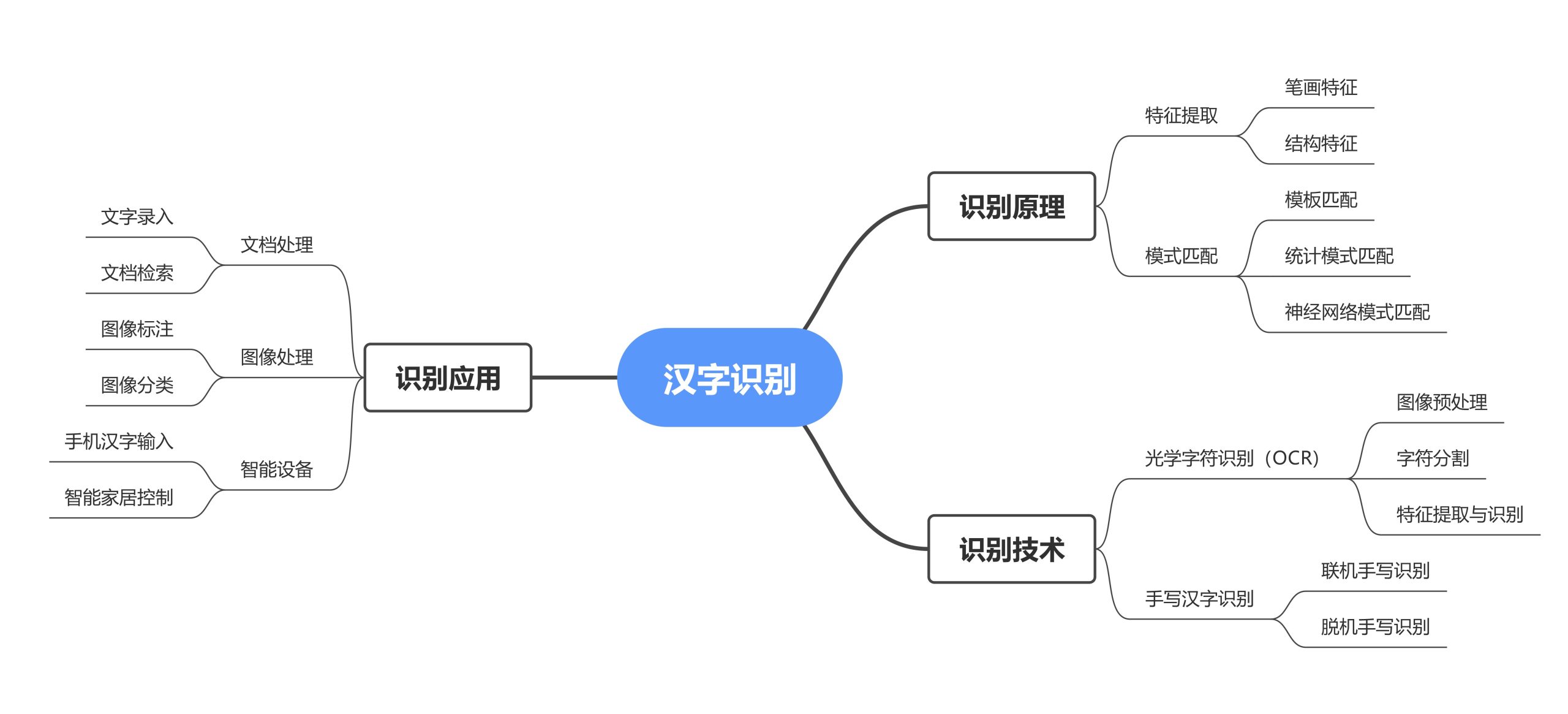
图1 汉字识别框架图
设计一副“识字眼镜”——卷积神经网络(CNN)是关键。它的卷积层能捕捉笔画细节,池化层会帮忙压缩数据,最后的全连接层则把这些特征转化成结果。我们在设计时要考虑很多细节,比如网络有多少层、卷积核有多大、池化方式如何选择。既要保证识别准确,还要让运行效率跟得上,做到“聪明又高效”。
当网络结构确定后,AI 就进入了“练习阶段”。它会在训练集中一遍遍学习,有时候会把“人”认成“大”,“口”看成“日”,但这没关系——通过调整学习率、batch size 等参数,它会慢慢改进。训练的过程就像学生做题改错,我们还会用曲线图把 AI 的学习轨迹画出来,看它是怎么从错误百出逐渐成长为“识字高手”的。
