
轻松搞定网页抓取?传统爬虫 vs 亮数据 Web MCP
本文对比了传统爬虫与亮数据Web MCP在网页抓取中的技术差异。作者指出传统方案存在DOM依赖、反爬处理复杂等问题,而亮数据MCP通过机器学习内容提取、自动反爬处理等优势显著提升效率。通过知乎Seedream文章抓取案例,展示了两种方案在代码实现、数据质量上的差异:传统方案需要处理加密参数、动态加载等问题,而MCP配置简单且输出结构化数据。最后建议根据项目需求选择:传统方案适合深度交互场景,MCP
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
2. 我的免费工具站: 欢迎访问 https://tools-6wi.pages.dev/😁 3. 毕业设计专栏,毕业季咱们不慌忙,几百款毕业设计等你选。
❤️ 4. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当 。python爬虫入门进阶
❤️ 5. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 6. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
作为一个在爬虫领域摸爬滚打10年的老码农,今天想跟大家聊聊网页数据抓取的技术选型问题。最近在做一个LLM项目的数据抓取,对比了传统Playwright方案和亮数据Web MCP,有些技术心得分享给大家。
**完整的操作视频见:
轻松搞定网页抓取?传统爬虫 vs 亮数据 Web MCP
传统爬虫的技术痛点分析
1. 技术架构层面的问题
DOM依赖性强
传统爬虫基于DOM元素定位,一旦网站改版,XPath/CSS选择器就失效。上周我刚写好的知乎爬虫,第二天他们就改了class命名规则,直接全军覆没。
反爬机制复杂
现代网站的反爬策略越来越复杂:
- IP频率限制(需要代理池)
- 行为验证(需要模拟真人操作)
- 动态参数加密(需要逆向工程)
- Canvas指纹检测(需要浏览器伪装)
亮数据Web MCP技术原理分析
1. 核心技术优势
智能内容提取
基于机器学习的内容识别算法,不依赖固定DOM结构。
反爬自动处理
内置了完整的反爬解决方案:
- 自动IP轮换(全球代理网络)
- 行为模拟(鼠标轨迹、滚动节奏)
- 验证码识别(OCR+机器学习)
