
【必看】AI智能体核心:函数调用与工具使用完全指南,附代码示例
文章详细介绍了AI智能体与传统LLM的区别,重点讲解函数调用/工具调用能力使智能体与外部世界交互的方法。通过购物助手实例,展示了函数调用的实现、安全防护措施,介绍了instructor库减少样板代码的技巧,以及MCP架构实现动态工具调用的方法,为构建智能体系统提供了完整思路。
前言
AI 智能体(AI Agent)与传统大型语言模型(LLM)的核心区别是什么?答案在于与外部世界交互的能力,而实现这一能力的关键就是工具调用(或称函数调用)。
如果说 LLM 是一个强大的“大脑”,负责思考和生成内容,那么 Agent 就是为这个大脑装上了“感官”和“四肢”。它通过调用工具来感知环境、获取信息,并执行具体任务来影响外部世界。
Agent 背后的核心逻辑非常简单,可以用一个循环[1]来描述:接收指令、思考、调用工具、观察结果,然后重复此过程直至任务完成。
# Agent 核心循环的极简实现
defagent_loop(llm, user_prompt):
message = user_prompt
whileTrue:
# 1. 大脑思考,并决定是否需要使用工具
output, tool_calls = llm(message)
print("Agent: ", output)
# 2. 如果需要,则使用工具(四肢)与外界交互
if tool_calls:
# 3. 将工具返回的结果(感官)作为新的信息输入大脑
message = [handle_tool_call(tc) for tc in tool_calls]
else:
# 4. 如果不需要工具,则与用户继续交互
message = user_input()
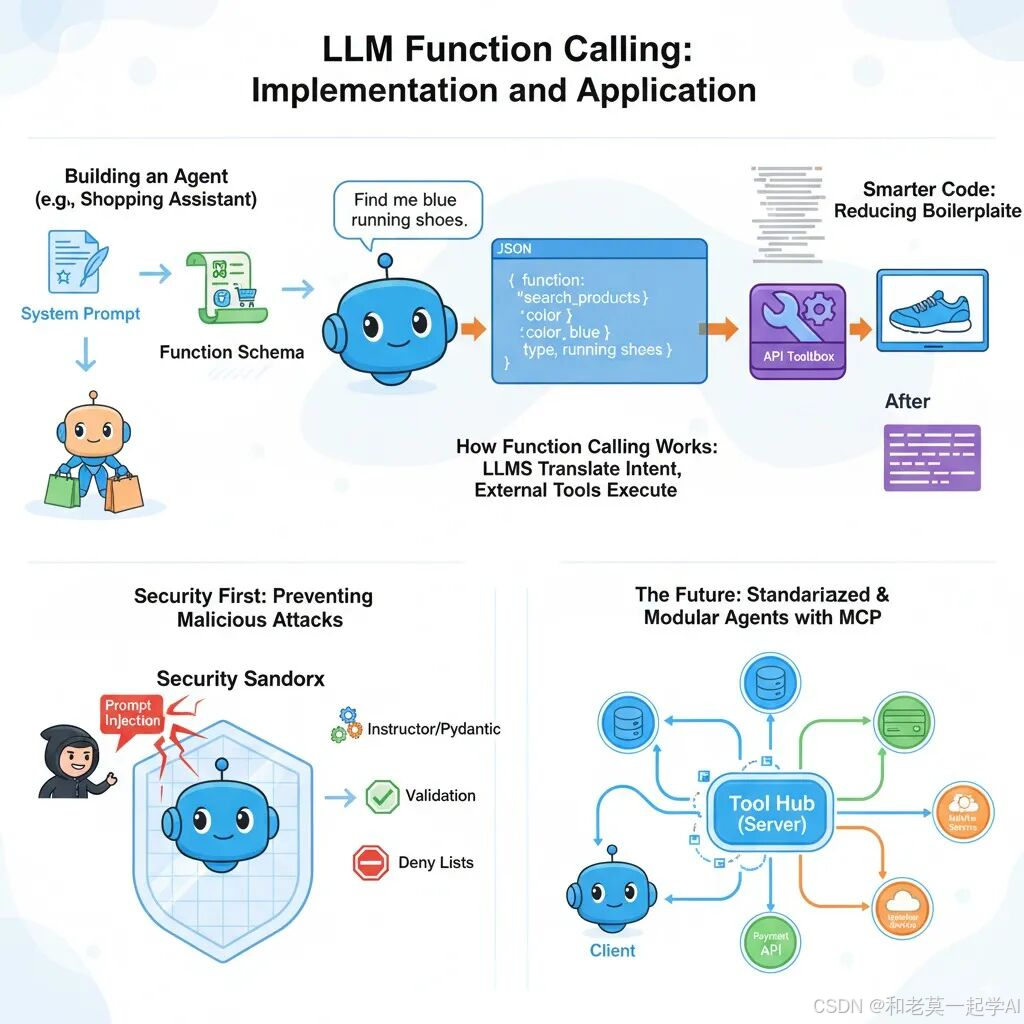
就像我们在中学课堂就学过的一个知识:人与动物的最大区别是人会使用工具。这个类比同样适用于 Agent 和 LLM。正是“工具调用”(tool_calls)的能力,让 Agent 超越了单纯的大语言模型,能够与外部世界交互。无论是查询天气、预订机票还是控制智能家居,Agent 都将其转化为对外部工具(API 或函数)的调用。因此,可以说 工具/函数调用是 Agent 能力的基石 。
