
LLM推理提速新策略:Attention与FFN分离方案深度解析,提升模型效率与性能!
AF分离增加了硬件部署方案的想象空间,使得有代差的硬件能够混合使用(例如H20与A800),也让不同品牌的硬件可以混合构建解决方案(如GPU与NPU卡),同时还能结合训推混池、弹性伸缩、跨集群部署等场景应用。目前主流的框架如vLLM、SGLang上都开始实现相关方案,各大模型厂商正在尝试推动方案落地。本文就现有技术和方案做一个简要分析。
推理部署形态从单卡、分布式、PD分离、大EP再到Attention与FFN分离,发展非常之快。技术的演进围绕着模型结构的需求和硬件性能的提升而展开,其中Attention(A)与FFN(F)分离最近热度上升,相关的探索如Step3的AFD、xDS的DMA、MegaScale-Infer的DEP等,致力于挖掘现有AI硬件的推理性能。
AF分离增加了硬件部署方案的想象空间,使得有代差的硬件能够混合使用(例如H20与A800),也让不同品牌的硬件可以混合构建解决方案(如GPU与NPU卡),同时还能结合训推混池、弹性伸缩、跨集群部署等场景应用。目前主流的框架如vLLM、SGLang上都开始实现相关方案,各大模型厂商正在尝试推动方案落地。本文就现有技术和方案做一个简要分析。
一、为什么要用AF分离?
Attention与FFN是目前主流Transformer架构中的关键模块,大模型的每一层都包含这两个子模块。在推理过程中,将Attention与FFN子模块分别部署到不同设备上,通过调整不同的A与F配比可实现较高推理性能。
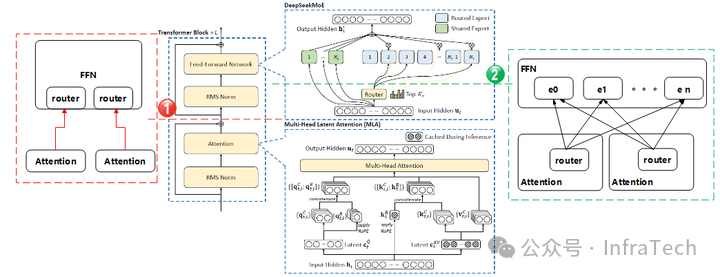
AF分离在不同研究中的称呼不尽相同,例如AFD(Attention-FFN Disaggregation)、DMA(Disaggregated MoE and Attention)、DEP(Disaggregated Expert Parallelism)等,但其核心思想均围绕Attention与FFN(或MoE)的分离展开。为便于描述,下文中统一使用AFD指代这一技术。
AFD产生的主要背景在于:Attention与FFN在存储和计算特性上与硬件之间存在匹配需求,这种差异在Decode阶段尤为明显。
1.1 AF计算的特点
