
训诂学与现代人工智能结合的学术价值与技术潜力
摘要:本文探讨中国传统训诂学与现代AI技术的融合路径,分析训诂学"形音义互求"等方法论对解决NLP深层语义理解瓶颈的价值。研究表明,训诂学可为AI提供文化语境理解、形音义关联建模等独特解决方案,弥补当前模型在可解释性和文化内涵解码方面的不足。报告提出构建训诂学知识图谱与专家系统的技术方案,通过典型案例展示其在古文多义消歧、语义演变追踪等方面的应用潜力。尽管面临数据集不足等挑战,
摘要
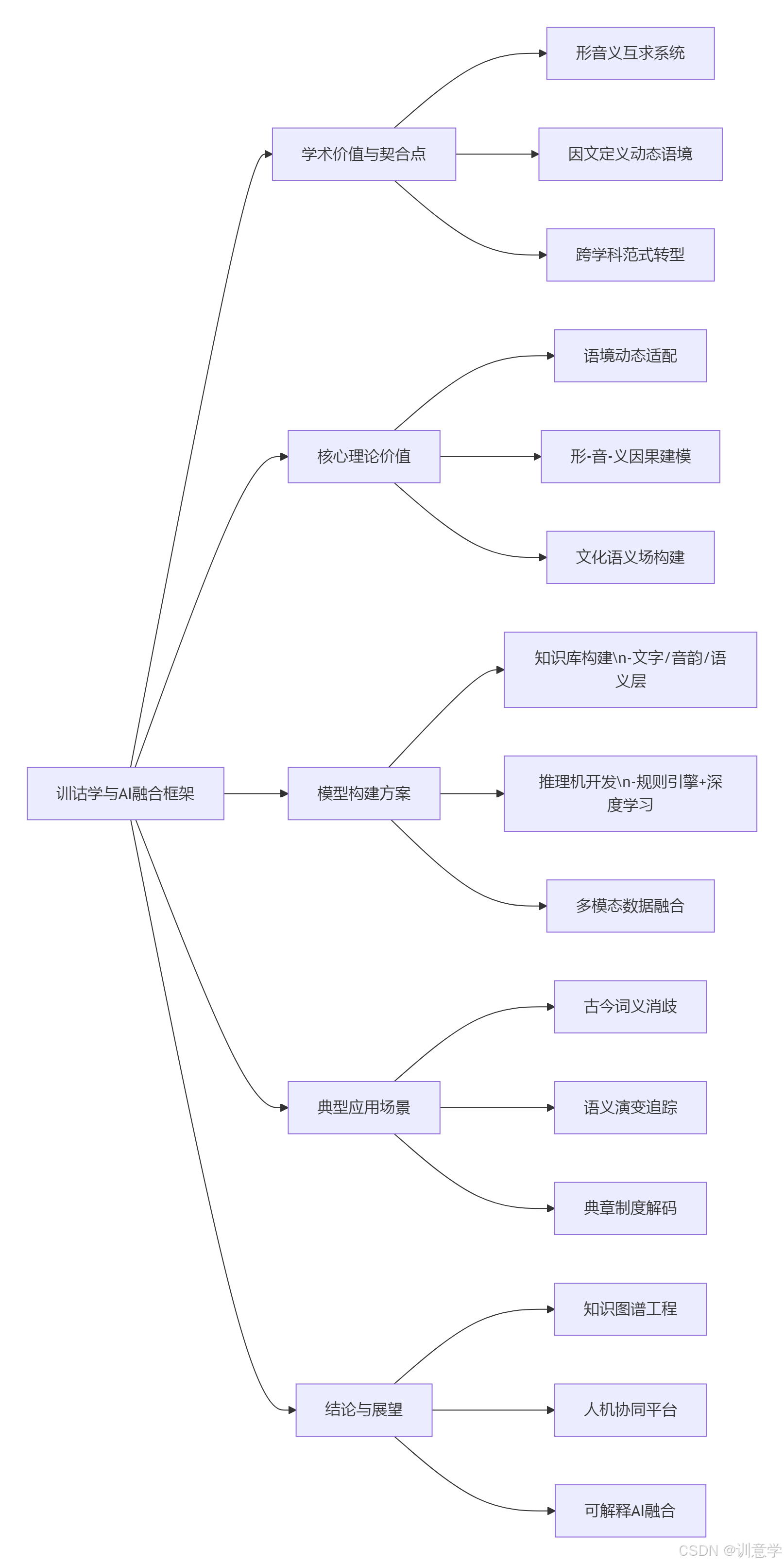
本报告旨在系统性探讨中国传统训诂学与现代人工智能(AI),特别是自然语言处理(NLP)技术,深度融合的学术价值、理论贡献与技术实现路径。训诂学作为研究中国古代文献语义的核心学科,其“形音义互求”、“因文定义”等方法论,为解决当前AI在深层语义理解、文化内涵解码及语境动态适配等方面的瓶颈提供了独特的理论宝库和技术启示。报告将首先分析二者结合的契合点与学术影响,进而阐述训诂学如何弥补现代NLP的语义分析短板,并提出构建基于训诂学的知识图谱与专家系统的具体方案。最后,报告将通过典型案例展示其应用潜力,并论述此种结合对于补充AI人文维度的重要意义。尽管目前尚未出现成熟的、完全基于训诂学理论构建的公开AI项目或数据集 本报告旨在勾勒一幅清晰的研究蓝图与技术路线图,论证其前瞻性与可行性。
一、 训诂学的核心优势与AI语义分析的契合点
训诂学与人工智能的结合,并非简单的学科嫁接,而是传统人文智慧与前沿计算技术的深度共鸣。这种共鸣根植于两者在探求语言深层意义这一共同目标上的方法论互补性。