为了检验成果,我们给 AI 准备了各种笔迹:潦草的、端正的、甚至花哨的,让它逐一识别。通过计算准确率、召回率等指标,就能知道它的真实水平如何。这样的测试不仅是检验成绩,更是帮助我们发现不足,好在下一步继续优化。等到它能应对各种字迹时,我们才算真正完成了一个靠谱的汉字识别系统。
二、实施方案
第一步:准备“识字教材”
为了让 AI 开始识字,需要先准备好大量的手写汉字样本。研究中我们借助公开数据集(如 CASIA),并通过 Python 的 OpenCV 工具对图像进行处理:统一尺寸、转成灰度、再做归一化。为了避免“常见字太多、冷门字太少”的偏差,我们还采用旋转、平移等数据增强方法,让数据分布更加均衡。最后,把数据按 7:2:1 的比例划分为训练集、验证集和测试集,为后续的模型学习打下坚实基础。
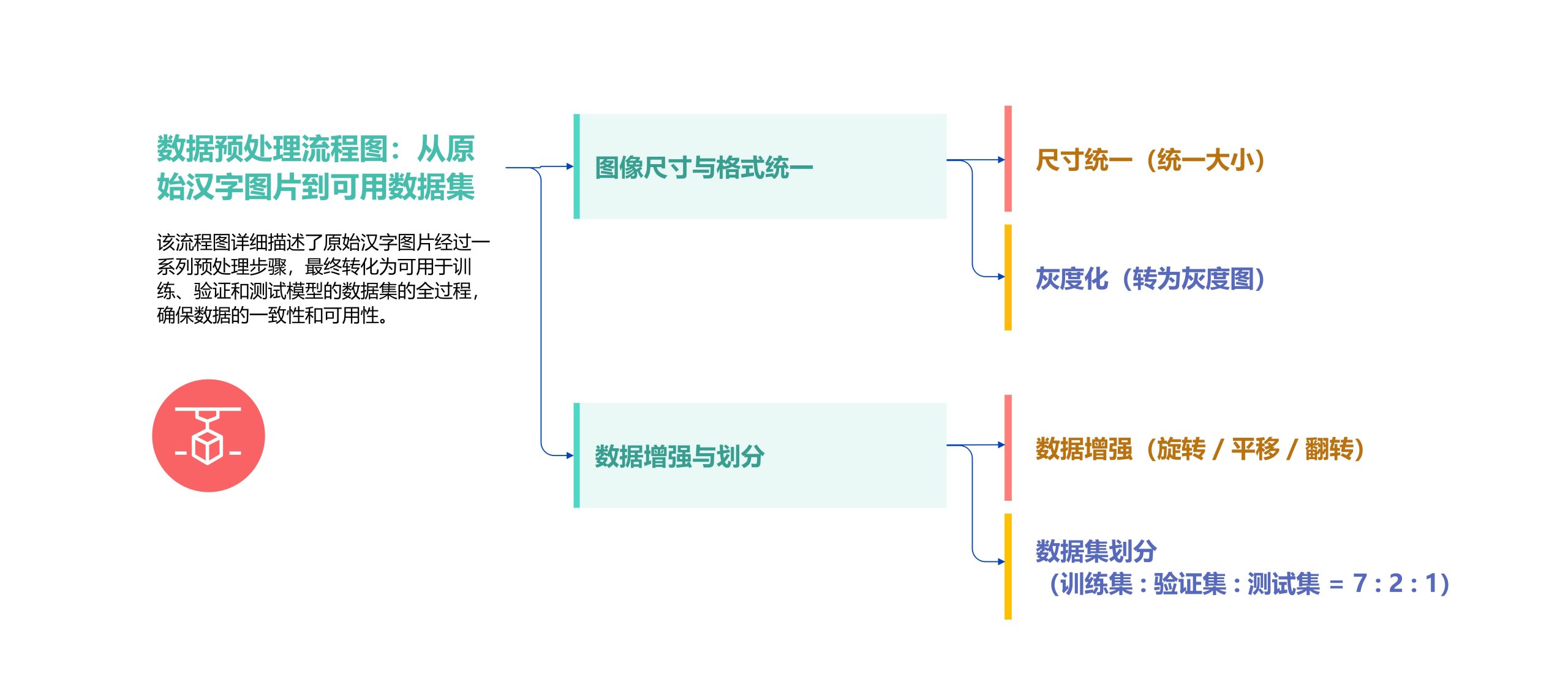
图2 数据预处理流程图
第二步:搭建“识字眼镜”
