
【值得收藏】一文读懂大模型核心:GPT与Transformer工作原理
本文通过简单类比和分步解析,介绍了GPT和Transformer的工作原理。从经典概率模型入手,解释了大模型如何预测下一个词/字,逐步细化到Transformer架构的输入处理、编解码过程和输出机制。重点讲解了Token词表、Embedding向量和Self-Attention算法等核心组件,展示了矩阵计算和多层处理如何使模型理解上下文并预测最可能的下一个词。
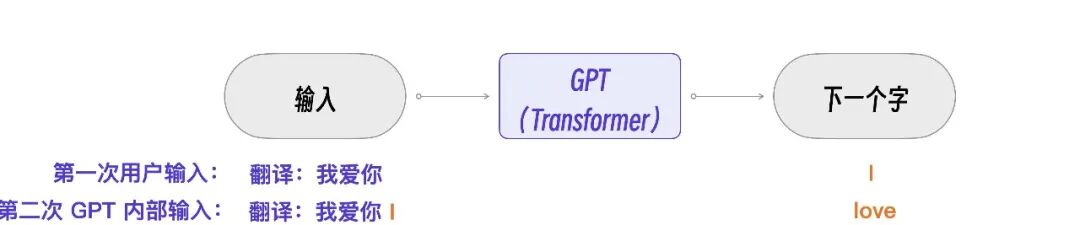
一个 GPT 会话例子
先看例 1,用明确的指令“翻译”让 GPT 做一个翻译。

GPT的实现原理可以用一句话表述:通过输入一段文本,模型会预测出最可能成为下一个字的字。在例 1 中,因为字符串是以“翻译:”开头的,所以,虽然没有指明翻译成什么语言,GPT 模型也就能据此推测出“我们想翻译成英文”并给出结果。后续我们再输入中文,它也能准确地预测这是一个翻译任务。
把这个过程画成流程图,会更加清晰。
串联概念:经典概率模型
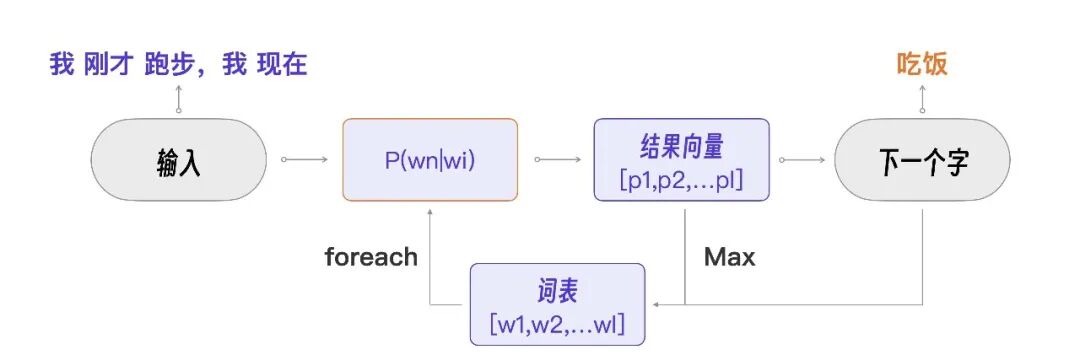
这个经典概率模型比 Transformer 简单 10 倍,非常易于理解。
假设我们要做一个汪星人的大模型,汪星人只有睡觉、跑步、吃饭三个行为,汪星语也只有下面这一种句式。
我 刚才 跑步,我 现在 吃饭