1.1 训诂学方法论与NLP深层语义推理的天然契合
传统训诂学的核心是“通经致用”,即通过精确解读字词本义与引申义,来理解古代经典的思想内涵。其精密的方法论体系,与AI追求的深层语义推理需求高度一致。
-
因果性语义建模的契合:训诂学强调汉字“形、音、义”三位一体的系统性关联,这本身就是一种因果逻辑的探求。例如,《说文解字》的部首分析(形训)和声旁提示(声训),揭示了字义源于字形的理据和通过声音联系的词族关系。这种“由形索义”和“因声求义”的思维路径,可为AI提供超越简单统计共现的、基于历史演变和构形逻辑的语义关联规则。例如,一个AI模型若能理解“江”、“河”、“湖”、“海”皆从“水”旁,便能建立它们与“水域”这一核心概念的强因果关联,这比仅仅通过词向量的余弦相似度来判断语义接近性要深刻和可解释得多。
-
语境动态适配的互补:训诂学的核心原则之一是“因文定义”,强调任何词义的解读都不能脱离其具体的上下文、篇章结构乃至时代背景。这与现代NLP领域中以Transformer架构为代表的注意力机制(Attention Mechanism)思想不谋而合 。Transformer模型通过计算句子中每个词与其他所有词的关联权重来动态生成词的语境化表示 。然而,当前模型的“语境”多局限于局部文本窗口。而训诂学的“语境”则是一个更为宏大的概念,涵盖了历史文化、典章制度、作者生平等多维度信息。将训诂学的考据方法融入AI,可以极大地扩展模型理解语境的深度和广度,从而更精准地处理一词多义和古今异义等复杂现象。
1.2 对训诂学学术地位的潜在影响