在数据准备完成后,需要为 AI 设计合适的卷积神经网络(CNN)。这个模型由多层结构组成:3–5 个卷积层用于提取笔画特征,2–3 个池化层帮助降低维度,全连接层则负责完成最终分类。整个过程就像为 AI 配备了一副可以逐步矫正、不断升级的“眼镜”,让它能越来越清晰地识别出汉字。
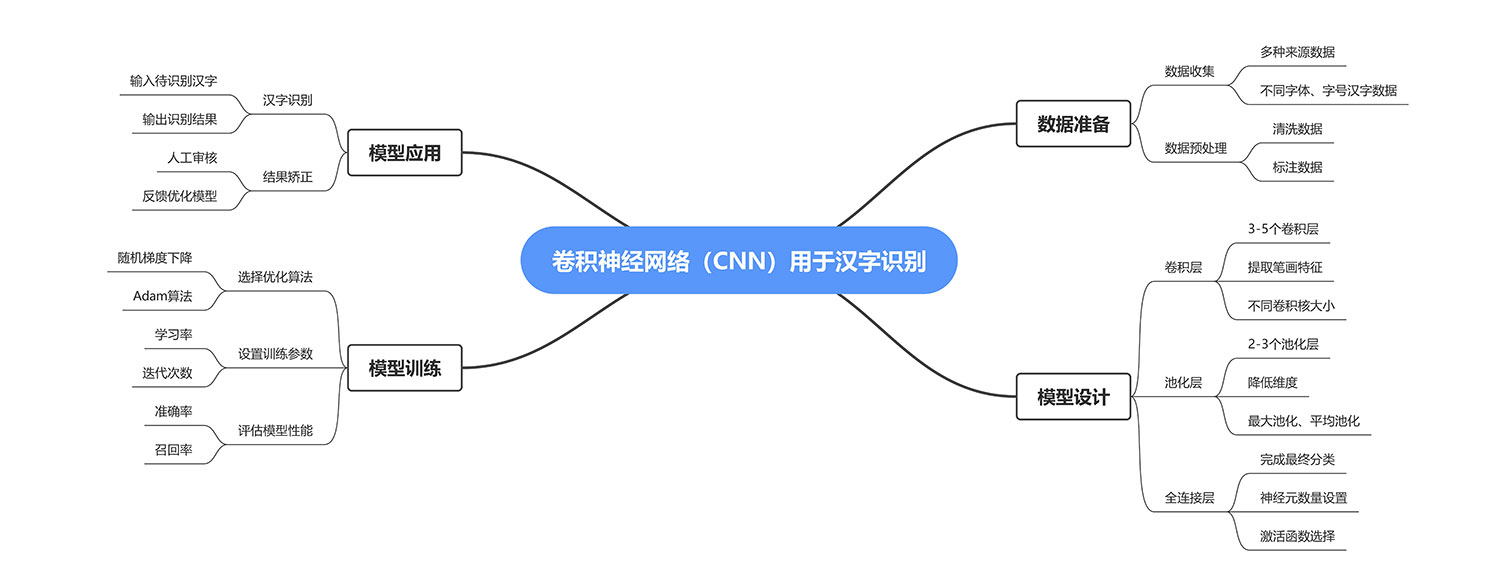
图3 CNN汉字识别流程图
第三步:进入“识字训练营”
有了模型结构,AI 便开始了正式的训练。研究中采用训练集进行多轮学习,并通过验证集监控它的学习效果。训练过程中,我们使用梯度下降法来优化损失函数,同时通过控制变量法对超参数进行微调:比如让学习率从 0.001 开始逐渐调整,或者在 batch size 设为 32、64 等不同值之间进行对比测试。与此同时,借助 Matplotlib 绘制损失值和准确率曲线,直观展现 AI 的学习轨迹,就像为它记录成长日记。