我们的目标和 GPT 是一样的,都是用已有的文本预测下一个字,比如下面的例子。
我 刚才 跑步,我 现在 ___
要预测上面例子的横线里应该填什么,只要计算“跑步”这个行为之后哪个行为的概率最大就可以了。比如:P(吃饭|跑步) 表示汪星人在“跑步”之后,下一个行为是“吃饭”的概率。
从程序视角实现这个“大模型”,显然需要先建立一个词表(Vocabulary),存储所有的汪星词汇。看下面这张图,一共有六个词,我、刚才、现在、吃饭、睡觉、跑步。那这个词表的长度 L 就等于 6。

然后,根据汪星语料,计算每一个词的概率 P(wn|wi),这也就是汪星大模型的模型训练过程。在模型运行时,可以根据输入的文本, 遍历词表获取每个词的概率,输出一个结果向量(长度也为 L)。
[0, 0, 0, 0.6, 0.3, 0.1]
比如上面的向量里 4 号词概率最高,是 0.6,所以下一个字要输出“吃饭”。
接下来的 Transformer 程序流程虽然比这个复杂,但是和外围辅助概念输入、输出、词表相比,结构和功能是一样的,只是概率计算方法不同。所以,我们完全可以在这个流程图的基础上进一步细化理解 Transformer 程序流程。
摸清流程:Transformer 架构及流程图
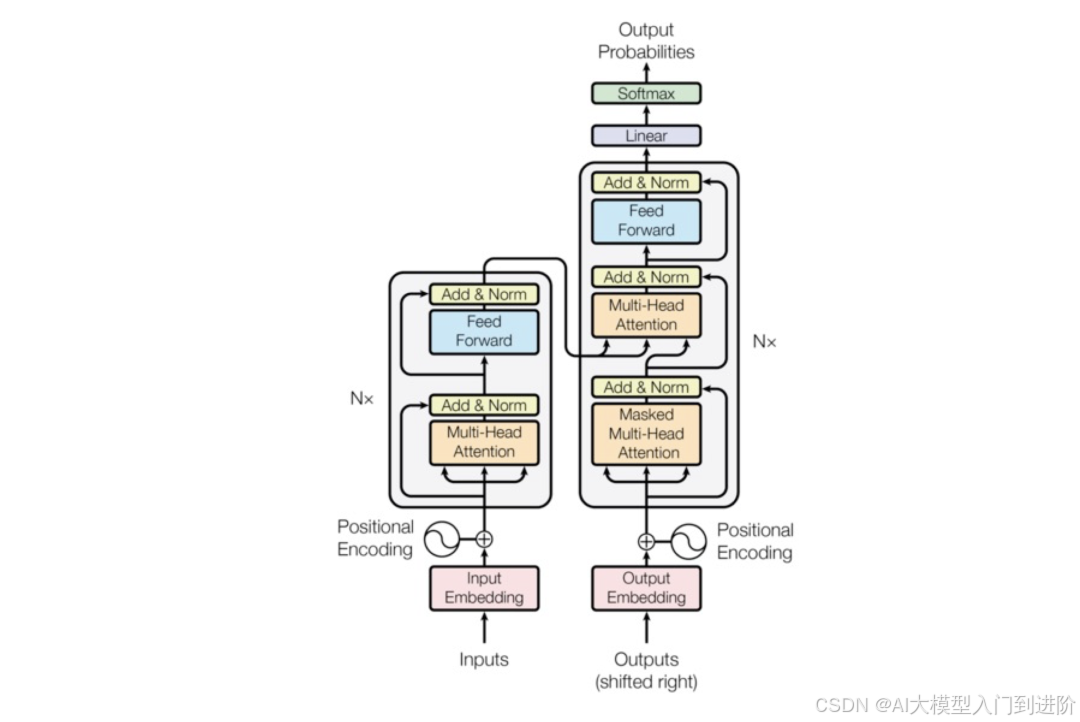
对普通工程师来说,我们可以用“分治法”把 Transformer 架构先用红框分为 3 大部分,输入、编解码、输出,更容易一步步理解它。