- 浏览器指纹伪装
实战案例:知乎Seedream文章抓取

获取MCP配置
注册之后点击获取MCP的配置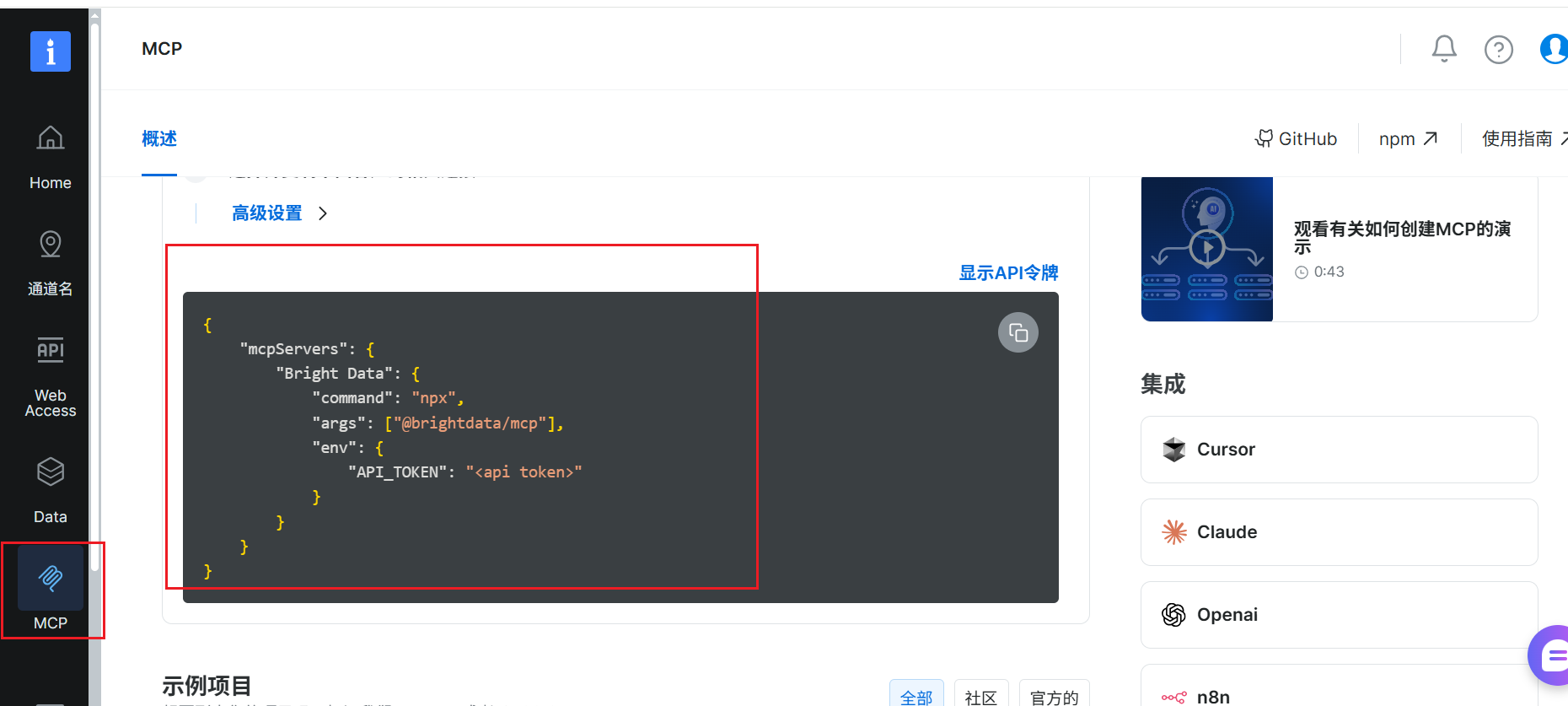
技术实现细节
需求分析:
需要抓取知乎上所有关于"seedream"的文章,包括标题、作者、内容、发布时间等字段。
传统方案踩坑记录:
- 知乎的接口有加密参数,需要逆向分析JS代码
- 内容动态加载,需要处理分页和懒加载
- 反爬严格,需要控制请求频率和随机等待
- 登录状态管理,需要处理Cookie失效问题
亮数据MCP配置:
{
"mcpServers": {
"brightdata-mcp": {
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": "your_api_token_here"
}
}
}
}
代码实现对比:
传统方案(部分代码):
import asyncio
from playwright.async_api import async_playwright
async def scrape_zhihu():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# 设置反爬
await page.set_user_agent(
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
)
# 处理登录状态
await page.context.add_cookies(cookies)
articles = []
for page_num in range(1, 10):
try:
await page.goto(f'https://www.zhihu.com/search?type=content&q=Seedream&page={page_num}')
await page.wait_for_selector('.ContentItem')
# 提取文章信息
items = await page.query_selector_all('.ContentItem')
for item in items:
title = await item.query_selector('.ContentItem-title')