在主流Decoder-only模型(如DeepSeek、Qwen、Kimi、Llama等)中,Attention与FFN对算力及访存的需求存在显著差异。在Decode阶段,Attention通常是访存瓶颈(memory access bound),而FFN则更多表现为计算瓶颈(compute bound)。
当增大batch size时,Attention的算力需求基本保持不变,因其已达到数据加载的上限;而FFN则能够随batch size增加获得一定的性能提升,这一特点在MoE架构中尤为明显。参考MegaScale-Infer数据,如下图所示,图中标注的“max”表示batch size增大至显存容量上限。
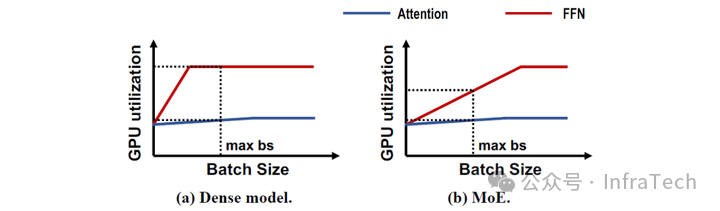
两种模型GPU利用率与batch size的关系
从数据初步可知,应当使用带宽较大的硬件处理Attention,而用计算能力更强的硬件处理MoE,或者说当算力用不满时,需要增大MoE的batch size。这也解释了在decode阶段采用大EP(Expert Parallelism)的目的——即为了增大batch size。
FFN(MoE/Dense)的最佳batch size满足这个等式:
B≥α×γ×Flops/Bandwith
其中,Flops/Bandwidth 表示计算与访存之比,α 与权重数据的存储方式相关(例如在8-bit量化下为0.5),γ 与激活的专家数量相关(在Dense模型中为1)。在其他场景中,例如专家总数为256、激活专家数为9(包括共享与独立专家)时,γ = 256/9。
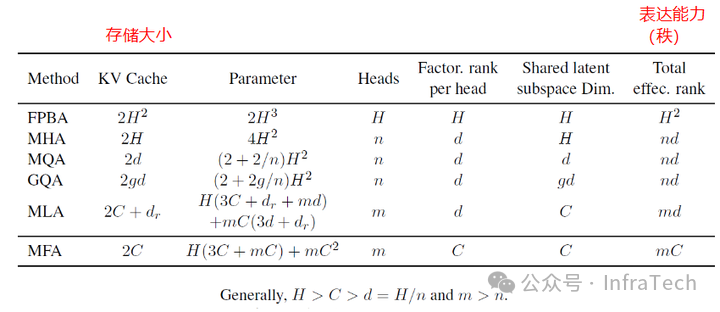
除了Attention与FFN之间存在差异之外,不同形态的Attention模块在表达能力以及存储和计算需求方面也各不相同。常见的Attention形态包括MHA、MLA和GQA,可以通过公式分析它们之间的区别。这些Attention模块可视为FPBA(Fully Parameterized Bilinear Attention)的变体,通过分解权重矩阵 Wc和 Uc来降低参数量、计算复杂度以及表达能力。
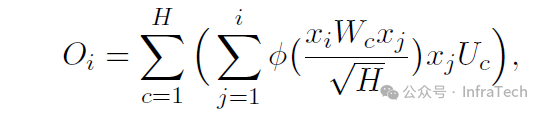
FPBA
MHA/GQA将W、U矩阵拆解为Q、K、V、O矩阵,而MLA在MHA基础上进一步拆解Q、K、V得到S矩阵,这种降秩方式减少了KV Cache的大小。
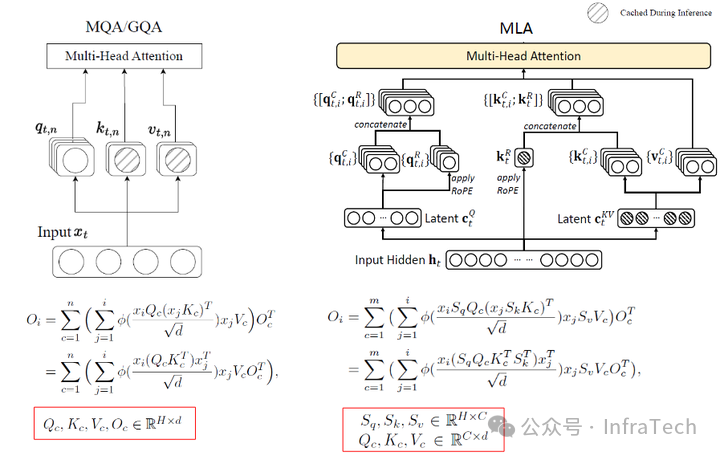