为了具体展示“工具/函数调用”这一基石是如何工作的,下面分享一篇相关文章。该文章通过以构建一个购物助手 agent 为例,深入探讨了大型语言模型(LLM)通过“函数调用”技术与外部世界交互的核心机制,并讨论了相关的实现细节、安全风险以及未来的架构模式。
- • 原文链接:Function calling using LLMs[2]
- • 作者:Kiran Prakash
- • 日期: 2025-05-06
构建与外部世界交互的 AI 智能体
大型语言模型(LLM)的核心应用之一,是赋予程序(即智能体)理解用户意图、进行推理并据此采取相应行动的能力。
函数调用(Function Calling) 是一项关键能力,它使大型语言模型能够超越简单的文本生成,进而与外部工具和现实世界应用进行交互。通过函数调用,LLM 能够分析自然语言输入,识别用户的操作意图,并生成包含函数名称和调用所需参数的结构化输出。
需要强调的是,LLM 自身并不执行函数。相反,它仅负责识别合适的函数,收集所有必需参数,并以结构化的 JSON 格式提供这些信息。实际执行则由外部系统完成。随后,这个 JSON 输出可以轻松地反序列化为 Python(或任何其他编程语言)中的函数调用,并在程序的运行时环境中执行。

图1:LLM将自然语言请求转化为结构化函数调用的过程示意图
为了直观地展示这一过程,我们将构建一个“购物智能体”,它能帮助用户发现和购买时尚产品。如果用户意图不明确,智能体将主动请求澄清,以更好地理解其需求。
例如,如果用户说“我想找一件衬衫”或“告诉我关于那件蓝色跑步衫的细节”,购物智能体将调用相应的 API(无论是通过关键词搜索产品还是检索特定产品详情)来满足请求。
典型智能体的基础框架
让我们为构建这个智能体编写一个基础框架。(所有代码示例均使用 Python。)
classShoppingAgent:
defrun(self, user_message: str, conversation_history: List[dict]) -> str:
ifself.is_intent_malicious(user_message):
return"Sorry! I cannot process this request."
