
【LLM】使用 Google ADK、Gemini、QDrant 和 MCP 构建深度研究系统
本文介绍了一个基于谷歌AgentDevelopmentKit开发、由Gemini2.0Flash驱动的多智能体研究助手系统。该系统整合了四类专业智能体(分类、规划、arXiv检索、网页搜索智能体),通过并行处理实现高效学术研究:1)分类智能体分析用户请求;2)规划智能体制定研究策略;3)arXiv智能体检索并分析50篇论文;4)网页搜索智能体获取最新动态。测试显示系统能在27秒内处理100篇论文和
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
在本文中,我将介绍一个基于谷歌Agent Development Kit(ADK)开发、由Gemini 2.0 Flash驱动的一站式多智能体研究助手系统。该体系展示了现代AI架构如何通过整合arXiv论文分析与实时网络搜索能力,协调多个智能体完成学术级研究任务。
该系统通过协调四类专业智能体(用于查询分析的分类智能体、制定研究策略的规划智能体、处理学术论文检索与RAG的arXiv智能体、追踪最新动态的网页搜索智能体),可处理跨多个领域的复杂研究场景。
一、引言:多智能体研究
多智能体系统具备以下独特优势:
- 并行处理:多个研究流的同时执行确保全面覆盖且无时间损耗
- 专业化智能:每个智能体针对特定任务(分类、规划、学术搜索、网络搜索)进行优化,从而产生更高质量的结果
- 来源验证:学术论文提供理论基础,而网络搜索捕捉最新发展,形成完整的研究覆盖
这种架构使多智能体研究系统在同时需要学术严谨性和当前市场情报的场景中展现出强大优势。
二、项目概述
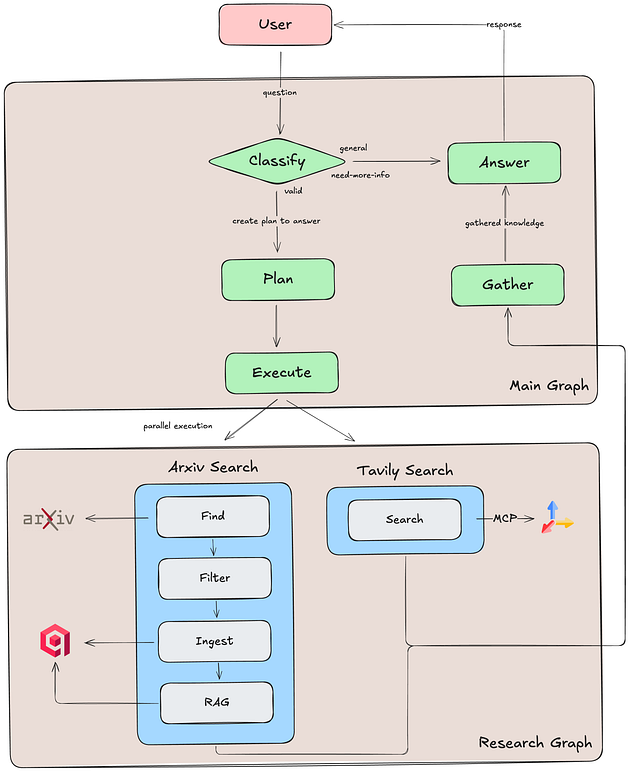
系统工作流程
多智能体工作流程:
1、查询分类与路由:系统分析传入请求,判断其是否构成有效研究问题、需要澄清或超出研究领域范围。
2、研究规划:专业规划智能体创建研究方案,结合ArXiv文献检索与网络搜索。
3、研究执行:多个智能体并行执行研究步骤(最多3步):
ArXiv智能体:检索前50篇论文,根据相关性筛选至前3篇,将全文摄入Qdrant向量数据库,并执行RAG进行信息提取
网络搜索智能体:通过Tavily MCP服务器实时收集网络内容并分析趋势
4、答案合成:汇总各步骤结果,综合生成独特响应。
三、系统架构深入探究
3.1、使用 Gemini 2.0 Flash 进行查询分类
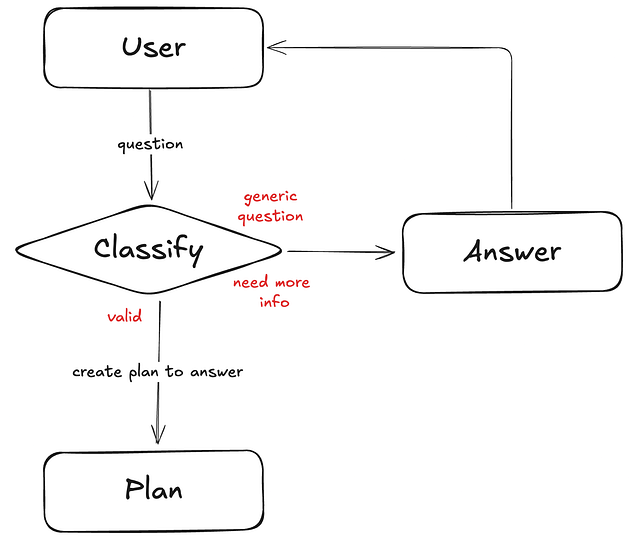
查询分类工作流程
分类代理利用 Pydantic 模型来确定请求的有效性并使用结构化输出进行适当的路由,以确保可预测的响应:
GEMINI_MODEL = ‘gemini-2.0-flash’
system_prompt = """You are a Request Classification Agent that categorizes user requests into three types:
**Categories:**
1. **valid** - Specific, clear research requests with defined topics/domains
2. **need-more-info** - Too broad but shows research intent (needs refinement)
3. **general** - Non-research requests (e.g., "2+2?", greetings, general questions) that don't involve research
**Output Format:**
- **valid**: Return classification + user_intent (concise description of research goal)
- **need-more-info**: Return classification + next_message (ask for clarification)
