
每天10分钟轻松掌握MCP(适合小白):Day 9 - MCP资源管理系统架构与访问控制(一)
每天10分钟轻松掌握MCP(适合小白):Day 9 - MCP资源管理系统架构与访问控制(一)!如果文章对你有帮助,还请给个三连好评,感谢感谢!
·
每天10分钟轻松掌握MCP 40 天学习 - 第9天
MCP资源管理系统架构与访问控制(一)
哈喽各位MCP探索者!今天我们要进入一个相当重要的话题——资源管理系统。如果说MCP是一座城市,那么资源管理系统就是这座城市的"物业管理公司",负责管理所有的房子(资源)、制定访问规则、发放钥匙(权限)。听起来很官方?别担心,我们用最接地气的方式来搞懂它!
MCP资源管理系统架构与访问控制(第一部分)
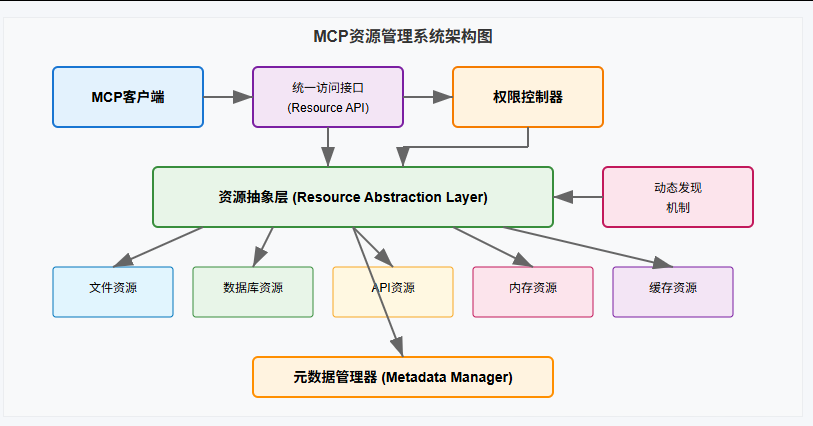
🏗️ 一、MCP资源管理系统整体架构
MCP资源管理系统其实就像一个超级智能的图书馆。这个图书馆不仅管理传统的书籍,还管理各种奇葩的东西:数据库、API接口、内存数据,甚至是临时文件。而我们的任务就是让AI助手能够有序、安全地访问这些"藏品"。
核心架构组件
| 组件名称 | 作用描述 | 生活中的比喻 |
|---|---|---|
| 资源抽象层 | 将不同类型资源统一抽象成标准接口 | 图书馆的分类系统,无论是小说还是工具书都有统一编号 |
| 统一访问接口 | 提供标准化的资源访问方法 | 图书馆的借阅台,所有借书都在这里办理 |
| 动态发现机制 | 自动发现和注册新资源 | 新书到货时自动入库登记 |
| 权限控制器 | 管理谁能访问什么资源 | 门禁系统,检查你的借书证等级 |
| 元数据管理器 | 存储资源的详细信息 | 图书档案,记录每本书的详细信息 |
系统架构流程图
🗂️ 二、资源类型分类体系
在MCP的世界里,资源就像超市里的商品一样,需要分门别类管理。不同类型的资源有着不同的"脾气"和特点,我们来一一认识它们:
资源类型对比表
| 资源类型 | 特点 | 访问方式 | 适用场景 | 生命周期 |
|---|---|---|---|---|
| 文件资源 | 持久化存储,结构化程度低 | 文件路径 | 文档管理、配置文件 | 长期 |
| 数据库资源 | 结构化存储,支持复杂查询 | SQL/NoSQL查询 | 业务数据、用户信息 | 长期 |
| API资源 | 动态数据,实时性强 | HTTP请求 | 第三方服务、实时数据 | 会话级 |
| 内存资源 | 访问速度快,易失性 | 内存地址/键值 | 临时计算、缓存 | 进程级 |
| 缓存资源 | 介于内存和持久化之间 | 缓存键 | 频繁访问数据 | 可配置 |
1. 文件资源详解
文件资源就像家里的各种物品,有的放在书架上(文档),有的放在工具箱里(配置文件),有的临时放在桌子上(临时文件)。
# 文件资源管理示例
from typing import Dict, Any
import os
import mimetypes
from datetime import datetime
class FileResource:
def __init__(self, file_path: str):
"""初始化文件资源
Args:
file_path: 文件路径,就像家里东西的具体位置
"""
self.file_path = file_path
self.resource_type = "file"
def get_metadata(self) -> Dict[str, Any]:
"""获取文件元数据,就像查看物品的标签"""
if not os.path.exists(self.file_path):
return {"error": "文件不存在,可能被外星人偷走了"}
stat = os.stat(self.file_path)
mime_type, _ = mimetypes.guess_type(self.file_path)
return {
"path": self.file_path,
"size": stat.st_size, # 文件大小,就像包裹的重量
"created_time": datetime.fromtimestamp(stat.st_ctime),
"modified_time": datetime.fromtimestamp(stat.st_mtime),
"mime_type": mime_type or "application/octet-stream",
"is_readable": os.access(self.file_path, os.R_OK),
"is_writable": os.access(self.file_path, os.W_OK),
"extension": os.path.splitext(self.file_path)[1]
}
def read_content(self, encoding: str = "utf-8") -> str:
"""读取文件内容,就像打开信封看里面的信"""
try:
with open(self.file_path, 'r', encoding=encoding) as file:
return file.read()
except UnicodeDecodeError:
# 如果是二进制文件,返回提示信息
return f"这是一个二进制文件,无法直接显示内容"
except Exception as e:
return f"读取失败:{str(e)}"
# 使用示例
def demo_file_resource():
"""演示文件资源的使用"""
# 创建一个示例文件
demo_file = "demo_config.txt"
with open(demo_file, 'w', encoding='utf-8') as f:
f.write("# 这是一个示例配置文件\napp_name=MCP学习助手\nversion=1.0\ndebug=true")
# 创建文件资源对象
file_res = FileResource(demo_file)
# 获取元数据
metadata = file_res.get_metadata()
print("文件元数据:", metadata)
# 读取内容
content = file_res.read_content()
print("文件内容:", content)
# 清理
os.remove(demo_file)
# 运行演示
if __name__ == "__main__":
demo_file_resource()
2. 数据库资源详解
数据库资源就像一个超级有序的仓库,每个货架(表)都有明确的标签,每个货物(记录)都有详细的信息卡片。
import sqlite3
from typing import List, Dict, Any
import json
class DatabaseResource:
def __init__(self, db_path: str, table_name: str):
"""初始化数据库资源
Args:
db_path: 数据库文件路径,仓库地址
table_name: 表名,具体的货架号
"""
self.db_path = db_path
self.table_name = table_name
self.resource_type = "database"
def get_metadata(self) -> Dict[str, Any]:
"""获取数据库表的元数据,就像查看货架的信息卡"""
try:
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# 获取表结构信息
cursor.execute(f"PRAGMA table_info({self.table_name})")
columns = cursor.fetchall()
# 获取记录总数
cursor.execute(f"SELECT COUNT(*) FROM {self.table_name}")
total_records = cursor.fetchone()[0]
# 获取数据库文件大小
import os
file_size = os.path.getsize(self.db_path) if os.path.exists(self.db_path) else 0
conn.close()
return {
"database_path": self.db_path,
"table_name": self.table_name,
"columns": [{"name": col[1], "type": col[2], "not_null": bool(col[3])} for col in columns],
"total_records": total_records,
"file_size": file_size,
"supports_sql": True
}
except Exception as e:
return {"error": f"数据库连接失败:{str(e)}"}
def query_data(self, limit: int = 10, where_clause: str = "") -> List[Dict[str, Any]]:
"""查询数据,就像在仓库里找特定的货物"""
try:
conn = sqlite3.connect(self.db_path)
conn.row_factory = sqlite3.Row # 让结果可以像字典一样访问
cursor = conn.cursor()
# 构建查询语句
query = f"SELECT * FROM {self.table_name}"
if where_clause:
query += f" WHERE {where_clause}"
query += f" LIMIT {limit}"
cursor.execute(query)
rows = cursor.fetchall()
# 转换为字典列表
result = [dict(row) for row in rows]
conn.close()
return result
except Exception as e:
return [{"error": f"查询失败:{str(e)}"}]
# 创建示例数据库并演示
def demo_database_resource():
"""演示数据库资源的使用"""
db_file = "demo_users.db"
# 创建示例数据库和数据
conn = sqlite3.connect(db_file)
cursor = conn.cursor()
# 创建用户表
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
email TEXT UNIQUE,