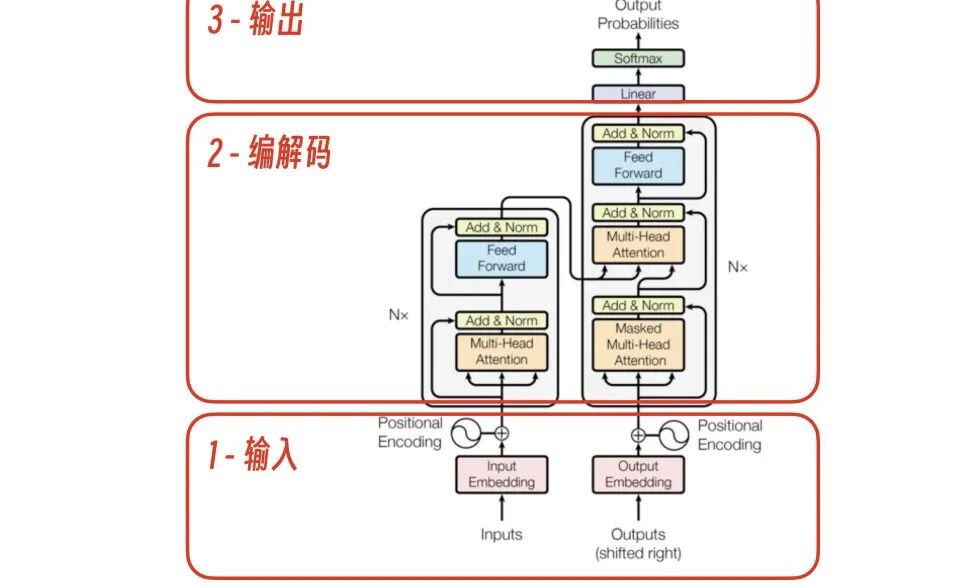
Transformer 是怎么做到通过输入一段文本,GPT 模型就能预测出最可能成为下一个字的字的呢?这个问题,我想下面的图已经表示得非常清楚了。
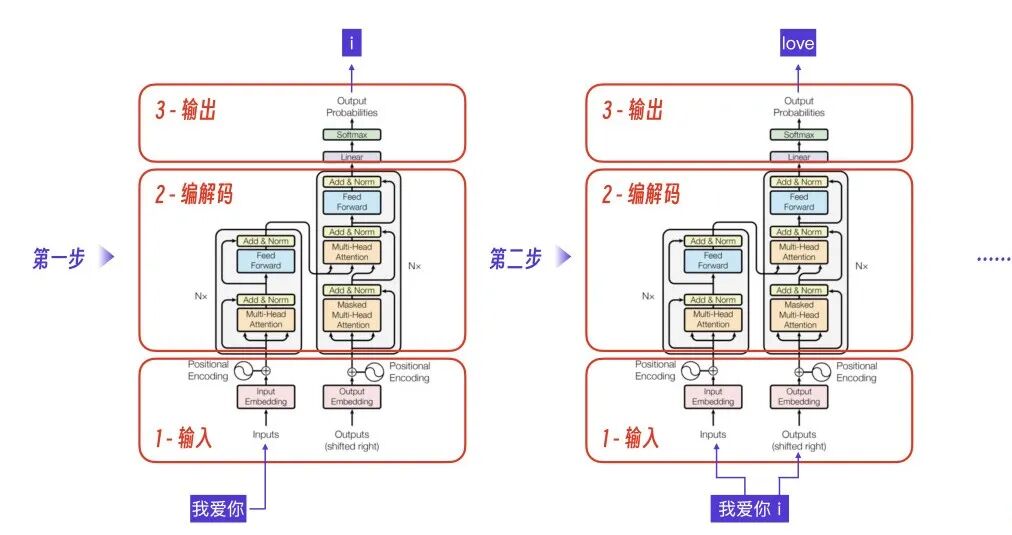
步骤1:处理初始输入
- 输入模块:当 Transformer 接收到初始输入“我爱你”时,它首先通过其输入层进行数据转换,将文本转化为内部可处理的格式。
- 编解码模块:随后,经过转换的数据进入编解码层。这是 Transformer 的核心,它会基于输入进行预测,并输出概率最高的下一个字符,这里假设是 “i”。
步骤2:处理新输入,输出下一个词
- 输入模块:此时,新的输入变成了“我爱你”和上一步输出的 “i” 的组合。
- 编解码模块:Transformer 再次对这个更新后的序列进行预测,这次它预测下一个词是 “love”
程序视角的逻辑:矩阵计算
Transformer 架构里的所有算法,其实都是矩阵和向量计算。
先看一个 N x M 的矩阵数据结构例子。可以理解为程序中的 n 行 m 列的数组。

其中,当 N = 1 时,就叫做 M 维向量。

简单起见,我们可以把每一个方框里的算法统一描述为下图。
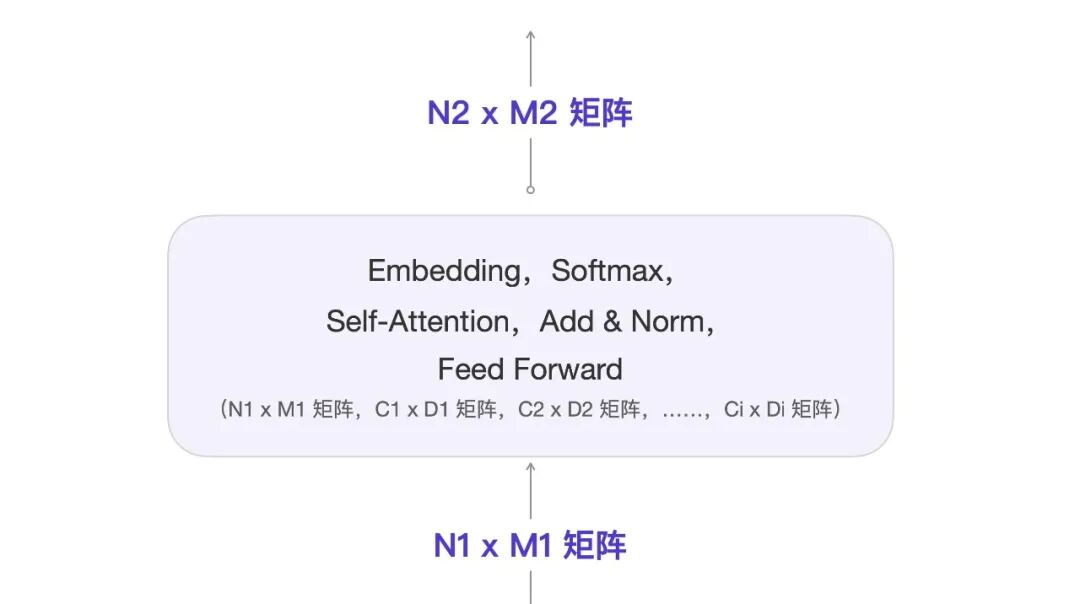