- **general**: Return classification + next_message (politely decline and explain you only help with research)
Personalize messages when possible.
"""
classify_agent = LlmAgent(
name='ClassifyAgent',
model=GEMINI_MODEL,
instruction=system_prompt,
description='Classify user requests and provide follow-up messages',
input_schema=UserRequest,
output_schema=ClassificationResult,
output_key='classification',
)输出示例:
“How much is 2+2?”
{
"type": "general",
"user_intent": null,
"next_message": "I help with research topics requiring
academic analysis, not simple math"
}3.2、研究计划生成
规划代理生成包含一个或多个步骤(最多3个)的计划:
GEMINI_MODEL = 'gemini-2.0-flash'
system_prompt = """You are a Research Planning Agent that creates step-by-step research plans from the user_intent.**Available Tools:**
1. **ArXiv Search** - Academic papers, theoretical foundations, established research
2. **Web Search** - Recent developments, industry applications, current trends
**Process:**
1. Start from the provided user_intent
2. Break it into key research components
3. Create targeted search queries using appropriate tools
4. Sequence steps logically to build comprehensive understanding
**Requirements:**
- Maximum 3 steps
- Each step must directly address the user's intent
- Build knowledge progressively from foundations to current applications
"""
plan_agent = LlmAgent(
name='PlanAgent',
model=GEMINI_MODEL,
instruction=system_prompt,
planner=PlanReActPlanner(),
description='Plan a list of steps to gather all the information needed to answer the user query',
input_schema=ClassificationResult,
output_schema=ResearchPlan,
output_key='research_plan',
)在此模块中,我们使用Google ADK的Plan ReAct规划器,该规划器会约束大语言模型在采取任何行动/观察前先生成计划。
注意:该规划器不要求模型支持内置的思考功能。
输出示例:
Tell me about the latest advancements on graph theory.