age INTEGER,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
''')
# 插入示例数据
sample_users = [
("小明", "xiaoming@example.com", 25),
("小红", "xiaohong@example.com", 22),
("小李", "xiaoli@example.com", 30),
("小张", "xiaozhang@example.com", 28)
]
cursor.executemany("INSERT INTO users (name, email, age) VALUES (?, ?, ?)", sample_users)
conn.commit()
conn.close()
# 创建数据库资源对象
db_res = DatabaseResource(db_file, "users")
# 获取元数据
metadata = db_res.get_metadata()
print("数据库元数据:", json.dumps(metadata, indent=2, ensure_ascii=False))
# 查询数据
data = db_res.query_data(limit=5)
print("查询结果:", json.dumps(data, indent=2, ensure_ascii=False))
# 带条件查询
filtered_data = db_res.query_data(limit=5, where_clause="age > 25")
print("条件查询结果:", json.dumps(filtered_data, indent=2, ensure_ascii=False))
# 清理
import os
os.remove(db_file)
# 运行演示
if __name__ == "__main__":
demo_database_resource()
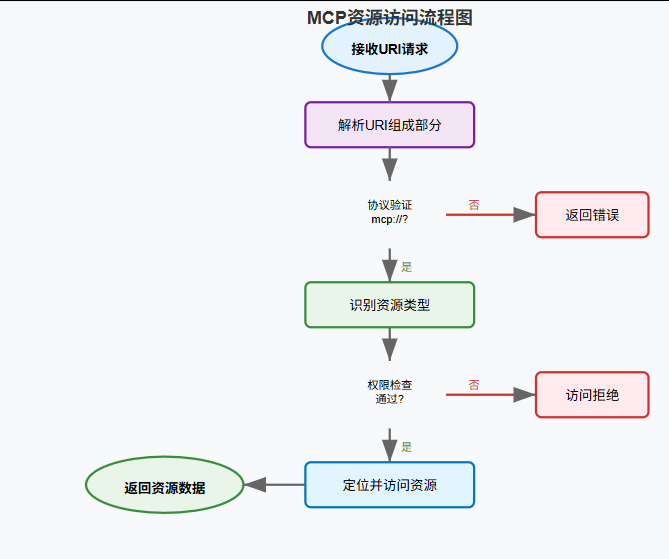
🏷️ 三、资源URI设计规范
URI就像快递地址一样,必须准确、唯一、易读。一个好的URI设计能让AI助手快速准确地找到需要的资源,就像快递员能准确找到你家一样。
URI组成要素详解
一个标准的MCP资源URI包含以下组成部分:
mcp://[authority]/[path]?[query]#[fragment]
| | | | |
协议 服务器信息 资源路径 查询参数 片段标识
URI设计示例表
| 资源类型 | URI示例 | 说明 |
|---|---|---|
| 文件资源 | mcp://local/files/documents/report.pdf |
本地文件系统中的PDF文档 |
| 数据库资源 | mcp://database/users?table=profiles&limit=10 |
用户数据库中的档案表 |
| API资源 | mcp://api.weather.com/current?city=beijing |
天气API的北京实时数据 |
| 内存资源 | mcp://memory/cache/user_session#user_123 |
内存中特定用户的会话数据 |
| 临时资源 | mcp://temp/uploads/image_20241215.jpg |
临时上传的图片文件 |
URI解析器实现
from urllib.parse import urlparse, parse_qs
from typing import Dict, Any, Optional
import re
class MCPUriParser:
"""MCP URI解析器,就像GPS导航一样解析地址"""
def __init__(self):
self.scheme_pattern = re.compile(r'^mcp$') # 只接受mcp协议
def parse_uri(self, uri: str) -> Dict[str, Any]:
"""解析MCP URI,分解成各个组成部分"""
try:
# 使用标准库解析URI
parsed = urlparse(uri)
# 验证协议
if not self.scheme_pattern.match(parsed.scheme):
return {"error": f"不支持的协议:{parsed.scheme},请使用mcp://"}
# 解析查询参数
query_params = parse_qs(parsed.query)
# 构建解析结果
result = {
"scheme": parsed.scheme,
"authority": parsed.netloc, # 服务器/权威部分
"path": parsed.path.strip('/').split('/') if parsed.path.strip('/') else [],
"query_params": {k: v[0] if len(v) == 1 else v for k, v in query_params.items()},
"fragment": parsed.fragment,
"original_uri": uri
}
# 根据权威部分推断资源类型
result["resource_type"] = self._infer_resource_type(parsed.netloc, parsed.path)
