
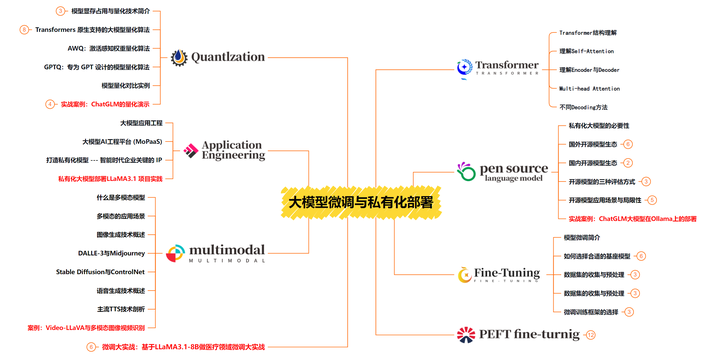
大模型面试题详解 | AI大模型核心技术(采样器、训练参数、LoRA原理)
使用 SFT: 当你有充足的计算资源和较大的数据集时,SFT 是更好的选择,因为它可以充分利用整个模型的能力进行任务特定微调。使用 LoRA: 当计算资源有限、需要快速微调或部署、或在处理非常大的模型(如 GPT-3、GPT-4)时,LoRA 提供了一个高效且存储友好的替代方案。总的来说,LoRA 和 SFT 各有优劣,选择哪种方法应根据具体的任务需求、可用资源和模型架构来决定。
文章详解AI模型核心技术,涵盖Stable Diffusion采样器原理、语音克隆评估指标、训练参数设置、LoRA微调方法及其与SFT的对比。内容实用性强,适合AI开发者学习和收藏。
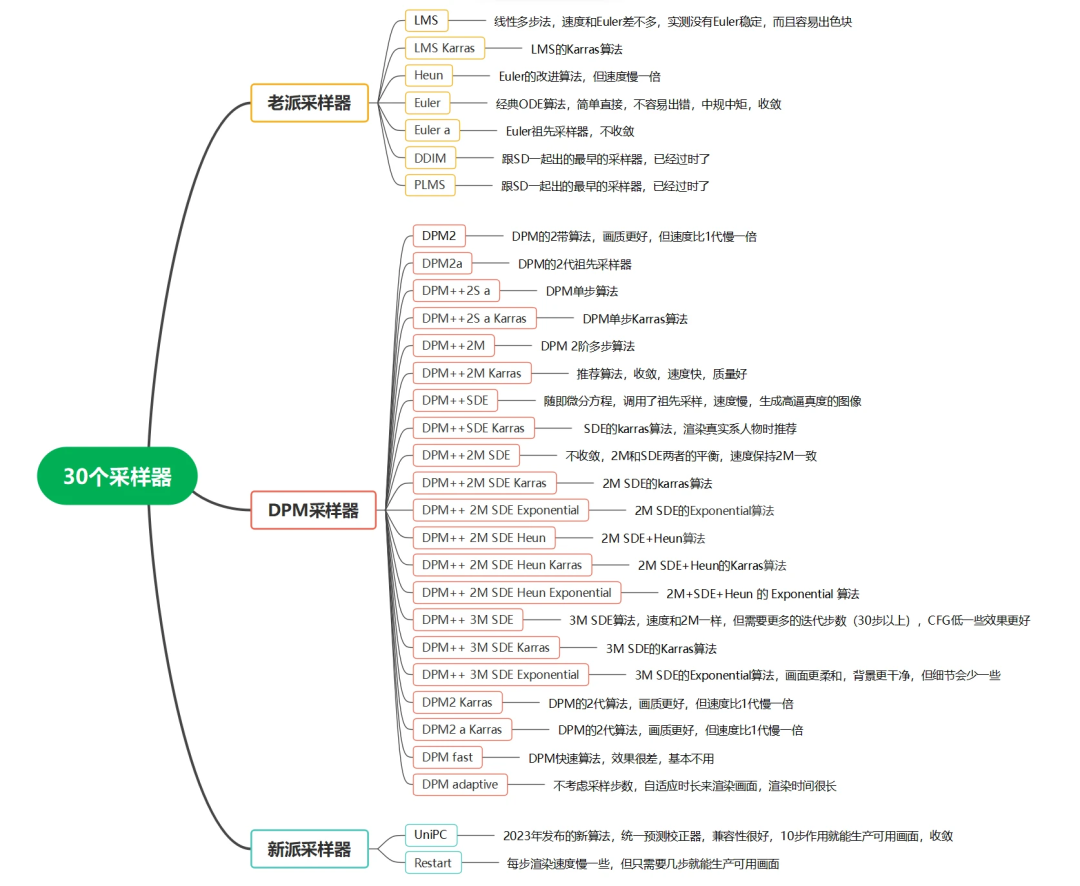
1.SD生图模型里采样器有哪些
什么是采样,在生成图片时,Stable Diffusion会先在隐层空间(latent space)中生成一张完全的噪声图。噪声预测器会预测图片的噪声,将预测出的噪声从图片中减去,就完成了一步。重复该过程将会得到清晰的图片。
由于 Stable Diffusion 在每一步都会产生一个新的图像样本,因此去噪的过程被也被称为采样。采样过程所使用的方法被称为采样方法或采样器。
Ancestor Samplers
Euler a
DPM2 a
DPM++ 2S a
DPM++ 2S a Karras
他们就是祖先采样器。祖先采样器会在每个采样步对图像添加噪声。祖先采样器都是随机(stochastic)采样器,因为他们的采样结果具有随机性。但是,注意也有其他的名字中不带 a 随机采样器。
下面是所有的采样器:
自己在编程时使用到的采样器:
from diffusers import EulerAncestralDiscreteScheduler,
UniPCMultistepScheduler, DPMSolverMultistepScheduler,
LCMScheduler
挑一些常见的采样器重点解释一下:
Euler a:祖先采样器不收敛
UniPC:2023年发布的新算法,统一预测校正器,兼容性很好,10步作用就能生产可用画面,收敛
