
小白入门智能体agent — 畅读《A SURVEY OF SELF-EVOLVING AGENTS: ON PATH TOARTIFICIAL SUPER INTELLIGENCE》分篇(一)
本文是一篇论文超详细偏基础讲解笔记,解析了自进化智能体(self-evolving agents)的研究进展,指出静态大语言模型在开放互动环境中的局限性,包括无法持续学习、缺乏记忆系统和执行能力。研究重点转向能实时适应环境变化的智能体,涉及架构设计(感知、记忆、推理等模块)和持续学习、强化学习等方法。论文围绕"进化内容"、"进化时机"和"进化方式"三个维度展开,探讨从大模型到基础智能体再到自进化智
本篇文章摘取原论文中重点表达进行讲解,面向纯小白,不需要系统阅读原综述论文,即可迅速掌握self-evolving agents的概要,也可以作为原论文的伴读博文。
同时考虑到篇幅,会将对该篇论文的讲解做成一个系列。
先放上我们要读的论文title:
自进化智能体综述:迈向人工超级智能ASI之路
《A SURVEY OF SELF-EVOLVING AGENTS: ON PATH TOARTIFICIAL SUPER INTELLIGENCE》

接下来先从摘要开始,和我一起读论文吧 ~
摘要ABSTRACT
As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time.
【译】:随着大型语言模型(LLMs)越来越多地部署在开放式、交互式环境中,这种静态特性已成为一个关键的瓶颈,需要能够适应性地进行推理、行动和实时进化的agents。
【讲解】:
开放式、互动式环境的特性,及静态LLMs的相应瓶颈:
1. 开放环境中,新的信息随时涌现,会出现训练数据中从未见过的场景、问题和组合( 长尾问题)。相应瓶颈:静态LLMs根据已有的知识,无法学习新出现的概念,也无法应对训练数据分布之外的“超出分布”(Out-of-Distribution, OOD)情况。
2. 智能体与环境会实时互动,环境的“状态”会改变。相应瓶颈:LLMs每次问答虽然可以有上下文窗口,但一旦窗口滑过,之前的互动就会被“遗忘”,没有一个持久化的、可更新的记忆系统,无法进行真正连贯的、个性化的长期交互。
( 环境的状态通常是智能体通过传感器观察到的外部世界状态,在对话系统中,环境通常包括用户输入、对话上下文、外部事件等 )
此外,静态LLMs还有不具备根据环境反馈进行自我优化和调整、自身无法执行任何动作(例如查询数据库、调用API、运行代码、操控机械臂等)的能力。
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
This paradigm shift —from scaling static models to developing self-evolving agents — has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences.
【译】:这种范式转变——从扩展静态模型到开发自我进化的agents——已经激发了对能够从数据、交互和经验中实现持续学习和适应的架构和方法的日益增长的兴趣。
【讲解】:
1. 大模型的Scaling Law :
这里参考了 https://zhuanlan.zhihu.com/p/667489780,模型的最终性能主要与计算量C,模型参数量N和数据大小D三者相关,而与模型的具体结构(层数/深度/宽度)基本无关。
( 当计算预算C固定时,性能取决于N和D的最佳配比。而在一类合理的模型结构(如Transformer)内,缩放规律普遍存在,其具体配置(深度/宽度等)会影响最优配比,但不会颠覆缩放规律本身。)
模型整体损失L(x),可分解成两项。第一项无法通过增加模型规模来减少的损失,是数据中的噪音;第二项能通过增加计算量 x ,减小模型拟合的分布与实际分布之间的差,来减少的损失,伴随计算量 x 趋向于无穷大,第二项可逼近0。
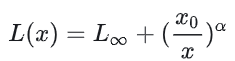
所以论文中的 scaling 就可以理解成,通过“增加模型规模,增加计算量”来达到提高模型性能的方法。
其实过去很多年,科学界的工作重心就是:设计一个固定的模型架构 -> 收集一个巨大的静态数据集 -> 投入海量计算资源进行一次性训练 -> 得到一个强大的模型。但这个模型本身是“静态”的,它一旦训练完成,其知识和能力就固定了。典型代表:GPT-3、PaLM等。
但是当前范式已经转变,“自我进化智能体” (Self-Evolving Agents)标志着智能体不再是静态的,而是能够