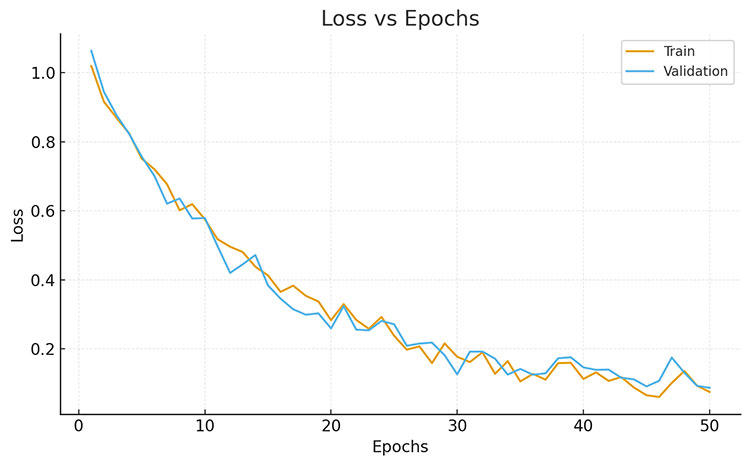
图4 Loss 学习曲线图
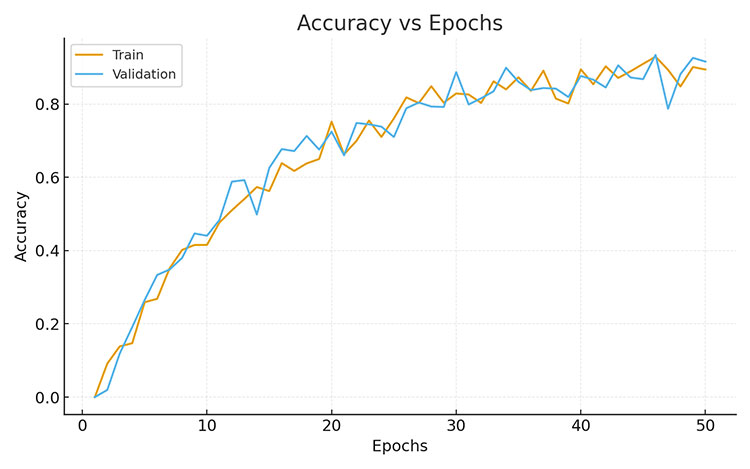
图5 Accuracy 学习曲线图
第四步:迎来“大考时刻”
当训练阶段完成,AI 需要接受一场全面的检验。我们使用测试集中的样本对它进行评估,涵盖了不同书写质量和复杂度的汉字。通过计算准确率、召回率等指标,能够清晰了解模型在实际应用场景下的表现。最终,再结合实验结果撰写报告,系统地总结研究思路、方法和成果。
三、CNN:AI的“眼睛”
卷积神经网络(CNN)之所以广受追捧,是因为它的灵感来自人类的视觉系统。想象一下,当我们看到一个汉字时,不会一眼就记住所有细节,而是先认出一笔一划,再理解字的结构,最后才能喊出它的名字。CNN 的思路正是如此:把复杂的汉字拆解成小部分,再逐层组合,直到完整识别。