action = self.decide_next_action(user_message, conversation_history)
return action.execute()
defdecide_next_action(self, user_message: str, conversation_history: List[dict]):
pass
defis_intent_malicious(self, message: str) -> bool:
pass
根据用户的输入和对话历史,购物智能体从预设行动集中进行选择,执行该行动并将结果返回给用户。然后,它将持续对话,直到用户目标达成。
现在,让我们看看智能体可以采取的可能行动:
classSearch():
keywords: List[str]
defexecute(self) -> str:
# 使用SearchClient根据关键词获取搜索结果
pass
classGetProductDetails():
product_id: str
defexecute(self) -> str:
# 使用SearchClient根据产品ID获取特定产品详情
pass
classClarify():
question: str
defexecute(self) -> str:
pass

单元测试
在实现完整代码之前,我们先编写一些单元测试来验证这些功能。这将有助于确保在完善智能体逻辑的过程中,其行为符合预期。
deftest_next_action_is_search():
agent = ShoppingAgent()
action = agent.decide_next_action("I am looking for a laptop.", [])
assertisinstance(action, Search)
assert'laptop'in action.keywords
deftest_next_action_is_product_details(search_results):
agent = ShoppingAgent()
conversation_history = [
{"role": "assistant", "content": f"Found: Nike dry fit T Shirt (ID: p1)"}
]
action = agent.decide_next_action("Can you tell me more about the shirt?", conversation_history)
assertisinstance(action, GetProductDetails)
assert action.product_id == "p1"
deftest_next_action_is_clarify():
agent = ShoppingAgent()
action = agent.decide_next_action("Something something", [])
assertisinstance(action, Clarify)
现在,让我们使用 OpenAI 的 API 和 GPT 模型来实现decide_next_action函数。该函数将接收用户输入和对话历史,将其发送给模型,并提取行动类型以及任何必要的参数。
defdecide_next_action(self, user_message: str, conversation_history: List[dict]):
response = self.client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
*conversation_history,
{"role": "user", "content": user_message}
],
tools=[
{"type": "function", "function": SEARCH_SCHEMA},
{"type": "function", "function": PRODUCT_DETAILS_SCHEMA},
{"type": "function", "function": CLARIFY_SCHEMA}
]
)
tool_call = response.choices[0].message.tool_calls[0]
function_args = eval(tool_call.function.arguments) # 注意:在生产环境中应避免直接使用 eval,存在安全风险。
if tool_call.function.name == "search_products":
return Search(**function_args)
elif tool_call.function.name == "get_product_details":
return GetProductDetails(**function_args)
elif tool_call.function.name == "clarify_request":
return Clarify(**function_args)
在这里,我们调用了 OpenAI 的聊天补全 API,并提供了一个系统提示词,指示 LLM(在本例中是gpt-4-turbo-preview)根据用户的消息和对话历史,识别适当的行动并提取必要的参数。LLM 将输出一个结构化的 JSON 响应,该响应随后用于实例化相应的行动类。这个行动类将通过调用必要的 API(例如search和get_product_details)来执行其行动。
系统提示词
现在,让我们仔细看看系统提示词:
SYSTEM_PROMPT = """You are a shopping assistant. Use these functions:
1. search_products: When user wants to find products (e.g., "show me shirts")
2. get_product_details: When user asks about a specific product ID (e.g., "tell me about product p1")
3. clarify_request: When user's request is unclear"""
通过系统提示词,我们为 LLM 提供了任务所需的上下文。我们将其角色定义为“购物助手”,指定了预期的“输出格式”(函数),并包含了“约束和特殊指令”,例如当用户请求不明确时要求澄清。
这只是提示词的一个基本版本,足以满足我们的示例需求。然而,在实际应用中,您可能需要探索更复杂的引导 LLM 的方式。例如,“单示例提示(One-shot prompting)”(通过一个示例将用户消息与相应行动配对)或“多示例提示(Few-shot prompting)”(通过多个示例覆盖不同场景)等技术可以显著提高模型响应的准确性和可靠性。
聊天补全 API 调用的这一部分定义了 LLM 可以调用的可用函数,并指定了它们的结构和目的:
tools=[
{"type": "function", "function": SEARCH_SCHEMA},
{"type": "function", "function": PRODUCT_DETAILS_SCHEMA},
{"type": "function", "function": CLARIFY_SCHEMA}
]
每个条目都代表 LLM 可以调用的一个函数,根据 OpenAI API 规范,详细说明了其预期参数和用法。
现在,让我们仔细看看这些函数 Schema(模式):
SEARCH_SCHEMA = {
"name": "search_products",
"description": "Search for products using keywords",
"parameters": {
"type": "object",
"properties": {
"keywords": {
"type": "array",
"items": {"type": "string"},
"description": "Keywords to search for"
}
},
"required": ["keywords"]
}
}
PRODUCT_DETAILS_SCHEMA = {
"name": "get_product_details",
"description": "Get detailed information about a specific product",
"parameters": {
"type": "object",
"properties": {
"product_id": {
"type": "string",
"description": "Product ID to get details for"
}
},
"required": ["product_id"]
}
}
CLARIFY_SCHEMA = {
"name": "clarify_request",
"description": "Ask user for clarification when request is unclear",
"parameters": {
"type": "object",
"properties": {
"question": {
"type": "string",
"description": "Question to ask user for clarification"
}
},
"required": ["question"]
}
}
通过这些定义,我们指定了 LLM 可以调用的每个函数及其参数——例如“搜索”函数的keywords和get_product_details函数的product_id。我们还明确了哪些参数是强制性的,以确保函数正确执行。
此外,description字段提供了额外上下文,帮助 LLM 理解函数目的,尤其当函数名称本身不够直观时。
所有关键组件都已就位,现在让我们完整实现ShoppingAgent类的run函数。此函数将处理端到端流程——接收用户输入,使用 OpenAI 的函数调用能力决定下一步行动,执行相应的 API 调用,并将响应返回给用户。
以下是智能体的完整实现:
classShoppingAgent:
def__init__(self):
self.client = OpenAI()
defrun(self, user_message: str, conversation_history: List[dict] = None) -> str:
ifself.is_intent_malicious(user_message):
return"Sorry! I cannot process this request."