Transformer 矩阵运算核心逻辑
在 Transformer 架构中,数据流动的核心是矩阵运算。每一个算法方框都接收一个 动态矩阵N1×M1 作为输入。这个动态矩阵代表了用户的输入或算法的中间结果。
核心计算过程
每个算法会用输入的动态矩阵,与一系列 预先训练好的参数矩阵(Ci×Di)进行计算。这些参数矩阵就是模型的“记忆”,是 Transformer 经过大量数据训练后形成的固定数值。
多层重复计算
编解码层中的 “Nx” 代表算法重复的次数。这意味着,同样的计算流程会执行 Nx 次。但需要注意的是,每一层的参数矩阵都是独一无二的,因此每一层都拥有自己独立的一套参数矩阵。
“我爱你”的生成过程
以您的例子为例,“我爱你”这个字符串在进入 Transformer 后,会经历一个多层计算的过程。它会依次与每一层预训练好的参数矩阵进行复杂的运算,最终输出一个概率向量。这个向量中概率最大的字符,就是模型预测的下一个字——“i”。
总而言之,Transformer 的核心在于其多层矩阵运算,其中动态的输入数据(Ni×Mi)与预训练好的固定参数矩阵(Ci×Di)相互作用,最终完成对下一个词的预测。
Transformer 核心算法和结构
我们集中注意力,依次细化最核心的三个算法和结构:Token 词表,Embedding 向量,Self-Attention 算法,并且在经典模型的程序流程图上进行细化。
Token 和 Token 词表