Step3中采用的MFA(Multi-matrix Factorization Attention)是对MLA/MHA的改进,旨在实现高表达能力(高秩)与低参数量(小存储空间)的平衡。
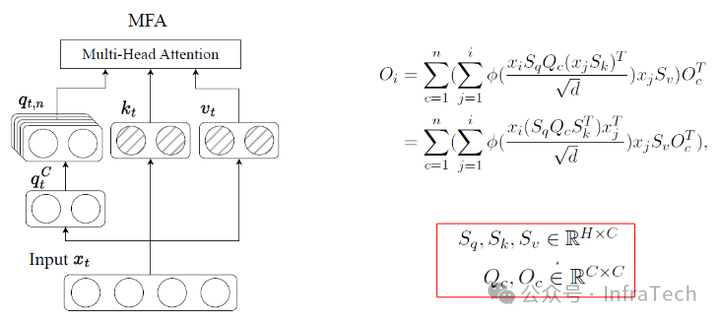
把几种Attention模块放到一起对比,能够看到不同模块的存储、表达能力的差异,根据一般的经验参数有:
-
表达能力:FPBA>MFA>MLA>MHA/GQA
-
KV存储:FPBA>MHA> MLA>MFA>MQA
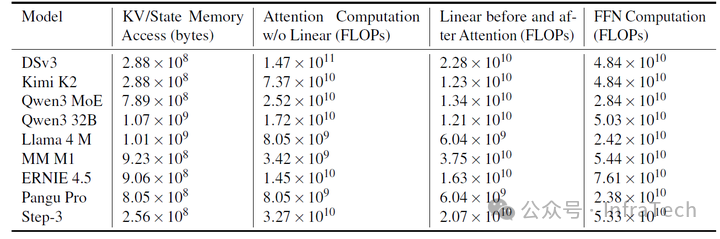
模块的算力消耗可结合具体参数模型进行分析。下表展示了在8k序列长度下,decode阶段每生成一个token时,KV Cache的访存(memory access)、Attention(scaled dot-product)计算量、Attention投影矩阵计算量以及FFN计算量的对比:
step3数据表格
一直在更新,更多的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

1.2 层的划分
在MoE模型结构中,AF分离时需考虑切割位置的选择,这与卡间通信机制及AF执行流水设计密切相关。常见的切割位置选择包括:
-
在残差连接交界处。该位置传递的数据仅为单路 hidden state,传输路径清晰。
-
在 router 之后。即将 router 模块划归至 Attention 部分,数据直接发送至目标专家所在设备,FFN 计算完成后再以点对点方式传回。这种做法优势在于FFN内部不涉及集群通信,对互联带宽的要求较低。
1.3硬件特点
不同硬件在算力、HBM容量及显存带宽等指标上存在显著差异。下表列出了几款常见GPU的规格。
|
特性 |
NVIDIA H800 |
NVIDIA H20 |
NVIDIA A800 |
华为昇腾910B |
|---|---|---|---|---|
|
显存容量 |
80GB HBM2e或HBM3 |
96GB HBM3 |
40GB或80GB HBM2e |
64GB HBM2e |
|
片上显存带宽 |
2.0TB/s(HBM2e) 或3.35 TB/s (HBM3) |
4.0 TB/s (HBM3) |
2.0 TB/s (HBM2e, 80G版) |
392GB/s (HBM2e) |
|
FP16/BF16 算力 |
~1979 TFLOPS |