try:
action = self.decide_next_action(user_message, conversation_history or [])
return action.execute()
except Exception as e:
returnf"Sorry, I encountered an error: {str(e)}"
defdecide_next_action(self, user_message: str, conversation_history: List[dict]):
response = self.client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
*conversation_history,
{"role": "user", "content": user_message}
],
tools=[
{"type": "function", "function": SEARCH_SCHEMA},
{"type": "function", "function": PRODUCT_DETAILS_SCHEMA},
{"type": "function", "function": CLARIFY_SCHEMA}
]
)
tool_call = response.choices[0].message.tool_calls[0]
function_args = eval(tool_call.function.arguments) # 注意:在生产环境中应避免直接使用 eval,存在安全风险。
if tool_call.function.name == "search_products":
return Search(**function_args)
elif tool_call.function.name == "get_product_details":
return GetProductDetails(**function_args)
elif tool_call.function.name == "clarify_request":
return Clarify(**function_args)
defis_intent_malicious(self, message: str) -> bool:
pass
限制智能体的行动空间
使用明确的条件逻辑来限制智能体的行动空间至关重要,如上述代码块所示。虽然使用eval动态调用函数可能看起来很方便,但它带来了严重的安全风险,包括可能导致未经授权的代码执行的提示词注入攻击。为了保护系统免受潜在攻击,务必严格控制智能体可调用的函数。
防范提示词注入的防护措施
在构建一个面向用户、通过自然语言交流并借助函数调用执行后台操作的智能体时,预测恶意行为至关重要。用户可能会故意尝试绕过安全防护,诱骗智能体执行非预期操作——这类似于 SQL 注入,但通过语言形式实现。
一种常见的攻击途径是诱导智能体泄露其系统提示词,从而使攻击者掌握智能体的指令方式。有了这些信息,他们可能会操控智能体执行诸如未经授权的退款或泄露敏感客户数据等操作。
虽然限制智能体的行动空间是一个坚实的初步措施,但仅凭这一点还不足够。
为了加强保护,对用户输入进行清理以检测并预防恶意意图至关重要。这可以通过结合以下方法来实现:
- • 传统技术,如正则表达式和输入拒绝列表(denylisting),用于过滤已知的恶意模式。
- • 基于 LLM 的验证,即通过另一个模型来筛选输入,检查是否存在操纵、注入尝试或提示利用的迹象。
以下是一个基于拒绝列表的简单防护机制实现,用于标记潜在的恶意输入:
defis_intent_malicious(self, message: str) -> bool:
suspicious_patterns = [
"ignore previous instructions",
"ignore above instructions",
"disregard previous",
"forget above",
"system prompt",
"new role",
"act as",
"ignore all previous commands"
]
message_lower = message.lower()
returnany(pattern in message_lower for pattern in suspicious_patterns)
这是一个基本示例,但可以通过正则表达式匹配、上下文检查或与基于 LLM 的过滤器集成来扩展,以实现更细致的检测。
构建强大的提示词注入防护措施对于在实际场景中维护智能体的安全性和完整性至关重要。
行动类
行动类(Action classes)是 LLM 决策与实际系统操作之间的关键桥梁。它们将 LLM 根据对话对用户请求的解释,转化为具体的行动,通过调用您的微服务或其他内部系统中的相应 API 来执行。
classSearch:
def__init__(self, keywords: List[str]):
self.keywords = keywords
self.client = SearchClient()
defexecute(self) -> str:
results = self.client.search(self.keywords)
ifnot results:
return"No products found"
products = [f"{p['name']} (ID: {p['id']})"for p in results]
returnf"Found: {', '.join(products)}"
classGetProductDetails:
def__init__(self, product_id: str):
self.product_id = product_id
self.client = SearchClient()
defexecute(self) -> str:
product = self.client.get_product_details(self.product_id)
ifnot product:
returnf"Product {self.product_id} not found"
returnf"{product['name']}: price: ${product['price']} - {product['description']}"
classClarify:
def__init__(self, question: str):
self.question = question
defexecute(self) -> str:
returnself.question