在自然语言处理中,Token 是一个非常基础的概念,可以理解为最小的语言单元。它可以是一个词、一个字符,甚至是一个词的一部分。例如,句子 “I love you.” 可以被切分为三个 Token:“I”、“love”、“you”。
但在中文里,因为没有天然的空格分隔,Token 的划分就更复杂了。例如,“我爱你”通常会被切分为三个字:“我”、“爱”、“你”。
输入模块的核心:Embedding向量
Embedding 向量具体形式如下。
#i --> [0.1095,0.0336,...,0.1263,0.2155,....,0.1589,0.0282,0.1756]
对应的,它的 Token 词表在逻辑上可以细化为下图。
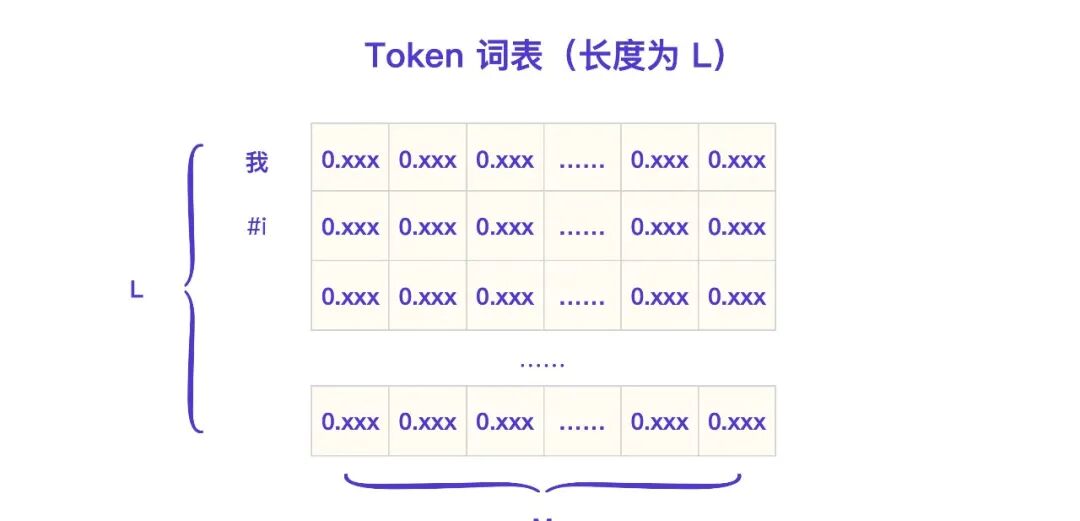
Transformer 架构输入部分第一个流程就是 Embedding,以这个例子里的输入 Token [我, 爱, 你, #i ]为例,你可以把这个过程理解为:Token 挨个去词表抽取相应的 Embedding,这个过程我用图片表示出来了。
你看,假设词表总长度是 L,比如“我”这个 Token 的 Embedding 就可以直接从词表里取出来,这个例子输入的总 Token 数量 N = 4,Embedding 向量的维度是 M,此时抽取的矩阵是一个 4 x M 的矩阵。