将训诂学与AI结合,不仅能提升AI的“智能”,更能为这门古老学科注入新的生命力,重塑其在当代学术体系中的地位。
-
推动跨学科融合,拓展学科边界:通过构建基于训诂学理论的知识图谱或专家系统,训诂学将从一门纯粹的文献研究学科,转变为“计算语言学”和“语言智能”领域的基础理论贡献者。例如,通过将《尔雅》的语义分类体系、《广韵》的音韵系统进行结构化和数字化,可以构建出服务于AI的古汉语语义网络和语音演变模型 使其研究成果直接转化为可计算、可应用的现代技术资产。
-
实现方法论的创新与验证:传统训诂学依赖学者的人工考据和逻辑推理,其过程难以量化和复现。AI的引入可以将“互训”、“声训”、“递训”等方法转化为可执行的计算规则或算法模型。例如,可以设计算法模拟清代学者戴震、王念孙等人的考据路径,通过大规模语料库进行自动化验证和新发现的挖掘。这不仅能提升训诂研究的效率和规模,更能使其方法论在与AI模型的互动中得到检验、修正和创新。
二、 核心理论价值:弥补现代NLP的语义分析短板
当前主流的NLP模型(如BERT、GPT系列)虽在多项任务上表现优异,但其本质上是基于大规模数据统计的“黑箱”模型,在可解释性、文化理解和深层逻辑推理方面存在明显短板。训诂学的理论恰好能从以下几个方面提供关键补充。
2.1 语境动态适配的精细化:从文本语境到文化语境
现代NLP模型虽能捕捉局部上下文,但对超出文本范围的宏大语境(如历史背景、社会制度)的理解能力有限。训诂学的考据法则为此提供了解决方案。例如,《左传》中的“器”字,在不同语境下可指具体的“车马器用”,也可指抽象的“名分、制度”。一个仅依赖BERT上下文窗口的模型很难准确区分。