
【每天一个知识点】RAG(Retrieval-Augmented Generation) 中的检索
RAG框架中检索环节是关键,负责弥补大模型知识盲区、提高生成准确性和控制幻觉。典型流程包括查询转化、文档匹配(稀疏/稠密/混合检索)、结果排序和格式化。检索方式分关键词、Embedding和动态聚类等类型,面临召回不足、长文档处理等挑战。检索质量直接影响生成效果,二者协同工作:检索获取相关知识,生成模型组织语言回答。
在 RAG(Retrieval-Augmented Generation) 框架中,检索(Retrieval) 是最核心的环节之一,直接决定了生成模型能否获取到高质量、相关性强的知识支撑。
1. 检索的目标
-
补充大模型的知识盲区:大模型的参数知识库是静态的,无法覆盖最新或专业的领域知识。检索通过外部知识库弥补这一不足。
-
提高生成的准确性与可信度:如果检索结果能精确命中用户问题相关的文档/事实,那么生成结果就更具解释力和可溯源性。
-
控制模型幻觉:通过“先找再答”,减少大模型凭空编造内容的风险。
2. 检索流程
典型的检索步骤包括:
-
用户查询转化:将用户的自然语言问题转化为检索请求(可能包括关键词抽取、embedding 表示、语义改写)。
-
文档索引与匹配:在知识库/向量库中,找到与查询最相关的文档片段。
-
稀疏检索(BM25、关键词索引):更适合短文本、符号化需求。
-
稠密检索(向量检索/embedding 召回):更适合语义匹配,解决“同义表达”。
-
混合检索(Hybrid Retrieval):结合两者优势。
-
-
候选文档排序(Ranking/Re-ranking):对初步召回的结果进行精排,确保最相关的片段排在前面。
-
结果裁剪与格式化:选出前k条结果,压缩为上下文,拼接进Prompt中供生成模型使用。
3. 检索方式的类型
-
基于关键词的检索:依赖倒排索引和关键词匹配,速度快但语义泛化能力差。
-
基于Embedding的检索:通过语义向量相似度(如余弦相似度)来判断相关性。
-
基于聚类/动态组织的检索(高级):在用户意图驱动下动态聚类,将相关信息聚合成知识单元,再进行匹配(这与你正在研究的 动态聚类记忆RAG 方向高度相关)。
-
多轮对话中的上下文检索:结合历史对话进行意图追踪和检索扩展。
4. 检索的挑战
-
召回不足:检索不到关键文档,导致答案缺乏支撑。
-
召回过宽:引入无关文档,降低生成效果。
-
长文档处理:如何切分文档(chunking)以平衡上下文完整性与向量召回粒度。
-
多源融合:如何在数据库、知识库、文档库、API 等多源之间调度检索。
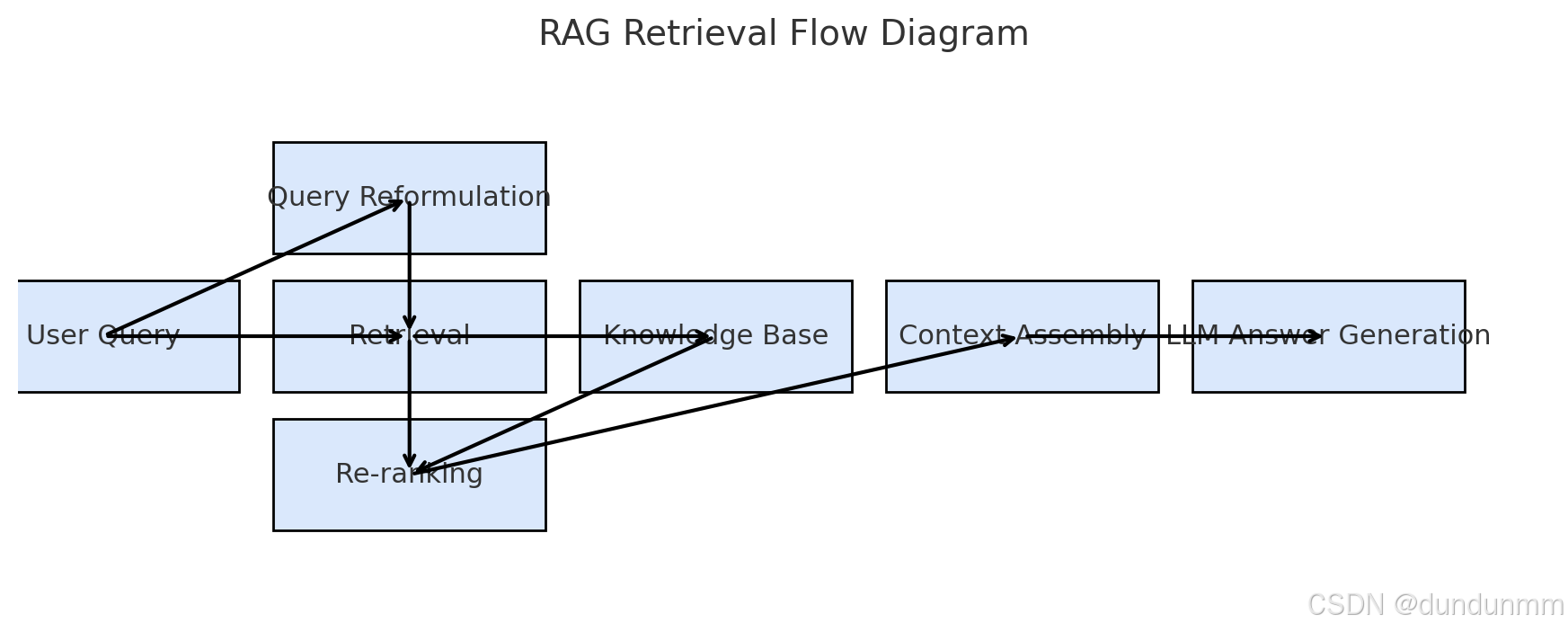
5. 在RAG中的位置
用户问题 → 查询改写 → 检索(文档/知识库/向量库)
↓
相关文档片段拼接进Prompt
↓
大模型生成回答(基于检索到的知识)
检索是 “找到对的知识”,生成是 “组织语言回答”。两者互为依赖:检索质量决定了生成的上限。
更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)