在 GPT-3 里,Embedding 的维度 M = 12288,这个例子里 N = 4,所以最终输入模块得到的矩阵就是下面这样的。

这个矩阵会被传递给编解码模块用作起始输入。一个 Embedding 维度代表一个 Token 的语义属性,维度越高,训练成本就越高,GPT-3 的经验是 M = 12288 维,就足够涌现出类似人类的智能。
好了,到此为止,我们已经把输入模块做了足够细化,下面是第一次细化后对应的程序流程图。
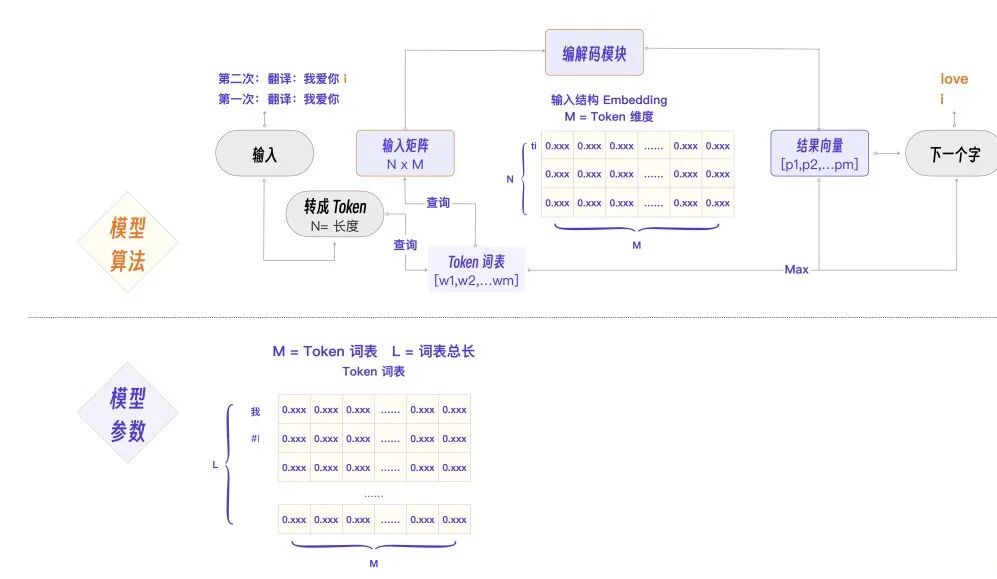
编解码模块核心:Self-Attention 算法
大模型做预测的时候,会关心或者叫注意当前自己这个句子里的那些重要的词,这个思想正是 自注意 Self-Attention 这个算法的命名来源。
自注意力机制(Self-Attention)是编解码模块的第一步,也是最重要的一步,目的是计算输入的每个 Token 在当前句子里的重要性,以便后续算法做预测时更关注那些重要的 Token。
我们分别从参数和算法两个角度来说明这个算法流程。
1.参数视角
模型需要训练并得到 3 个权重矩阵,分别叫 Wq、Wk、Wv。
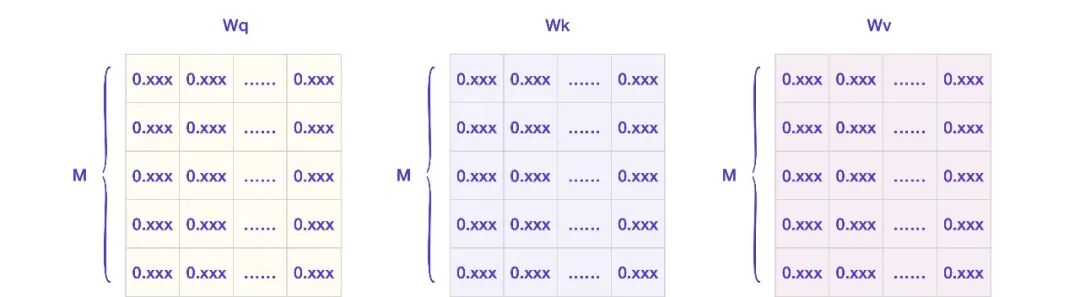
现在输入的 Token 列表是 [t1, t2, t3 … tn],假设当前需要计算第 i 个 Token 的重要性,记为 ti,那么 Wq、Wk、Wv 分别是什么意思呢?