content = await item.query_selector('.RichContent')
if title and content:
articles.append({
'title': await title.text_content(),
'content': await content.text_content()
})
# 随机等待,避免被封
await asyncio.sleep(random.uniform(2, 5))
except Exception as e:
print(f'第{page_num}页抓取失败: {e}')
continue
await browser.close()
return articles
亮数据方案,配置好MCP JSON之后就可以直接在Cursor中使用了。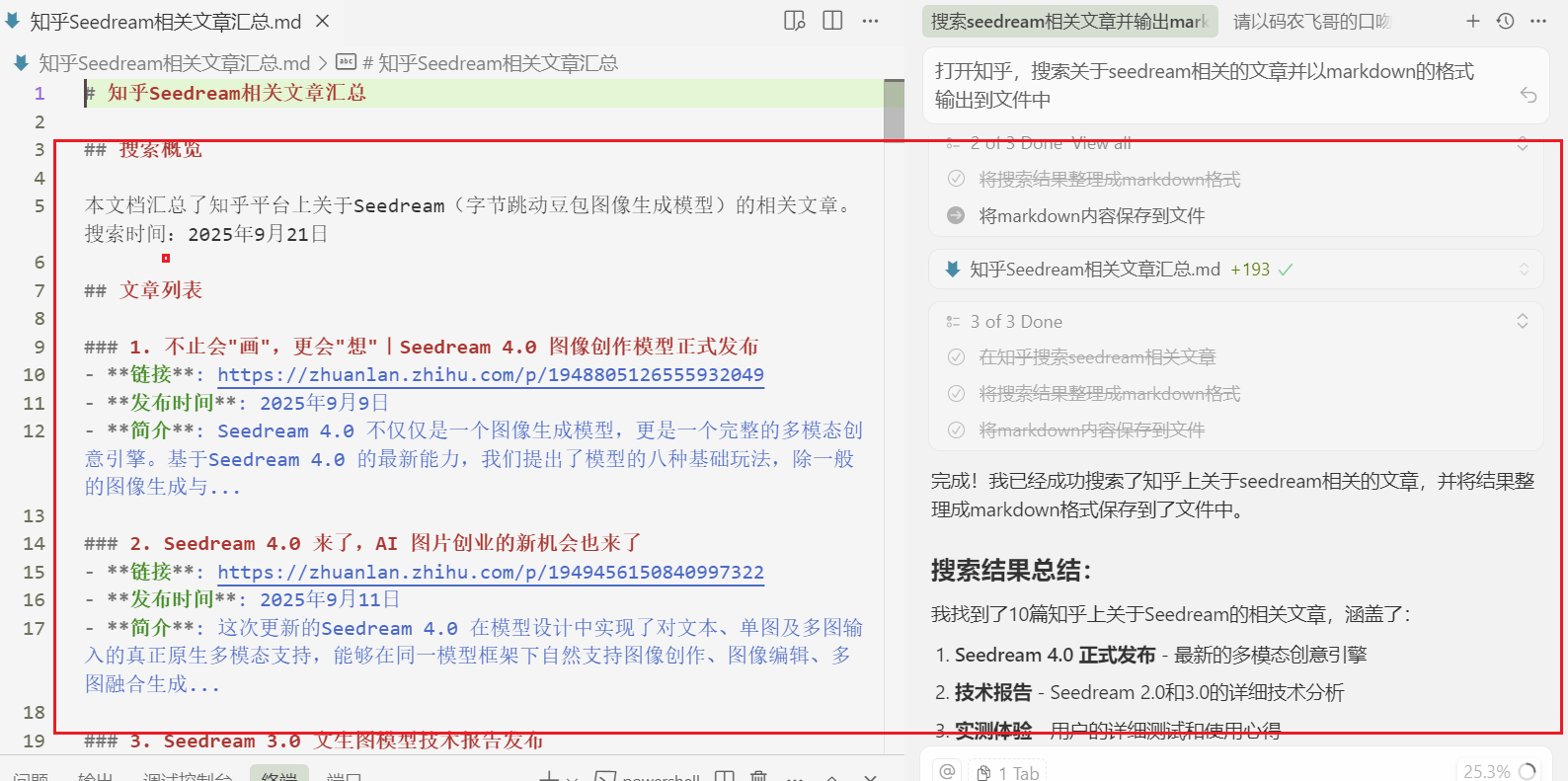
数据质量对比
传统方案提取的数据:
- HTML标签混杂,需要二次清洗
- 动态加载内容经常缺失
- 格式不统一,后续处理复杂
亮数据提取的数据:
- 纯Markdown格式,无需清洗
- 内容完整性高
- 结构化程度高,便于分析
技术选型建议
适用场景分析
选择传统爬虫的情况:
- 需要深度交互(登录、表单提交)
- 对抓取成本敏感(免费方案)
- 有专业的反爬团队
- 数据量较小,维护成本可控
选择亮数据MCP的情况:
- 快速原型验证
- 生产环境稳定性要求高
- 团队缺乏反爬经验
- 数据量大,需要高并发
成本分析
传统爬虫隐性成本:
- 开发时间:高级工程师×天
- 维护成本:持续投入
- 代理IP费用:¥500-2000/月
- 服务器资源:¥200-500/月
亮数据MCP成本:
- 免费额度:5000次/月
- 无额外维护成本
了解更多
- CSDN企业号:https://brightdata.blog.csdn.net/
- OSChina专区:https://www.oschina.net/group/brightdata
- Github中文区:https://github.com/bright-cn
- 知乎账号:https://www.zhihu.com/org/bright-data
更多推荐

 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)