148 TFLOPS |
312TFLOPS |
256-376 TFLOPS |
|
互联带宽 (NVLink) |
400GB/s |
900GB/s |
400GB/s |
392 GB/s (华为HCCL) |
在AF分离架构中,主要关注算力与显存带宽两项指标,二者之比定义出一个理论上限值
roofline=FLOPs/bandwith
不同模型类型对应不同的计算瓶颈上限(roofline),模型或模块的参数设计应尽可能匹配硬件的roofline性能曲线。例如,在Step3研究中就对比了多种Attention机制与不同硬件的计算-访存曲线关系:
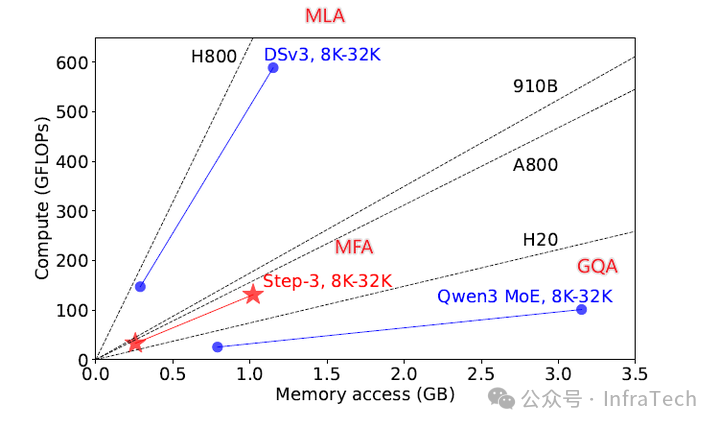
综上所述,Attention与FFN在计算特性上存在差异,不同类型的Attention或FFN之间也存在计算区别。在Decode计算过程中,当AF的类型或参数发生变化时,往往难以使A和F同时达到硬件的算力上限,加之不同硬件本身的性能差异,导致整体效率受限。因此将A与F分离部署,通过构建异构计算场景,能够更好地发挥硬件性能、实现整体推理效能的最优配置。
二、研究方案
目前公开的研究方案主要围绕硬件的特性、模型的特性、网络的特点展开。
2.1 xDS方案
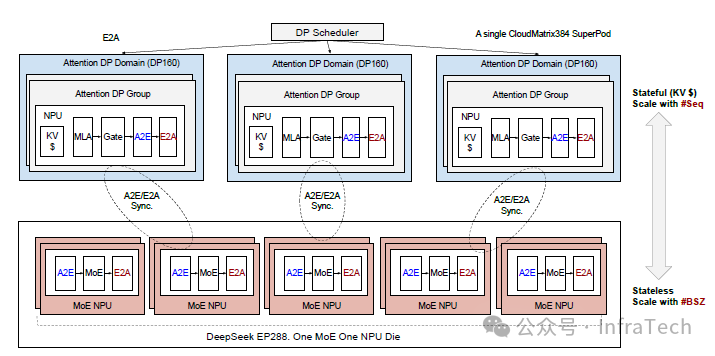
xDS中DMA方案基于CloudMatrix384硬件架构进行研究。CloudMatrix384是一种超节点架构,每个节点包含768个NPU(或GPU),NPU间通过超平面互联,卡间带宽保持均匀一致。相比传统以8卡为一个节点的集群,该架构显著提高了节点内互联带宽。在MoE与Attention分离设计时,需充分利用这一高带宽、一致性互联的特性。
整体方案:
在768卡资源分配中:288卡用于部署专家模块(含256个路由专家及32个共享专家),480卡用于部署MLA结构(采用DP160与TP1并行策略)。Attention与FFN间通过定制通信算子A2E/E2A进行通信。
弹性扩缩容功能方面:Attention模块可根据序列长度动态调整规模,FFN模块则依据batch size实现弹性扩缩容。
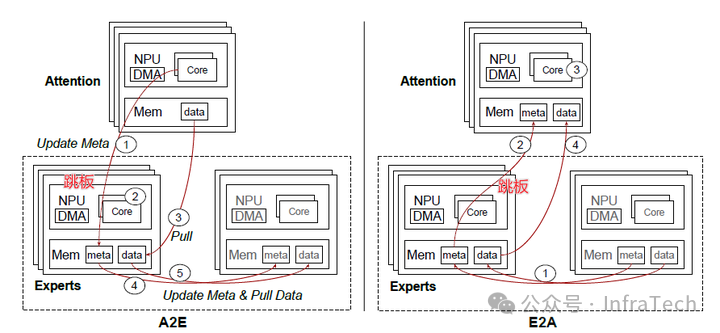
通信与流水设计:
DMA中的定制通信算子A2E(Attention to Expert)与E2A(Expert to Attention)功能类似于Dispatch/Combine,但核心目标是解决通信负载均衡问题。一般的方式中Attention模块需向所有专家发送数据,而DMA采用了一种“跳板”机制:指定Attention模块的NPU与部分专家NPU构成对等子集作为跳板,数据首先发送至跳板NPU,再由其完成向目标专家的转发。
在流水线设计方面,单个Attention实例与FFN实例间采用同步锁定机制进行通信。当某一Attention实例与FFN进行交互时,其他Attention实例无法同时与该FFN实例通信。其数据流水方式与流水并行(Pipeline Parallelism, PP)类似,需逐层执行串行计算,同样存在流水线空泡(Bubble)问题。
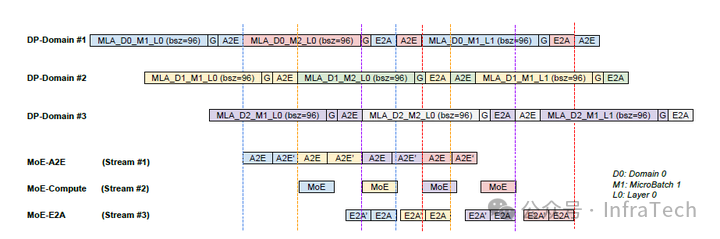
根据公开报告显示,DMA方案在性能方面提升显著,但目前该实现尚未开源,且其设计紧密围绕超节点架构展开,在通用场景下的适用性仍有待验证。
2.2 MegaScale-Infer方案
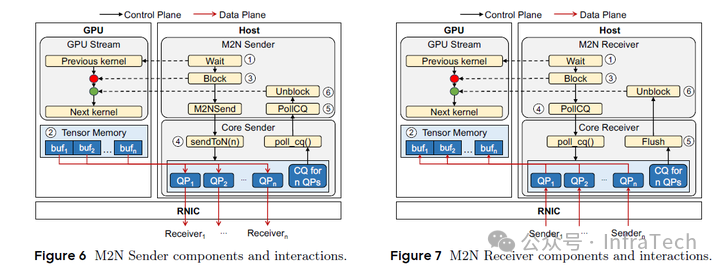
MegaScale-Infer 方案尝试采用 GPU 异构架构,通过匹配异构硬件与模型特性以优化推理性能。部署采用 xMxN 结构,通信通过 M2N/N2M 算子实现。该方案具有以下特点:
-
硬件匹配策略:Attention 模块部署在片上带宽大、算力相对较低的硬件上,FFN 模块则使用算力更高的硬件;
-
并行控制方式:通过调整数据并行(DP)并行度控制 GPU 利用率,通过张量并行(TP)并行度调控时延(Latency),并通过 M/N 的数量配置调节系统吞吐量。
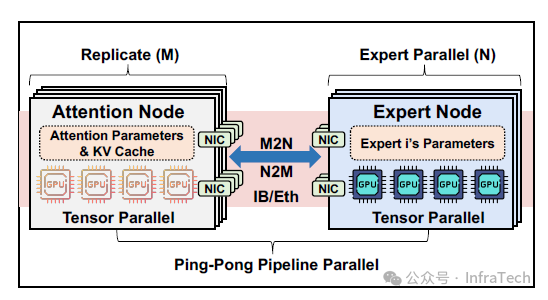
为实现 DEP 的高效通信,MegaScale-Infer 设计了专用通信库 MxN。该库基于 NCCL 进行了多项优化:减少 Host-to-Device(H2D)与 Device-to-Host(D2H)的拷贝操作、降低集群通信组的初始化开销、缓解 GPU 同步带来的影响,从而有效解决了通信开销过大与延迟(Latency)不稳定的问题。
配合 MxN 通信库的流水设计采用称为“Ping-Pong”的方案,该方案主要通过拆分 batch 构建执行流水,以实现通信与计算的重叠(Overlap)。当 Attention 计算时间(Ta)与 FFN 计算时间(Te)接近时,overlap效果尤为显著。