DPM++2M:DPM2阶多步算法
DPM++2M Karras:推荐算法,收敛,速度快,质量好
LCM:Latent Consistency Models(潜在一致性模型),它的使用需要搭配一个小的Lora模型,主要的作用是实现超级加速的绘画,可以在1秒内生成图像。
2.语音克隆评判最优的步数,指标是什么
📊 衡量指标(Metrics)
Mean Opinion Score (MOS): 主观人耳评估常用指标;
相似度(Similarity): 比较参考音频,GPT‑SoVITS 在 5 秒音频样本条件下,通常能克隆出 80 %–95 % 的相似度;1分钟样本微调时可以更贴近真人;
Timbre similarity(音色相似度): 特别是在 v3/v4 中,通过 S2 结构的改进,不仅音质提升,音色相似度也显著增强;
过拟合情况: 如出现 metallic noise(电音)、失真等,说明训练步数或模型配置过高,应适度调整。
3.训练步数和轮数的区别
在机器学习中,训练步数(training steps)和轮数(epochs)是控制模型训练进度的两个核心概念,它们之间存在以下区别与联系:
🛠️ 定义
训练步数(Step 或 Iteration):指模型通过一个 batch 的一次前向 + 反向传播,并更新参数,即一次梯度下降更新。
轮数(Epoch):指模型完整地遍历了整个训练数据集一次。一轮通常包括多个 batch,也就是多个步骤。
🔢 关系与公式
每轮中包含的步骤数 = 总样本数 ÷ batch 大小。例如,有2000张图、batch=10,则每轮有200步。
总训练步数 = 轮数 × 每轮步骤数。
📌 举例说明
假设:
数据集 = 2000 张图片
batch size = 10
设置训练 5 个 epoch
那么:
每轮步骤数 = 2000 / 10 = 200 步
总训练步数 = 5 × 200 = 1000 步
也就是说,模型将迭代更新参数 1000 次,但这次迭代是分散在整个训练过程里的。
4.简单讲一下Lora的原理
LoRA(Low-Rank Adaptation)是一种参数高效微调技术,核心思想是:不直接修改预训练模型的原始权重,而是通过引入可训练的低秩矩阵来模拟权重变化,从而大幅减少计算和存储开销。