{
"steps": [
{
"action": "arxiv_search",
"query": "recent advances in graph theory"
},
{
"action": "web_search",
"query": "latest developments graph theory"
},
{
"action": "web_search",
"query": "applications of graph theory in 2025"
}
]
}3.3、并行研究执行
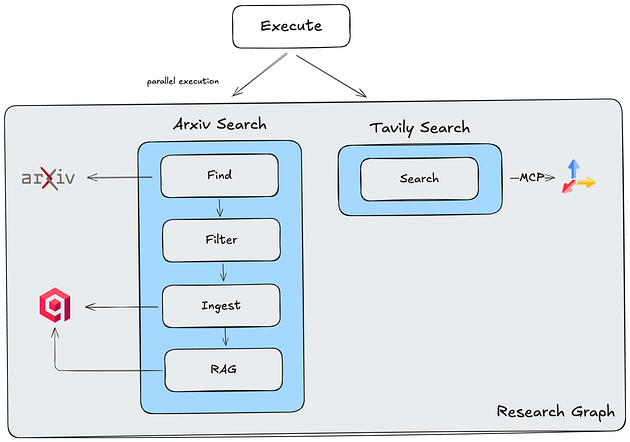
研究执行工作流程
ArXiv研究代理
该ArXiv代理实现了论文分析流程:
class ArxivAgent(BaseAgent):
"""Agent for coordinating ArXiv paper research workflow."""
def __init__(
self,
*,
name: str,
run_id: str,
agent_id: str,
document_service: DocumentIngestionService,
) -> None:
"""
Initialize the ArXiv agent.
Args:
name: Name of the agent
run_id: Unique identifier for the current run
agent_id: Unique identifier for this agent instance
document_service: Service for document ingestion and retrieval
"""
super().__init__(name=name)
self._run_id = run_id
self._agent_id = agent_id
self._document_service = document_service
self._find_step = FindStep(
name='find_step', description='Find papers on arxiv', run_id=run_id, agent_id=agent_id,
)
self._ingest_step = IngestStep(
name='ingest_step', description='Ingest documents', run_id=run_id, document_service=document_service,
)
self._rag_step = RAGStep(
name='rag_step', description='Perform RAG',
run_id=run_id, agent_id=agent_id, document_service=document_service,
)
async def _run_async_impl(self, context: InvocationContext) -> AsyncGenerator[Event, None]:
"""
Execute the complete ArXiv research workflow.
Args:
context: Invocation context containing session state and configuration
Yields:
Events from each step of the workflow
"""
logger.debug(
f'Starting ArXiv research workflow for agent {self._agent_id}',
)
logger.debug('Starting ArXiv paper search step')
async for event in self._find_step.run_async(context):
yield event
logger.debug('Starting paper filtering step')
async for event in filter_agent.run_async(context):
yield event
logger.debug('Starting paper ingestion step')
async for event in self._ingest_step.run_async(context):
yield event
logger.debug('Starting RAG step')
async for event in self._rag_step.run_async(context):
yield event
logger.info(
f'Completed ArXiv research workflow for agent {self._agent_id}',
)工作流
1. 查找(ArXiv API):使用步骤生成的查询,在 Arxiv 上搜索 50 篇论文。暂时不获取论文内容,仅获取其摘要。
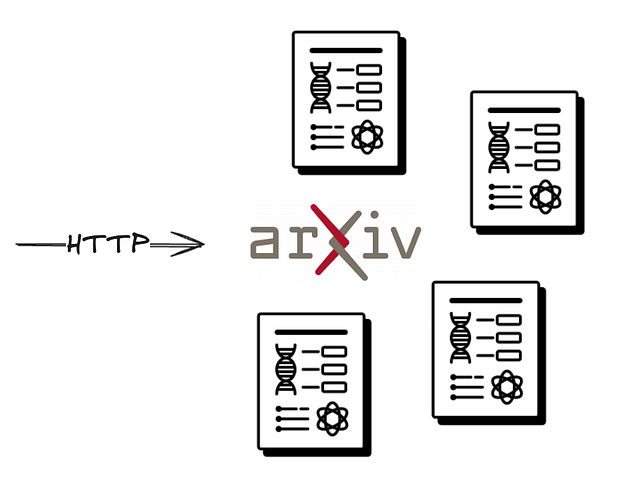
获取 Arxiv 论文的 HTTP 请求
2. 过滤(Gemini 2.0 Flash):过滤结果,选取与步骤查询最相关的前 3 篇论文。现在,我们下载它们的内容。
GEMINI_MODEL = 'gemini-2.0-flash'
PAPERS_NUM = 3
system_prompt = f"""You are a Research Search Agent.