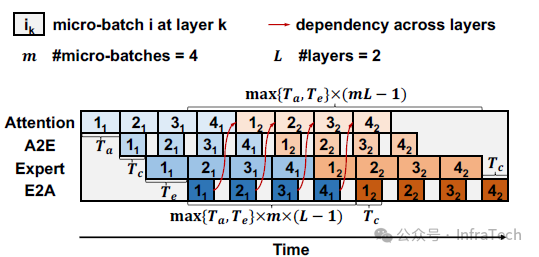
Ping-pong Pipeline Parallelism
2.3Step3方案
Step3 的 AFD 方案基于自研模型结构实现,其 Attention 模块采用 MFA(Multi-matrix Factorization Attention)结构,显著减少了计算量和 KV Cache 的缓存占用,并定制了专用通信库 StepMesh,以支持高效的 A2F 与 F2A 通信。
整体方案:
AF划分的具体方式如图左所示,其中 router 模块归属于 Attention 实例。该方案具有以下特点:
-
数据传递:从 A 到 F 的数据包括 Norm 计算后的 FP8 tokens、量化比例及专家分布数据;从 F 返回 A 的数据为 FP16/BF16 格式。
-
分布策略:Attention 部分采用数据并行(DP),FFN 部分可选用张量并行(TP)、专家并行(EP)或两者结合(TP+EP)。
-
通信设计:A2F 与 F2A 仅在同编号的卡间进行点对点广播传输,不涉及集合通信操作。当 Attention 实例数量与 FFN 实例匹配时,通信-计算重叠效果较好;若 FFN 实例数量过多,则可能成为系统瓶颈。
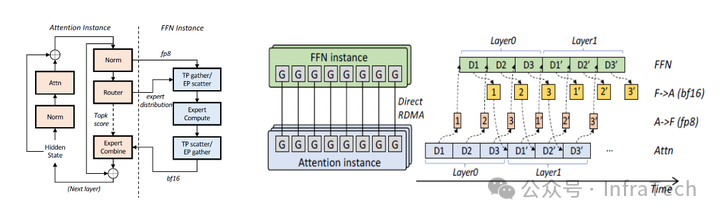
整体方案
通信与流水设计:
Step3的AF通信采用了定制的通信库StepMesh,并且相关内容已开源(详细介绍)
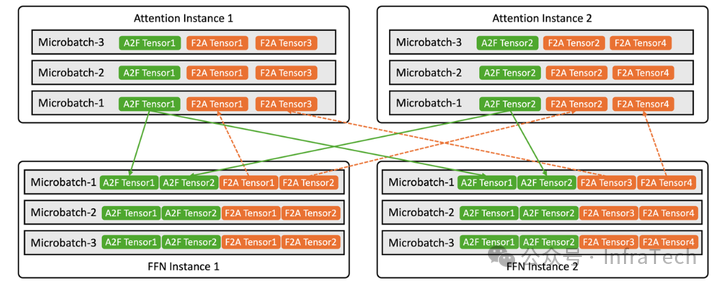
StepMesh 通信模式,以 2A2F 3 级流水线(FFN 并行策略为 EP)为例
特点:
-
一个基于 GPUDirect RDMA 技术、专为 AF 分离架构设计的通信库,可提供低延迟、零流多处理器(SM)占用和灵活的二分图通信能力。该库基于开源项目BytePs构建
-
设计需满足 20 Tokens/s 的 SLA 要求,完成一次双向通信的时间开销应小于 273 μs。

满足 SLA 条件下,2A2F(Batch Size=128)场景下,StepMesh 理想通信开销
StepMesh的流水设计围绕SLA展开。