一句话原理
用两个小矩阵的乘积(低秩分解)来近似全参数微调中的权重更新,只训练这两个小矩阵。
具体步骤


5.解释使用Lora为什么参数量从d×k降至(d+k)×r
直观理解

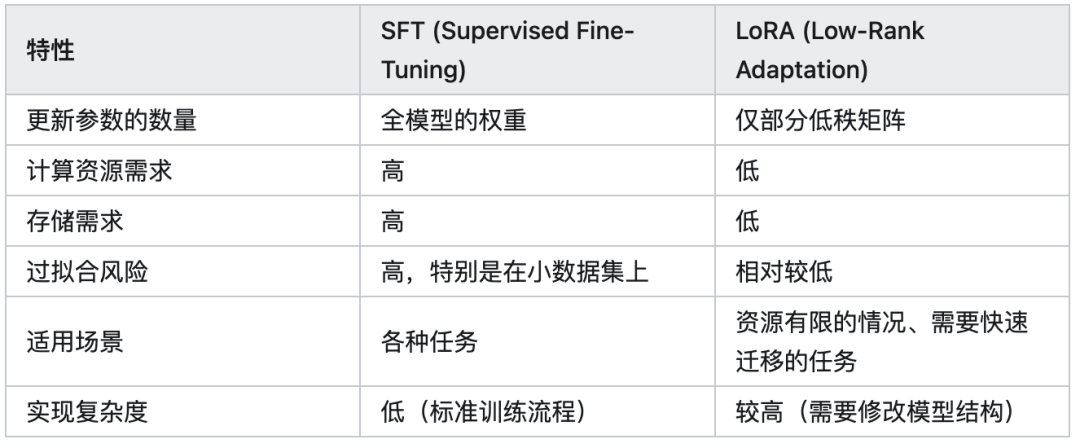
6.SFT和Lora的区别
SFT (Supervised Fine-Tuning) 和 LoRA (Low-Rank Adaptation of Large Language Models) 是两种在深度学习中用于微调预训练模型的方法。它们有不同的适用场景和实现方式,以下是对这两种方法的详细解释及其区别。
1. SFT (Supervised Fine-Tuning)
SFT(监督式微调) 是一种传统的模型微调方法,主要用于在特定任务上进一步训练预训练模型。
基本概念: 在 SFT 中,整个预训练模型的权重都会被更新。这种方法通常是为了让预训练模型适应新的特定任务或者数据集,利用带有标签的数据对模型进行监督式学习。
过程:
预训练模型加载: 从预训练的大型模型(如 BERT、GPT-3 等)开始。
微调数据准备: 准备好任务特定的数据集,通常是标注过的数据。
训练: 使用标注数据集在模型的所有权重上执行反向传播和梯度下降更新。
优点:
通用性强: 可以适用于各种不同的任务(如分类、生成、翻译等)。
简单直接: 直接使用标准的训练方法,无需修改模型架构。
缺点:
计算开销大: 由于需要更新整个模型的权重,计算资源需求高。
存储需求高: 对于大型模型,存储和更新整个模型的所有权重需要大量内存和存储空间。
过拟合风险: 对小数据集进行全模型微调容易导致过拟合。
2. LoRA (Low-Rank Adaptation of Large Language Models)
LoRA(低秩适应) 是一种轻量化微调方法,专门设计用于有效地调整大型预训练语言模型,尤其是在内存和计算资源有限的情况下。
基本概念: LoRA 的核心思想是减少训练参数的数量,而不是直接更新整个模型的权重。它通过在每个线性层(如 Transformer 中的自注意力和前馈神经网络)引入额外的低秩矩阵来实现参数高效的微调。
过程:
预训练模型加载: 从预训练的大型模型(如 GPT-3)开始,保持模型的原始权重不变。