而一个融合了训诂学知识的系统,可以通过链接到预先构建的《周礼》等典章制度知识库,识别出与“器”一同出现的词(如“名”、“位”),从而推理出此处的“器”指向的是超越物理实体的礼制象征,实现从“文本语境”到“文化语境”的跨越式理解。
2.2 形-音-义系统关联的因果性建模:提升模型的可解释性
NLP模型常被诟病“知其然不知其所以然”。训诂学的“形音义互求”法则能为AI的语义判断提供清晰的因果链条,增强其解释性。
-
音义关联的计算化:古音学中的“古无轻唇音”、“古无舌上音”等规律,解释了大量通假字的成因。例如,“父”与“爸”在古代音值相近,可以建立语音上的关联;“道”与“导”声母相同、韵母相近,存在意义上的引申关系。将这些音韵演变规律编码为知识图谱中的推理路径,AI在遇到“知周万物,而道济天下”中的“道”时,不仅能识别其“道路”的本义,还能根据声训关联,推导出“引导、治理”的引申义。目前虽缺乏完整的公开数据集,但一些学者整理的重构发音词典为此提供了可能 。
-
形义关联的结构化:汉字的表意特质是巨大的信息宝库。《说文解字》对汉字构形的分析,如“心”作为意符,衍生出“思、想、情、意、志”等一系列与心理活动相关的字,揭示了从具体器官到抽象情感的隐喻映射机制。在构建知识图谱时,可以建立从“字形部件”到“核心语义范畴”再到“具体引申义”的多层级边关系(例如:
心->is_semantic_radical_of->思;思->has_cognitive_metaphor->思想活动)。这使得模型对词义的理解不再是扁平的向量,而是具有内在结构和生成逻辑的知识体系。
2.3 文化语义场的构建:赋予AI人文内涵