Your role is to identify the most relevant academic papers for a given user query.
**Step 1 — Analyze candidates:**
- Carefully review the retrieved papers, considering both *title* and *abstract*.
- Assess their relevance to the user query with precision.
**Step 2 — Select results:**
- Choose **up to {PAPERS_NUM}** papers that best match the query.
- Prefer recent works (published in the last 3 years).
- Only include papers that provide direct, specific insights on the topic.
- If fewer than {PAPERS_NUM} are relevant, return only those (never add irrelevant ones).
Output rules (strict):
- The output must be a **valid JSON array of strings**, containing only the selected paper IDs.
- Do not include explanations, text outside the JSON, or formatting such as Markdown.
"""
filter_agent = LlmAgent(
name='FilterAgent',
model=GEMINI_MODEL,
instruction=system_prompt,
description='Filter papers',
input_schema=PapersMetas,
output_schema=PaperIDs,
output_key='paper_ids',
)3. 数据摄取(OpenAI 嵌入):对每篇论文内容进行分块、标记化处理,并嵌入到 QDrant 向量数据库中。

从文档到嵌入数据存入QDrant
4. RAG(OpenAI嵌入+语义搜索):使用检索增强生成技术(RAG)提取必要的知识片段来回答步骤查询。

集成MCP的网页搜索代理
该网页搜索代理利用Tavily MCP服务器获取实时信息。通过这种方式,我们能够动态搜索新知识,并将约束条件的选择交由大型语言模型处理。实际上,Tavily提供多种搜索约束选项,例如:
• 起始日期与结束日期
• 搜索主题
• 搜索深度
第二步查询的输出示例:
latest developments graph theory
{
"query": "latest developments graph theory",
"results": [
{
"url": "https://www.quantamagazine.org/how-does-graph-theory-shape-our-world-20250626/",
"title": "How Does Graph Theory Shape Our World? - Quanta Magazine",
"content": "Maria Chudnovsky reflects on her journey in graph theory, her groundbreaking solution to the long-standing perfect graph problem, and the unexpected ways this",
"score": 0.98533,
"raw_content": null
},
{
"url": "https://ijsrem.com/download/a-review-on-the-latest-developments-in-graph-theory-and-its-applications/",
"title": "A review on the latest developments in graph theory and its ...",
"content": "This study explores recent advances in graph theory, particularly in terms of algorithmic development, novel types of graphs, and their diverse applications.",
"score": 0.98393,
"raw_content": null
},
{
"url": "https://news.mit.edu/2024/graph-based-ai-model-maps-future-innovation-1112",
"title": "Graph-based AI model maps the future of innovation | MIT News",
"content": "The new AI approach uses graphs based on methods inspired by category theory as a central mechanism to understand symbolic relationships in",
"score": 0.97673,
"raw_content": null
},
{
"url": "https://www.mdpi.com/journal/axioms/special_issues/560T7U3LML",
"title": "Special Issue : Recent Developments in Graph Theory - Axioms",
"content": "This special issue focuses on advancements in graph theory, discrete applied mathematics, domination theory, and chemical graph theory, with applications in",
"score": 0.97205,
"raw_content": null
},
{
"url": "https://research.google/blog/the-evolution-of-graph-learning/",
"title": "The evolution of graph learning - Google Research",
"content": "We describe how graphs and graph learning have evolved since the advent of PageRank in 1996, highlighting key studies and research.",
"score": 0.97179,
"raw_content": null
}
],
"response_time": 1.4
}3.4、知识收集与答案生成
最后,我们汇总通过执行不同步骤所产生的知识,从而得出答案。
system_prompt = """Synthesize the research results to provide a direct, comprehensive answer to the user's query.