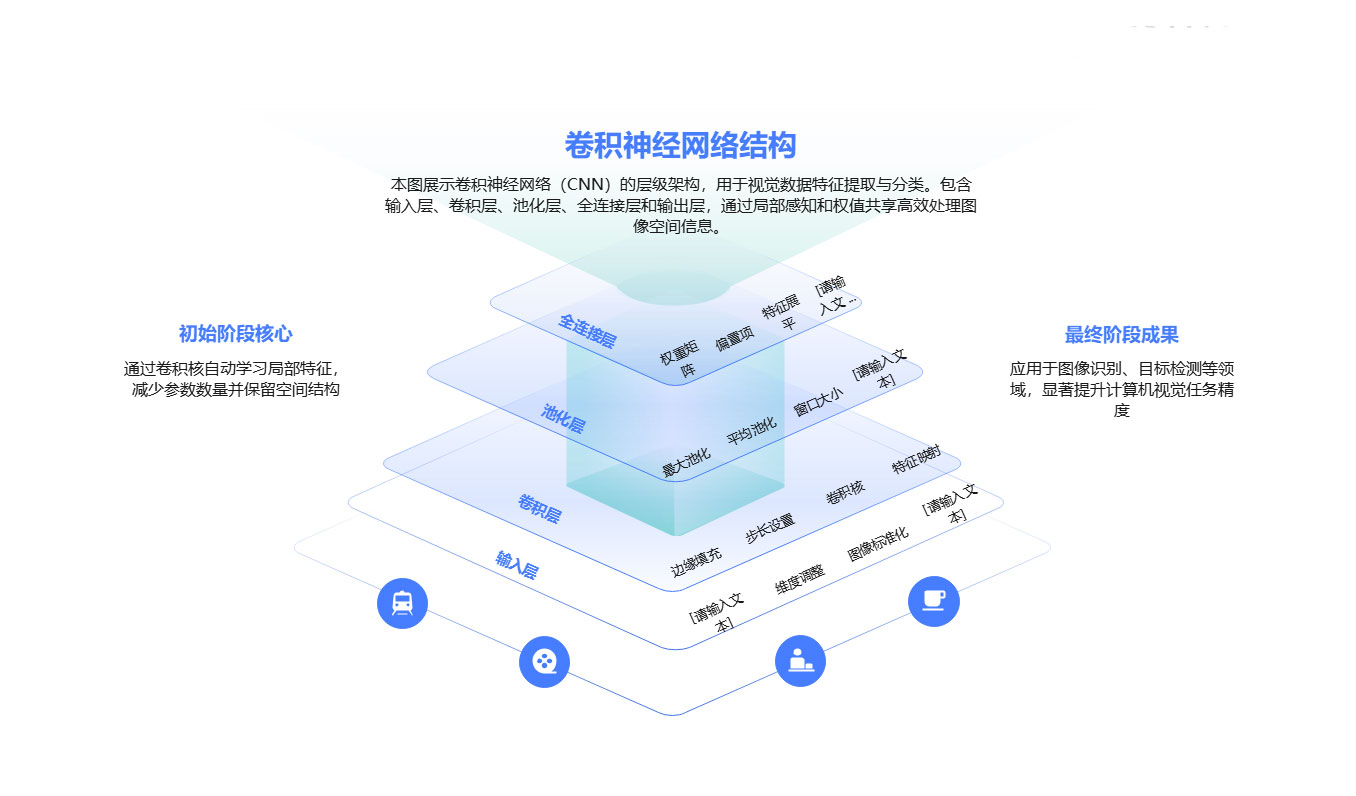
图5 CNN结构示意图
在 CNN 的第一层——卷积层,模型像一支放大镜,紧紧盯住笔画细节。横、竖、撇、捺,就像拼图的碎片,被这一层逐一扫描,形成最初的特征图。此时的 AI,就像刚入学的小孩,正在学习“这是一横,那是一竖”。
池化层接过接力棒,负责做“笔记整理”。它在不丢失重点的前提下,删去冗余信息,降低计算负担。就像学生上课记笔记,不会把每个字都抄下来,而是挑重点,抓核心。这样一来,AI 能更专注于字的关键特征。
随着多层卷积与池化的交替,AI 的“识字知识库”越来越丰富。全连接层这时站上舞台,把前面提取到的碎片化信息重新拼接组合,最终映射成一个具体的汉字类别。就像孩子看到“一横一竖”,终于脱口而出:“这就是‘十’!”