词汇并非孤立存在,而是构成反映特定文化的语义网络或“语义场”。《尔雅》将词汇按“释亲”、“释器”、“释草”等分类,本身就是对古代社会文化关注点的系统梳理。例如,对亲属称谓的研究,可以揭示古代宗法制度、姻亲关系和家庭伦理。在训练词嵌入模型时,除了使用大规模文本语料,还可以额外引入这些由训诂学梳理出的“文化标签”(如:礼制、宗法、五行),构建一个融合了文化属性的多维语义空间。这将极大提升AI对“仁”、“义”、“礼”、“孝”等文化负载词的理解深度,避免将其简单等同于“benevolence”或“ritual”等英文词汇的苍白翻译。
三、 基于训诂学的专家系统与AI模型构建方案
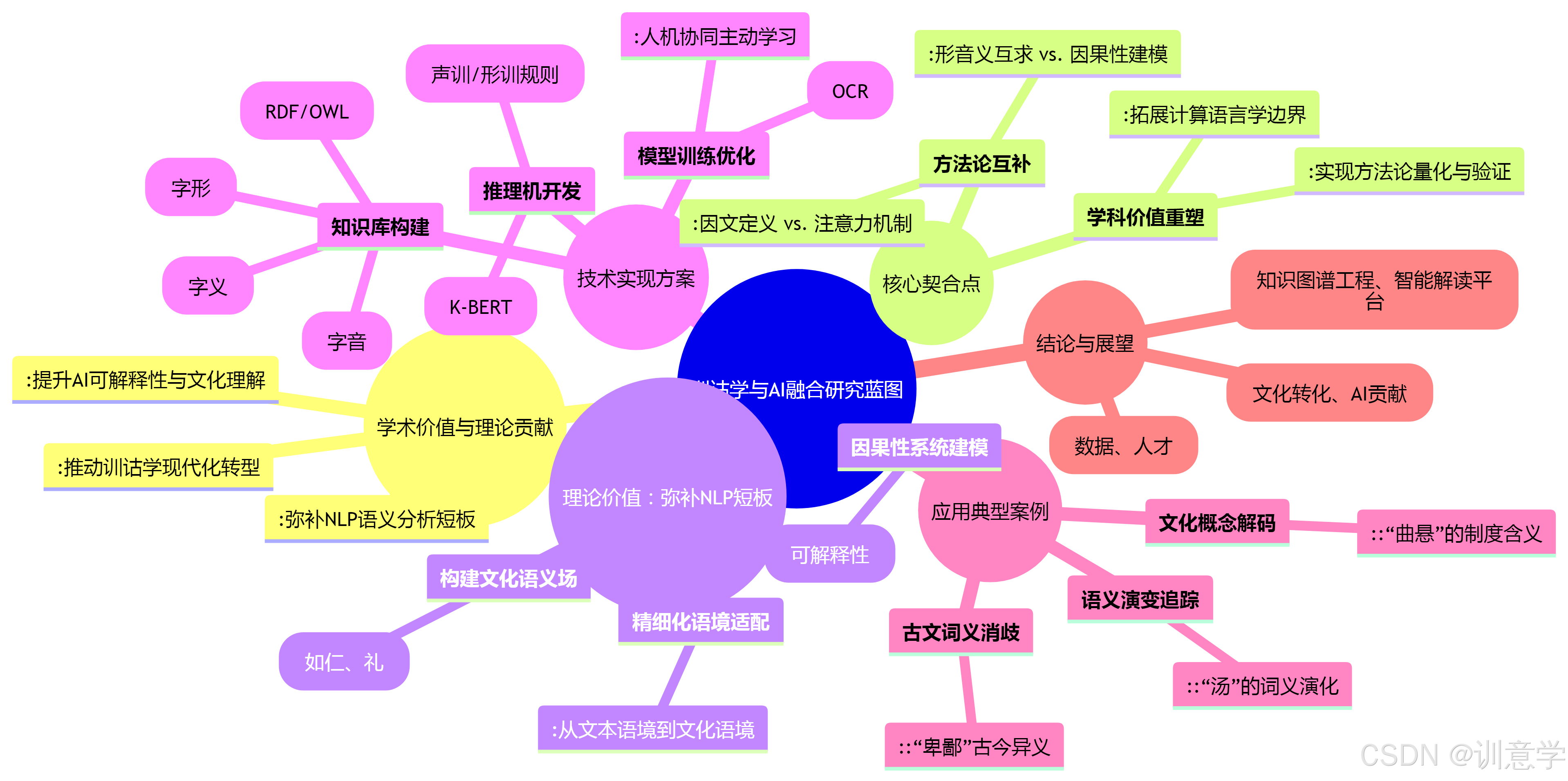
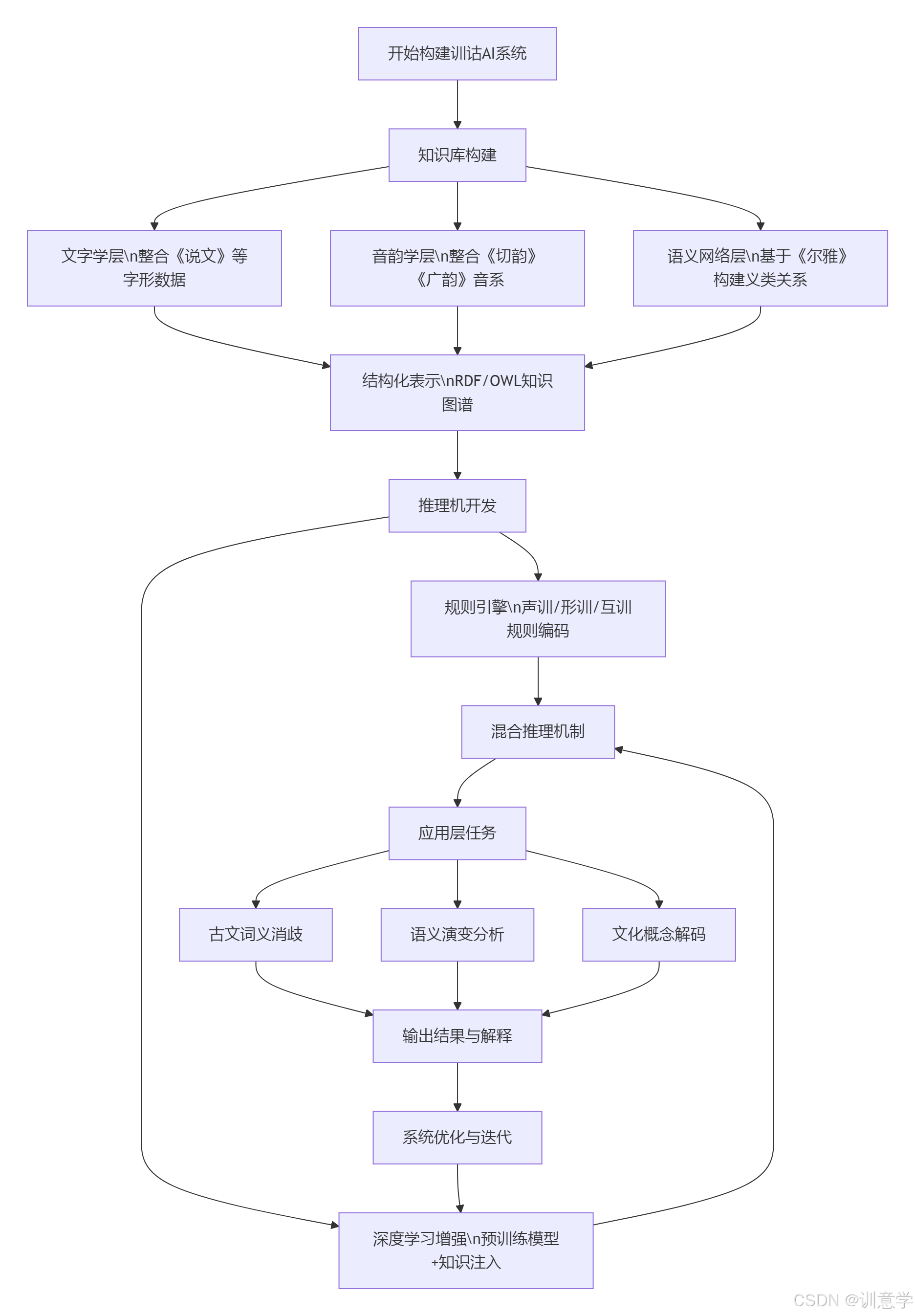
尽管公开的、专门用于训诂学知识图谱构建的综合性数据集仍付之阙如 但整合现有资源并提出一个前瞻性的技术方案是完全可行的。一个理想的训诂学AI系统应包含知识库、推理机和上层应用三个核心部分。
3.1 知识库设计:结构化与标准化
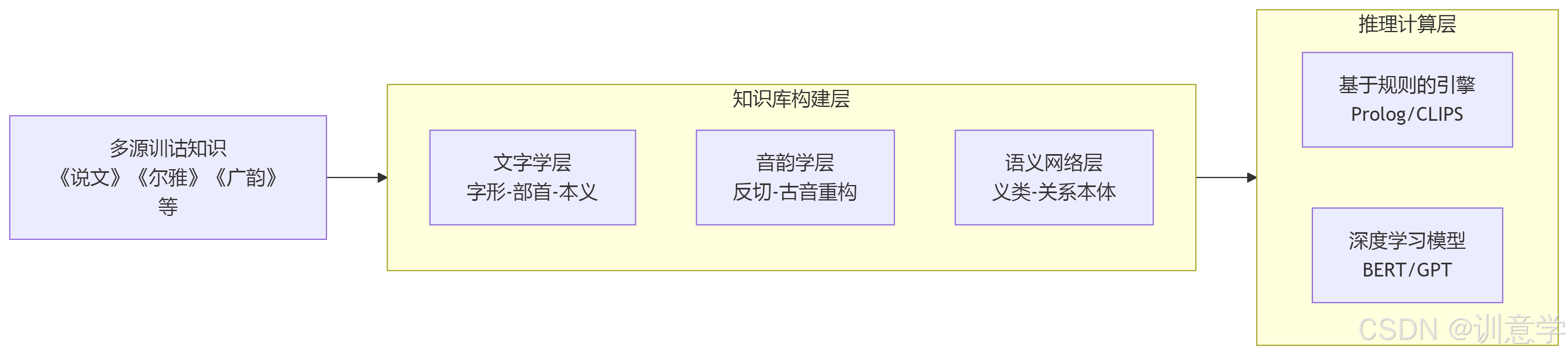
构建该系统的基石是一个高质量、大规模的训诂学知识图谱。虽然目前没有现成的“训诂知识图谱”,但我们可以整合多个来源的数据进行构建。
-
结构化训诂知识:
- 文字学层:抽取《说文解字》的9353个小篆及其形义分析、540个部首的统摄关系,形成“字形-部首-本义”的三元组。例如:
(人, 是部首, True),(仁, 从属部首, 人),`(仁, 释义, 亲也)”。同时,可以整合甲骨文、金文、简帛等多种古文字形数据 建立跨时代的字形演变链条。 - 音韵学层:整合《切韵》《广韵》的中古音系反切数据,以及学者如高本汉、王力、李方桂等的上古、中古音重构成果 。将这些数据转化为国际音标(IPA)或其他标准化音值表示,用于计算语音相似度。
- 语义网络层:以《尔雅》《释名》的义类划分为基础,借鉴现代语义学理论(如概念依存理论),定义一套语义角色和关系本体。例如,将《尔雅·释亲》的分类映射为
is_kinship_term_of等关系。类似“HanziNet”项目所提出的“字符驱动”本体论构建思路也极具参考价值 。
- 文字学层:抽取《说文解字》的9353个小篆及其形义分析、540个部首的统摄关系,形成“字形-部首-本义”的三元组。例如:
-
知识表示标准化:所有知识应采用W3C推荐的RDF(资源描述框架)或OWL(Web本体语言)进行表示,确保存储的结构化、可扩展性,并便于推理机进行高效的逻辑查询和推理。
3.2 推理机开发:规则引擎与深度学习的混合驱动
推理机是激活知识库、模拟训诂学家思维的核心。
-
基于规则的推理引擎:将训诂学的核心方法编码为形式化规则,可使用Prolog等逻辑编程语言或CLIPS等产生式系统实现。例如:
- 声训规则:
通假(字A, 字B) :- 古音相似(字A, 字B, 阈值_高), 语义相关(字A, 字B, 阈值_中). - 形训规则:
语义包含(字A, 范畴B) :- 部首(字A, 部首C), 范畴(部首C, 范畴B). - 互训规则:
同义(字A, 字B) :- 互训(尔雅, 字A, 字B).