以 3 级流水线为例,当第 1 层的的 Microbatch 1 Attention 完成计算后,StepMesh 的 Net-Send 线程启动对 A2F Tensor 的 RDMA 发送操作,发送完成后,FFN 侧将接收到相应的信号,并启动 FFN 计算操作。在实际计算前,FFN 还需要执行一次 AllGather 操作,用于将不同 GPU 收到的 Tokens 分发到所有 FFN GPU。AllGather 完成后将执行后续计算操作。完成前置操作后,FFN 侧将调用 StepMesh 的 Net-Send 线程将计算结果发送至 Attention 侧。
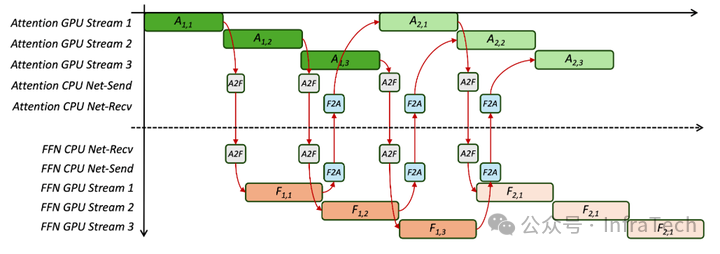
3 级流水线下,StepMesh Timeline
Step3 在设计上考虑了模型与不同硬件之间的亲和性,其通信库 StepMesh 现已开源。
几种方案的通信方式的简单对比:
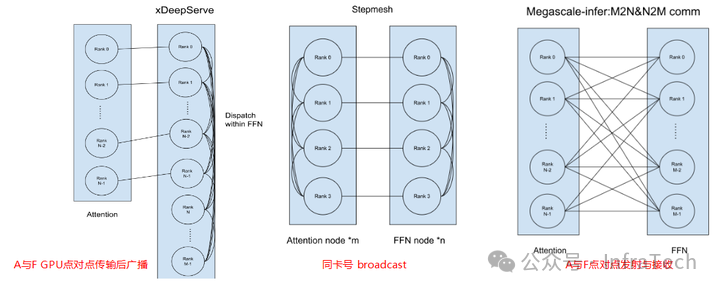
不同方案的通信方式对比
三、框架上的实践
目前 AFD 在主流框架中的方案仍处于 RFC(Request for Comments)阶段,本节重点分析其在 SGLang 和 vLLM 中的实现情况。
3.1SGLang框架
SGLang 目前主要推行 Step3 提出的方案,当前尚处于可行性验证阶段(该方案仍需进一步迭代与优化)。在该架构中,Attention 模块负责请求的输入和输出处理,并由 Attn 调度器分发 FFN 的计算任务;请求执行过程中采用微批次(Microbatch)流水并行方式。
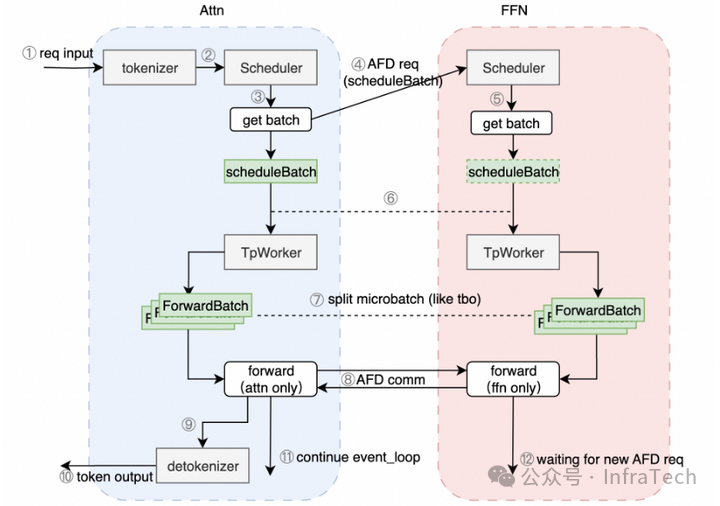
从方案设计来看,代码的改动涉及 tokenizer 的执行位置、scheduler 参数的接收与执行逻辑、worker 间的数据传递(或专用 worker 的引入)等方面。相关的社区 PR 和 RFC 可参考以下内容:
https://github.com/sgl-project/sglang/issues/9401
https://github.com/sgl-project/sglang/issues/9347
3.2vLLM 框架
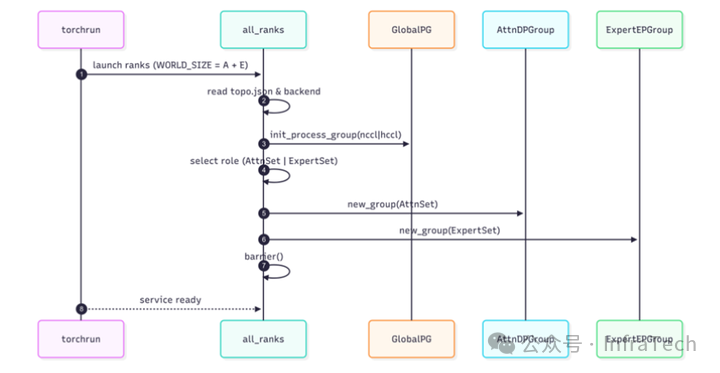
在 vLLM 中支持 AFD 功能需对调度层与执行层进行修改,并需实现一个专用于 A 与 F 间通信的传输层。社区中讨论的方案主要包括:
1、基于 vLLM 引擎部署Attention实例:在vLLM API服务器后端部署纯Attention计算节点,复用连续批处理、分页键值缓存管理等机制,同时将Attention激活值传输至独立进程中的FFN模块。