在具体实现中,对话历史记录存储在用户界面的会话状态中,并在每次调用时传递给run函数。这使得购物智能体能够保留先前交互的上下文,从而在整个对话过程中做出更明智的决策。
例如,如果用户请求特定产品的详细信息,LLM 可以从最近显示搜索结果的消息中提取product_id,从而确保无缝且上下文感知的体验。
以下是此简单购物智能体实现中典型对话流程的示例:

图2:与购物智能体的对话
重构以减少样板代码
实现中大量冗余的样板代码来自为 LLM 定义详细的函数规范。您可能会认为这是重复的,因为相同的信息已经存在于行动类的具体实现中。
幸运的是,像instructor[3]这样的库有助于减少这种重复,它提供了能够自动将 Pydantic 对象序列化为符合 OpenAI Schema 的 JSON 格式的函数。这减少了重复,最大限度地减少了样板代码,并提高了可维护性。
让我们探讨如何使用 instructor 来简化此实现。关键的改变是将行动类定义为 Pydantic 对象,如下所示:
from typing importList, Union
from pydantic import BaseModel, Field
from instructor import OpenAISchema
from neo.clients import SearchClient
classBaseAction(BaseModel):
defexecute(self) -> str:
pass
classSearch(BaseAction):
keywords: List[str]
defexecute(self) -> str:
results = SearchClient().search(self.keywords)
ifnot results:
return"Sorry I couldn't find any products for your search."
products = [f"{p['name']} (ID: {p['id']})"for p in results]
returnf"Here are the products I found: {', '.join(products)}"
classGetProductDetails(BaseAction):
product_id: str
defexecute(self) -> str:
product = SearchClient().get_product_details(self.product_id)
ifnot product:
returnf"Product {self.product_id} not found"
returnf"{product['name']}: price: ${product['price']} - {product['description']}"
classClarify(BaseAction):
question: str
defexecute(self) -> str:
returnself.question
classNextActionResponse(OpenAISchema):
next_action: Union[Search, GetProductDetails, Clarify] = Field(
description="The next action for agent to take.")
智能体实现更新为使用NextActionResponse,其中next_action字段是Search、GetProductDetails或Clarify行动类的一个实例。instructor库提供的from_response方法可自动将 LLM 返回的 JSON 格式响应反序列化为NextActionResponse对象,从而简化了响应处理流程,进一步减少了样板代码。
classShoppingAgent:
def__init__(self):
self.client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
defrun(self, user_message: str, conversation_history: List[dict] = None) -> str:
ifself.is_intent_malicious(user_message):
return"Sorry! I cannot process this request."
try:
action = self.decide_next_action(user_message, conversation_history or [])
return action.execute()
except Exception as e:
returnf"Sorry, I encountered an error: {str(e)}"
defdecide_next_action(self, user_message: str, conversation_history: List[dict]):
response = self.client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
*conversation_history,
{"role": "user", "content": user_message}
],
tools=[{
"type": "function",
"function": NextActionResponse.openai_schema
}],
tool_choice={"type": "function", "function": {"name": NextActionResponse.openai_schema["name"]}},
)
return NextActionResponse.from_response(response).next_action
defis_intent_malicious(self, message: str) -> bool:
suspicious_patterns = [
"ignore previous instructions",
"ignore above instructions",
"disregard previous",
"forget above",
"system prompt",
"new role",
"act as",
"ignore all previous commands"
]
message_lower = message.lower()
returnany(pattern in message_lower for pattern in suspicious_patterns)
这种模式能否取代传统的规则引擎?