- 声训规则:
-
深度学习增强的推理:纯规则系统灵活性有限。更强大的方案是将训诂知识图谱注入到大型预训练语言模型(如BERT、GPT)中。一个经过验证的有效方法是采用类似K-BERT(Knowledge-enabled BERT)的技术 。在处理一段古文时,可以将文本中词汇在知识图谱中相关的三元组(如字形分解、音韵关系、义类归属)转换为文本序列,一并输入给Transformer模型。这样,模型在进行语义判断时,不仅能看到文本本身,还能“看到”与之相关的结构化训诂知识,从而做出更精准、更可解释的决策 。
3.3 模型训练与优化
- 多模态数据融合:对于古籍,特别是出土文献,文字的载体(如甲骨、青铜、竹简)和书法形态本身也承载着重要信息。可以训练一个结合OCR(光学字符识别)与语义解析的端到端多模态模型,利用金石拓片、简帛图像等数据 实现从图像直接到语义的理解。
- 人机协同与主动学习:系统在面对新的、不确定的语言现象时,可以主动向专家(训诂学者)提问,并将专家的反馈(如一个新的义项、一条新的通假关系)增量式地更新到知识库和推理规则中,形成一个能够自我演进、持续学习的“活”系统。
四、 解决NLP深层语义挑战的典型案例
一个融合了训诂学智慧的AI系统,将在解决NLP领域公认的几大难题上展现出巨大优势。
-
古文多义词与古今异义的精准消歧:现代NLP模型处理古今异义词时常常出错。例如,《出师表》中的“卑鄙”,其本义是“出身低微,见识浅陋”,是诸葛亮的自谦之词。现代模型很可能错误地标注为负面情感。一个训诂AI系统可以通过以下方式解决:首先,其知识库中标注了“卑鄙”一词在汉代的义项;其次,通过比较《论语》《史记》等大量同时期文献中“卑”和“鄙”的用法(即训诂学中的“互证”),模型可以确认其在当时语境中的中性或自谦含义。研究表明,基于图和多知识源的消歧方法在中文WSD任务上表现优异,这为我们的设想提供了佐证 。虽然专门针对古汉语的WSD基准仍在建设中 ,但其方法论是通用的。
-
跨时代语义演变的追踪与预测:词义并非一成不变。例如“汤”一词,从《礼记》“冬日则饮汤”中的“热水”,演变为后世的“菜羹”,其间经历了复杂的认知隐喻过程(“热的液体” -> “烹饪用的热液体” -> “烹饪出的带汤汁的菜肴”)。训诂学的历时分析法,通过梳理不同时代文献中的用例,可以清晰地勾勒出这条演变路径。将这些路径作为标注语料,可以训练AI模型(如时序模型)来理解甚至预测词义的演变趋势。
-
文化特定概念与典章制度的深层解码:古籍中充满了反映特定历史文化的词汇。例如,《周礼》中的“曲悬”,字面意思是乐器的一种悬挂方式,但其深层含义是指代“诸侯等级的礼乐制度”。对于标准NLP模型而言,这是一个无法解码的“暗语”。而训诂AI系统可以链接一个专门的历代职官、礼制、地理数据库,实现“词汇 → 制度实体 → 权力象征”的层级化、多跳推理(multi-hop reasoning),从而真正读懂文字背后的文化密码。
五、 结论与展望
训诂学与人工智能的结合,是一场古典人文学术与尖端信息科学的双向赋能。它不仅为AI的语义理解瓶颈提供了源于东方智慧的独特解决方案,也为训诂学这门古老学科的现代化转型与价值重塑开辟了前所未有的道路。
当前,这一交叉领域的研究尚处于起步阶段,面临着高质量、标准化、开放共享的数据集匮乏 以及兼通两门学科的复合型人才稀缺等挑战。然而,正如本报告所论证的,其巨大的学术价值和技术潜力是毋庸置疑的。
展望未来,我们亟需启动大规模的训诂学知识图谱构建工程,整合学界力量,将《说文》《尔雅》《广韵》等基础典籍以及历代学者的研究成果进行系统性的数字化和结构化。在此基础上,开发融合规则推理与深度学习的下一代古籍智能解读平台,不仅能极大推动历史、文学、哲学等领域的研究范式变革,更将助力人工智能迈向更深邃、更具人文内涵的通用智能。这不仅是对中华优秀传统文化的创造性转化与创新性发展,也是对世界人工智能技术路线的独特贡献。
以下是基于Prolog的声训规则示例和RDF三元组示例,展示如何形式化训诂知识:
% 声训规则:通假字关系推理
is_related(X, Y) :-
ancient_sound(X, SoundX),
ancient_sound(Y, SoundY),
sound_similarity(SoundX, SoundY, high),
semantic_relevance(X, Y, high).
% 形训规则:部首语义关联
shape_meaning_relation(Character, Meaning) :-
has_radical(Character, Radical),
radical_semantic_field(Radical, SemanticField),
belongs_to_semantic_field(Meaning, SemanticField).更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)