Wq 是为了生成查询向量,也就是 ti 拿来去向别人查询的向量。
Wk 是为了生成键向量,也就是 ti 用来回应它人查询的向量。
Wv 是为了生成值向量,也就是表示 ti 的重要性值的向量。
2.算法视角
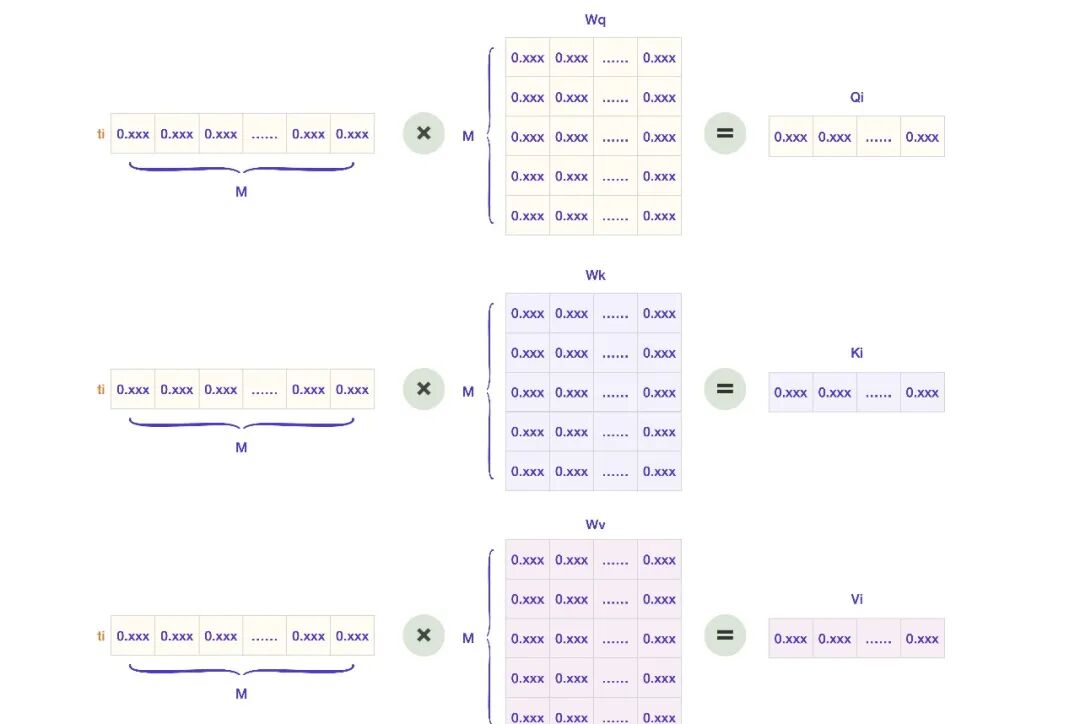
首先,我们写下 ti 的 Embedding 向量。

我来拆解一下整个过程。
第一步,生成每个 Token 对应的 Q(查询向量),K(键向量),V(值向量)。针对 ti 的算法图就是下面这样的。
第二步,Token ti 拿着自己的 Q 向量去询问每个 Token,并得到自己的重要性分数 Score。
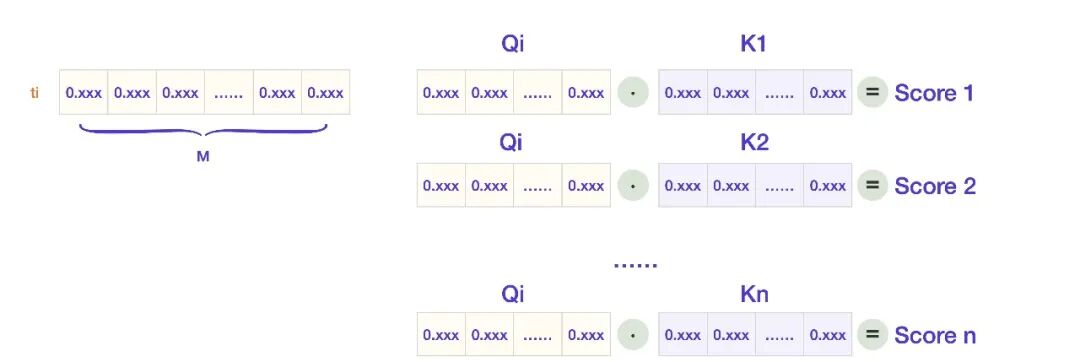
再反过来,当其他 Token 向 ti 查询的时候,ti 会用自己的 K 向量参与回应计算。
第三步,[score1, score2,… score-n] 这些分数再和 ti 的值向量 V 计算,就得到了模型内部表示重要性的向量 Z。
自注意力机制(Self-Attention)是 GPT 拥有高智能在算法层面的核心因素,我们对编解码模块的注意也就到这个算法为止。不用有太多负担,理解即可。接下来可以把完整的程序流程图绘制出来了。