return result
except Exception as e:
return {"error": f"URI解析失败:{str(e)}"}
def _infer_resource_type(self, authority: str, path: str) -> str:
"""根据URI特征推断资源类型,就像看地址猜房子类型"""
if authority in ["local", "file", "fs"]:
return "file"
elif authority in ["database", "db", "sql"]:
return "database"
elif authority.startswith("api.") or "api" in authority:
return "api"
elif authority in ["memory", "mem", "cache"]:
return "memory"
elif authority in ["temp", "temporary"]:
return "temporary"
else:
return "unknown"
def build_uri(self, resource_type: str, path: list, query_params: Dict[str, str] = None,
fragment: str = None) -> str:
"""构建标准的MCP URI,就像写标准地址"""
# 根据资源类型选择权威部分
authority_map = {
"file": "local",
"database": "database",
"api": "api",
"memory": "memory",
"temporary": "temp"
}
authority = authority_map.get(resource_type, "unknown")
# 构建路径
path_str = "/" + "/".join(path) if path else ""
# 构建查询字符串
query_str = ""
if query_params:
query_parts = [f"{k}={v}" for k, v in query_params.items()]
query_str = "?" + "&".join(query_parts)
# 构建片段
fragment_str = f"#{fragment}" if fragment else ""
return f"mcp://{authority}{path_str}{query_str}{fragment_str}"
# 使用示例和测试
def demo_uri_parser():
"""演示URI解析器的使用"""
parser = MCPUriParser()
# 测试不同类型的URI
test_uris = [
"mcp://local/documents/projects/mcp_tutorial.md",
"mcp://database/users?table=profiles&limit=10&order=created_at",
"mcp://api.github.com/repos/anthropic/mcp?type=public",
"mcp://memory/cache/user_sessions#session_12345",
"mcp://temp/uploads/image.jpg?quality=high"
]
print("=== URI解析测试 ===")
for uri in test_uris:
result = parser.parse_uri(uri)
print(f"\n原始URI: {uri}")
print(f"解析结果: {json.dumps(result, indent=2, ensure_ascii=False)}")
print("\n=== URI构建测试 ===")
# 测试构建URI
built_uri = parser.build_uri(
resource_type="database",
path=["users", "profiles"],
query_params={"limit": "20", "filter": "active"},
fragment="user_123"
)
print(f"构建的URI: {built_uri}")
# 解析构建的URI以验证
parsed_built = parser.parse_uri(built_uri)
print(f"验证解析: {json.dumps(parsed_built, indent=2, ensure_ascii=False)}")
if __name__ == "__main__":
import json
demo_uri_parser()
资源访问流程图
哈哈,看完这些是不是觉得MCP的资源管理系统其实也没那么神秘?就像管理一个智能化的大型仓库,有清晰的分类、标准的地址系统、严格的门禁控制。下一部分我们将深入探讨权限控制机制和元数据管理,让这个"仓库"变得更加安全和智能!
欢迎大家关注同名公众号《凡人的工具箱》:关注就送学习大礼包

更多推荐

 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)