- 持续学习 (Continual Learning):在与环境和用户的交互中不断学习新知识。
- 适应与进化 (Adaptation):根据反馈(奖励、惩罚、结果)调整自己的策略和行为。
- 反思与规划 (Reflection & Planning):不仅被动响应,还能主动思考、制定长远计划。
2. Architectures (架构):
architectures = 智能体有哪些模块 + 模块间如何连接 + 模块间如何通信及如何协同工作,可以类比一个人,包括大脑、神经系统、感官和四肢。
一般来说,新型架构通常包含多个专门化的模块:
-
感知模块(Perception Module): 负责处理来自环境的原始数据(如视觉、听觉、文本)。
-
记忆模块(Memory Module): 存储过去的经验、知识、技能,并能快速检索。
-
推理/规划模块(Reasoning/Planning Module): 负责利用当前感知和记忆中的信息进行思考、制定计划、做出决策。大语言模型(LLMs)常常被用作这个模块的“核心引擎”。
-
动作模块(Action Module): 负责执行决策,与环境交互。
-
学习/适应模块(Learning/Adaptation Module): 负责评估表现、从成功和失败中学习,并更新模型参数或记忆内容。
典型架构如CAMEL、AutoGPT 等AI智能体项目都是用这种模块化架构实现的。
3. Methods (方法):
“方法”指的是实现智能体学习、适应和进化的具体算法。
例如“解决持续学习”的常用方法:
-
持续/在线学习(Continual/Online Learning): 方法包括,正则化(防止重要权重被改变)、动态架构(扩展新的网络结构)、回放缓冲(Replay Buffer)(重播旧数据)等。
-
强化学习(Reinforcement Learning, RL):从人类反馈中进行的学习的(RLHF),智能体通过试错,根据获得的奖励(Reward)来调整自己的策略。
-
元学习(Meta-Learning):让智能体在经历了多个任务后,能够快速适应全新的任务。
-
反思与提炼(Reflection & Abstraction): 让智能体回顾自己的经历(Experiences),分析成功与失败的原因,并将具体的经历提炼成抽象的原则或知识,存入记忆模块以备将来使用。
4. Data (数据):
智能体所处理和学习的一切信息的总和,一般包括:
-
传统静态数据: 用于预训练的基础数据集(如用于训练LLM的大量互联网文本)。
-
情境数据(Contextual Data): 智能体在执行特定任务时接收到的实时信息,如用户的指令、当前网页的内容、传感器的读数等。
-
合成数据(Synthetic Data): 智能体自己生成或通过模拟环境产生的数据,用于自我训练和改进。
5. Interactions (交互):
“交互”指的是智能体与外部环境(包括用户、其他智能体、工具、API、虚拟或物理世界)进行双向通信和动作交换的过程。可以是问答、调用工具(如计算器、搜索引擎)、操作软件界面、控制机器人肢体等。通过交互,智能体才能检验其知识、获取奖励信号(是正反馈还是负反馈),从而驱动“方法”进行学习。
6. Experiences (经验):
“经验”是交互和数据经过消化吸收后形成的结构化知识。它不仅仅是原始数据记录,而且附带了上下文、交互的结果、反思等。
也就是智能体获得的原始数据,及在和环境交互后得到的结果,和针对结果进行的反思,都会被作为经验存入记忆模块,未来遇到类似情境时被检索出来指导行动。
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
organizing the field around three foundational dimensions — what to evolve, when to evolve, and how to evolve
【译】:论文正文将围绕三个基础维度组织该领域的综述——进化什么、何时进化以及如何进化。
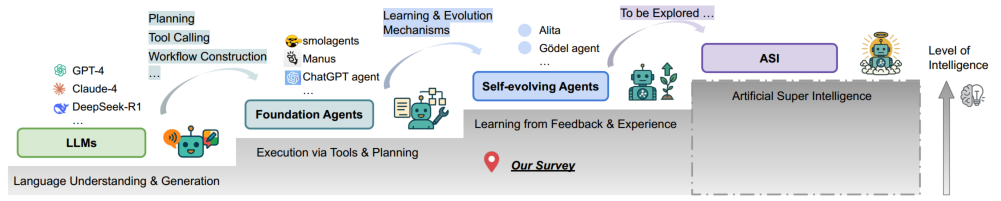
一条概念轨迹,描绘了从大型语言模型(LLMs)到基础 agents 的进展,进而发展为自我进化的 agents ——重点最终指向假设性的人工超级智能(ASI)。沿着这条路径,智能和适应性得到增强,标志着向更自主和代理性AI系统的转变。
更多推荐

 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)