最终的 Transformer 程序流程图
现在可以进行第二次程序流程图细化,得到最终的 Transformer 程序流程图。你也可以在这张图的基础上回看前面的内容,进一步理解细节。
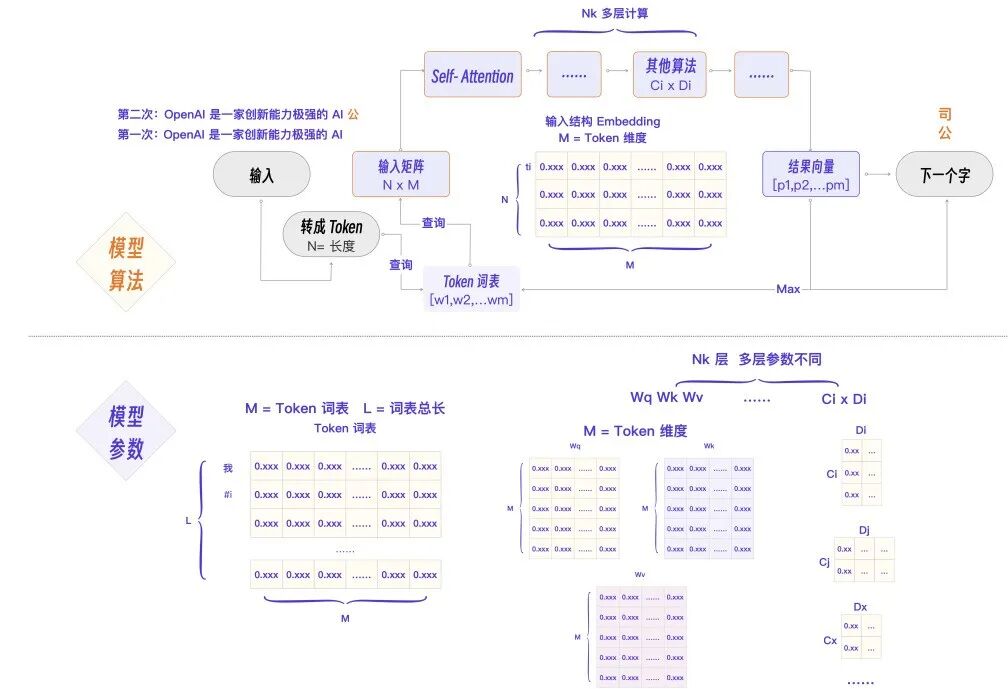
里有几个流程要点,我再来强调一下。
N 为输入 Token 总数,M 为 Embedding 维度,L 为词表总数。
关键流程是这样的:词的 Token 化 -> Embedding 查询 -> 组成 NxM 输入矩阵 -> Self-Attention 计算 Q,K,V -> Nk 层计算 -> 得到结果向量。
涉及的几个关键参数分别是 Token 词表,每个 Token 的 Embedding 向量,Wq、Wk、Wv 权重矩阵,以及其他算法层 Ci x Di 参数矩阵。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
更多推荐
 15
15 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)