这套流程,其实就是一段 AI 的识字成长之旅:从笔画入手,到理解结构,再到完整识别。CNN 赋予计算机分层理解的能力,让它一步步从“看不懂”走向“会读字”。正因如此,汉字识别不再是遥不可及的梦想,而是可以落地的现实。
四、从“认错字”到“字迹达人”
在训练的最初阶段,AI 就像一个刚入学的小孩,经常闹出笑话。它会把“人”误认为“大”,把“口”看成“日”,甚至在一些笔画复杂的字面前完全“认不出来”。这些错误看似低级,却恰好说明了它还处在摸索阶段,需要大量的练习和反馈。
为了帮助它进步,我们引入了 损失函数。损失函数就像一位严格的老师,时刻提醒 AI 哪里做错了。与此同时,优化器则像一位耐心的辅导员,根据错误的方向不断调整参数,带领 AI 一步步修正认知,让它逐渐学会分辨细微的差异。
随着训练的深入,参数不断被调优,AI 的识字能力也在稳步提升。它开始能区分“人”和“大”的差别,能看出“口”和“日”并不一样。每一次迭代训练,都让它的识别精度更高,也让它在面对新汉字时更加从容。
整个过程被一条条 学习曲线完整记录下来。曲线从最初的跌宕起伏,到逐渐趋于平稳,就像孩子成长的日记:从跌跌撞撞到自信稳健。最终,这些曲线不仅见证了 AI 的进步,也为研究者提供了直观的参考,帮助他们判断训练是否真正走在正确的道路上。
五、期末考试:检验成果
当训练阶段告一段落,AI 就要迎来它的“期末考试”。在这场考试中,我们准备了各种风格的手写汉字:有的笔迹潦草匆忙,有的端正规整,还有的带着个人的独特风格甚至夸张变化。AI 必须逐一识别,就像学生面对一份涵盖各种题型的大考卷,既要识基础题,也要啃难题。
考试的结果会用 准确率 和 召回率 这些指标来衡量,就像成绩单一样,把它的学习成果量化展现。高分意味着它已经具备较强的识字能力,而不足之处则提醒研究者需要继续优化。通过这场“大考”,我们能清楚地看到 AI 是否真正学会了在各种场景下识别汉字,也为未来的改进提供了方向。
六、超越代码:AI 与汉字的对话
这项研究的意义,远远不止是训练出一个能够识别手写汉字的系统。它背后折射出的,是人工智能与人类文明之间的一次深度交融。AI 不再只是运行在冰冷服务器上的代码,而是借助学习汉字的过程,逐渐触摸到中华文化的脉络。
汉字是一种独特的书写体系。它既承载了语言的功能,又承载了历史、艺术与文化的印记。从甲骨文的刀刻,到篆隶楷行的演变,再到今天的简化字,汉字在数千年的发展中不断变化,却始终是中华文明的符号。而当深度学习介入时,这种古老的文字体系与现代科技产生了奇妙的呼应。
CNN 的加入,让计算机不再只是“看图说话”,而是学会了逐笔逐划地理解汉字。这种过程,就像是一场跨越时空的“对话”:人类用笔墨留下印记,机器用算法解读这些符号。技术因此成为桥梁,把古老的文化遗产与未来的智能世界连接在一起。
这不仅是一种科技突破,更是一种文化守护。通过 AI,我们能够更好地保存、理解和传承文字遗产;而通过汉字,AI 也获得了更具深度的人文意义。技术与文化并不是对立的两个极端,而是可以在一次次的尝试中交织互补,推动人类走向一个更丰富、更智慧的未来。
七、结语
手写汉字识别的研究,看似是一道技术难题,实则背后承载着深厚的文化意蕴。它不仅仅是算法精度和模型参数的较量,更是一次让人工智能触碰文字灵魂的尝试。每一个被识别的笔画,都是科技与文化的交汇点。
想象一下,在不远的将来,无论是潦草的课堂笔记,模糊的会议手稿,还是爷爷奶奶留下的书信与日记,AI 都能帮我们完整地解读。这不仅意味着效率的提升,更意味着人与文字之间的隔阂被进一步消弭,让交流与传承变得更容易。
因此,让机器学会读懂汉字,不只是科研成果的展示,更是一种文化守护。它提醒我们:科技的最终意义,不在于冰冷的计算,而在于如何温柔地守护人类文明的印记。汉字识别,或许正是数字时代献给中华文字的一份深情礼物。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)