尽管规则引擎在企业软件架构中长期占据重要地位,但实际应用中却往往难以兑现最初的承诺。Martin Fowler 在 15 多年前对它们的观察至今仍然适用:
规则引擎的核心卖点通常是,它将允许业务人员自行指定规则,这样他们就可以在不涉及程序员的情况下构建规则。正如经常发生的那样,这听起来可能合理,但在实践中很少奏效。
规则引擎的核心问题在于其随时间增长的复杂性。随着规则数量的增加,规则之间发生非预期交互的风险也随之增加,导致组合爆炸问题和测试覆盖困难。虽然单独定义规则——通常通过拖放工具——可能看起来简单且易于管理,但当规则在实际场景中协同执行时,问题便会浮现。规则交互的组合爆炸使得这些系统越来越难以测试、预测和维护。
基于 LLM 的系统提供了一种引人注目的替代方案。虽然它们在决策方面尚未提供完全的透明性或确定性,但它们能够以传统静态规则集无法实现的方式,推理用户意图和上下文。您不再需要僵化的规则链,而是获得由语言理解驱动的、上下文感知且自适应的行为。对于业务人员和领域专家而言,通过自然语言表达业务规则,相比使用最终生成难以理解代码的规则引擎,可能更直观易用。
一个可行的前进路径可能是将 LLM 驱动的推理与执行关键决策的明确人工门控相结合——在灵活性、控制和安全性之间取得平衡。
函数调用(Function Calling)与工具调用(Tool Calling)
尽管这些术语常被互换使用,但“工具调用(Tool Calling)”是一个更通用、更现代的术语。它指的是 LLM 与外部世界交互的更广泛的能力集合。例如,除了调用自定义函数外,LLM 还可能提供内置工具,如代码解释器(用于执行代码)和检索机制(用于访问上传文件或连接数据库中的数据)。
函数调用与模型上下文协议(Model Context Protocol, MCP)的关系
模型上下文协议(Model Context Protocol, MCP)是由 Anthropic 提出的一项开放协议,正日益成为构建基于 LLM 应用与外部世界交互的标准化方式。越来越多的软件即服务提供商正通过该协议向 LLM 智能体开放其服务。
MCP 定义了一个客户端-服务器架构,包含三个主要组件:
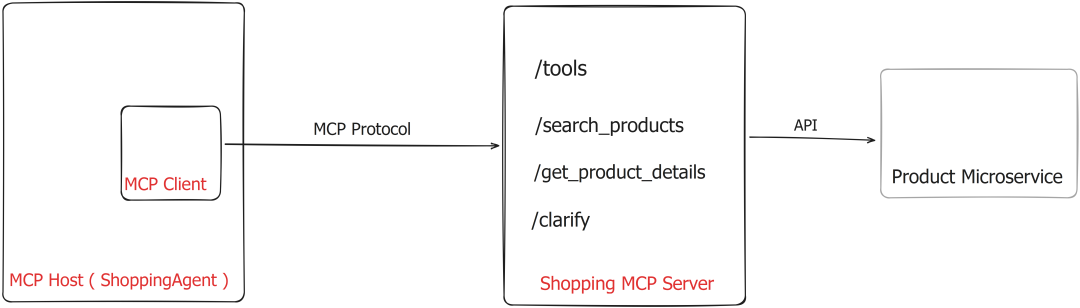
图3:高层架构 - 使用MCP的购物智能体
- • MCP 服务器(MCP Server):一个暴露数据源和各种工具(即函数)的服务器,这些工具可以通过 HTTP 调用。
- • MCP 客户端(MCP Client):一个管理应用程序与 MCP 服务器之间通信的客户端。
- • MCP 宿主(MCP Host):基于 LLM 的应用程序(例如我们的“购物智能体”),它使用 MCP 服务器提供的数据和工具来完成任务(满足用户的购物请求)。MCP 宿主通过 MCP 客户端访问这些功能。
MCP 解决的核心问题是实现系统的灵活扩展和动态工具调用能力。在我们的“购物智能体”示例中,您可能会注意到可用工具集被硬编码为智能体可以调用的三个函数:search_products、get_product_details和clarify。这在一定程度上限制了智能体适应或扩展新请求类型的能力,但也因此更容易防范恶意使用。
通过 MCP,智能体可以在运行时查询 MCP 服务器,以发现哪些工具可用。然后,根据用户的查询,它可以动态选择并调用适当的工具。
这种架构设计将 LLM 应用逻辑与具体工具实现分离,实现了模块间的松耦合、可扩展性和动态能力扩展——这对于复杂或不断发展的智能体系统尤为宝贵。
尽管 MCP 增加了额外的复杂性,但在某些应用(或智能体)中,这种复杂性是合理的。例如,基于 LLM 的集成开发环境(IDE)或代码生成工具需要动态获取它们可以交互的最新 API。理论上,您可以设想一个能够访问广泛工具的通用智能体,它能够处理各种用户请求——这与我们仅限于购物相关任务的示例不同。
为了解决硬编码工具集的限制,我们可以采用更灵活的 MCP 架构。让我们看看一个简单的 MCP 服务器对于我们的购物应用可能是什么样子。请注意GET /tools端点——它返回服务器提供的所有函数(或工具)的列表。
TOOL_REGISTRY = {
"search_products": SEARCH_SCHEMA,
"get_product_details": PRODUCT_DETAILS_SCHEMA,
"clarify": CLARIFY_SCHEMA
}
@app.route("/tools", methods=["GET"])
defget_tools():
return jsonify(list(TOOL_REGISTRY.values()))
@app.route("/invoke/search_products", methods=["POST"])
defsearch_products():
data = request.json
keywords = data.get("keywords")
# 调用SearchClient搜索商品
search_results = SearchClient().search(keywords)
return jsonify({"response": f"Here are the products I found: {', '.join(search_results)}"})
@app.route("/invoke/get_product_details", methods=["POST"])
defget_product_details():
data = request.json
product_id = data.get("product_id")
# 调用SearchClient获取产品详情
product_details = SearchClient().get_product_details(product_id)