插入低秩矩阵: 在模型的部分权重矩阵(例如自注意力机制的权重矩阵)上插入低秩的矩阵分解。
训练低秩矩阵: 只训练这些新引入的低秩矩阵,而保持原始权重不变。
优点:
高效性: 大幅减少了需要更新的参数数量,从而降低了计算和存储需求。
节省内存: 不需要存储整个模型的梯度,只需存储额外的低秩矩阵。
易于迁移: 由于只更新一小部分参数,微调后的模型容易迁移到不同任务。
缺点:
灵活性稍弱: 由于 LoRA 只训练低秩矩阵,对于某些特定任务可能不如全量参数微调(SFT)有效。
依赖于特定架构: LoRA 的实现依赖于 Transformer 模型架构的线性层,不能直接应用于所有类型的模型。
3.区别总结
4. 选择哪个方法?
使用 SFT: 当你有充足的计算资源和较大的数据集时,SFT 是更好的选择,因为它可以充分利用整个模型的能力进行任务特定微调。
使用 LoRA: 当计算资源有限、需要快速微调或部署、或在处理非常大的模型(如 GPT-3、GPT-4)时,LoRA 提供了一个高效且存储友好的替代方案。
总的来说,LoRA 和 SFT 各有优劣,选择哪种方法应根据具体的任务需求、可用资源和模型架构来决定。
如何系统学习AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

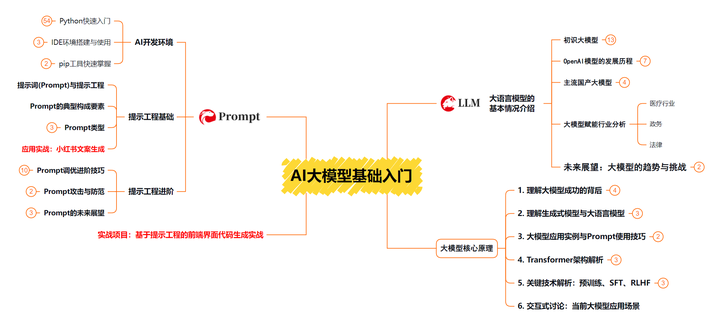
第一阶段 大模型基础入门【10天】
这一阶段了解大语言模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;掌握Prompt提示工程。
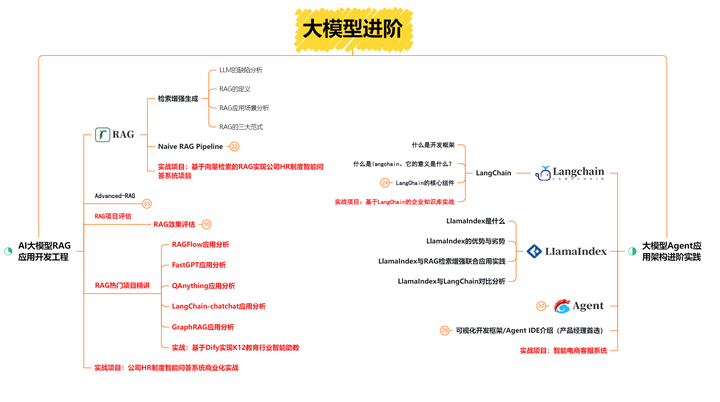
第二阶段 大模型进阶提升【40天】
这一阶段学习AI大模型RAG应用开发工程和大模型Agent应用架构进阶实现。
第三阶段 大模型项目实战【40天】
这一阶段学习大模型的微调和私有化部署
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

更多推荐

 9
9 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)