Research Results:
{results}
User Query:
{query}
Instructions:
- Use ALL research findings to answer the query completely
- Support your response with specific evidence from the results
- For EVERY piece of information you include, cite the source with proper references
- When referencing ArXiv papers, use the format: [Author et al., Year] (arXiv:ID)
- When referencing web sources, use the format: [Title] (URL)
- Include a "References" section at the end listing all sources used
- Structure your answer clearly and concisely with proper citations throughout
- Address the query directly without unnecessary elaboration
- Ensure each claim or statement is backed by a specific source reference"""
class AnswerAgent(BaseAgent):
"""Agent for synthesizing research results into a comprehensive answer."""
def __init__(self, *, name: str, run_id: str) -> None:
"""
Initialize the AnswerAgent.
Args:
name: Name of the agent
run_id: Unique identifier for the current run
"""
super().__init__(name=name)
self._run_id = run_id
self._answer_llm = LlmAgent(
model='gemini-2.0-flash',
name=f'answer',
instruction=system_prompt.format(
results=f'{{results:{self._run_id}}}',
query='{query}',
),
)
async def _run_async_impl(self, context: InvocationContext) -> AsyncGenerator[Event, None]:
"""
Execute the answer generation process.
Args:
context: Invocation context containing research results and query
Yields:
Events from the answer generation LLM
"""
async for event in self._answer_llm.run_async(context):
yield event最终,我们得出答案(此处为清晰简洁略作删减):
图论最新进展包括:
图变换器(GTs):在建模图结构及解决图神经网络(GNNs)的过平滑和过挤压等局限性方面展现出强大能力[Bharatiya博客]。研究重点集中在架构、可解释性及应用方向[2502.16533v2]。
超超图神经网络(SHGNNs)与模糊图神经网络:正在建立理论基础以扩展神经网络在这些高级图结构中的适用性[2412.01176v1]。
...
参考文献:
[2502.16533v2]《图变换器综述:架构、理论与应用》(http://arxiv.org/pdf/2502.16533v2)
[2412.01176v1]《超超图神经网络与模糊图神经网络:理论基础》(http://arxiv.org/pdf/2412.01176v1)
...
四、结果
性能指标:
- 查询处理时间:27秒(并行执行)
- 分析论文数量:通过2次ArXiv搜索共100篇论文
- 选定论文:6篇高相关性论文
- 网络来源:来自主要科技公司和研究机构的5个来源
- 响应质量:全面涵盖理论基础和实际实施方案
五、结论
该原型仅代表一个开端。系统的模块化和可扩展特性使其成为持续改进的理想基础。未来开发可聚焦以下几个关键领域,以突破多智能体研究的边界:
- 异构数据工具的扩展:当前系统使用ArXiv和网络搜索功能。通过集成更多专业工具来收集多样化信息,可进一步扩展系统功能。例如,添加金融数据API用于分析股市趋势、医疗数据库用于临床研究,或社交媒体分析工具用于公众情绪分析。
- 采用先进嵌入模型:当前系统使用OpenAI嵌入技术,但谷歌自主研发的Gemini嵌入模型提供了极具吸引力的替代方案。迁移至Gemini嵌入将完全避免对OpenAI的依赖。
- 升级至生产级基础设施:要从原型过渡到可扩展的可靠服务,必须强化基础设施。将Qdrant向量存储迁移至全托管云解决方案(如GCP向量搜索),可提供企业级功能支持。
- 引入新型智能体角色:当前系统配置了四类智能体,但可新增智能体类型以处理更复杂任务。例如:"评审智能体"可分析最终答复中的偏见或逻辑谬误,"专家智能体"可针对特定领域(如法律或医学)进行微调以提供高度专业化的见解,而"创意智能体"则能基于收集的数据协助构思新的研究方向。
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)