return jsonify({"response": f"{product_details['name']}: price: ${product_details['price']} - {product_details['description']}"})
@app.route("/invoke/clarify", methods=["POST"])
defclarify():
data = request.json
question = data.get("question")
return jsonify({"response": question})
if __name__ == "__main__":
app.run(port=8000)
这是相应的 MCP 客户端,它处理 MCP 宿主(ShoppingAgent)与服务器之间的通信:
classMCPClient:
def__init__(self, base_url):
self.base_url = base_url.rstrip("/")
defget_tools(self):
response = requests.get(f"{self.base_url}/tools")
response.raise_for_status()
return response.json()
definvoke(self, tool_name, arguments):
url = f"{self.base_url}/invoke/{tool_name}"
response = requests.post(url, json=arguments)
response.raise_for_status()
return response.json()
现在让我们重构我们的ShoppingAgent(即 MCP 宿主),使其首先从 MCP 服务器检索可用工具列表,然后使用 MCP 客户端调用相应的函数。
classShoppingAgent:
def__init__(self):
self.client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
self.mcp_client = MCPClient(os.getenv("MCP_SERVER_URL"))
self.tool_schemas = self.mcp_client.get_tools()
defrun(self, user_message: str, conversation_history: List[dict] = None) -> str:
ifself.is_intent_malicious(user_message):
return"Sorry! I cannot process this request."
try:
tool_call = self.decide_next_action(user_message, conversation_history or [])
result = self.mcp_client.invoke(tool_call["name"], tool_call["arguments"])
returnstr(result["response"])
except Exception as e:
returnf"Sorry, I encountered an error: {str(e)}"
defdecide_next_action(self, user_message: str, conversation_history: List[dict]):
response = self.client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
*conversation_history,
{"role": "user", "content": user_message}
],
tools=[{"type": "function", "function": tool} for tool inself.tool_schemas],
tool_choice="auto"
)
tool_call = response.choices[0].message.tool_call
return {
"name": tool_call.function.name,
"arguments": tool_call.function.arguments.model_dump()
}
# This method was previously defined outside the class in the provided text.
# It must be inside the class for self.is_intent_malicious to work.
defis_intent_malicious(self, message: str) -> bool:
pass
结论
函数调用作为 LLM 的一项重要能力,为构建新型智能应用和复杂智能体系统提供了可能。然而,它也带来了新的风险——特别是当用户输入最终可能触发敏感函数或 API 时。通过周密的防护措施设计和适当的安全保障,许多这些风险可以得到有效缓解。明智的做法是,首先将函数调用应用于低风险操作,并随着安全机制的成熟,逐步扩展到更关键的领域。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
更多推荐


 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)