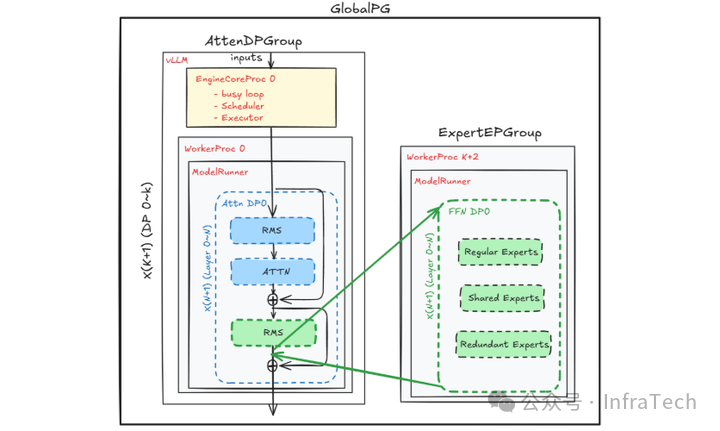
2、FFN 实例部署:采用独立的 vLLM 引擎核心运行纯 FFN 分片,通过 multiprocessing(mp)或 Ray 后端接入专家并行组,实现与 vLLM 服务器的解耦。
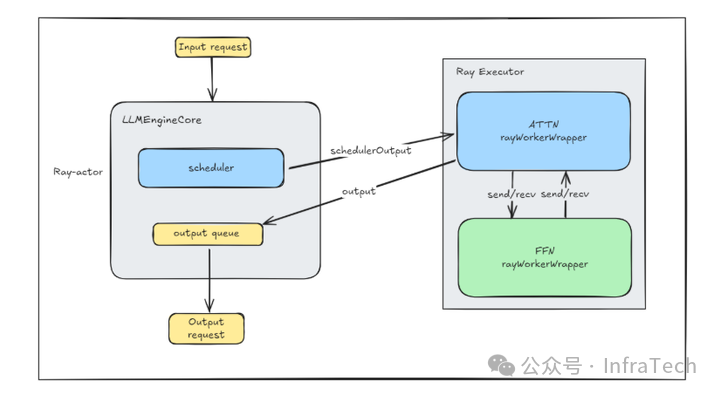
3、AFD 集合通信方案:构建统一的集合通信组,基于 NCCL 等通信库,在每个微批次中以非阻塞流式顺序执行集合通信操作,如分组发送/接收(grouped send/recv)或 all-to-all。
4、传输层设计参考:类似于 PD 分离架构中 KV 传输采用的 Connector 类,可考虑为实现 AFD 设计专用的 Connector 类,底层集成 StepMesh 等通信库。
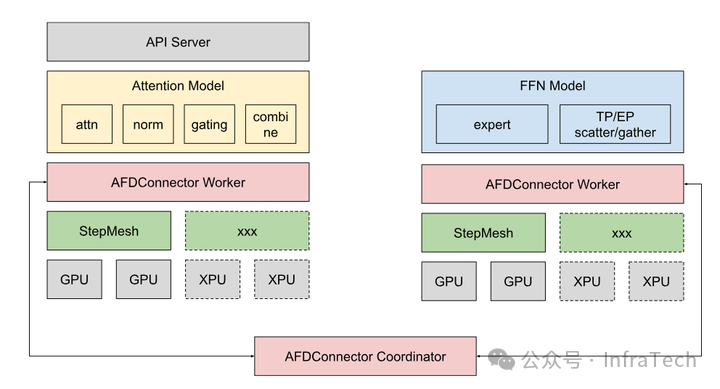
总体而言,vLLM 中上述实现方案目前仍处于探索阶段,具体设计可能随社区进展不断调整。
相关的讨论PR:https://github.com/vllm-project/vllm/issues/22799
四、小结
AFD的价值:目前AFD的关注重点集中在芯片侧。正如Step3主要作者所言,大多数可采用大专家并行(大EP)的场景均能适用AF分离方案,并可实现更优性能。已有若干研究验证了其在Decode场景下为集群带来的显著收益。
方案的挑战:实施AFD集群方案需综合考虑多方面问题,涉及框架本身改动、集群通信调整,若引入异构硬件还需解决不同集群间的网络互通与通信协议匹配。在系统设计层面,启用弹性调度机制会增加系统复杂度,可靠性也将成为关键挑战。
框架方案:AFD对性能的优化效果与具体应用场景紧密耦合,一旦模型参数、结构或硬件配置发生变化,原有优化收益可能难以保持,往往需经过多次调整甚至重新设计。当前社区中的相关方案尚不成熟,预计仍需经历较多迭代。
五、AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!
01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
更多推荐

 12
12 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)